
目錄 環境準備 創建hadoop用戶 更新apt 配置SSH免密登陸 安裝配置Java環境 安裝Hadoop Hadoop單機/偽分佈配置 單機Hadoop 偽分佈Hadoop 啟動Hadoop 停止Hadoop 目錄 作者: vincent_zh時間:2016-10-16 出處:http://ww ...
目錄
作者: vincent_zh
時間:2016-10-16
出處:http://www.cnblogs.com/vincentzh/p/5967274.html
聲明:本文以學習、研究和分享為主,如需轉載,標明作者和出處,非商業用途!
環境準備
此處準備的環境是Virtual Box虛擬機下的Ubuntu14.04 64位系統,Hadoop版本為Hadoop2.6.0。裝好Hadoop運行的基礎Linux環境後,還需要做以下準備:
- 創建hadoop用戶;
- 更新apt;
- 配置SSH免密登陸;
- 安裝配置Java環境。
創建hadoop用戶
如果安裝系統時配置的並非是“hadoop”用戶,就需要新增加一個“hadoop”用戶。
1 $ sudo useradd -m hadoop -s /bin/bash
該命令創建新的“hadoop”用戶,並指定 /bin/bash 作為其shell。
如需更改hadoop用戶密碼,可通過如下命令進行:
1 $ sudo passwd hadoop
同樣,為避免後期安裝過程中的用戶許可權問題,可直接給“hadoop”用戶添加上管理員許可權:
1 $ sudo adduser hadoop sudo
之後,需切換到hadoop用戶下進行下麵操作。
更新apt
切換到hadoop用戶之後,需要先更新一下apt,後續需要通過apt安裝其他軟體,直接在命令行安裝會方便很多,如果沒有更新,一些軟體可能安裝不了。可參考以下命令進行更新:
1 $ sudo apt-get update
Linux 的編輯工具,當然非 vim 莫屬了,先裝上 vim 後期改參數配置文件時用的到。
1 $ sudo apt-get install vim
遇到命令行的 [ yes/no] 或者 [Y/N] 選項,直接yes進行安裝。
配置SSH免密登陸
單點/集群都需要安裝SSH。一方面是遠程登陸,可一再本機通過SSH直接連接虛擬機的系統,這樣也便於後期在Windows環境下使用 Eclipse 進行配置開發 MapReduce 程式;另一方面,在配置Hadoop集群時,集群工作過程中主機和從機、從機和從機之間都通過SSH進行授權登陸工作通信。Ubuntu系統預設已經安裝了SSH Client,需要額外安裝SSH Server。
1 $ sudo apt-get install openssh-server
首次登陸SSH會有首次登陸提示,鍵入yes,按提示輸入hadoop用戶密碼即可登陸。

配置免密登陸。一方面,我們通過ssh登陸時比較方便,不需重新輸入密碼;另一方面,在集群方式工作時,主機與從機通信過程或從機與從機之間進行文件備份時是需要越過密碼驗證這一環節的,所以需要提前生成公鑰,在集群工作時,可以直接自動登陸。
1 $ exit #推出剛剛登陸的 localhost 2 $ cd ~/.ssh #若無此目錄,請先進行一次ssh 登陸 3 $ ssh-keygen -t rsa #會有很多提示,全部回車即可 4 $ cat ./id_rsa.pub >> ./authorized_keys #將公鑰文件加入授權
再次通過 ssh 登陸就不需要輸入密碼了。
安裝配置Java環境
Java環境,Oracle JDK 和 OpenJDK都可以,此處直接通過命令安裝OpenJDK1.7(其中包含 jre 和 jdk):
1 $ sudo apt-get install openjdk-7-jre openjdk-7-jdk
配置環境變數:
安裝好JDK後,需要配置Java環境變數,通過以下命令尋找Java安裝路徑:
1 $ dpkg -L openjdk-7-jdk | grep '/bin/javac'
該命令會輸出一個路徑,除去路徑末尾的 “/bin/javac”,剩下的就是JDK的安裝路徑了。

在.bashrc文件中配置環境變數:
1 $ vi ~/.bashrc
需要在.bashrc文件中添加如下環境變數:

生效並檢驗環境變數配置是否正確:
1 $ source ./.bashrc #生效環境變數 2 $ echo $JAVA_HOME #查看環境變數 3 $ java -version 4 $ $JAVA_HOME/bin/java -version #驗證與java -version 輸出一致
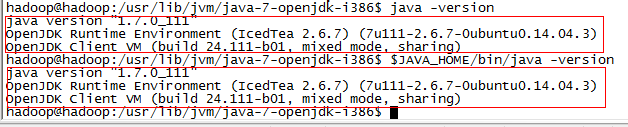
OK,Java環境安裝配置完成。
安裝Hadoop
通過http://mirrors.cnnic.cn/apache/hadoop/common/ 可下載Hadoop穩定版 hadoop-2.x.y.tar.gz 文件都是編譯好的,建議同時下載hadoop-2.x.y.tar.gz.mds,此mds文件是為了檢驗在下載和移動文件過程中文件的完整性。
通過驗證文件的md5值去檢驗文件的完整性:
1 $ cat ./hadoop-2.6.0.tar.gz.mds | grep 'MD5' 2 $ md5sum ./hadoop-2.6.0.tar.gz | tr 'a-z' 'A-Z'

文件驗證無誤,將文件解壓到安裝目錄:
1 $ cd /usr/lcoal #切換到壓縮文件所在目錄 2 $ sudo tar -zxf ./hadoop-2.6.0.tar.gz ./ #解壓文件 3 $ sudo mv ./hadoop-2.6.0 ./hadoop #將文件名改為較容易辨認的 4 $ chown -R hadoop ./hadoop #修改文件許可權
在.bashrc文件中配置hadoop相關環境變數:
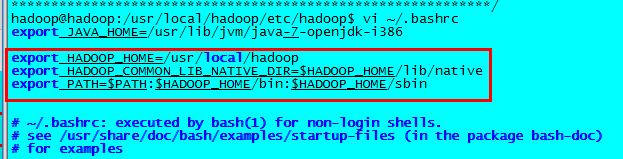
生效環境變數,並驗證Hadoop安裝成功。
1 $ source ~/.bashrc 2 $ hadoop version
Hadoop單機/偽分佈配置
單機Hadoop
Hadoop 預設模式為非分散式模式,無需進行其他配置即可運行。非分散式即單 Java 進程,方便進行調試。
註:單機、偽分佈、集群的區別:
單機:故名思意,Hadoop運行再單台伺服器上,並且此時的Hadoop讀取的是本地的文件系統,並沒有使用自己的HDFS。
偽分佈:單機版集群,單台伺服器既是NameNode,也是DataNode,並且也只有這一個DataNode,文件是從HDFS讀取。
集群:單機和偽分佈說了集群就簡單了。一般單獨分配一臺伺服器作為NameNode,並且NameNode一般不會同時配置為DataNode,DataNode一般在其他伺服器上,另外對大型集群,為體現Hadoop集群的高可用性,也會單獨設置一臺伺服器作為集群的SecondaryNameNode,也就是NameNode的備份,主要用於NameNode失效時的快速恢復。
偽分佈Hadoop
Hadoop 偽分散式的方式是在單節點上運行的,節點既作為 NameNode 也作為 DataNode,同時,讀取的是 HDFS 中的文件,Hadoop 進程以分離的 Java 進程來運行。
Hadoop 的配置文件位於 $HADOOP_HOME/etc/hadoop/ 中,偽分散式需要修改2個配置文件 core-site.xml 和 hdfs-site.xml 。Hadoop的配置文件是 xml 格式,每個配置以聲明 property 的 name 和 value 的方式來實現。另外如果要啟動YARN,需要再修改 mapred-site.xml 和 yarn-site.xml 兩個配置文件。
通過編輯器或 vim 對xml配置文件進行修改。
修改 core-site.xml 配置文件:
1 <configuration> 2 <property> 3 <name>hadoop.tmp.dir</name> 4 <value>file:/usr/local/hadoop/tmp</value> 5 <description>Abase for other temporary directories.</description> 6 </property> 7 <property> 8 <name>fs.defaultFS</name> 9 <value>hdfs://localhost:9000</value> 10 </property> 11 </configuration>
修改 hdfs-site.xml 配置文件:
1 <configuration> 2 <property> 3 <name>dfs.replication</name> 4 <value>1</value> 5 </property> 6 <property> 7 <name>dfs.namenode.name.dir</name> 8 <value>file:/usr/local/hadoop/tmp/dfs/name</value> 9 </property> 10 <property> 11 <name>dfs.datanode.data.dir</name> 12 <value>file:/usr/local/hadoop/tmp/dfs/data</value> 13 </property> 14 </configuration>
修改 mapred-site.xml 配置文件:
1 <configuration> 2 <property> 3 <name>mapreduce.framework.name</name> 4 <value>yarn</value> 5 </property> 6 </configuration>
修改 yarn-site.xml 配置文件:
1 <configuration> 2 <property> 3 <name>yarn.nodemanager.aux-services</name> 4 <value>mapreduce_shuffle</value> 5 </property> 6 </configuration>
啟動Hadoop
配置完成,首次啟動Hadoop時需要對NameNode格式化:
1 $ hdfs namenode -format
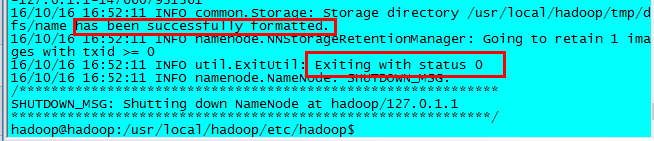
有這兩個標誌,則表示配置沒問題,namenode已經格式化,可以啟動Hadoop了。如果格式化錯誤,需要檢查配置文件配置是否正確,最常見的問題就是配置文件里的拼寫錯誤。
啟動守護進程:
1 $ start-dfs.sh #啟動hdfs,含NameNode、DataNode、SecondaryNameNode守護進程 2 $ start-yarn.sh #啟動yarn,含ResourceManager、NodeManager 3 $ mr-jobhistory-daemon.sh start historyserver #開啟歷史伺服器,才能在Web中查看任務運行情況
守護進程的啟動情況可通過 jps 命令查看,查看所有的守護進程是否都正常啟動。如果有未啟動的守護進程,需要去 $HADOOP_HOME/logs 目錄查看對應的守護進程啟動的日誌查找原因。
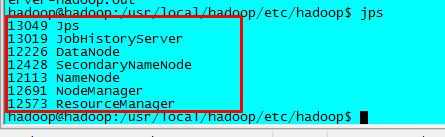
成功啟動所有守護進程之後,通過Web界面 http://server_ip/50070 查看NameNode 和 DataNode 的信息,還可以線上查看HDFS文件。
YRAN啟動之後(即 ResourceManager 和 NodeManager),也可以通過 http://server_ip/8088 查看管理資源調度,和查看Job的執行情況。
停止Hadoop
1 $ stop-dfs.sh 2 $ stop-yarn.shResourceManager、NodeManager 3 $ mr-jobhistory-daemon.sh stop historyserver
Note:Hadoop常用的伺服器管理命令腳本都可以在 $HADOOP_HOME/bin 和 $HADOOP_HOME/sbin 目錄中找到。

