
Storm基本概念 Storm是一個開源的實時計算系統,它提供了一系列的基本元素用於進行計算:Topology、Stream、Spout、Bolt等等。 在Storm中,一個實時應用的計算任務被打包作為Topology發佈,這同Hadoop的MapReduce任務相似。但是有一點不同的是:在Hado ...
Storm基本概念
Storm是一個開源的實時計算系統,它提供了一系列的基本元素用於進行計算:Topology、Stream、Spout、Bolt等等。
在Storm中,一個實時應用的計算任務被打包作為Topology發佈,這同Hadoop的MapReduce任務相似。但是有一點不同的是:在Hadoop中,MapReduce任務最終會執行完成後結束;而在Storm中,Topology任務一旦提交後永遠不會結束,除非你顯示去停止任務。
計算任務Topology是由不同的Spouts和Bolts,通過數據流(Stream)連接起來的圖。下麵是一個Topology的結構示意圖:

其中包含有:
Spout:Storm中的消息源,用於為Topology生產消息(數據),一般是從外部數據源(如Message Queue、RDBMS、NoSQL、Realtime Log)不間斷地讀取數據併發送給Topology消息(tuple元組)。
Bolt:Storm中的消息處理者,用於為Topology進行消息的處理,Bolt可以執行過濾, 聚合, 查詢資料庫等操作,而且可以一級一級的進行處理。
最終,Topology會被提交到storm集群中運行;也可以通過命令停止Topology的運行,將Topology占用的計算資源歸還給Storm集群。
Storm數據流模型
數據流(Stream)是Storm中對數據進行的抽象,它是時間上無界的tuple元組序列。在Topology中,Spout是Stream的源頭,負責為Topology從特定數據源發射Stream;Bolt可以接收任意多個Stream作為輸入,然後進行數據的加工處理過程,如果需要,Bolt還可以發射出新的Stream給下級Bolt進行處理。
下麵是一個Topology內部Spout和Bolt之間的數據流關係:

Topology中每一個計算組件(Spout和Bolt)都有一個並行執行度,在創建Topology時可以進行指定,Storm會在集群內分配對應並行度個數的線程來同時執行這一組件。
那麼,有一個問題:既然對於一個Spout或Bolt,都會有多個task線程來運行,那麼如何在兩個組件(Spout和Bolt)之間發送tuple元組呢?
Storm提供了若幹種數據流分發(Stream Grouping)策略用來解決這一問題。在Topology定義時,需要為每個Bolt指定接收什麼樣的Stream作為其輸入(註:Spout並不需要接收Stream,只會發射Stream)。
目前Storm中提供了以下7種Stream Grouping策略:Shuffle Grouping、Fields Grouping、All Grouping、Global Grouping、Non Grouping、Direct Grouping、Local or shuffle grouping,具體策略可以參考這裡。
一種Storm不能支持的場景
以上介紹了一些Storm中的基本概念,可以看出,Storm中Stream的概念是Topology內唯一的,只能在Topology內按照“發佈-訂閱”方式在不同的計算組件(Spout和Bolt)之間進行數據的流動,而Stream在Topology之間是無法流動的。

這一點限制了Storm在一些場景下的應用,下麵通過一個簡單的實例來說明。
假設現在有一個Topology1的結構如下:通過Spout產生數據流後,依次需要經過Filter Bolt,Join Bolt,Business1 Bolt。其中,Filter Bolt用於對數據進行過濾,Join Bolt用於數據流的聚合,Business1 Bolt用於進行一個實際業務的計算邏輯。

目前這個Topology1已經被提交到Storm集群運行,而現在我們又有了新的需求,需要計算一個新的業務邏輯,而這個Topology的特點是和Topology1公用同樣的數據源,而且前期的預處理過程完全一樣(依次經歷Filter Bolt和Join Bolt),那麼這時候Storm怎麼來滿足這一需求?據個人瞭解,有以下幾種“曲折”的實現方式:
1) 第一種方式:首先kill掉已經在集群中運行的Topology1計算任務,然後實現Business2 Bolt的計算邏輯,並重新打包形成一個新的Topology計算任務jar包後,提交到Storm集群中重新運行,這時候Storm內的整體Topology結構如下:

這種方式的缺點在於:由於要重啟Topology,所以如果Spout或Bolt有狀態則會丟失掉;同時由於Topology結構發生了變化,因此重新運行Topology前需要對程式的穩定性、正確性進行驗證;另外Topology結構的變化也會帶來額外的運維開銷。
2) 第二種方式:完全開發部署一套新的Topology,其中前面的公共部分的Spout和Bolt可以直接復用,只需要重新開發新的計算邏輯Business2 Bolt來替換原有的Business1 Bolt即可。然後重新提交新的Topology運行。這時候Storm內的整體Topology結構如下:

這種方式的缺點在於:由於兩個Topology都會從External Data Source讀取同一份數據,無疑增加了External Data Source的負載壓力;而且會導致同樣的數據在Storm集群內被傳輸相同的兩份,被同樣的計算單元Bolt進行處理,浪費了Storm的計算資源和網路傳輸帶寬。假設現在不止有兩個這樣的Topology計算任務,而是有N個,那麼對Storm的計算Slot的浪費很嚴重。
註意:上述兩種方式還有一個公共的缺點——系統可擴展性不好,這意味著不管哪種方式,只要以後有這種新增業務邏輯的需求,都需要進行複雜的人工操作或線性的資源浪費現象。
3) 第三種方式:OK,看了以上兩種方式後,也許你會提出下麵的解決方案:通過Kafka這樣的消息中間件,實現不同Topology的Spout共用數據源,而且這樣可以做到消息可靠傳輸、消息rewind回傳等,好處是對於Storm來說,已經有了storm-kafka插件的支持。這時候Storm內的整體Topology結構如下:

這種實現方式可以通過引入一層消息中間件減少對External Data Source的重覆訪問的壓力,而且可以通過消息中間件層,屏蔽掉External Data Source的細節,如果需要擴展新的業務邏輯,只需要重新部署運行新的Topology,應該說是現有Storm版本下很好的實現方式了。不過消息中間件的引入,無疑將給系統帶來了一定的複雜性,這對於Storm上的應用開發來說提高了門檻。
值得註意的是,方案三中仍遺留有一點問題沒有解決:對於Storm集群來說,這種方式還是沒有能夠從根本上避免數據在Storm不同Topology內的重覆發送與處理。這是由於Storm的數據流模型上的限制所導致的,如果Storm實現了不同Topology之間Stream的共用,那麼這一問題也就迎刃而解了。
一個流處理系統的數據流模型
個人工作中有幸參與過一個流處理框架的開發與應用。下麵我們來簡單看看其中所採用的數據流模型:

其中:
1)數據流(data stream):時間分佈和數量上無限的一系列數據記錄的集合體;
2)數據記錄(data record):數據流的最小組成單元,每條數據記錄包括 3 類數據:所屬數據流名稱(stream name)、用於路由的數據(keys)和具體數據處理邏輯所需的數據(value);
3)數據處理任務定義(task definition):定義一個數據處理任務的基本屬性,無法直接被執行,必須特化為具體的任務實例。其基本屬性包括:
- (可選)輸入流(input stream):描述該任務依賴哪些數據流作為輸入,是一個數據流名稱列表;數據流產生源不會依賴其他數據流,可忽略該配置;
- 數據處理邏輯(process logic):描述該任務具體的處理邏輯,例如由獨立進程進行的外部處理邏輯;
- (可選)輸出流(output stream):描述該任務產生哪個數據流,是一個數據流名稱;數據流處理鏈末級任務不會產生新的數據流,可忽略該配置;
4)數據處理任務實例(task instance):對一個數據處理任務定義進行具體約束後,可推送到某個處理結點上運行的邏輯實體。附加下列屬性:
- 數據處理任務定義:指向該任務實例對應的數據處理任務定義實體;
- 輸入流過濾條件(input filting condition):一個 boolean 表達式列表,描述每個輸入流中符合什麼條件的數據記錄可以作為有效數據交給處理邏輯;若某個輸入流中所有數據記錄都是有效數據,則可直接用 true 表示;
- (可選)強制輸出周期(output interval):描述以什麼頻率強制該任務實例產生輸出流記錄,可以用輸入流記錄個數或間隔時間作為周期;忽略該配置時,輸出流記錄產生周期完全由處理邏輯自身決定,不受框架約束;
5)數據處理結點(node):可容納多個數據處理任務實例運行的實體機器,每個數據處理結點的IPv4地址必須保證唯一。
該分散式流處理系統由多個數據處理結點(node)組成;每個數據處理結點(node)上運行有多個數據任務實例(task instance);每個數據任務實例(task instance)屬於一個數據任務定義(task definition),任務實例是在任務定義的基礎上,添加了輸入流過濾條件和強制輸出周期屬性後,可實際推送到數據處理結點(node)上運行的邏輯實體;數據任務定義(task definition)包含輸入數據流、數據處理邏輯以及輸出數據流屬性。
該系統中,通過分散式應用程式協調服務ZooKeeper集群存儲以上數據流模型中的所有配置信息;不同的數據處理節點統一通過ZooKeeper集群獲取數據流的配置信息後進行任務實例的運行與停止、數據流的流入和流出。
同時,每個數據處理任務可以接受流系統中已存在的任意數據流(data stream)作為輸入,並產出新的任意名稱的數據流(data stream),被其他結點上運行的任務實例訂閱。不同結點之間對於各個數據流(data stream)的訂閱關係,通過ZooKeeper集群來動態感知並負責通知流系統做出變化。
二者在數據流模型上的不同之處
至於兩個系統的實現細節,我們先不去做具體比較,下麵僅列出二者在數據流模型上的一些不同之處(這裡並不是為了全面對比二者的不同之處,只是列出其中的關鍵部分):
1) 在Storm中,數據流Stream是在Topology內進行定義,併在Topology內進行傳輸的;而在上面提到的流處理系統中,數據流Stream是在整個系統內全局唯一的,可以在整個集群內被訂閱。
2) 在Storm中,數據流Stream的發佈和訂閱都是靜態的,所謂靜態是指數據流的發佈與訂閱關係在向Storm集群提交Topology計算任務時,被一次性生成的,這一關係在Topology的運行過程中是不能被改變的;而在上面提到的流處理系統中,數據流Stream的發佈和訂閱都是動態的,即數據處理任務task可以動態的發佈Stream,也可以動態的訂閱系統內已經生成的任意Stream,數據流的訂閱關於通過分散式應用程式協調服務ZooKeeper集群的動態節點來維護管理。
有了以上的對比,我們不難發現,對於本文所舉的應用場景實例,Storm的數據流模式尚不能很方便的支持,而在這裡提到的這個流處理系統的全局數據流模型下,這一應用場景的需求可以很方便的滿足。
1.什麼是Topology?
2.如何創建Topology?
3.Topology的worker數由誰來配置?
4.Topology中某個bolt的executor數由誰來指定?
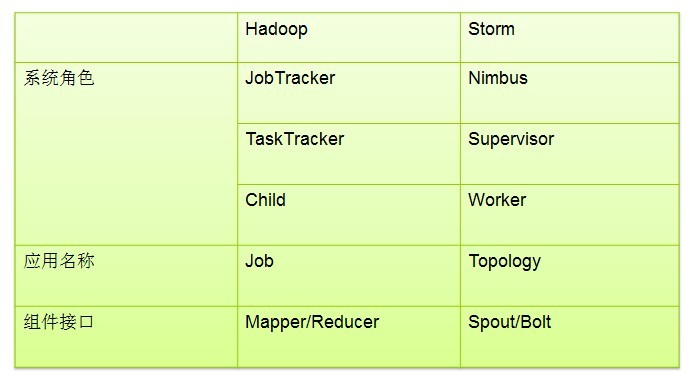
5.Supervisor、worker、Executor、Task、Spout、Bolt之間的關係?![]()
在創建Storm的Topology時,我們通常使用如下代碼:
builder.setBolt("cpp", new CppBolt(), 3).setNumTasks(5).noneGrouping(pre_name);
Config conf = new Config();
conf.setNumWorkers(3);
參數1:bolt名稱 "cpp"
參數2:bolt類型 CppBolt
參數3:bolt的並行數,parallelismNum,即運行topology時,該bolt的線程數
setNumTasks() 設置bolt的task數
noneGrouping() 設置輸入流方式及欄位
conf.setNumWorkers()設置worker數據。
經過多次試驗總結,得出如下結論:
1)Topology的worker數通過config設置,即執行該topology的worker(java)進程數。它可以通過storm rebalance 命令任意調整。
2) Topology中某個bolt的executor數,即parallelismNum,即執行該bolt的線程數,在setBolt時由第三個參數指定。它可以通過storm rebalance 命令調整,但最大不能超過該bolt的task數;
3) bolt的task數,通過setNumTasks()設置。(也可不設置,預設取bolt的executor數),無法在運行時調整。
4)Bolt實例數,這個比較特別,它和task數相等。有多少個task就會new 多少個Bolt對象。而這些Bolt對象在運行時由Bolt的thread進行調度。也即是說
builder.setBolt("cpp", new CppBolt(), 3).setNumTasks(5).noneGrouping(pre_name);
會創建3個線程,但有記憶體中會5個CppBolt對象,三個線程調度5個對象。
每台Supervisor上運行著若幹個worker進程,在Configure對象中可以配置worker的數量,conf.setNumWorkers(number);
每個Workder進行上運行著若幹個Executor執行線程,就是所謂的Task任務。
在TopologyBuilder對象中可以配置Task的數量,topologyBuilder.setNumTasks(number);這些Task任務指的是Spout或者Bolt任務。
在TopologyBuilder對象中可以配置Spout、Bolt的任務的數量。
topologyBuilder.setSpout(“spout tag name”,new XxSpout(),number);
topologyBuilder.setBolt(“bolt tag name”,new XxBolt(),number);
預設情況下# executor = #tasks即一個Executor中運行著一個Task。Spout或者Bolt的Task個數一旦指定之後就不能改變了,而Executor的數量可以根據情況來進行動態的調整。
一句話介紹,每台worker node上可以運行很多個worker,每個worker會開闢很多Executor線程來執行Task。在Storm看來,spout和bolt都是task。


