
目錄為什麼要學習使用make工具?什麼是make工具?make工具的學習過程1. 安裝make:sudo apt install make;並學習使用make安裝make流程學習使用make指令make指令的相關特點make只會對修改過的或者可執行目標文件不存在的.c文件進行編譯使用make時,若不 ...
目錄
為什麼要學習使用make工具?
在實際項目開發過程中,我們都會選擇對項目進行模塊化編程,即把可以重覆使用的函數介面、數據結構等封裝為源文件和頭文件,這樣可以大大提升項目程式的可移植、可讀性和可維護性。但是當項目的源碼數量較大時,就會導致封裝的源文件和頭文件的數量較多,此時就大大提高了項目的編譯難度。為了提高項目的開發效率,我們必須學習使用make工具。
什麼是make工具?
Make工具最早由斯圖爾特·費爾德曼(Stuart Feldman)在1977年開發,作為UNIX系統的一部分推出。費爾德曼的Make工具解決了當時構建大型軟體項目的複雜性問題,通過自動化依賴管理和構建過程,顯著提高了開發效率。
為了獲得更高的項目開發效率,所以GNU組織就在Linux系統中集成了Make工具,而Makefile就屬於Make工具的一部分。Makefile是一個強大而靈活的工具,廣泛應用於各種編程語言和項目中。通過定義目標、依賴和命令,Makefile可以自動化管理項目的構建過程,處理複雜的依賴關係,簡化開發和部署工作。無論是編譯大型C/C++項目,還是自動化生成文檔和部署應用,Makefile都能提供極大的便利和效率提升。

Makefile可以理解為是一個腳本文件,用於管理項目的自動化構建過程,尤其在編譯和鏈接複雜的源代碼項目中非常有用。 Makefile文件的主要目的是簡化和自動化項目的構建過程,包括編譯源代碼、鏈接生成可執行文件、清理中間文件等任務。
make工具的學習過程
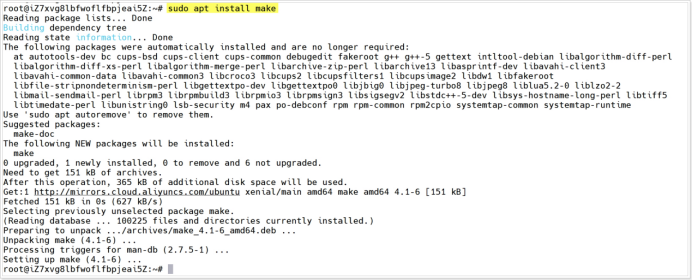
1. 安裝make:sudo apt install make;並學習使用make
安裝make流程
雖然linux系統是支持使用make的,但是make工具在linux系統中是預設未安裝,所以我們需要確認linux系統聯網的情況下,通過指令:sudo apt install make 完成安裝。
學習使用make指令
安裝完成之後,可以選擇閱讀man手冊來瞭解make指令的使用規則和註意事項,如下所示:

經過閱讀man手冊,我們可知:
在Linux系統中,可以通過make指令完成Makefile文件的執行,make指令是一個命令工具,是一個解釋Makefile文本的命令工具,也可以說它是一個工程管理器軟體工具。
總而言之,Makefile是一個類似配置文件的文本(必須命名為Makefile或者makefile),用於描述如何去編譯項目中的源文件以及完成一些其他操作,而make是解釋該配置文件的命令工具。
make指令的相關特點
make只會對修改過的或者可執行目標文件不存在的.c文件進行編譯
思考:如何判斷“修改過”?
答:通過文件修改時間來判斷,即可執行文件的修改時間早於.c文件,則代表.c文件進行了修改,make便會對其重新編譯生成可執行文件。具體舉例說明如下:
假設一個工程有四個源文件,分別為a.c、b.c、x.c和y.c,他們最終將會鏈接生成可執行文件image,如下圖:
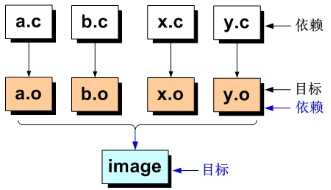
在開發的過程當中,如果修改了x.c源文件,就須重新生成x.o,再重新編譯鏈接生成image文件,但是在由成千上萬個源文件組成的龐大工程,比如Linux源碼,一旦對若幹個源文件進行了修改,則需要花費時間挑選出需重新編譯的文件,否則就需要整體工程編譯必將會浪費大量的時間;而這個挑選文件的任務可以交給make工程管理器,讓make按照Makefile配置文件進行挑選所需文件進行編譯處理。
使用make時,若不加 -f 選項,make會依次尋找,GNUmakefile、makefile、Makefile這三個文件
make是一個shell命令,用於執行Makefile文件中的命令(gcc xxx.c -o xxx),前提是執行make指令的時候,當前路徑下需要有Makefile文件,如果沒有Makefile文件,則指令make指令時會報錯。如下圖所示:

2. 學習編寫Makefile文件
命名規則
我們從man手冊對於make 指令的解釋說明中,可知:
用戶在編寫makefile文件的時候,該文件的名稱應該是makefile或者Makefile,建議大家使用Makefile作為該腳本文件的名稱,註意:該文件是沒有拓展名的!!!
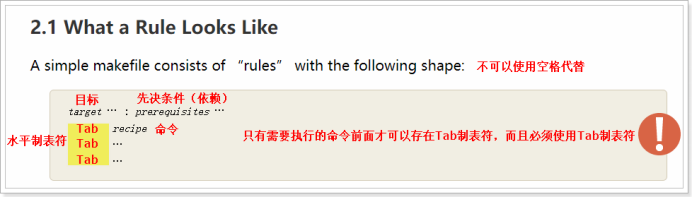
基本規則
通過GNU組織提供的Make手冊可以知道,Makefile文件的基本規則是有四部分組成,分別是目標、先決條件、製表符、命令,具體的規則如下所示:

註意:
- 一套完整的規則,目標、先決條件(依賴)、製表符、命令,四個部分缺一不可,但是根據實際情況,先決條件與shell命令可以不填寫。
- Makefile中可以有多套規則存在,但是應該把最終目標的規則設置為第一套規則。
- 一個目標的多個依賴文件之間,使用<空格>隔開。
- 一個目標生成可能需要多條指令,但每條命令最好獨立一行寫,並且必須以Tab製表符開頭;製表符的個數無強制要求,但是一般以一個Tab製表符開頭。
- <tab符>即是製表符,即Tab鍵,*不能用空格代替*;也是因為這個製表符,make才知道後面是一個需要執行的shell命令。
- 如果想要在一行編寫多條執行命令,則需要使用“;”分號將每條命令隔開。如無特殊情況,建議還是一條命令寫一行。
- Makefile文件中允許存在“偽目標”,其意義為,如果不在make 後面添加指定偽目標名稱,則不會執行偽目標內部的命令,一般多用於清除.o文件和可執行文件。“偽目標”如上圖右邊所示,且不能省略“.PHONY: 偽目標名稱”。
- 經過實際測試,一個Makefile文件中不應該只存在偽目標,否則使用make時,會執行文件中的第一個偽目標。
- 如果make在執行Makefile中規則時,發現其依賴條件不存在,則會在Makefile文件中進行遞歸查找,該查找順序與規則編寫順序無關,只要存在,make便會繼續執行;沒有找的則會報錯。
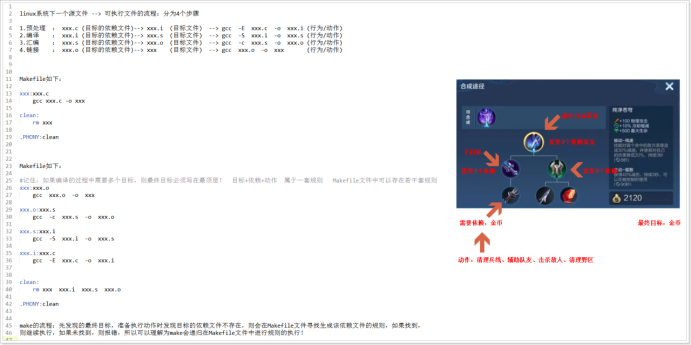
Makefile文件實現原理進一步闡述
image:a.o b.o x.o y.o
gcc a.o b.o x.o y.o -o image
a.o:a.c
gcc a.c -o a.o -c
b.o:b.c
gcc b.c -o b.o -c
x.o:x.c
gcc x.c -o x.o -c
y.o:y.c
gcc y.c -o y.o -c
這個簡單的Makefile文件總共有11行,具有5套規則,其中第1行中的image是第1個目標,冒號後面是這個目標的依賴列表(四個.o可重定位文件)。第2行的行首是一個製表符,後面緊跟著一句shell命令。
下麵從第4行到第11行,也都是這樣的“目標-依賴”,及其相關的Shell命令。但是這裡必須註意一點:雖然這個Makefile總共出現了5個目標,但是第一個規則的目標(即image)被稱之為終極目標,終極目標指的是當你執行make的時候,預設生成的那個可執行文件。
註意:如果第一個規則有多個目標,則只有第一個才是終極目標。另外,以圓點.開頭的目標不在此討論範圍內,流程如下:
1.找到由終極目標構成的一套規則。(第1行和第2行)。
2.如果終極目標及其依賴列表都存在,則判斷他們的時間戳關係,只要目標比任何一個依賴文件舊,就會執行其下麵的Shell命令。(目標與執行命令中生成的可執行文件名要一致,否則無法對比依賴列表與目標的時間戳)
3.如果有任何一個依賴文件不存在,或者該依賴文件比該依賴文件的依賴文件要舊,則需要執行以該依賴文件為目標的規則的Shell命令。(比如a.o如果不存在或者比a.c要舊,則會找到a.o所在行的這一套規則,並執行其下一行的Shell命令)
4.如果依賴文件都存在並且都最新,但是目標不存在,則執行其下麵的Shell命令。---對應執行文件不存在,make會生成的規則
變數說明
編寫工程Makefile文件是為了簡化編譯流程的,但是目前編寫的Makefile文件仍然不能滿足該要求。
假設:在現有工程基礎上再添加一個z.c源文件,要放在一起編譯,對於上述的Makefile文件而言,可能需要重新修改一遍,另外,假設工程有1000個文件,貌似就要寫1000套規則,這樣是不現實的。其實Makefile提供了很多機制,比如變數、函數等來幫助我們更好更方便地組織工作(簡化Makefile的編寫)。
自定義變數
系統預定義變數
自動化變數
在Makefile中變數的特征有以下幾點:
- 變數和函數的展開(除規則的命令行以外),是在make讀取Makefile文件時進行的,這裡的變數包括了使用“=”定義和使用指示符“define”定義的變數。
- 變數可以用來代表一個文件名列表、編譯選項列表、程式運行的選項參數列表、搜索源文件的目錄列表、編譯輸出的目錄列表和所有我們能夠想到的事物。這裡需要與C語言中的變數作區分,不再是“容器”決定“承載內容”,而是“承載內容”決定“容器”。
- 變數名不能包括“:”、“#”、“=”、前置空白和尾空白的任何字元串。前置空白和尾空白會造成系統在執行相應命令的語法錯誤,且很難直接通過觀察Makefile文件找出,需要特別註意。還需要註意的是,儘管在GNU make中沒有對變數的命名有其它的限制,但定義一個包含除字母、數字和下劃線以外的變數的做法也是不可取的,因為除字母、數字和下劃線以外的其它字元可能會在以後的make版本中被賦予特殊含義,並且這樣命名的變數對於一些Shell來說不能作為環境變數使用。
- 變數名是大小寫敏感的。變數“foo”、“Foo”和“FOO”指的是三個不同的變數。Makefile傳統做法是變數名是全採用大寫的方式。推薦的做法是在對於內部定義的一般變數(例如:目標文件列表objects)使用小寫方式,而對於一些參數列表(例如:編譯選項CFLAGS)採用大寫方式,這並不是要求的。但需要強調一點:對於一個工程,所有Makefile中的變數命名應保持一種風格,否則會顯得你是一個蹩腳的開發者(就像代碼的變數命名風格一樣),隨時有被鄙視的危險。
- 另外有一些變數名只包含了一個或者很少的幾個特殊的字元(符號)。稱它們為自動化變數。自動化變數也能夠大幅度提升開發效率,像“<”、“@”、“?”、“*”、“@D”、“%F”、“^D”等等,通過深入的學習,我會將學習到的與大家一同分享。
- 變數的引用跟Shell腳本類似,使用美元符號和圓括弧,比如有個變數叫A,那麼對他的*引用則是$(A)*,有個自動化變數叫@,則對他的引用是$(@),有個系統變數是CC則對其引用的格式是$(CC)。對於前面兩個變數而言,他們都是單字元變數,因此對他們引用的括弧可以省略,寫成$A和$@。 這點很重要,因為不按照“$(變數名)”系統將無法區別變數與普通文件名稱,存在二義性。
變數種類介紹
1. 自定義變數
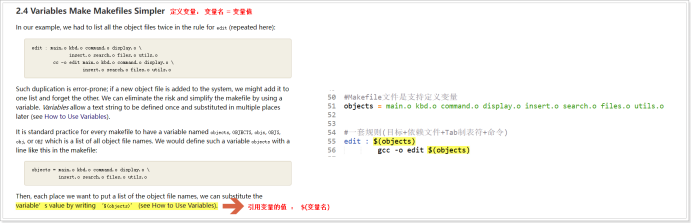
自定義變數,即用戶定義的變數名稱與變數中的內容,例如
A = apple
B = I love China
C = $(A) tree
以上三個變數都是自定義變數,其中變數A包含了一個單詞,變數B的值包含了三個單詞,變數C的值引用了變數A的值,因此他的值是“apple tree”。如果要將這三個變數的值列印出來,可以這麼寫:既然是類似巨集,所以在使用是需要添加特殊符號的: $(變數名)
gec@ubuntu:~$ cat Makefile -n
1 A = apple
2 B = I love China
3 C = $(A) tree
4
5 all:
6 @echo $(A) //echo前面的@代表命令本身不列印出來
7 @echo $(B)
8 @echo $(C)
gec@ubuntu:~$ make
apple
I love China
apple tree
使用自定義變數,可以將前面的工程配置文件Makefile中的所有.o文件用一個變數OBJ來代表,這樣可以減少輸入代碼量,且能夠更好啊的對程式進行更新添加與減少,提升了可維護性:
gec@ubuntu:~$ cat Makefile -n
1 OBJ = a.o b.o x.o y.o
2
3 image:$(OBJ)
4 gcc $(OBJ) -o image
5
6 a.o:a.c
7 gcc a.c -o a.o -c
8 b.o:b.c
9 gcc b.c -o b.o -c
10 x.o:x.c
11 gcc x.c -o x.o -c
12 y.o:y.c
13 gcc y.c -o y.o -c
14 clean:
15 rm $(OBJ)
擴展介紹:“=” 、“ := ” 、“ ?= "、” += ” 四種賦值的區別
- 遞歸展開式變數:"="定義的變數是遞歸方式擴展的變數,在引用的地方是嚴格的文本替換過程,但在出現該變數的時候才會將他替換。例子如下:
A = $(B)
B = $(C)
C = banana
#在這裡定義一個target偽目標
target: $(A)
echo $<
執行make指令後,最終會輸出“banana”,實際輸出過程如下:
將$(A)替換成$(B),
將$(B)替換成$(C),
將$(C)替換成banana,
最終列印出"banana"。
所以,使用"="定義的變數被稱為“遞歸展開式變數“,即遞歸展開(一步步執行)。
- 直接展開式變數:在使用“:=”定義變數時,變數值中對其他量或者函數的引用在定義變數時被展開(對變數進行替換)。所以不能拿未定義的變數作為值(:= 右邊的字元串)進行賦值動作。例子如下:
x := foo
y := $(x) bar
x := later
就等價於:
y := foo bar
x := later
和遞歸展開式變數不同:此風格變數在定義時就完成了對所引用變數和函數的展開,因此不能實現 對其後定義變數的引用。如:
CFLAGS := $(include_dirs)-O
include_dirs :=-Ifoo-Ibar
由於變數“include_dirs”的定義出現在“CFLAGS”定義之後。因此在“CFLAGS”的定義中, “include_dirs”的值為空。“CFLAGS”的值為“-O”而不是“-Ifoo-Ibar-O”。這一點也是直接展 開式和遞歸展開式變數的不同點。註意這裡的兩個變數都是“直接展開”式的。如果一個是“遞歸展開式”一個是“直接展開式”則情況又不一樣。
- 追加變數值:"+="是一個通用變數,。我 們可以在定義時(也可以不定義而直接追加)給它賦一個基本值,後續根據需要可隨時對它的值進 行追加(增加它的值)。在Makefile中使用“+=”(追加方式)來實現對一個變數值的追加操作。像 下邊那樣:當使用這種方式後,新賦值的變數值會添加到原有變數值的後面並用空格隔開。
objects += another.o
這個操作把字元串“another.o”添加到變數“objects”原有值的末尾,使用空格和原有值分開。 因此我們可以看到:
objects = main.o foo.o bar.o utils.o
objects += another.o
上邊的兩個操作之後變數“objects”的值就為:“main.o foo.o bar.o utils.o another.o”。使用 “+=”操作符,相當於:
objects = main.o foo.o bar.o utils.o
objects := $(objects) another.o
註意:
- 如果被追加值的變數之前沒有定義,那麼,“+=”會自動變成“=”,此變數就被定義為一個 遞歸展開式的變數。如果之前存在這個變數定義,那麼“+=”就繼承之前定義時的變數風格
- 直接展開式變數的追加過程:變數使用“:=”定義,之後“+=”操作將會首先替換展開之前 此變數的值,爾後在末尾添加需要追加的值,並使用“:=”重新給此變數賦值。
- 遞歸展開式變數的追加過程:一個變數使用“=”定義,之後“+=”操作時不對之前此變數 值中的任何引用進行替換展開,而是按照文本的擴展方式(之前等號右邊的文本未發生變化) 替換,爾後在末尾添加需要追加的值,並使用“=”給此變數重新賦值。
-
條件賦值的賦值操作符“?=”。被稱為條件賦值是因為:只有 此變數在之前沒有賦值的情況下才會對這個變數進行賦值。例如:
FOO ?= bar其等價於:
ifeq ($(origin FOO), undefined) FOO = bar endif含義是:如果變數“FOO”在之前沒有定義,就給它賦值“bar”。否則不改變它的值.
2. 系統預定義變數
CFLAGS、CC、MAKE、Shell等等,這些變數已經有了系統預定義好的值,當然我們可以根據需要重新給他們賦值,例如CC的預設值是gcc,當我們需要使用gcc編譯器的時候可以直接使用。
這樣做的好處是:在不同平臺中,c編譯器的名稱也許會發生變化,如果我們的Makefile使用了100處c編譯器的名字,那麼換一個平臺我們只需要重新給預定義變數CC賦值一次即可,而不需要修改100處不同的地方。比如我們換到ARM開發平臺中,只需要重新給CC賦值為arm-linux-gcc即可。(用自定義變數覆蓋系統預定義,實質是變數的值改變了,不再是原本的,而是一個新)
常用的系統預定義變數,請看下表:
| *變數名* | *含義* | *備註* |
|---|---|---|
| AR | 函數庫打包程式,可創建靜態庫.a文檔。預設是“ar”。 | 無 |
| AS | 彙編程式。預設是“as”。 | 無 |
| CC | C編譯程式。預設是“cc”。 | 無 |
| CXX | C++編譯程式。預設是“g++”。 | 無 |
| CPP | C程式的預處理器。預設是“$(CC) –E”。 | 無 |
| RM | 刪除命令。預設是“rm –f”。 | 無 |
| ARFLAGS | 執行AR命令的命令行參數。預設值是“rv”。 | 無 |
| ASFLAGS | 彙編器AS的命令行參數(明確指定“.s”或“.S”文件時)。 | 無 |
| CFLAGS | 執行CC編譯器的命令行參數(編譯.c源文件的選項)。 | 無 |
| CXXFLAGS | 執行g++編譯器的命令行參數(編譯.cc源文件的選項)。 | 無 |
3. 自動化變數
<、@、?、#等等,這些特殊的變數之所以稱為自動化變數,是因為它們的值會“自動地”發生變化,可以類比普通變數,只要你不給它重新賦值,那麼它的值是永久不變的,比如上面的系統預定義CC變數,只要不對它重新賦值,CC永遠都等於gcc。
也就是說自動化變數的值是可以改變的,不是固定的。例如@,不能說 @ 的值等於某個固定值,但是它的含義的固定的:*@* *代表了其所在規則的目標的完整名稱*。
有關自動化變數的詳細情況,見下表:
| *變數名* | *含義* | *備註* |
|---|---|---|
| *@* | *代表其所在規則的目標的完整名稱* | |
| % | 代表其所在規則的靜態庫文件的一個成員名 | |
| *<* | *代表其所在規則的依賴列表的第一個文件的完整名稱* | |
| ? | 代表所有時間戳比目標文件新的依賴文件列表,用空格隔開 | |
| *^* | *代表其所在規則的依賴列表* | *同一文件不可重覆* |
| + | 代表其所在規則的依賴列表 | 同一文件可重覆,主要用在程式鏈接時,庫的交叉引用場合。 |
| * | 在模式規則和靜態模式規則中,代表莖 | 莖是目標模式中“%”所代表的部分(當文件名中存在目錄時,莖也包含目錄(斜杠之前)部分。 |
上述列出的自動量變數中。其中有四個在規則中代表一個文件名(@、<、%和*)。而其它三個的在規則中代表一個文件名的列表。
其中在GUN make中,還可以通過以上這七個自動化變數來獲取一個完整文件名中的目錄部分或者具體文件名,需要在這些變數中加入“D”或者“F”字元。這樣就形成了一系列變種的自動化變數:
| *變數名* | *含義* | *備註* |
|---|---|---|
| @D | 代表目標文件的目錄部分(去掉目錄部分的最後一個斜杠) | 如果“$@”是“dir/foo.o”,那麼“$(@D)”的值為“dir”。如果“$@”不存在斜杠,其值就是“.”(當前目錄)。註意它和函數“dir”的區別 |
| @F | 目標文件的完整文件名中除目錄以外的部分(實際文件名) | 如果“$@”為“dir/foo.o”,那麼“$(@F)”只就是“foo.o”。“$(@F)”等價於函數“$(notdir $@)” |
| *D | 代表目標莖中的目錄部分 | |
| *F | 代表目標莖中的文件名部分 | |
| %D | 當以如“archive(member)”形式靜態庫為目標時,表示庫文件成員“member”名中的目錄部分 | 僅對“archive(member)”形式的規則目標有效 |
| %F | 當以如“archive(member)”形式靜態庫為目標時,表示庫文件成員“member”名中的文件名部分 | 僅對“archive(member)”形式的規則目標有效 |
| <D | 代表規則中第一個依賴文件的目錄部分 | |
| <F | 代表規則中第一個依賴文件的文件名部分 | |
| ^D | 代表所有依賴文件的目錄部分 | 同一文件不可重覆 |
| ^F | 代表所有依賴文件的文件名部分 | 同一文件不可重覆 |
| +D | 代表所有依賴文件的目錄部分 | 同一文件可重覆 |
| +F | 代表所有依賴文件的文件名部分 | 同一文件可重覆 |
| ?D | 代表被更新的依賴文件的目錄部分。 | |
| ?F | 代表被更新的依賴文件的文件名部分。 |
靜態規則
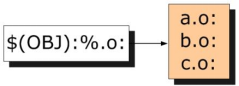
所謂的靜態規則,其工作原理是:$(OBJ)被稱為原始列表,即(a.o b.o x.o y.o),緊跟在其後的%.o被稱為匹配模式,含義是在原始列表中按照這種指定的模式挑選出能匹配得上的單詞(在本例中要找出原始列表裡所有以.o為尾碼的文件)作為規則的目標。如下所示:
gec@ubuntu:~$ cat Makefile -n
1 OBJ = a.o b.o c.o
2
3 image:$(OBJ)
4 $(CC) $(OBJ) -o image
5
6 $(OBJ):%.o:%.c
7 $(CC) $(^) -o $(@) l -c -Wal
8
9 clean:
10 $(RM) $(OBJ) image
11
12 .PHONY: clean
靜態規則工作原理整個過程用下圖演示:
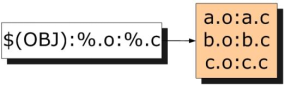
簡單地講,就是用一個規則來生成一系列的目標文件。接著,第二個冒號後面的內容就是目標對應的依賴,%可以理解為通配符,因此本例中%.o:%.c的意思就是:每一個匹配出來的目標所對應的依賴文件是同名的.c文件,這個過程也用圖演示如下:
可見,靜態規則的目的就是用一句話來自動生成很多目標及其依賴,接下來要針對每一對目標-依賴生成對應的編譯語句:
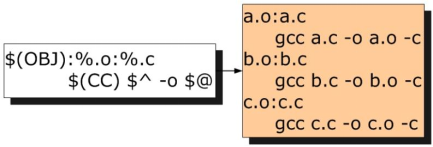
此處可見自動化變數的用武之地了,因為每一對目標-依賴對的名字都不一樣,因此在靜態規則中不可能直接把名字寫死,而要用自動化變數來自動調整為對應的名字。
總結一下,靜態規則是:當規則存在多個目標時,不同的目標可以根據目標文件的名字來自動構造出依賴文件(即只需寫出目標名,即可尋找相應同名字的依賴文件)。


