
彙編器構造 一、 彙編器簡介 前面介紹了編譯器構造和靜態鏈接器構造的具體方法,而且我們實現了一個將高級語言轉化為彙編語言的編譯器,同時又實現了一個將多個目標文件鏈接為一個可執行文件的鏈接器。現在需要一個連接這兩個模塊的功能模塊——彙編器,它能將一個單獨的彙編文件轉換為一個可重定位目標文件,如圖1-1 ...
彙編器構造
一、 彙編器簡介
前面介紹了編譯器構造和靜態鏈接器構造的具體方法,而且我們實現了一個將高級語言轉化為彙編語言的編譯器,同時又實現了一個將多個目標文件鏈接為一個可執行文件的鏈接器。現在需要一個連接這兩個模塊的功能模塊——彙編器,它能將一個單獨的彙編文件轉換為一個可重定位目標文件,如圖1-1反映出彙編器在整個編譯系統中的地位和功能。

圖 1-1 靜態編譯步驟
從本質上講,彙編器也是編譯器,只是它和我們熟知的編譯器的有略微的差別。彙編器處理的“高級語言”是彙編語言,輸出的是機器語言二進位形式。因此,對於彙編器的構造,實質上和編譯器大同小異,也都需要進行詞法分析、語法分析、語義處理、符號表管理和代碼生成(機器代碼)等階段。
對於編譯器來說,代碼生成階段只需要將解析的語法樹映射到彙編語言子模塊即可(當然還要考慮指令優化問題),而對於彙編器,將解析出的指令簡潔的映射到正確機器代碼相對比較複雜。另外,由於本彙編器處理的輸入文件為編譯器生成的彙編文件,經測試,編譯生成的彙編文件是正確的彙編文件,因此彙編器不需要考慮源文件會產生錯誤,因此它的語法分析的目的是識別出輸入語言的語法結構併進行解析引導機器代碼生成。
另外,彙編器和編譯器最大的不同是:彙編語言允許符號後置定義,因此通過一遍掃描無法保證獲得某個符號的準確定義信息,所以對於彙編器必須採用兩邊掃描的方式進行設計,彙編器的設計結構如圖1-2所示。
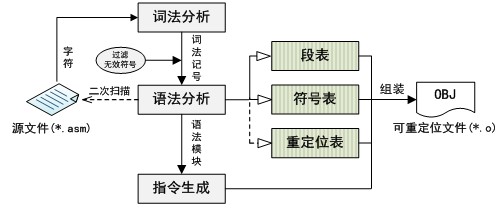
圖1-2 彙編器結構
從圖中可以看出彙編器的設計中,在語法分析模塊之前和前述編譯器的結構完全相同,只是語法分析時要進行兩遍的掃描過程,通過第一遍掃描獲取文件定義的所有的段的信息以及全部的符號信息,第二遍掃描根據最新的段表和符號表,將所有的重定位信息收集到重定位表中,然後通過指令生成模塊生成了代碼段數據。最後,從符號表中抽取有效數據定義形成數據段,符號導出到文件符號表段,再把所有的段按照elf文件的格式組裝起來,形成最終的可重定位目標文件*.o。下麵就按照上述路程具體說明彙編器設計的內容。
二、 文法定義
和編譯器設計過程相同,首先必須明確處理彙編語言的文法定義,按照符合LL(1)文法的規則定義的待處理彙編語言的文法如表2-1所示:
表2-1 彙編文法
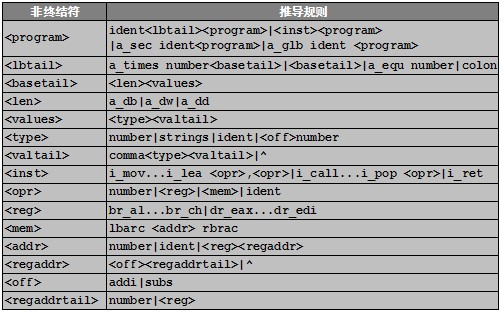
上述彙編文法可以識別之前編譯器生成的所有代碼,從文法定義中,可以看出彙編語言的功能主要如下:
(1)支持段聲明,全局符號聲明,數據定義db|dw|dd,times關鍵字和equ巨集命令。
(2)支持數據為整數和字元串格式,允許定義中引用符號,數據使用逗號分隔。
(3)支持的指令數:雙操作數指令5條,單操作數指令17條,無操作數指令1條。
(4)支持定址模式:寄存器定址,立即定址,寄存器間址,間接定址,基址+偏移定址,基址+變址定址。
明確彙編語言的文法後就可以構造分析程式識別語言的語法結構。
三、 詞法分析
彙編器的詞法分析過程和編譯器相同,也需要掃描器和解析器,區別在於字母表和詞法記號的差別。彙編語言的詞法記號如表3-1所示。
表 3-1 詞法記號
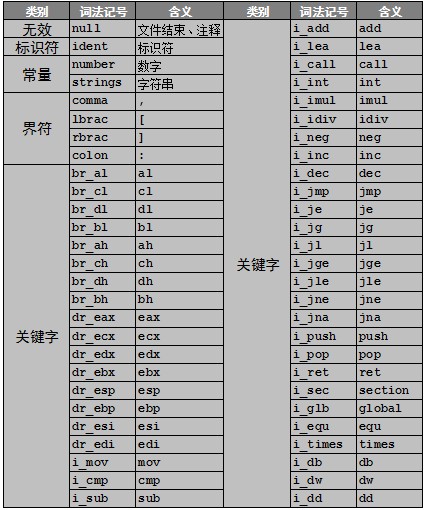
從詞法記號表中可以看出彙編語言詞法記號的變化:
(1)標識符可以用符號‘@’開頭。
(2)增加一部分界符‘[’,‘]’,‘:’。
(3)刪除了一部分界符‘*’,‘/’,‘=’,‘>’,‘<’,‘!’,‘;’,‘(’,‘)’,‘{’,‘}’。
(4)註釋由分號引導的單行註釋。
(5)關鍵字表有重大變化,所有的彙編助記符、寄存器、彙編器操作符都是關鍵字。
很明顯,隨著彙編語法結構的相對簡化,詞法記號的識別的複雜度也有所降低。另外由於由編譯器生成的彙編語言文件是經過測試正確的,因此不需要進行異常處理。
四、 語法分析
語法分析是彙編器設計的核心,從圖1-2就可以看出語法分析模塊的重要地位。彙編器的語法分析模塊不需要進行錯誤處理和修複的操作,但是必須正確識別並處理每一個關鍵的語法模塊。彙編語言有兩大類型的語法模塊:數據和指令。數據語法模塊要能識別所有類型的符號並存儲到符號表,供指令模塊和重定位表使用。指令語法模塊要填充臨時數據結構,供指令生成模塊生成正確的操作碼和操作數二進位信息。
簡單的說,語法分析的目的是填充系統需要的三張表:段表、符號表、重定位表。通過第一遍掃描將輸入文件的所有的段信息收集到段表中,所有的符號信息收集到符號表中,然後第二面掃描在產生重定位的地方生成重定位項,填充重定位表。這三張表是輸出文件信息的核心,下邊就按照這三張表的構造流程逐個說明。
4.1 段表
彙編語言使用section關鍵字聲明段開始,直到下一個段聲明或者文件結束位置結束,整個中間部分都屬於section聲明的段的內容。具體的說,由於編譯器生成的彙編文件共有三個段:.text,.data,.bss。又因為我們使用兩邊掃描源文件的方式,因此,在第二遍掃描之前(第一遍.bss段結束後)彙編器就可以獲得所有的段信息。參考鏈接器設計中elf文件Elf32_Shdr的數據結構可以看出段表項信息的最關鍵的信息是:段名、偏移、大小。段名在每次section聲明時候記錄下來即可,偏移計算之前必須知道上一個段的大小,因此段的大小計算是關鍵中的關鍵。為此彙編器使用一個全局變數curAddr記錄了相對於當前段的起始偏移,每次彙編語言定義一個需要地址空間存儲的語法模塊,這個curAddr就會累加當前語法模塊的大小,直到段聲明結束時記錄了整個段的大小。至於每個語法模塊的大小如何計算,在後邊符號表中再具體介紹。另外,由於.bss的特殊性,它的物理大小為0,但是虛擬大小需要計算。比如編譯器只使用.bss存儲了輔助棧供64k位元組,因此虛擬大小為64k,但是占用磁碟空間大小為0。
另外還需要註意的是段的偏移並不是簡單的累加段的大小計算,因為還涉及另一個概念——段對齊。這裡和鏈接器類似,段的開始位置必須是一個數的整數倍(一般重定位目標文件是按照4位元組對齊),因此在每次累加段偏移的時候需要考慮段對齊的影響。圖4-1給出了一個構造段表項一個例子:
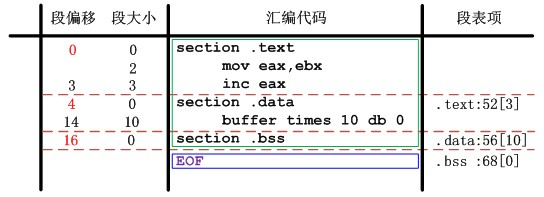
圖4-1 段表構造實例
下麵給出了段表項的相關代碼:
void Table::switchSeg(){
if(scanLop==1)
{
dataLen+=(4-dataLen%4)%4;
obj.addShdr(curSeg,lb_record::curAddr);//新建一個段
if(curSeg!=".bss")
dataLen+=lb_record::curAddr;
}
curSeg="";curSeg+=id;//切換下一個段名
lb_record::curAddr=0;//清0段偏移
}
void Elf_file::addShdr(string sh_name,int size)
{
int off=52+dataLen;
if(sh_name==".text")
{
addShdr(sh_name,SHT_PROGBITS,SHF_ALLOC|SHF_EXECINSTR,0,off,size,0,0,4,0);
}
else if(sh_name==".data")
{
addShdr(sh_name,SHT_PROGBITS,SHF_ALLOC|SHF_WRITE,0,off,size,0,0,4,0);
}
else if(sh_name==".bss")
{
addShdr(sh_name,SHT_NOBITS,SHF_ALLOC|SHF_WRITE,0,off,size,0,0,4,0);
}
}
函數switchSeg在每次段聲明的位置被調用,但是只是在第一次掃描時候生成段表項,每次調用後都會記錄當前段名到curSeg,並清零curAddr。dataLen記錄了當前的段偏移,添加段表項之前都會將之按照4位元組對齊後在加上52(elf文件頭大小)作為真正的段偏移添加到段表。另外,.bss段聲明結束後是不累加段偏移的,這就反映了.bss無物理空間的含義。最後,addShdr按照段名分別生成具體的段表項,記錄到段表。
4.2 符號表
符號表是所有表中最重要的,段表使用它計算自身大小,重定位需要它識別重定位符號,最終的數據段和符號表段還需要符號表進行導出。符號表相關的有三個最重要的數據結構:lb_record,Inst和Table。顧名思義,lb_record記錄了當前分析出來的符號,Inst記錄了當前分析出來的指令,Table是對所有符號的記錄,即傳統意義上的符號表,不過這裡把Inst也作為符號表數據結構的一部分看待。下麵首先給出這三種數據結構的定義:
首先說明符號數據結構:
struct lb_record//符號聲明記錄{
static int curAddr;//一個段內符號的偏移累加量
string segName;//隸屬於的段名,三種:.text .data .bss
string lbName;//符號名
bool isEqu;//是否是L equ 1
bool externed;//是否是外部符號,內容是1的時候表示為外部的,此時curAddr不累加
int addr;//符號段偏移
int times;//定義重覆次數
int len;//符號類型長度:db-1 dw-2 dd-4
int *cont;//符號內容數組
int cont_len;//符號內容長度
lb_record(string n,bool ex);//L:或者創建外部符號(ex=true:L dd @e_esp)
lb_record(string n,int a);//L equ 1
lb_record(string n,int t,int l,int c[],int c_l);//L times 5 dw 1,"abc",L2 或者 L dd 23
void write();//輸出符號內容
};
(1) curAddr:當前段偏移的靜態變數。
(2) segName:符號隸屬於的段名。
(3) lnName:符號名。
(4) isEqu:符號是否是equ定義的常量。
(5) externed:符號是否是外部符號。
(6) addr:符號的段偏移,若isEqu為true則表示符號的值。
(7) times:符號定義重覆次數,不帶times關鍵字預設為1,equ和外部符號為0。
(8) len:符號類型長度,db,dw,dd分別為1,2,4位元組,無類型為0。
(9) cont


