
原因: 之前已經寫過一篇關於列存儲索引的簡介http://www.cnblogs.com/wenBlog/p/4970493.html,很粗糙但是基本闡明瞭列存儲索引的好處。為了更好的理解列存儲索引,接下來我們一起通過列存儲索引與傳統的行存儲索引地對比2014中的列存儲索引帶來了哪些改善。由於已經很 ...
原因:
之前已經寫過一篇關於列存儲索引的簡介http://www.cnblogs.com/wenBlog/p/4970493.html,很粗糙但是基本闡明瞭列存儲索引的好處。為了更好的理解列存儲索引,接下來我們一起通過列存儲索引與傳統的行存儲索引地對比2014中的列存儲索引帶來了哪些改善。由於已經很多介紹列存儲,因此這裡我僅就性能的改進進行重點說明。
測試場景
我創建了5個測試,儘量保證測試環境避免來自外界的重負載進而影響到結果。測試結果基於兩個獨立的表,分別是:
- FactTransaction_ColumnStore - 這個表僅有一個聚集列存儲索引,由於列存儲索引的限制,該表不再有其他索引。
- FactTransaction_RowStore - 該表將包含一個聚集索引和一個非聚集列存儲索引和一個非聚集行存儲索引。
首先我用腳本文件創建表和索引,然後用30m行數據填充到三個表中。由於所有的測試我都制定了最大並行度的hint ,因此可以指定內核數量來查詢。
測試1-填充表
為了更好地測試,一個表由列存儲索引構成,而另一個表僅有行存儲索引構成。填充數據來自於另一個表'FactTransaction'。
IO 和時間統計
Table 'FactTransaction_ColumnStore'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. Table 'FactTransaction'. Scan count 1, logical reads 73462, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. (30000000 row(s) affected) SQL Server Execution Times: CPU time = 98204 ms, elapsed time = 109927 ms. Table ' FactTransaction_RowStore '. Scan count 0, logical reads 98566047, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. Table 'FactTransaction'. Scan count 1, logical reads 73462, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. (30000000 row(s) affected) SQL Server Execution Times: CPU time = 111375 ms, elapsed time = 129609 ms.
觀察測試
| 表名 | 填充時間 | 邏輯讀 |
| FacTransaction_ColumnStore | 1.49 mins | 0 |
| FacTransaction_RowStore | 2.09 mins | 98566047 |
測試2-比較搜索
註意這裡在行存儲索引上我指定表的hint,迫使表通過索引查找。
-- Comparing Seek.... SET Statistics IO,TIME ON Select CustomerFK From [dbo].FactTransaction_RowStore WITH(FORCESEEK) Where transactionSK = 4000000 OPTION (MAXDOP 1) Select CustomerFK From [dbo].FactTransaction_ColumnStore Where transactionSK = 4000000 OPTION (MAXDOP 1) SET Statistics IO,TIME OFF
IO 和時間統計
Table 'FactTransaction_RowStore'. Scan count 0, logical reads 3, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. SQL Server Execution Times: CPU time = 0 ms, elapsed time = 0 ms. Table 'FactTransaction_ColumnStore'. Scan count 1, logical reads 714, physical reads 0, read-ahead reads 2510, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. SQL Server Execution Times: CPU time = 0 ms, elapsed time = 83 ms.
執行計劃

觀察測試2
正如上圖所示,行存儲索引表的索引查找遠比列存儲索引表查詢快的多。這主要歸因於2014的sqlserver不支持聚集列存儲索引的索引查找。執行計劃對比圖中一個是索引掃描導致更多的邏輯讀,因此導致了性能的下降。
| 表名 | 索引類型 | 邏輯讀 | 運行時間 |
| FacTransaction_ColumnStore | Column | 714 | 83 ms |
| FacTransaction_RowStore | Row | 3 | 0 ms |
Test 3 - Comparing SCAN
註意這次我指定的hint都是索引掃描,當然列存儲索引上優化器預設為索引掃描。
-- Comparing Scan.... SET Statistics IO,TIME ON Select CustomerFK From [dbo].FactTransaction_RowStore WITH(FORCESCAN) Where transactionSK = 4000000 OPTION (MAXDOP 1) Select CustomerFK From [dbo].FactTransaction_ColumnStore WITH(FORCESCAN) Where transactionSK = 4000000 OPTION (MAXDOP 1) SET Statistics IO,TIME OFF
IO 和時間統計
Table 'FactTransaction_RowStore'. Scan count 1, logical reads 12704, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. SQL Server Execution Times: CPU time = 32 ms, elapsed time = 22 ms. Table 'FactTransaction_ColumnStore'. Scan count 1, logical reads 714, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. SQL Server Execution Times: CPU time = 0 ms, elapsed time = 2 ms.
執行計劃
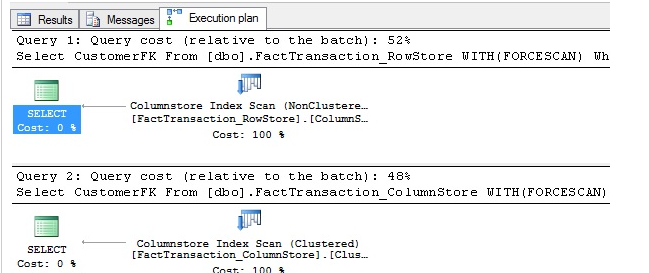
觀察測試3
正如之前提到的,索引掃描列存儲要比行存儲快,倆個邏輯讀和運行時間表明列存儲索引在大表掃描上是更優的方式,因此更適合於數據倉庫的表。
| 表名 | 索引類型 | 邏輯讀 | 運行時間 |
| FacTransaction_ColumnStore | Column | 714 | 2 ms |
| FacTransaction_RowStore | Row | 12704 | 22 ms |
測試4-聚合查詢
測試行存儲表使用基於聚集索引。
SET Statistics IO,TIME ON Select CustomerFK,BrandFK, Count(*) From [dbo].[FactTransaction_RowStore] WITH(INDEX=RowStore_FactTransaction) Group by CustomerFK,BrandFK OPTION (MAXDOP 4)
測試行存儲表,使用CustomerFK 和BrandFK的索引。(覆蓋索引)
Select CustomerFK,BrandFK, Count(*) From [dbo].[FactTransaction_RowStore] WITH(INDEX=RowStore_CustomerFK_BrandFK) Group by CustomerFK,BrandFK OPTION (MAXDOP 4)
測試行存儲索引使用CustomerFK 和BrandFK的列存儲索引(覆蓋索引)
Select CustomerFK,BrandFK, Count(*) From [dbo].[FactTransaction_RowStore] WITH(INDEX=ColumnStore_CustomerFK_BrandFK) Group by CustomerFK,BrandFK OPTION (MAXDOP 4) Test on the columnstore table using the Clustered Index. Select CustomerFK,BrandFK, Count(*) From [dbo].[FactTransaction_ColumnStore] Group by CustomerFK,BrandFK OPTION (MAXDOP 4) SET Statistics IO,TIME OFF
IO 和時間統計
使用基於聚集索引查詢行存儲的表。
Table 'FactTransaction_RowStore'. Scan count 5, logical reads 45977, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. Table 'Workfile'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. SQL Server Execution Times: CPU time = 9516 ms, elapsed time = 2645 ms.
使用行存儲的非聚集索引測試行存儲表。(覆蓋索引)
Table 'FactTransaction_RowStore'. Scan count 5, logical reads 71204, physical reads 0, read-ahead reads 2160, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. Table 'Workfile'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. SQL Server Execution Times: CPU time = 5343 ms, elapsed time = 1833 ms.
使用非聚集列存儲索引測試行存儲表。(覆蓋索引)
Table 'FactTransaction_RowStore'. Scan count 4, logical reads 785, physical reads 7, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. Table 'Workfile'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. SQL Server Execution Times: CPU time = 141 ms, elapsed time = 63 ms.
使用聚集索引測試列存儲表。
Table 'FactTransaction_ColumnStore'. Scan count 4, logical reads 723, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. Table 'Workfile'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. SQL Server Execution Times: CPU time = 203 ms, elapsed time = 118 ms.
執行計劃
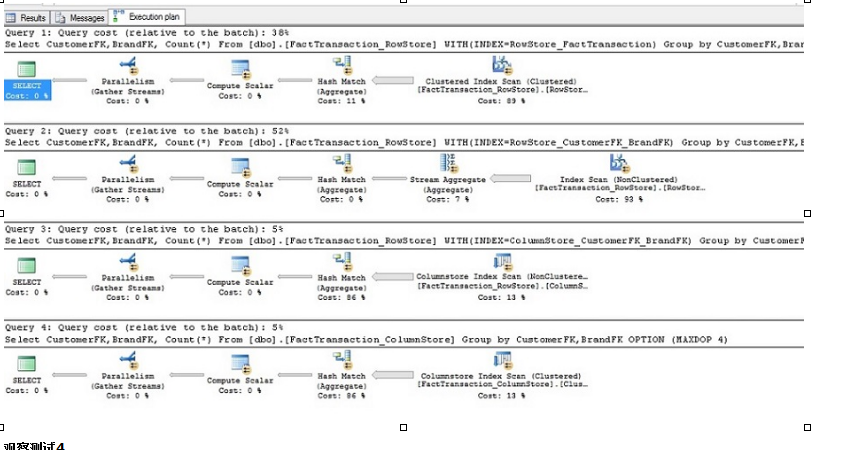
觀察測試4
這裡才是列存儲索引開始“閃耀”的地方。兩個列存儲索引的表查詢要比傳統的航索引在邏輯讀和運行時間上性能好得多。
| 表名 | 索引使用 | 索引類型 | 邏輯讀 | 運行時間 |
| FacTransaction_ColumnStore | ClusteredColumnStore | Column | 717 | 118 |
| FacTransaction_RowStore | RowStore_FactTransaction | Row | 45957 | 2645 |
| FacTransaction_RowStore | RowStore_CustomerFK_BrandFK | Row | 71220 | 1833 |
| FacTransaction_RowStore | ColumnStore_CustomerFK_BrandFK | Column | 782 | 63 |
測試5-比較更新(數據子集)
這個測試中,我將更新少於100m行數據,占總數據的30分之一。
SET Statistics IO,TIME ON Update [dbo].[FactTransaction_ColumnStore] Set TransactionAmount = 100 Where CustomerFK = 112 OPTION (MAXDOP 1) Update [dbo].[FactTransaction_RowStore] Set TransactionAmount = 100 Where CustomerFK = 112 OPTION (MAXDOP 1) SET Statistics IO,TIME OFF
IO 和時間統計
Table 'FactTransaction_ColumnStore'. Scan count 2, logical reads 2020, physical reads 0, read-ahead reads 2598, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. (913712 row(s) affected) SQL Server Execution Times: CPU time = 27688 ms, elapsed time = 37638 ms. Table 'FactTransaction_RowStore'. Scan count 1, logical reads 2800296, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. (913712 row(s) affected) SQL Server Execution Times: CPU time = 6812 ms, elapsed time = 6819 ms.
執行計劃
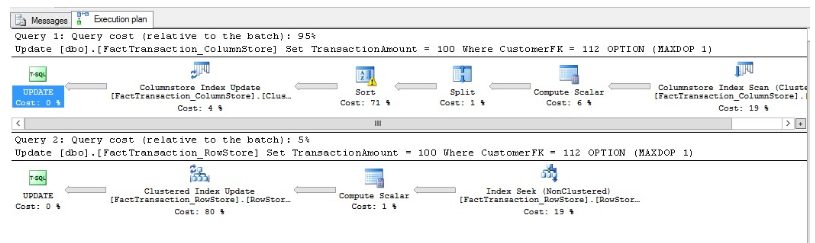
觀察測試5
在這種情況下 ,列存儲索引的表要比行存儲的更新慢的多。
| 表名 | 索引類型 | 邏輯讀 | 運行時間 |
| FacTransaction_ColumnStore | Column | 2020 | 37638 ms |
| FacTransaction_RowStore | Row | 2800296 | 6819 ms |
註意對於行存儲表邏輯讀還是要比行存儲的要多很多。這是歸因於列存儲索引的壓縮比率更高,因此占用更少的記憶體。
總結
列存儲索引(包含聚集和非聚集)提供了大量的優勢。但是在數據倉庫上使用還是要做好準備工作。一種合適地使用情況是非聚集索引不能被更新且禁用對底層表的更新。如果是巨大且沒有分區的表,可能存在一個問題,整個表的索引每次都會被重建,因此如果表是巨大的則禁止使用列存儲索引。因此必須要有好的分區策略來支持這種索引。
有幾個應用列存儲索引的地方:事實表的聚合、Fast Track Data Warehouse Servers、恰當環境SSAS的Cube…

