
. . . . . 目錄 (一) 一起學 Unix 環境高級編程 (APUE) 之 標準IO (二) 一起學 Unix 環境高級編程 (APUE) 之 文件 IO (三) 一起學 Unix 環境高級編程 (APUE) 之 文件和目錄 (四) 一起學 Unix 環境高級編程 (APUE) 之 系統數據 ...
.
.
.
.
.
目錄
(一) 一起學 Unix 環境高級編程 (APUE) 之 標準IO
(二) 一起學 Unix 環境高級編程 (APUE) 之 文件 IO
(三) 一起學 Unix 環境高級編程 (APUE) 之 文件和目錄
(四) 一起學 Unix 環境高級編程 (APUE) 之 系統數據文件和信息
(五) 一起學 Unix 環境高級編程 (APUE) 之 進程環境
(六) 一起學 Unix 環境高級編程 (APUE) 之 進程式控制制
(七) 一起學 Unix 環境高級編程 (APUE) 之 進程關係 和 守護進程
(八) 一起學 Unix 環境高級編程 (APUE) 之 信號
(九) 一起學 Unix 環境高級編程 (APUE) 之 線程
(十) 一起學 Unix 環境高級編程 (APUE) 之 線程式控制制
(十一) 一起學 Unix 環境高級編程 (APUE) 之 高級 IO
(十二) 一起學 Unix 環境高級編程 (APUE) 之 進程間通信(IPC)
(十三) [終篇] 一起學 Unix 環境高級編程 (APUE) 之 網路 IPC:套接字
在前面的博文中我們討論了進程間通訊(IPC)的各種常用手段,但是那些手段都是指通訊雙方在同一臺機器上的情況。在現實生活中我們會經常接觸到各種各樣的網路應用程式,比如大家經常使用的 ftp、svn、甚至QQ、迅雷等等,它們的通訊雙方通常都是在不同的機器上的,那麼它們的通訊就是跨主機的進程間通訊了,所以網路通訊也是一種進程間通訊的手段。
跨主機的程式在傳輸數據之前要制定嚴謹的協議,不然對方可能會看不懂你發送的數據,從而導致數據傳送失敗,甚至造成安全類bug,所以跨主機的通訊就不像我們之前學習的在同一臺主機上的進程間通訊那麼簡單了。
制定協議要考慮的問題至少包括以下幾點:
1)告訴對方自己的 IP 和埠;
先來看看 IP 和埠的概念。
當我們的程式在進行網路通訊之前,需要先與自己的機器進行約定,告訴操作系統我需要使用哪個埠,這樣操作系統的某個埠在收到數據的時候就會發送給我們的進程。當另一個程式也來通知操作系統它要使用這個埠時,操作系統要保證這個埠只有我們使用而不能再讓別人使用,否則當它收到數據的時候就不知道應該發送給誰了。
當我們需要發送數據的時候,也會使用這個埠進行發送,只有特殊情況才會使用別的埠或者使用多個埠。
2)還要考慮的問題是通信的雙方應該採用什麼數據類型呢?
假如通訊雙方要傳送一個 int 類型的數據,那麼對方機器上 int 類型的位數與我們機器上的位數是否相同呢?
也就是說 int 類型在我的機器上是 32bit,但是在對方的機器上也是 32bit 嗎?假設在對方機器上是 16bit,那麼我發送給它的 int 值它能正確解析嗎?
所以通信雙方的數據類型要採用完全一致的約定,這個我們在下麵會討論如何讓數據類型一致。
3)還要考慮位元組序問題,這個說的是大小端的問題。
大端格式是:低地址存放高位數據,高地址存放低位數據。
小端格式是:低地址存放低位數據,高地址存放高位數據。
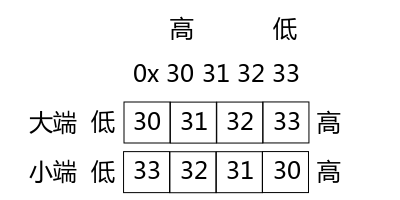
圖1 大小端
如圖1 所示,假設要存放的數據是 0x30313233,那麼 33 是低位,30 是高位,在大端存儲格式中,30 存放在低位,33 存放在高位;而在小端存儲格式中,33 存放在低位,30 存放在高位。
這個東西有什麼作用呢?它其實就是我們使用的網路設備(電腦、平板電腦、智能手機等等)在記憶體當中存儲數據的格式。所以如果通訊雙方的設備存儲數據的格式不同,那麼一端發送過去的數據,另一端是無法正確解析的,這可怎麼辦呢?
沒關係,還好系統為我們準備了一組函數可以幫我們實現位元組序轉換,我們可以像使用公式一樣使用它們。
1 htonl, htons, ntohl, ntohs - convert values between host and network byte order 2 3 #include <arpa/inet.h> 4 5 uint32_t htonl(uint32_t hostlong); 6 7 uint16_t htons(uint16_t hostshort); 8 9 uint32_t ntohl(uint32_t netlong); 10 11 uint16_t ntohs(uint16_t netshort);
這組函數的名字好奇怪是吧,所以為了便於記憶,在討論它們的功能之前我們先來分析一下它們名字里的玄機:
h 是 host,表示主機;n 是 network,表示網路。l 表示 long,s 表示 short。
這樣一來就好理解多了吧?它們的作用從名字中就可以看出來了,就是把數據從主機序轉換為網路序,或者把數據從網路序轉換為主機序。
網路位元組序一般都是大端的,而主機位元組序則根據硬體平臺的不同而不同(在 x86 平臺和絕大多數的 ARM 平臺都是小端)。所以為了簡化我們編程的複雜度,這些函數的內部會根據當前機器的結構自動為我們選擇是否要轉換數據的位元組序。我們不用管到底我們自己的主機採用的是什麼位元組序,只要是從主機發送數據到網路就需要調用 hton 函數,從網路接收數據到主機就需要調用 ntoh 函數。
4)最後一項約定是結構體成員不對齊,由於數據對齊也是與硬體平臺相關的,所以不同的主機如果使用不同的對齊方式,就會導致數據無法解析。
如何使數據不對齊呢,只需要在定義結構體的時候在結尾添加 __attribute__((packed)) 就可以了,見如下慄子:
1 struct msg_st 2 { 3 uint8_t name[NAMESIZE]; 4 uint32_t math; 5 uint32_t chinese; 6 }__attribute__((packed));
網路傳輸的結構體中的成員都是緊湊的,所以不能地址對齊,需要在結構體外面增加 __attribute__((packed))。
關於位元組對齊的東西就足夠寫一篇博文了,LZ 在這裡僅僅簡單介紹一下什麼是位元組對齊,如果感興趣大家可以去查閱專門的資料。
結構體的地址對齊是通過 起始地址 % sizeof(type) == 0 這個公式計算的,也就是說存放數據的起始地址位於數據類型本身長度的整倍數。
如果當前成員的起始地址能被 sizeof 整除,就可以把數據存放在這;否則就得繼續看下一個地址能不能被 sizeof 整除,直到找到合適的地址為止。不適合作為起始地址的空間將被空(lang)閑(fei)。

圖2 位元組對齊
從進程間通信開始,我們寫程式就是一步一步按部就班的寫就可以了,編寫網路應用也一樣,網路通信本質上就是一種跨主機的進程間通信(IPC)。
在上一篇博文中我們瞭解了主動端和被動端的概念,那麼接下來看看在 Socket 中主動端和被動端都要做什麼。
主動端(先發包的一方)
1.取得 Socket
2.給 Socket 取得地址(可省略,不必與操作系統約定埠,由操作系統指定隨機埠)
3.發/收消息
4.關閉 Socket
被動端(先收包的一方,先運行)
1.取得 Socket
2.給 Socket 取得地址
3.收/發消息
4.關閉 Socket
首先我們來看一個慄子,看不懂沒關係,稍後 LZ 會告訴大家用到的函數都是什麼意思。
proto.h 裡面主要是通訊雙方約定的協議,包含埠號、傳送數據的結構體等等。
1 /* proto.h */ 2 #ifndef PROTO_H__ 3 #define PROTO_H__ 4 5 #include <stdint.h> 6 7 #define RCVPORT "1989" 8 9 #define NAMESIZE 13 10 11 12 struct msg_st 13 { 14 uint8_t name[NAMESIZE]; 15 uint32_t math; 16 uint32_t chinese; 17 }__attribute__((packed)); 18 19 20 #endif
rcver.c 是被動端的代碼,也是通訊雙方先啟動的一端。
1 /* rcver.c */ 2 #include <stdio.h> 3 #include <stdlib.h> 4 5 #include <arpa/inet.h> 6 #include <sys/types.h> 7 #include <sys/socket.h> 8 9 #include "proto.h" 10 11 #define IPSTRSIZE 64 12 13 int main() 14 { 15 int sd; 16 struct sockaddr_in laddr,raddr; 17 socklen_t raddr_len; 18 struct msg_st rbuf; 19 char ipstr[IPSTRSIZE]; 20 21 sd = socket(AF_INET,SOCK_DGRAM, 0/*IPPROTO_UDP*/); 22 if(sd < 0) 23 { 24 perror("socket()"); 25 exit(1); 26 } 27 28 laddr.sin_family = AF_INET; 29 laddr.sin_port = htons(atoi(RCVPORT)); 30 inet_pton(AF_INET,"0.0.0.0",&laddr.sin_addr.s_addr); 31 32 if(bind(sd,(void *)&laddr,sizeof(laddr)) < 0) 33 { 34 perror("bind()"); 35 exit(1); 36 } 37 38 raddr_len = sizeof(raddr); 39 while(1) 40 { 41 if(recvfrom(sd,&rbuf,sizeof(rbuf),0,(void *)&raddr,&raddr_len) < 0) 42 { 43 perror("recvfrom()"); 44 exit(1); 45 } 46 47 inet_ntop(AF_INET,&raddr.sin_addr,ipstr,IPSTRSIZE); 48 printf("---MESSAGE FROM:%s:%d---\n",ipstr,ntohs(raddr.sin_port)); 49 printf("Name = %s\n",rbuf.name); 50 printf("Math = %d\n",ntohl(rbuf.math)); 51 printf("Chinese = %d\n",ntohl(rbuf.chinese)); 52 } 53 54 close(sd); 55 56 57 exit(0); 58 }
snder.c 是主動端,主動向另一端發送消息。這端可以不用向操作系統綁定埠,發送數據的時候由操作系統為我們分配可用的埠即可,當然如果想要自己綁定特定的埠也是可以的。
1 /* snder.c */ 2 #include <stdio.h> 3 #include <stdlib.h> 4 #include <arpa/inet.h> 5 #include <sys/types.h> 6 #include <sys/socket.h> 7 #include <string.h> 8 9 #include "proto.h" 10 11 12 int main(int argc,char **argv) 13 { 14 int sd; 15 struct msg_st sbuf; 16 struct sockaddr_in raddr; 17 18 if(argc < 2) 19 { 20 fprintf(stderr,"Usage...\n"); 21 exit(1); 22 } 23 24 sd = socket(AF_INET,SOCK_DGRAM,0); 25 if(sd < 0) 26 { 27 perror("socket()"); 28 exit(1); 29 } 30 31 // bind(); // 主動端可省略綁定埠的步驟 32 33 memset(&sbuf,'\0',sizeof(sbuf)); 34 strcpy(sbuf.name,"Alan"); 35 sbuf.math = htonl(rand()%100); 36 sbuf.chinese = htonl(rand()%100); 37 38 raddr.sin_family = AF_INET; 39 raddr.sin_port = htons(atoi(RCVPORT)); 40 inet_pton(AF_INET,argv[1],&raddr.sin_addr); 41 42 if(sendto(sd,&sbuf,sizeof(sbuf),0,(void *)&raddr,sizeof(raddr)) < 0) 43 { 44 perror("sendto()"); 45 exit(1); 46 } 47 48 puts("ok!"); 49 50 close(sd); 51 52 53 exit(0); 54 }
由這三個文件組成的程式就可以進行網路通訊了,不知道大家有沒有註意到,無論是發送端還是接收端,執行的步驟都是固定的,將來大家在開發更複雜的網路應用時也是基於這幾個步驟進行擴展。
根據上面的代碼中協議(proto.h)的定義,我們知道其中 msg_st 結構體中 name 成員的長度是固定的,這樣並不好用,那麼我們就把它修改為變長結構體。
修改成變長結構體很簡單,只需把變長的部分放到結構體的最後面,然後通過 malloc(3) 動態記憶體管理來為它分配我們需要的大小。如下所示:
1 struct msg_st 2 { 3 uint32_t math; 4 uint32_t chinese; 5 uint8_t name[1]; 6 }__attribute__((packed));
UDP 包常規的最大尺寸是 512 位元組,去掉包頭的 8 個位元組,再去掉結構體中除了最後一個成員以外其它成員大小的總和,剩下的就是我們最後一個成員最大能分配的大小。
大家還記得如何操作一個文件嗎?
1.首先通過 open(2) 函數打開文件,並獲得文件描述符;
2.通過 read(2)、write(2) 函數讀寫文件;
3.調用 close(2) 函數關閉文件,釋放相關資源。
沒錯,在 Linux 的一切皆文件的設計理念中,網路也是文件,網路之間的通訊也可以像操作文件一樣,對它進行讀寫。
在網路程式中,通常步驟是這樣的:
1.首先通過 socket(2) 函數獲得 socket 文件描述符;
2.通過 send(2)、sendto(2)、recv(2)、recvfrom(2) 等函數讀寫數據,這一步就相當於在網路上收發數據了。
3.調用 close(2) 函數關閉網路,釋放相關資源。你沒看錯,這個函數就是我們關閉文件描述符的時候使用的函數。
下麵我們依次介紹上面遇到的各種函數。
socket(2)
1 socket - create an endpoint for communication 2 3 #include <sys/types.h> /* See NOTES */ 4 #include <sys/socket.h> 5 6 int socket(int domain, int type, int protocol);
socket(2) 函數是用來獲取對網路操作的文件描述符的,就像 open(2) 函數一樣。
參數列表:
domain:協議族;
type:鏈接方式;
protocol:具體使用哪個協議。在 domain 的協議族中每一個對應的 type 都有一個或多個協議,使用協議族中預設的協議可以填寫 0。
返回值:如果成功,返回的是一個代表當前網路鏈接的文件描述符,你要保存好它,因為後續的網路操作都需要它。如果失敗,返回 -1,並設置 errno。
下麵就是 Linux 支持的協議族,也就是 domain 參數可以選擇的巨集,它們都定義在 sys/socket.h 頭文件中,所以想要使用下麵的巨集不要忘記包含這個頭文件喲。
AF_UNIX、AF_LOCAL:本地協議;通過 man 7 unix 可以得到有關這個協議族更詳細的描述。
AF_INET:IPV4 協議;這是我們最常見的協議族,通過 man 7 ip 可以得到有關這個協議族更詳細的描述。
AF_INET6:IPV6 協議;,通過 man 7 ipv6 可以得到有關這個協議族更詳細的描述。
AF_IPX:Novell 當年是網路的代名詞,是非常古老的操作系統,出現在 TCP/IP 之前;
AF_NETLINK:是用戶態與內核態通信的協議;
AF_X25:這是很早的協議,感興趣的話可以自己去 Google 一下;
AF_AX25:應用於業餘無線電,也稱為短波通信,都是一些無線電愛好者使用的協議。據說汶川地震時災區所有通訊都癱瘓了,第一個求救信號就是短波發送出來的,因為這些無線電愛好者家裡一般都有大大小小的發電機。
AF_ATMPVC:當年如日中天,後來死於封閉。協議設計得非常好,後來幾家公司都為了拿大頭就僵持起來,誰都沒有推廣它,就在這時候乙太網發展起來了,就把它打敗了。乙太網發展起來就是因為很簡陋,所以更容易推廣。
AF_APPLETALK:蘋果使用的一個區域網協議;
AF_PACKET:底層 socket 所用到的協議,比如抓包器所遵循的協議一定要在網卡驅動層,而不能在應用層,否則無法見到包封裝的過程。再比如 ping(1) 命令大家都熟悉吧,想要實現 ping(1) 命令就需要瞭解這個協議族,感興趣的話大家可以自行 Google 一下。
如果想要對網路編程進行更深入的學習,那麼《APUE》作者寫的《UNIX 網路編程》有必要讀一遍;《TCP/IP詳解》三捲也要讀一下,但是這三捲都很難讀,而且翻譯質量也一般,可以買一本中文的再找一本英文電子版的,遇到中文的讀不通的時候拿出來英文原文對照一下就可以了。
下麵我們看一下 type 參數有哪些可選項:
SOCK_STREAM:流式套接字,特點是有序、可靠。有序、雙工、基於鏈接的、以位元組流為單位的。
可靠不是指不丟包,而是流式套接字保證只要你能接收到這個包,那麼包中的數據的完整性一定是正確的。
雙工是指雙方都能收發。
基於鏈接的是指:比如大街上張三、李四進行對話,一定不會說每句話之前都叫著對方的名字。也就是說通信雙方是知道對方是誰的。
位元組流是指數據沒有明顯的界限,一端數據可以分為任意多個包發送。
SOCK_DGRAM:報式套接字,無鏈接的,固定的最大長度,不可靠的消息。
就像寫信,無法保證你發出的信對方一定能收到,而且無法保證內容不會被篡改。如果今天發了一封信,明天又發了一封信,不能保證哪封信先到。大家都能收到這個包,但是發現不是自己的之後就會丟棄,發現是自己的包再處理,有嚴格的數據分界線。更詳細的解釋可以參閱 man 手冊。
SOCK_SEQPACKET:提供有序、可靠、雙向基於連接的數據報通信。
SOCK_RAW:原始的套接字,提供的是網路協議層的訪問。
SOCK_RDM:數據層的訪問,不保證傳輸順序。
SOCK_PACKET:不好用,具體的 bug 要查 man 7 packet。
bind(2)
1 bind - bind a name to a socket 2 3 #include <sys/types.h> /* See NOTES */ 4 #include <sys/socket.h> 5 6 int bind(int sockfd, const struct sockaddr *addr, 7 socklen_t addrlen);
bind(2) 函數用於綁定本機埠,就是提前跟操作系統約定好,來自 xx 埠的數據都要轉交給我(當前進程)處理,並且我占用了這個埠號別人(其它進程)就不能再使用了。
參數列表:
sockfd:剛剛使用 socket(2) 函數得到的文件描述符,表示要對該網路鏈接綁定埠。
addr:要綁定到套接字上的地址。根據不同的協議要在 man 手冊第 7 章查閱具體的章節,然後在 Address Types 一欄裡面找到對應的結構體。比如你在調用 socket(2) 函數的時候,domain 參數選擇的是 AF_INET,那麼這個結構體就可以在 man 手冊 ip(7) 章節中找到。
addrlen:addr 傳遞的地址結構體的長度。
以 AF_INET 為例,下麵這兩個結構體就是在 ip(7) 中找到的。
1 struct sockaddr_in { 2 sa_family_t sin_family; /* 指定協議族,一定是 AF_INET,因為既然是 man ip(7),那麼一定是 AF_INET 協議族的 */ 3 in_port_t sin_port; /* 埠,需要使用 htons(3) 轉換為網路序 */ 4 struct in_addr sin_addr; /* internet address */ 5 }; 6 7 /* Internet address. */ 8 struct in_addr { 9 uint32_t s_addr; /* 無符號32位大整數,可以使用 inet_pton(3) 將便於記憶的點分式 IP 地址表示法轉換為便於電腦使用的大整數,inet_ntop(3) 的作用則正好相反。本機地址轉換的時候可以使用萬能IP:0.0.0.0(稱為any address),函數會自動將 0.0.0.0 解析為真實的本機 IP 地址。 */ 10 };
大家可以看到,這個結構體的類型是 struct sockaddr_in,而 bind(2) 函數的第二個參數 的類型是 struct sockaddr,它們二者有什麼關係呢?別瞎想,不是繼承關係啦,C 語言中沒有繼承這種東東。在傳參的時候直接把實參強轉為 void* 類型即可,就像上面慄子中 rcver.c 寫得那樣。
recv(2) 和 recvfrom(2) 函數
1 recv, recvfrom - receive a message from a socket 2 3 #include <sys/types.h> 4 #include <sys/socket.h> 5 6 ssize_t recv(int sockfd, void *buf, size_t len, int flags); 7 8 ssize_t recvfrom(int sockfd, void *buf, size_t len, int flags, 9 struct sockaddr *src_addr, socklen_t *addrlen);
這兩個函數的作用是從網路上接收內容並寫入 len 個位元組長度的數據到 buf 中,且將發送端的地址信息填寫到 src_addr 中。
返回值是真正能接收到的位元組數,返回 -1 表示失敗。
recv(2) 函數一般用在流式(SOCK_STREAM)套接字中,而 recvfrom(2) 則一般用在報式(SOCK_DGRAM)套接字中。
為什麼這麼說呢,還記得上面我們提到過嗎,流式套接字是基於鏈接的,而報式套接字是無鏈接的。那麼我們再來觀察下這兩個函數的參數列表,很明顯 recv(2) 函數並沒有地址相關的參數,而 recvfrom(2) 函數則會將對方的地址埠等信息回填給調用者。
網路中的數據只有單位元組數據不用考慮位元組序,從網路上接收過來的數據只要涉及到位元組序就需要使用 ntoh 系列函數進行位元組序轉換。這一組函數我們上面介紹過了,沒記住的童鞋可以往上翻。
小提示:通過 netstat(1) 命令 ant 參數可以查看 TCP 鏈接情況,或通過 netstat(1) 命令 anu 參數可以查看 UDP 鏈接情況。
t 參數表示 TCP;
u 參數表示 UDP;
send(2) 和 sendto(2) 函數
1 send, sendto, sendmsg - send a message on a socket 2 3 #include <sys/types.h> 4 #include <sys/socket.h> 5 6 ssize_t send(int sockfd, const void *buf, size_t len, int flags); 7 8 ssize_t sendto(int sockfd, const void *buf, size_t len, int flags, 9 const struct sockaddr *dest_addr, socklen_t addrlen);
這兩個函數與 recv(2) 和 recvfrom(2) 函數正好是對應的,它們的作用是向網路上發送數據。
參數列表:
sockfd:通過哪個 Socket 往外發數據,這個參數的值就是在調用 socket(2) 函數的時候取得的;
buf:要發送的數據;
len:要發送的數據的長度;
flags:特殊要求,沒有填 0;
src_addr:目標地址;就像上面我們討論 bind(2) 函數時一樣,具體使用哪個結構體要根據你在調用 socket(2) 函數的時候使用的具體協議族有關係,然後到對應的 man 手冊第 7 章去查找。
addrlen:目標地址的長度;
返回值是真正發送出去的數據的長度;出現錯誤返回 -1 並設置 errno。
最後剩下 close(2) 函數就不需要 LZ 在這裡介紹了吧,如果還有童鞋對 close(2) 函數不熟悉,那麼請翻閱到前面 文件 IO 部分的博文中複習一遍。
上面我們討論的是單點通訊,多點通訊只能用報式套接字來實現。
一般多點通訊分為:廣播 和 多播(組播)兩種方式。
廣播又分為 全網廣播(255.255.255.255) 和 子網廣播 兩種形式。
多播:都是 D 類地址,以 224. 開頭。224.0.0.1 是一個組播中的特殊地址,發到這個地址的消息會強制所有組播地址中的主機接收,類似於全網廣播。
註意:廣播和組播僅在區域網內有效。
getsockopt(2) 和 setsockopt(2) 函數
1 getsockopt, setsockopt - get and set options on sockets 2 3 #include <sys/types.h> 4 #include <sys/socket.h> 5 6 int getsockopt(int sockfd, int level, int optname, 7 void *optval, socklen_t *optlen); 8 int setsockopt(int sockfd, int level, int optname, 9 const void *optval, socklen_t optlen);
這兩個函數用於讀取和設置套接字的特殊要求。
對 sockfd 這個套接字的 level 層的 optname 選項進行設置,值放在 optval 里,大小是 optlen。
參數 sockfd、level 和 optname 的對應關係就是:一個 sock 有多個 level,每個 level 有多個選項。
所有的選項需要在不同協議的 man 手冊(第7章) Socket options 一欄查找。
常用 optname 參數:
SO_BROADCAST:設置或獲取廣播標識,當這個標識被打開時才允許接收和發送報式套接字廣播,所以大家使用廣播的時候不要忘記設置這個 opt,但在流式套接字中無效。
IP_MULTICAST_IF:創建多播組,optval 參數應該使用 ip_mreqn 還是 ip_mreq 結構體,取決於 IP_ADD_MEMBERSHIP 選項。
1 struct ip_mreqn { 2 struct in_addr imr_multiaddr; /* 多播組 IP 地址,大整數,可以用 inet_pton(3) 將點分式轉換為大整數 */ 3 struct in_addr imr_address; /* 本機 IP 地址,可以用 0.0.0.0 代替,大整數,可以用 inet_pton(3) 將點分式轉換為大整數 */ 4 int imr_ifindex; /* 當前使用的網路設備的索引號,ip ad sh 命令可以查看編號,用 if_nametoindex(3) 函數也可以通過網路設備名字獲取編號,名字就是 ifconfig(1) 看到的名字,如 eth0、wlan0 等 */ 5 };
IP_ADD_MEMBERSHIP:加入多播組
下麵來談談丟包和校驗的問題。
UDP 會丟包,為什麼會丟包呢?因為不同的請求會選擇不同的路徑經過不同的路由器,這些包到達路由器的時候會進入路由器的等待隊列,當路由比較繁忙的時候隊列就會滿,當隊列滿了的時候各個路由會根據不同的演算法丟棄多餘的包(一般是丟棄新來的包或隨機丟棄包)。所以丟包的根本原因是擁塞。
ping 命令的 TTL 是一個數據包能夠經過的路由器數量的上限,這個上限在 Linux 環境里預設是 64,在 Windows 里預設是 128。假設從中國某個點發送一個包到美國的某個點,從發出開始到中國的總路由器需要大約十幾跳,從中國總路由到美國總路由大約兩三跳就到了,再從美國總路由到達目標點也經過大約十幾跳,因此無論 TTL 是 64 還是 128 都足以從全球任何一個點發送數據到另一個點了,所以丟包絕不是因為 TTL 值太小導致的。
解決丟包的方法是使用流量控制,之前我們寫過令牌桶還記得吧?流控分為開環式和閉環式。
我們在這裡介紹一種停等式流控:它是一種閉環式流控。它的實現方式很簡單,一問一答即可。就是發送方每次發送一個數據包之後要等待接收方的響應,確認接收方收到了自己的數據包後再發送下一個數據包。這種方式的特點是每次等待的時間是不確定的,因為每次發包走的路徑是不同的,所以包到達目的地的時間也是不同的,而且還要受網路等環境因素影響。
並且停等式流控的缺點也很明顯:
1.浪費時間,多數時間都花費在等待響應上面了。
2.雙方發送包的數量增加了,這也意味著丟包率升高了。
3.為了降低錯誤率,實現的複雜度會變高。如果 s 端 data 包發過去了,但是 c 端響應的 ack 包丟了,s 端過了一會兒沒收到 ack 認為 data 丟了再次發送 data,當 c 端再次收到一模一樣的 data 包時不知道到底是有兩段數據一模一樣還是 s 端把包發重覆了,所以需要給data包加編號,這樣 c 端就知道當前這個 data 包是合法的數據還是多餘的數據了。
停等式流控雖然上升了丟包率,但是能保證對方一定能收到數據包。
web 傳輸通常採用兩種校驗方案:
1.不做硬性校驗:交給用戶來做。比如你在瀏覽網頁,網頁周邊的廣告都載入出來了,但是正文沒有載入出來,你肯定會刷新頁面吧?但是如果正文載入出來了,周邊的廣告沒有載入出來,你會刷新網頁一定要讓整個網頁全部都載入完整再看內容碼?
2.延遲應答:下次通訊的時候把上次的 ack 帶過來,表示上次的通訊是完整的。

圖3 ack 延遲
不僅僅 data 包會出現延遲, ack 包也會出現延遲(見圖3)。所以 ack 包也需要加編號。為了防止被抓包,所以往往不會把原始的編號暴露出來,比如將編號+1或-1再發送。
網路的擁塞不僅僅會帶來丟包的問題,還會帶來延遲的問題。延遲並不可怕,可怕的是延遲抖動。比如在北京看新聞聯播和在雲南看新聞聯播會是同時的嗎?肯定會有相應的延遲吧,每一幀都延遲就沒關係,就怕其中某些幀延遲,其它幀不延遲,這樣看到的內容就全亂了。
上面說了用停等式流控可以保證數據一定能夠讓對方接收到,但是有沒有覺得速度慢了點?
可以通過視窗或滑動視窗提高速度,見圖4。
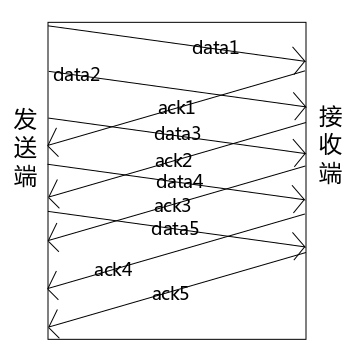
圖4 視窗
使用視窗協議的停等式流控,不再是發送一個包之後等待 ack 然後再發送另一個包,而是一下子發送出去多個包(圖中一次發送 5 個包),分別等待它們的響應後再發送下一批次的包。一次發送 5 個包,那麼視窗的大小就是 5。使用視窗協議就可以儘可能多的搶占公共資源(交換機的等待隊列等)了,這樣傳輸效率相比簡單的停等式流控就更高了。當然視窗的缺點也是顯而易見的:視窗的大小不可變,對於複雜的網路情況並不靈活。那麼只要對視窗稍加改變就可以更靈活的應對複雜多變的網路環境:動態改變視窗的大小,使之可以根據不同的網路情形動態的改變流控的速率,這樣就可以平衡丟包率和傳輸速率之間的杠桿了,這種可以動態調整視窗大小的協議叫做“滑動視窗”。關於視窗和滑動視窗這裡就不做過多介紹了,感興趣的童鞋可以去查閱一些專門的資料。
說完了 UDP,接下來聊一聊 TCP。
說到 TCP 就不得不談到 TCP 的三次握手,見圖 5。
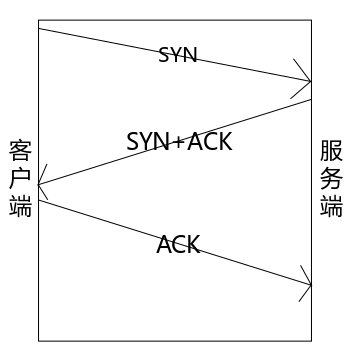
圖5 TCP 三次握手
TCP 都是要客戶端先發起請求,所以客戶端可以稱為“主動端”,而伺服器被動接收請求,所以服務端也可以稱為“被動端”。往往服務端要先運行起來,然後客戶端再發送消息,否則客戶端發送的包會因為找不到目的地而被丟棄。
服務端收到客戶端發來的 SYN 報文後,會響應 SYN+ACK 報文給客戶端,並將當前鏈接的一些信息放入一個叫做“半鏈接池”的緩衝區中,當超過一定時間後該客戶端沒有返回 ACK 報文,服務端再把這個半鏈接從半鏈接池中移除,釋放相關資源。
只要出現了“XX池”,那麼該池的容量終歸是有限的,所以有一種下流的拒絕服務攻擊手段就是利用大量的半鏈接把服務端的半鏈接池沾滿,以實現拒絕服務攻擊。例如當很多肉雞向某台伺服器發送第一次握手(FIN)卻永遠不發送第三次握手(ACK),這樣很快就把伺服器的半鏈接池沾滿了,有效的用戶也就無法請求伺服器了,這就是下流的半鏈接攻擊手段的大致原理。
防範半鏈接的手段就是取消半鏈接池,然後通過一個演算法為每個鏈接計算出一個獨一無二的標識,再把這個標識放入 cookie 中通過 ACK 返回給客戶端。cookie 由內核產生,僅保留這一秒和上一秒的 cookie。當用戶再次請求時需要帶著這個 cookie,用相同的 cookie 計算,只要與用戶帶來的 cookie 相同就認為是合法用戶,如果不相同就用上一秒的cookie再次計算和比較,如果還不相同,就認為用戶的cookie 是偽造的或是超時的,所以用戶會立即重新建立第一次握手。
cookie計算公式:本機IP+本機埠+對端IP+對端埠 | Salt
其實在實踐當中也會保留半鏈接池,裡面僅僅存放頻繁訪問的用戶來優化 cookie 方式的鏈接。
簡要的介紹了 TCP 的三次握手之後,我們來看看如何實現用 TCP 協議收發數據。有關更詳細的 TCP 知識,感興趣的童鞋可以參閱《TCP/IP 捲一:協議》。
TCP 的步驟
S端(先運行)
1.取得 SOCKET (socket(2)) IPPROTO_SCTP 是一種新協議,也可以實現流式套接字
2.給 SOCKET 取得地址 (bind(2))
3.將 SOCKET 置為監聽模式 (listen(2)) backlog 參數寫什麼正整數都行。
4.接受鏈接 (accept(2)) 如果成功返回接受鏈接的文件描述符,失敗返回 -1 並設置 errno。註意不能直接用存放之前 socket(2) 返回的文件描述符變數來接收 accept(2) 的返回值,因為accept(2) 可能會遇到假錯,這樣之前變數里保存的文件描述符就丟了,會導致記憶體泄漏。
5.收/發消息 (send(2))
6.關閉 SOCKET (close(2))
C端(主動)
1.取得 SOCKET (socket)
2.給 SOCKET 取得地址(可省) (bind)
3.發起鏈接 (connect)
4.收/發消息
5.關閉 SOCKET
proto.h,這個文件是客戶端與服務端的協議,雙方共同遵守的格式要定義在這裡,所以兩邊都要包含這個頭文件。
1 #ifndef PROTO_H__ 2 #define PROTO_H__ 3 4 // 伺服器埠號 5 #define SERVERPORT "12999" 6 7 #define FMT_STAMP "%lld\r\n" 8 9 #endif
server.c 服務端,要先運行起來,監聽指定的埠,操作系統指定的埠收到數據後就會送到服務端程式這裡來。
1 #include <stdio.h> 2 #include <stdlib.h> 3 #include <arpa/inet.h> 4 #include <sys/types.h> 5 #include <sys/socket.h> 6 #include <errno.h> 7 8 #include "proto.h" 9 10 #define BUFSIZE 1024 11 #define IPSTRSIZE 40 12 13 static void server_job(int sd) 14 { 15 char buf[BUFSIZE]; 16 int len; 17 18 len = sprintf(buf,FMT_STAMP,(long long)time(NULL)); 19 20 if(send(sd,buf,len,0) < 0) 21 { 22 perror("send()"); 23 exit(1); 24 } 25 26 return ; 27 } 28 29 int main() 30 { 31 int sd,newsd; 32 struct sockaddr_in laddr,raddr; 33 socklen_t raddr_len; 34 char ipstr[IPSTRSIZE]; 35 36 // 選擇 TCP 協議 37 sd = socket(AF_INET,SOCK_STREAM,0/*IPPROTO_TCP,IPPROTO_SCTP*/); 38 if(sd < 0) 39 { 40 perror("socket()


