
序列 延遲查詢執行 查詢操作符 查詢表達式 表達式樹 (一) 序列 先上一段代碼, 這段代碼使用擴展方法實現下麵的要求: 取進程列表,進行過濾(取大於10M的進程) 列表進行排序(按記憶體占用) 只保留列表中指定的信息(ID,進程名) 為了能清楚理解上面代碼的內部動作,我們需要介紹幾組概念. 1. I ...
- 序列
- 延遲查詢執行
- 查詢操作符
- 查詢表達式
- 表達式樹
(一) 序列
先上一段代碼,
這段代碼使用擴展方法實現下麵的要求:
- 取進程列表,進行過濾(取大於10M的進程)
- 列表進行排序(按記憶體占用)
- 只保留列表中指定的信息(ID,進程名)
1 var res = Process.GetProcesses() 2 .Where(s => s.WorkingSet64 > 10 * 1024 * 1024) 3 .OrderByDescending(s => s.WorkingSet64) 4 .Select(s => new { ID = s.Id, Name = s.ProcessName });
為了能清楚理解上面代碼的內部動作,我們需要介紹幾組概念.
1. IEnumerable<T>介面
Process.GetProcesses()的返回值是一個Process的數組,而在C#中,所有數組對象均實現了IEnumerable<T>介面.

IEnumerable<T>介面之所以重要,是因為 上面代碼中的Where, OrderByDescending, Select 等LINQ中的標準查詢操作符都需要使用該類型的對象做為參數.
那麼,上面代碼中的Where, OrderByDescending, Select 是哪裡來的呢? 它們是擴展方法, 基於IEnumerable<T>介面類型的擴展方法.
在LINQ中, 術語"序列" 就是指所有實現了IEnumerable<T>介面的對象.
我們給出Where擴展方法的實現代碼:
1 public static IEnumerable<TSource> Where<TSource>( 2 this IEnumerable<TSource> source, 3 Func<TSource, Boolean> predicate) 4 { 5 foreach (TSource element in source) 6 { 7 if (predicate(element)) 8 yield return element; 9 } 10 }
其第一參數中的this關鍵字就證明瞭它是一個擴展方法,參數類型就是IEnumerable<T>.
關鍵字yield return 就構成了一個迭代器.
我們來看一下迭代器的背景知識.
2. 迭代器
從結果的角度看,迭代器與一個返回集合數據的傳統方法沒有什麼區別,因為都是返回按一序列排列的值.
比如下麵的代碼,就返回一個集合的值.
1 int[] OneTwoThree() 2 { 3 return new[] { 1, 2, 3 }; 4 }
不過,C#中的迭代器的行為卻非常特殊.迭代器將不會一次性返回整個集合中的所有值.而是每次返回一個.這樣的設計減少了記憶體需求.
我們構建一個迭代器的例子,看一看這個特性.
1 private void button2_Click(object sender, EventArgs e) 2 { 3 foreach (var m in OneTwoThree()) 4 { 5 Console.WriteLine(m); 6 } 7 } 8 static IEnumerable<int> OneTwoThree() 9 { 10 Console.WriteLine("returning 1"); 11 yield return 1; 12 Console.WriteLine("returning 2"); 13 yield return 2; 14 Console.WriteLine("returning 3"); 15 yield return 3; 16 }
運行結果如下圖
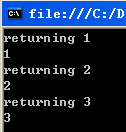
可以看到,函數OneTwoThree直到執行完最後一條語句之後才完整退出.
每次遇到yield return語句時,該方法都向調用者返回一個值.
foreach迴圈收到這個值後進行了處理,然後控制權又交回給迭代器方法OneTwoThree方法,由它給出下一個元素.
看起來好像兩個方法在同時運行.這也正是可以將.NET中的迭代器當作是一類輕量級的協同程式(coroutine)的原因.
(二) 延遲查詢執行
LINQ查詢語句非常依賴於延遲查詢執行機制,惹是缺少了這個機制,LINQ的執行效率將會大大降低.
來看一段代碼:
1 static double Square(double n) 2 { 3 Console.WriteLine("計算 Square(" + n + ")..."); 4 return Math.Pow(n, 2); 5 } 6 private void button3_Click(object sender, EventArgs e) 7 { 8 int[] numbers = { 1, 2, 3 }; 9 var res = from n in numbers 10 select Square(n); 11 foreach (var m in res) 12 Console.WriteLine(m); 13 }
運行結果如下:

結果可以看到,明顯該查詢並不是一次性執行完畢的.只有在迭代到某一項時,查詢才開始求出這一項的值.
這就是所謂的查詢延遲執行的機制在發揮作用.
我們來討論一下其中的原理:
var res = from n in numbers select Square(n);
上面的LINQ查詢在編譯後,實際上變成了這樣的:
IEnumerable<double> res = Enumerable.Select<int, double>(numbers, n => Square(n));
也就是LINQ查詢轉為一系列擴展方法的調用,其中的Enumerable.Select方法正是一個迭代器--這也就是其實現了延遲執行的原理.
如果我們需要查詢強制立即執行,可以通過調用ToList方法來實現.
我們把上面的代碼改動一下:
1 private void button4_Click(object sender, EventArgs e) 2 { 3 int[] numbers = { 1, 2, 3 }; 4 var res = from n in numbers 5 select Square(n); 6 foreach (var m in res.ToList()) 7 Console.WriteLine(m); 8 }
可以看到結果就不同了:

可以見到是先得到查詢的結果,最後才把結果迭代輸出的.
(三) 查詢操作符
上面代碼所示的 Where,OrderByDescending, Select這些擴展方法 包含有共同的特性:
- 操作於可被迭代的集合對象之上
- 允許管道形式的數據處理
- 依賴於延遲執行
正是上面這些特征讓這些擴展方法能用於編寫查詢.因此這些擴展方法也稱為"查詢操作符"
查詢操作符是LINQ的核心,甚至比語言方面的特性(比如查詢表達式)更重要.
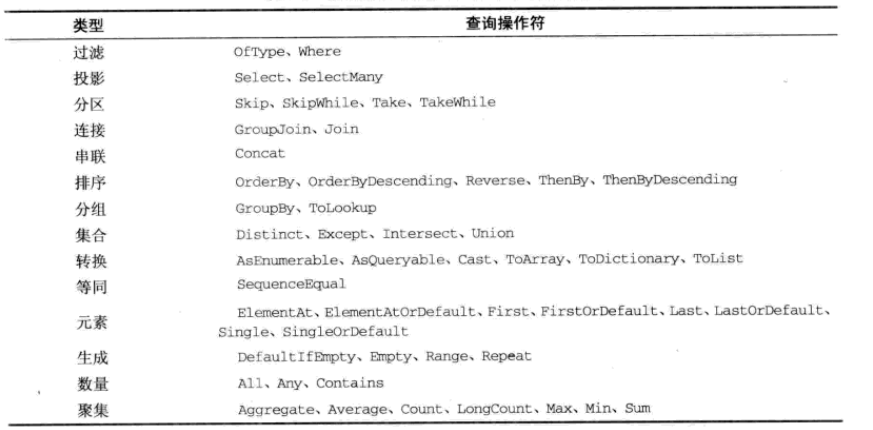
下圖是按照操作類型分組的標準查詢操作符:
(四) 查詢表達式
開往篇的程式是使用查詢操作符實現的.再次引用一下:
1 var res = Process.GetProcesses() 2 .Where(s => s.WorkingSet64 > 10 * 1024 * 1024) 3 .OrderByDescending(s => s.WorkingSet64) 4 .Select(s => new { ID = s.Id, Name = s.ProcessName });
另一種語法則讓LINQ查詢更像是SQL的查詢語句.
1 var res = from s in Process.GetProcesses() 2 where s.WorkingSet64 > 10 * 1024 * 1024 3 orderby s.WorkingSet64 descending 4 select new { ID = s.Id, Name = s.ProcessName };
上面的這種寫法就叫做查詢表達式,或者查詢式語法.
這兩種代碼的寫法從語義上來講是完全相同的,而且實現的功能也一致.
查詢表達式是由C#語言提供的語言級特性,一種語法糖,這種語法類似於SQL,它可以操作於一個或者多個數據源之上,併為這些數據源應用若幹個標準或者自定義的查詢操作符.在上面的示例代碼中,使用了3個標準的查詢操作符:Where, orderByDescending以及Select.
在使用查詢表達式語法時,編譯器會自動將其轉化為對標準查詢操作符的調用.
查詢表達式存在的最主要意義在於,它能夠大大簡化查詢所需要的代碼,並提高查詢語句的可讀性(類似熟悉的SQL).
下圖是查詢表達式的完整語法:

標準查詢操作符與查詢表達式的關係,見下表所示:


通過上表可以看到,不是每一個操作符都有與之對應的C#關鍵字.在前面那個簡單的查詢中,我們當然完全可以使用語言所提供的關鍵字實現.不過對於那些較為複雜的查詢來說,我們將不得不直接調用查詢操作符完成.
因為查詢表達式最終都會被編譯成各個標準操作符的調用.因此如果願意的話,完全可以只用查詢操作符編寫所有查詢語句,根本不理會查詢表達式的存在.
(五) 表達式樹
Lambda表達式在前面提到過它的主要作用之一是實現匿名委托.如下例:
Func<int,bool> isOdd=i=>(i & 1)==1;
但是,Lambda表達式也能夠以數據的形式使用,這正是表達式樹所要求的.
當把代碼改成下麵這樣時,我們就無法以委托的形式來使用isOdd了.因為在這裡isOdd並不是委托,而是個表達式樹.
Expression<Func<int,bool>> isOdd =i => (i & 1) ==1;
編譯器不會把上面的Lambda表達式換成IL代碼,而是會構造出一個樹狀的,用來表示該表達式的對象.
但是需要註意的是:只有那些帶有表達式體的Lambda表達式才能夠用於表達式樹.主體部分是語句的Lambda表達式則沒有類似的支持.
例如,下麵第1行代碼可以用來生成一顆表達式樹,因為其帶有表達式體.
第2行的就不能,因為它的主體部分是一個語句.
1 Expression<Func<Object, Object>> identity = o=>o; 2 Expression<Func<Object, Object>> identity = o=>{ return o;};
當編譯器看到某個Lambda表達式賦值給類型為Expression<>的變數時,就會將其編譯成一系列工廠方法的調用,這些工廠方法將在程式運行時動態地構造出表達式樹.
下麵就是編譯器為上述表達式自動生成的代碼:
1 ParameterExpression i = Expression.Parameter(typeof(int), "i"); 2 Expression<Func<int, bool>> isOdd = 3 Expression.Lambda<Func<int, bool>>( 4 Expression.Equal( 5 Expression.And( 6 i, 7 Expression.Constant(1, typeof(int))), 8 Expression.Constant(1, typeof(int))), 9 new ParameterExpression[] { i });
上面的代碼是可以手工編寫的,但是編譯器可以代勞.
表達式樹將在程式運行中動態構造,不過一旦構造完成,則無法被再次修改.
表達式樹在第5章中用以創建動態查詢這種高級場景上得到了應用.
上面的表達式樹,在記憶體中以樹的數據結構存儲,它表示解析了後的Lambda表達式,如下圖:

上面的表達式樹,還可以"逆向"編譯成委托方法:
1 Expression<Func<int, bool>> isOddExpression = i => (i & 1) == 1; 2 Func<int, bool> isOddCompiledExpression = isOddExpression.Compile();
這時候,上面的isOddCompiledExpression和下麵的委托isOdd就完全相同了,它們生成的IL代碼就沒有任何區別了.
Func<int,bool> isOdd=i=>(i & 1)==1;
為什麼要使用表達式樹呢?
實際上,表達式樹就是一顆抽象語法樹(AST).抽象語法樹用來表示一段經過解析的代碼.在上面例子中,這顆樹就是C#對於Lambda表達式解析後的結果.這樣做的目的是便於其它代碼對該表達式樹進行分析,並執行一些必要的操作.
表達式樹可以在運行時傳遞給其它的工具,隨後這些工具可以根據該樹開始執行查詢,或者是將其轉化為其它形式的代碼,例如LINQ to SQL中的SQL語句.
最後我們來看看表達式樹執行延遲查詢執行的方法:
引用之前LINQ to SQL例子中的代碼:
1 var contacts = 2 from contact in db.GetTable<HelloLinqToSql.Contact>() 3 where contact.City == "武漢" 4 select contact; 5 6 Console.WriteLine("查找在武漢的聯繫人"+Environment.NewLine); 7 foreach (var contact in contacts) 8 Console.WriteLine("聯繫人: " + contact.Name.Trim()+" ID:"+contact.ContactID);
我們知道使用IEnumerable<T>迭代器可以產生延遲查詢的行為,在上面代碼中 contacts變數的類型不是IEnumerable<T>,而是IQueryable<Contact>.
處理IQueryable<Contact>數據與處理序列完全不同.IQueryable<Contact>的實例將要接受一棵表達式樹,由些分析出下一步將要進行的操作.
在上面代碼中,一旦我們開始遍歷contacts變數,那麼程式就會開始分析其中包含的表達式樹,隨後生成SQL語句並執行,最後該SQL語句的返回結果以Contact對象集合的形式給出.
與基於IEnumerable<T>的序列相比, IQueryable<Contact>更加強大,因為程式可以根據表達式樹的分析結果進行智能地處理.通過查看某個查詢的表達式樹,編譯器即可智能地進行推斷併進行大量的優化.IQueryable<Contact>和表達式樹的組合將給我們帶來更強大的可定製能力.
原創文章,出自"博客園, 豬悟能'S博客" : http://www.cnblogs.com/hackpig/

