
本篇文章就要根據源碼分析 SparkContext 所做的一些事情,用過Spark的開發者都知道SparkContext是編寫Spark程式用到的第一個類,足以說明SparkContext的重要性;這裡先摘抄SparkContext源碼註釋來 簡單介紹介紹SparkContext,註釋的第一句話就是 ...
本篇文章就要根據源碼分析SparkContext所做的一些事情,用過Spark的開發者都知道SparkContext是編寫Spark程式用到的第一個類,足以說明SparkContext的重要性;這裡先摘抄SparkContext源碼註釋來 簡單介紹介紹SparkContext,註釋的第一句話就是說SparkContext為Spark的主要入口點,簡明扼要,如把Spark集群當作服務端那Spark Driver就是客戶端,SparkContext則是客戶端的核心;如註釋所說 SparkContext用於連接Spark集群、創建RDD、累加器(accumlator)、廣播變數(broadcast variables),所以說SparkContext為Spark程式的根本都不為過,這裡使用的Spark版本為2.0.1;
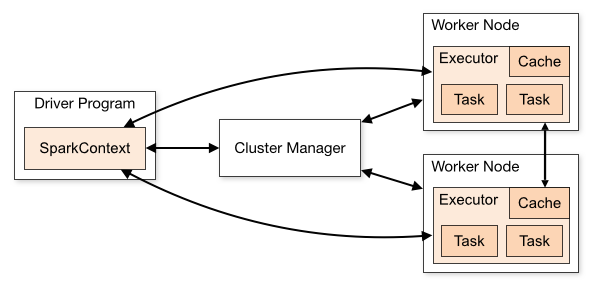
圖片來自Spark官網,可以看到SparkContext處於DriverProgram核心位置,所有與Cluster、Worker Node交互的操作都需要SparkContext來完成;
SparkContext相關組件
1、SparkConf
SparkConf為Spark配置類,配置已鍵值對形式存儲,封裝了一個ConcurrentHashMap類實例settings用於存儲Spark的配置信息;配置項包括:master、appName、Jars、ExecutorEnv等等;
2、SparkEnv
SparkEnv可以說是Context中非常重要的類,它維護著Spark的執行環境,包含有:serializer、RpcEnv、block Manager、map output tracker、etc等;所有的線程都可以通過SparkCotext訪問到同一個SparkEnv對象;SparkContext通過SparkEnv.createDriverEnv創建SparkEnv實例;在SparkEnv中包含瞭如下主要對象:
SecurityManager:用於對許可權、賬號進行管理、Hadoop YARN模式下的證書管理等;
RpcEnv:為Rpc環境的封裝,之前使用的是Akka現在預設已經使用了Netty作為Spark的Rpc通信框架,Spark中有RpcEnvFactory trait特質預設實現為NettyRpcEnvFactory,在Factory中預設使用了Jdk的Serializer作為序列化工具;
SerializerManager:用於管理Spark組件的壓縮與序列化;
BroadcastManager:用與管理廣播對象,預設使用了TorrentBroadcastFactory廣播工廠;
MapOutputTracker:跟蹤Map階段結果的輸出狀態,用於在reduce階段獲取地址與輸出結果,如果當前為Driver則創建MapOutputTrackerMaster對象否則創建的是MapOutputTrackerWorker兩者都繼承了MapOutputTracker類;
ShuffleManager:用於管理遠程和本地Block數據shuffle操作,預設使用了SortShuffleManager實例;
MemoryManager:用於管理Spark的記憶體使用策略,有兩種模式StaticMemoryManager、UnifiedMemoryManager,第一種為1.6版本之前的後面那張為1.6版本時引入的,當前模式使用第二種模式;兩種模式區別為粗略解釋為第一種是靜態管理模式,而第二種為動態分配模式,execution與storage之間可以相互“借”記憶體;
BlockTransferService:塊傳輸服務,預設使用了Netty的實現,用於獲取網路節點的Block或者上傳當前結點的Block到網路節點;
BlockManagerMaster:用於對Block的協調與管理;
BlockManager:為Spark存儲系統重要組成部分,用於管理Block;
MetricsSystem:Spark測量系統;
3、LiveListenerBus
非同步傳遞Spark事件監聽與SparkListeners監聽器的註冊;
4、JobProgressListener
JobProgressListener監聽器用於監聽Spark中任務的進度信息,SparkUI上的任務數據既是該監聽器提供的,監聽的事件包括有,Job:active、completed、failed;Stage:pending、active、completed、skipped、failed等;JobProgressListener最終將註冊到LiveListenerBus中;
5、SparkUI
SparkUI為Spark監控Web平臺提供了Spark環境、任務的整個生命周期的監控;
6、TaskScheduler
TaskScheduler為Spark的任務調度器,Spark通過他提交任務並且請求集群調度任務;TaskScheduler通過Master匹配部署模式用於創建TashSchedulerImpl與根據不同的集群管理模式(local、local[n]、standalone、local-cluster、mesos、YARN)創建不同的SchedulerBackend實例;
7、DAGScheduler
DAGScheduler為高級的、基於stage的調度器,為提交給它的job計算stage,將stage作為tasksets提交給底層調度器TaskScheduler執行;DAGScheduler還會決定著stage的最優運行位置;
8、ExecutorAllocationManager
根據負載動態的分配與刪除Executor,可通過ExecutorAllcationManager設置動態分配最小Executor、最大Executor、初始Executor數量等配置,調用start方法時會將ExecutorAllocationListener加入到LiveListenerBus中監聽Executor的添加、移除等;
9、ContextClearner
ContextClearner為RDD、shuffle、broadcast狀態的非同步清理器,清理超出應用範圍的RDD、ShuffleDependency、Broadcast對象;清理操作由ContextClearner啟動的守護線程執行;
10、SparkStatusTracker
低級別的狀態報告API,對job、stage的狀態進行監控;包含有一個jobProgressListener監聽器,用於獲取監控到的job、stage事件信息、Executor信息;
11、HadoopConfiguration
Spark預設使用HDFS來作為分散式文件系統,HadoopConfigguration用於獲取Hadoop配置信息,通過SparkHadoopUtil.get.newConfiguration創建Configuration對象,SparkHadoopUtil 會根據SPARK_YARN_MODE配置來判斷是用SparkHadoopUtil或是YarnSparkHadoopUtil,創建該對象時會將spark.hadoop.開頭配置都複製到HadoopConfugration中;
簡單總結
以上的對象為SparkContext使用到的主要對象,可以看到SparkContext包含了Spark程式用到的幾乎所有核心對象可見SparkContext的重要性;創建SparkContext時會添加一個鉤子到ShutdownHookManager中用於在Spark程式關閉時對上述對象進行清理,在創建RDD等操作也會判斷SparkContext是否已stop;
通常情況下一個Driver只會有一個SparkContext實例,但可通過spark.driver.allowMultipleContexts配置來允許driver中存在多個SparkContext實例;
參考資料:
http://spark.apache.org/docs/latest/
文章首發地址:Solinx
http://www.solinx.co/archives/643


