
這一篇首先從allitebooks.com里抓取書籍列表的書籍信息和每本書對應的ISBN碼。 一、分析需求和網站結構 allitebooks.com這個網站的結構很簡單,分頁+書籍列表+書籍詳情頁。 要想得到書籍的詳細信息和ISBN碼,我們需要遍歷所有的頁碼,進入到書籍列表,然後從書籍列表進入到每本 ...
這一篇首先從allitebooks.com里抓取書籍列表的書籍信息和每本書對應的ISBN碼。
一、分析需求和網站結構
allitebooks.com這個網站的結構很簡單,分頁+書籍列表+書籍詳情頁。 要想得到書籍的詳細信息和ISBN碼,我們需要遍歷所有的頁碼,進入到書籍列表,然後從書籍列表進入到每本書的詳情頁里,這樣就能夠抓取詳情信息和ISBN碼了。
二、從分頁里遍歷每一頁書籍列表
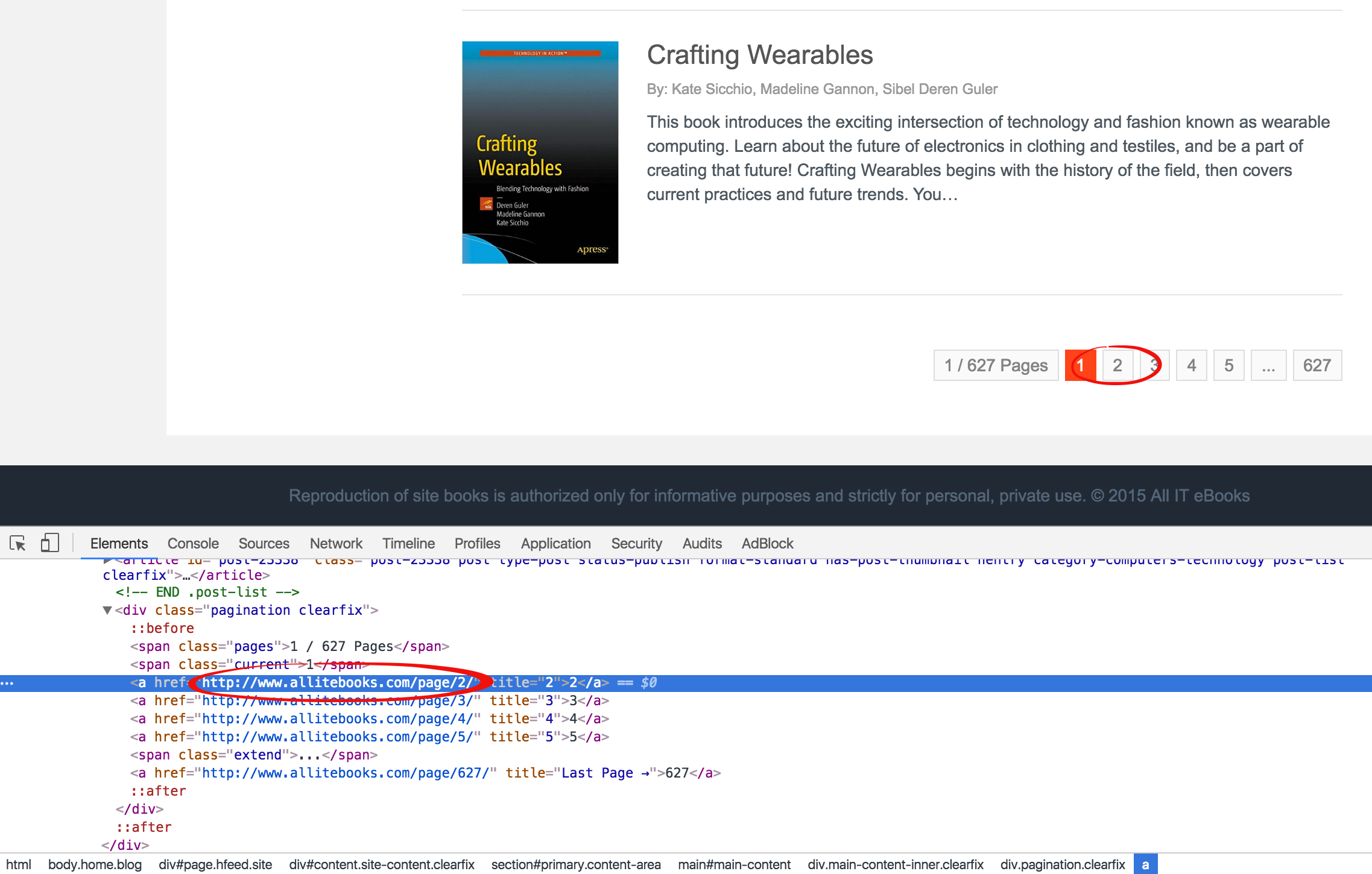 通過查看分頁功能的HTML代碼,通過class="current"可以定位當前頁碼所在span標簽,此span標簽的下一個兄弟a標簽就是下一頁鏈接所在的標簽,
而通過對比最後一頁的span可以發現,在最後一頁中,通過class="current"找到的span標簽卻沒有下一個兄弟a標簽。所以我們可以通過這一點判斷出是否已經到最後一頁了。代碼如下:
通過查看分頁功能的HTML代碼,通過class="current"可以定位當前頁碼所在span標簽,此span標簽的下一個兄弟a標簽就是下一頁鏈接所在的標簽,
而通過對比最後一頁的span可以發現,在最後一頁中,通過class="current"找到的span標簽卻沒有下一個兄弟a標簽。所以我們可以通過這一點判斷出是否已經到最後一頁了。代碼如下:
# Get the next page url from the current page url def get_next_page_url(url): page = urlopen(url) soup_page = BeautifulSoup(page, 'lxml') page.close() # Get current page and next page tag current_page_tag = soup_page.find(class_="current") next_page_tag = current_page_tag.find_next_sibling() # Check if the current page is the last one if next_page_tag is None: next_page_url = None else: next_page_url = next_page_tag['href'] return next_page_url
三、從書籍列表裡找到詳情頁的鏈接
在書籍列表點擊書名或者封面圖都可以進入詳情,則書名和封面圖任選一個,這裡選擇書名。
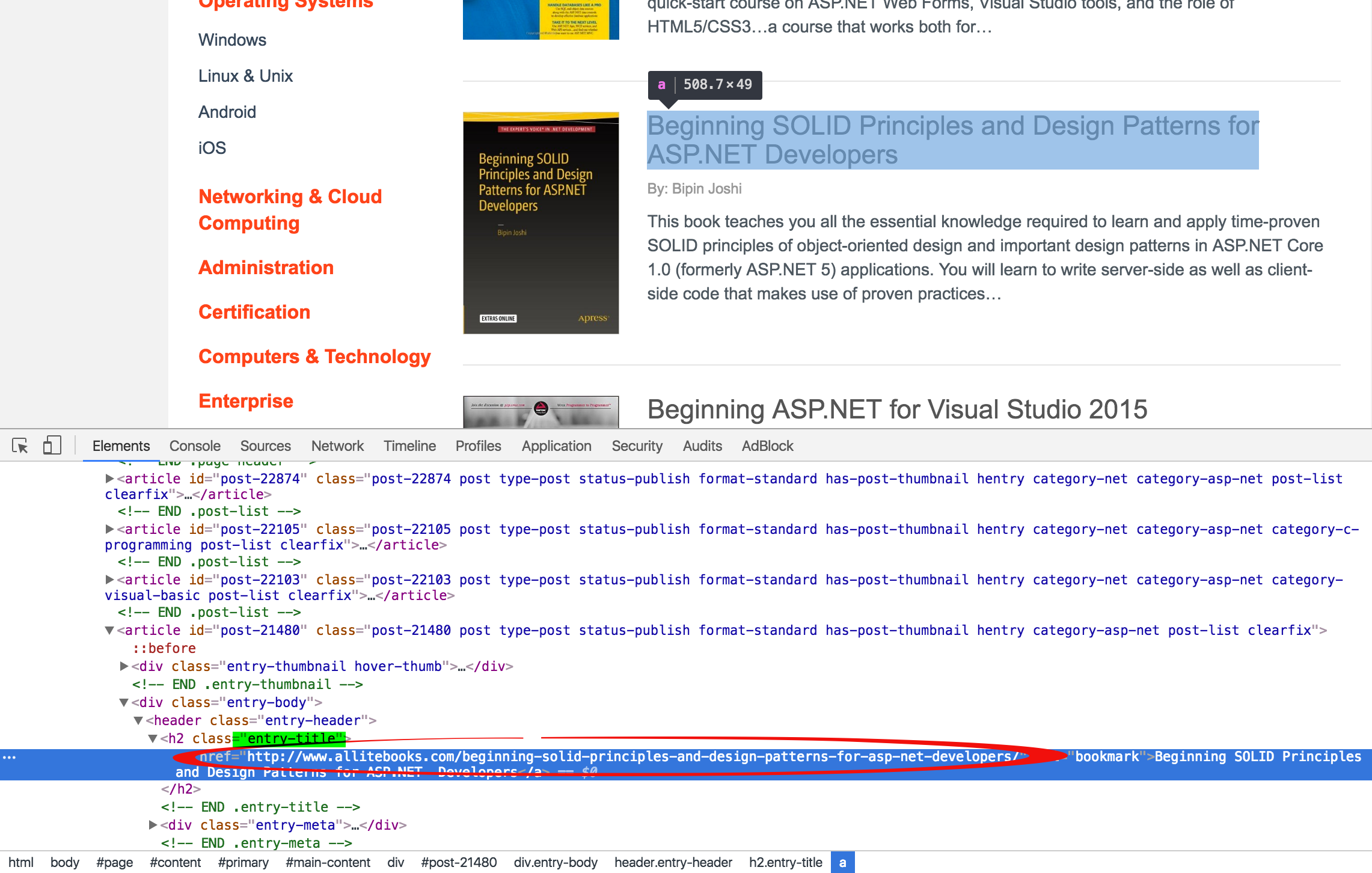
# Get the book detail urls by page url def get_book_detail_urls(url): page = urlopen(url) soup = BeautifulSoup(page, 'lxml') page.close() urls = [] book_header_tags = soup.find_all(class_="entry-title") for book_header_tag in book_header_tags: urls.append(book_header_tag.a['href']) return urls
四、從書籍詳情頁里抓取標題和ISBN碼
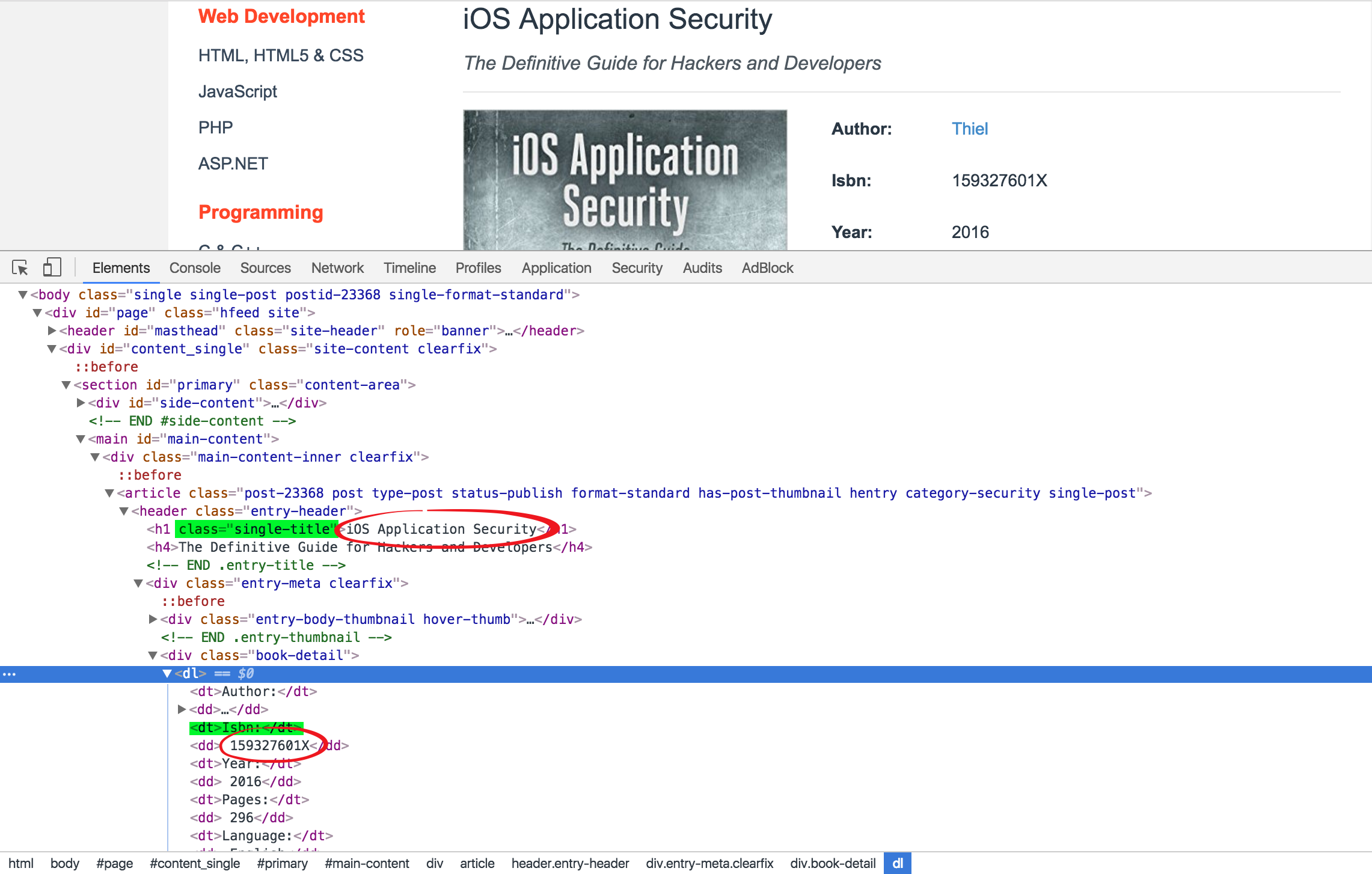 通過查看書籍詳情頁的HTML代碼,我們可以通過查找class="single-title"定位到標題所在的h1標簽獲得標題,然後通過查找text="Isbn:"定位到"Isbn:"的所在的dt標簽,此標簽的下一個兄弟節點就是書籍ISBN碼所在的標簽,通過此標簽的string屬性可獲得ISBN碼內容。
代碼如下:
通過查看書籍詳情頁的HTML代碼,我們可以通過查找class="single-title"定位到標題所在的h1標簽獲得標題,然後通過查找text="Isbn:"定位到"Isbn:"的所在的dt標簽,此標簽的下一個兄弟節點就是書籍ISBN碼所在的標簽,通過此標簽的string屬性可獲得ISBN碼內容。
代碼如下:
# Get the book detail info by book detail url def get_book_detail_info(url): page = urlopen(url) book_detail_soup = BeautifulSoup(page, 'lxml') page.close() title_tag = book_detail_soup.find(class_="single-title") title = title_tag.string isbn_key_tag = book_detail_soup.find(text="Isbn:").parent isbn_tag = isbn_key_tag.find_next_sibling() isbn = isbn_tag.string.strip() # Remove the whitespace with the strip method return { 'title': title, 'isbn': isbn }
五、將三部分代碼整合起來
def run(): url = "http://www.allitebooks.com/programming/net/page/1/" book_info_list = [] def scapping(page_url): book_detail_urls = get_book_detail_urls(page_url) for book_detail_url in book_detail_urls: # print(book_detail_url) book_info = get_book_detail_info(book_detail_url) print(book_info) book_info_list.append(book_info) next_page_url = get_next_page_url(page_url) if next_page_url is not None: scapping(next_page_url) else: return scapping(url)
運行結果
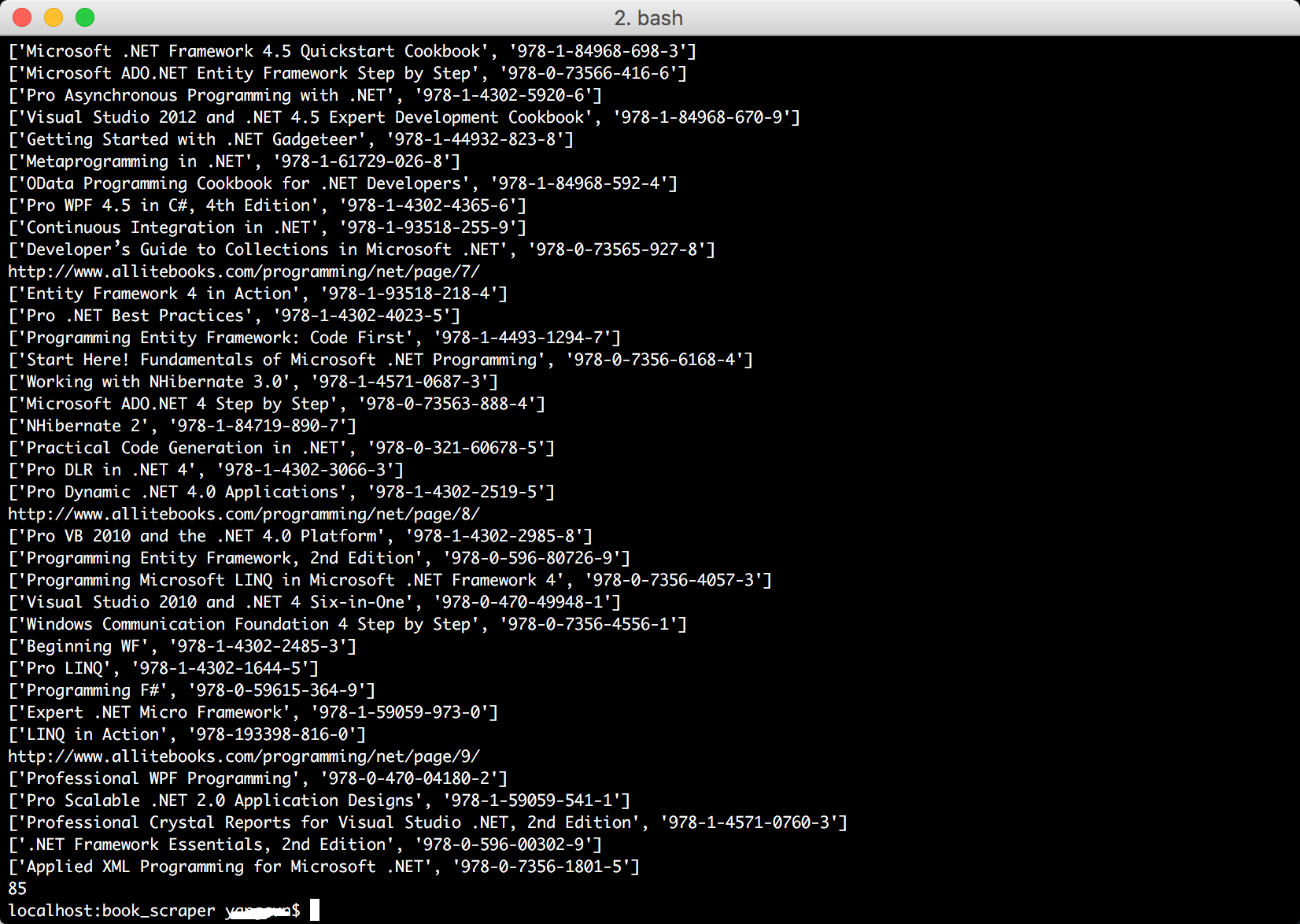
六、將結果寫入文件,以供下一步處理使用
def save_to_csv(list): with open('books.csv', 'w', newline='') as fp: a = csv.writer(fp, delimiter=',') a.writerow(['title','isbn']) a.writerows(list)
未完待續...
完整代碼請移步github:https://github.com/backslash112/book_scraper_python Beautiful Soup基礎知識:網路爬蟲: 從allitebooks.com抓取書籍信息並從amazon.com抓取價格(1): 基礎知識Beautiful Soup 我們處於大數據時代,對數據處理感興趣的朋友歡迎查看另一個系列隨筆:利用Python進行數據分析 基礎系列隨筆彙總 接下來一篇隨筆是根據獲取到的ISBN碼去amazon.com網站獲取每本書對應的價格,並通過數據分析的知識對獲取的數據進行處理,最後輸出到csv文件。有興趣的朋友歡迎關註本博客,也歡迎大家留言討論。
