
本文深入探討了Kubernetes中的Pod調度機制,包括基礎概念、高級調度技術和實際案例分析。文章詳細介紹了Pod調度策略、Taints和Tolerations、節點親和性,以及如何在高流量情況下優化Pod調度和資源管理。 關註【TechLeadCloud】,分享互聯網架構、雲服務技術的全維度知識 ...
本文深入探討了Kubernetes中的Pod調度機制,包括基礎概念、高級調度技術和實際案例分析。文章詳細介紹了Pod調度策略、Taints和Tolerations、節點親和性,以及如何在高流量情況下優化Pod調度和資源管理。
關註【TechLeadCloud】,分享互聯網架構、雲服務技術的全維度知識。作者擁有10+年互聯網服務架構、AI產品研發經驗、團隊管理經驗,同濟本復旦碩,復旦機器人智能實驗室成員,阿裡雲認證的資深架構師,項目管理專業人士,上億營收AI產品研發負責人

一、引言
Kubernetes(簡稱K8s)已成為現代雲計算和容器化環境中不可或缺的一部分。它作為一個強大的容器編排系統,使得部署、管理和擴展應用程式變得高效且自動化。其中,Pod調度是Kubernetes架構中最為關鍵的部分之一,它決定著容器化應用的運行效率、資源利用率以及系統的整體穩定性。
在Kubernetes集群中,Pod是最小的部署單位,代表著一個或多個容器的集合。Pod的調度,即決定這些Pod在集群中的哪個節點上運行,是一個複雜且富有挑戰的過程。正確理解和掌握Pod調度的機制,對於任何使用Kubernetes的組織和技術人員來說,都是至關重要的。
本文將深入探討Kubernetes中的Pod調度機制,從基礎概念到高級技巧,再到實戰案例的分析,旨在為高級技術專家提供一個全面、深入的指南。通過本文,您將瞭解Pod調度的工作原理、如何優化調度策略,以及在複雜環境中應對各種挑戰的方法。
二、Kubernetes Pod基礎
在深入探討Pod調度之前,瞭解什麼是Pod以及它的基本特性非常重要。Pod是Kubernetes中最基本的可部署對象,它代表了集群中的一個應用實例。一個Pod可以包含一個或多個容器,這些容器共用存儲、網路資源,且被設計為緊密協作。
-
Pod的定義和特點:
- 單一實體:儘管一個Pod可以包含多個容器,但它們作為一個整體進行調度和管理。
- 共用資源:Pod內的容器共用IP地址和埠空間,能夠通過
localhost互相通信。 - 臨時性:Pod通常是短暫的,例如在節點故障或調度策略變更時,Pod可能被銷毀和重建。
-
Pod的生命周期:
- Pending:Pod已被創建,但部分容器尚未啟動。
- Running:所有容器都已被創建,至少有一個在運行。
- Succeeded/Failed:所有容器正常終止/至少有一個容器非正常終止。
- Unknown:Pod狀態未知,通常是與Pod通信出現問題。
-
代碼示例:創建一個基本的Pod。
apiVersion: v1 kind: Pod metadata: name: my-pod spec: containers: - name: my-container image: nginx
這個YAML文件定義了一個簡單的Pod,名為my-pod,包含一個名為my-container的容器,使用的鏡像是nginx。
三、Pod調度概念
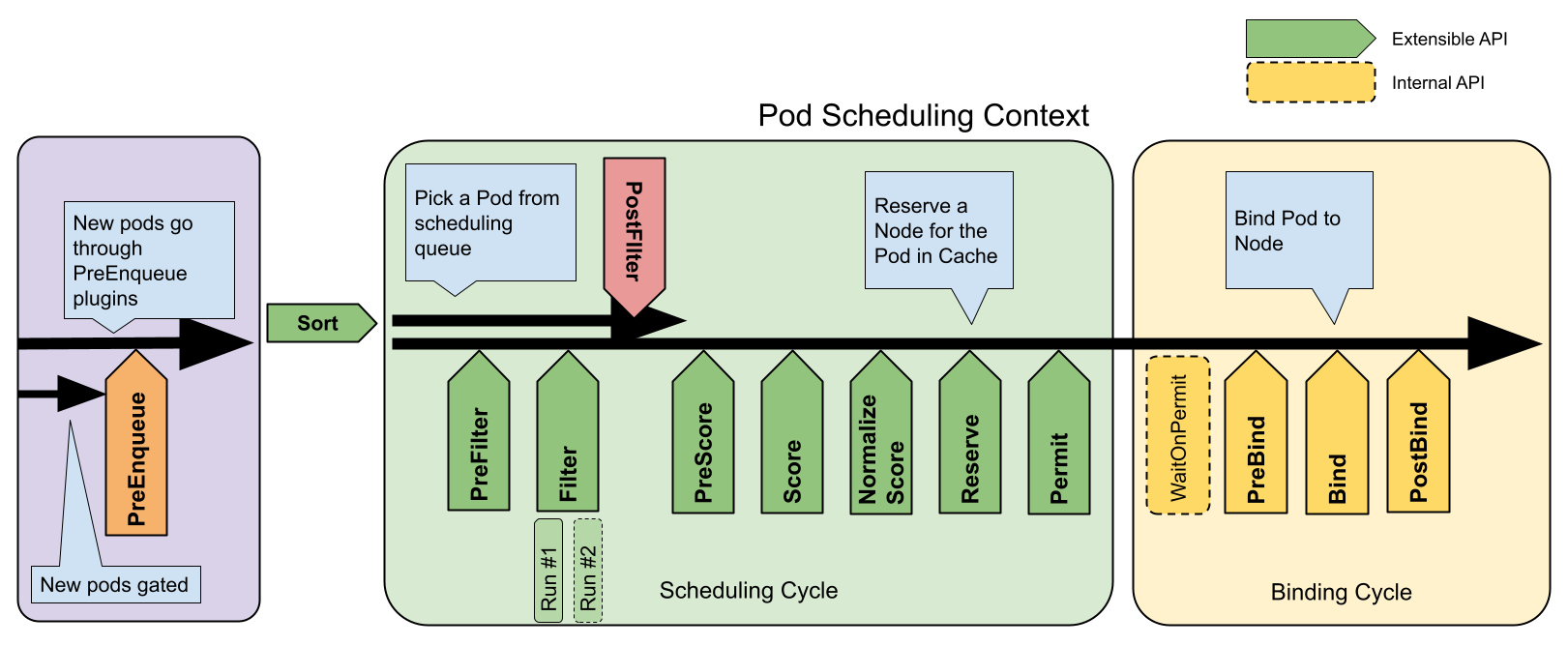
在Kubernetes中,Pod調度是一個決定Pod在哪個節點上運行的過程。這個過程涉及許多複雜的考量,從節點的資源可用性到Pod的特定需求。理解這些概念對於優化應用的性能和可靠性至關重要。
3.1 調度器的工作原理
Kubernetes調度器的主要職責是為新創建的Pod選擇一個合適的節點。調度過程分為兩個主要階段:篩選和打分。
-
篩選階段:在這一階段,調度器檢查所有的節點,以確定哪些節點具備運行該Pod所需的資源(如CPU、記憶體)和其他要求(如節點選擇器標簽)。
-
打分階段:通過篩選的節點接下來會進行打分。調度器根據一系列標準(如節點親和性、資源利用率等)為每個節點評分,最高分的節點將被選為Pod的運行地點。
3.2 調度決策的因素
多種因素可以影響Pod的調度決策:
-
資源需求與限制:Pod規格中可以指定所需的最小資源(如CPU和記憶體)。只有滿足這些要求的節點才會被考慮作為Pod的運行地點。
-
親和性與反親和性:這些設置允許Pod指定它們傾向或避免調度到特定的節點。例如,兩個高度協作的Pod可能會設置親和性規則,以確保它們被調度到相同或相鄰的節點上。
-
污點與容忍:節點可以設置污點以阻止某些Pod在其上運行,除非這些Pod具有匹配的容忍設置。
-
節點選擇器:節點選擇器允許Pod指定應該在具有特定標簽的節點上運行。
3.3 代碼示例:定義Pod的調度策略
下麵是一個YAML文件示例,展示瞭如何為Pod定義調度策略。
apiVersion: v1
kind: Pod
metadata:
name: my-scheduled-pod
spec:
containers:
- name: my-container
image: nginx
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: disktype
operator: In
values:
- ssd
tolerations:
- key: "key"
operator: "Equal"
value: "value"
effect: "NoSchedule"
在這個示例中,Pod被設置為僅在具有disktype:ssd標簽的節點上運行,並且它容忍具有特定污點的節點。
3.4 高級調度功能
Kubernetes還提供了一些高級功能,以支持更複雜的調度需求:
-
Pod親和性與反親和性:這些設置允許Pod指定它們傾向或避免與特定的其他Pod共同調度。
-
自定義調度策略:可以通過編寫自定義調度器來實現更複雜的調度邏輯。
-
優先順序和搶占:Pod可以設置優先順序,較高優先順序的Pod可以搶占
較低優先順序Pod的位置,這對於確保關鍵任務始終有足夠資源非常重要。
3.5 調度策略的動態性
Kubernetes調度器的一個關鍵特性是其動態性。隨著集群狀態的變化(如節點的增加或減少、資源的變化),調度器能夠適應這些變化,重新調整Pod的分配。這種動態性確保了集群資源的有效利用和應用性能的最優化。
3.6 調度器的自定義和擴展
Kubernetes允許通過自定義調度策略和演算法來擴展調度器的功能。這為滿足特定應用需求和優化集群性能提供了巨大的靈活性。例如,可以開發專門的調度器以支持特定的硬體需求,如GPU或高性能計算。
3.7 調度模擬和測試
在實際部署之前,可以使用各種工具和策略來模擬和測試Pod的調度策略。這有助於識別潛在的問題和性能瓶頸,確保在生產環境中的平穩運行。
3.8 環境約束和調度
在某些情況下,環境因素(如數據中心的地理位置、網路拓撲或安全要求)也會影響Pod的調度決策。在設計調度策略時考慮這些約束,對於保證應用的可靠性和合規性至關重要。
四、高級調度技術
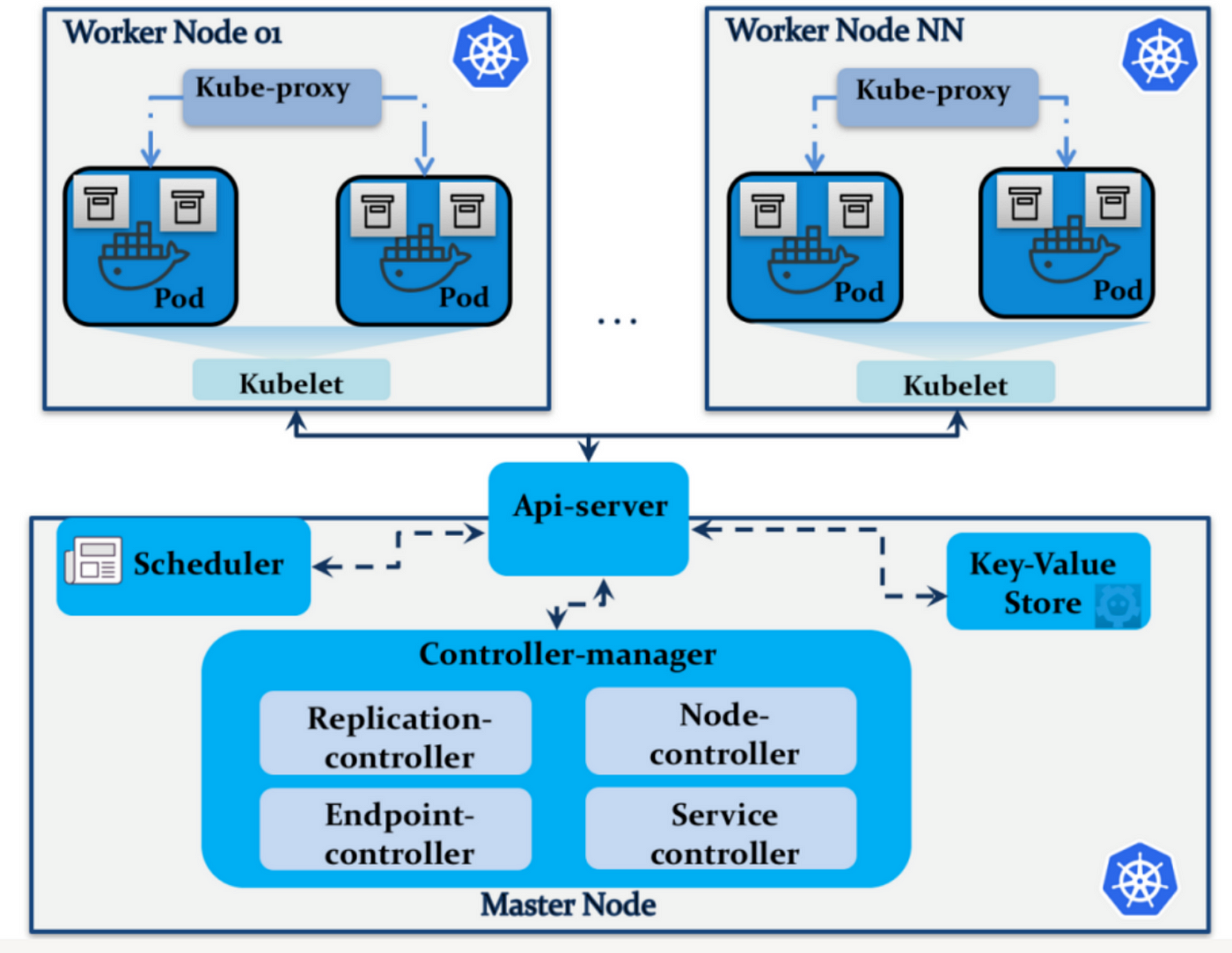
在Kubernetes的世界中,高級調度技術是實現精細化、高效和可靠容器調度的關鍵。這些技術不僅提高了資源利用率,也確保了高性能和高可用性。以下是幾種核心的高級調度技術。
4.1 Taints 和 Tolerations
Taints(污點)和Tolerations(容忍)是Kubernetes中一對強大的功能,用於確保Pod只在適當的節點上運行。
-
Taints:可以在節點上應用taint,這樣只有具有匹配toleration的Pod才能被調度到該節點上。Taints通過三個屬性定義:鍵(key)、值(value)和效果(effect)。效果通常是
NoSchedule(不在此節點上調度新Pod)、PreferNoSchedule(儘量避免調度新Pod)或NoExecute(不調度新Pod且驅逐已存在的Pod)。 -
Tolerations:Pod可以定義tolerations以表明它們可以容忍一個或多個taint。這允許對Pod進行更細粒度的調度控制。
-
應用場景:例如,將
taint應用於擁有特殊硬體(如GPU)的節點,確保只有真正需要這些資源的Pod才能調度到這些節點上。
4.2 節點選擇器和節點親和性
節點選擇器(Node Selector)和節點親和性(Node Affinity)提供了對Pod調度位置的更細緻控制。
-
節點選擇器:簡單但有限的方式來約束Pod可以調度的節點。通過在Pod規格中指定
nodeSelector,Pod只會被調度到具有匹配標簽的節點上。 -
節點親和性:是節點選擇器的擴展,提供了更豐富的表達式,允許您指定規則集合,這些規則可以是硬性的(必須滿足)或軟性的(儘量滿足)。
-
代碼示例:使用節點親和性。
apiVersion: v1 kind: Pod metadata: name: my-pod spec: affinity: nodeAffinity: requiredDuringSchedulingIgnoredDuringExecution: nodeSelectorTerms: - matchExpressions: - key: disktype operator: In values: - ssd
4.3 優先順序和搶占
在資源緊張的環境中,優先順序和搶占機制確保高優先順序的應用可以獲得所需的資源。
-
優先順序:Pod可以有優先順序,高優先順序的Pod可以搶占低優先順序Pod的位置。
-
搶占:當高優先順序的Pod找不到合適的節點時,調度器會嘗試通過驅逐一個或多個低優先順序的Pod來為其騰出空間。
4.4 自定義調度器
Kubernetes允許您創建自定義調度器來替代或並行於預設調度器運行。這提供了極大的靈活性,允許您實現特定於應用的調度邏輯。
-
自定義調度器的創建:可以通過實現新的調度演算法或調整現有策略來創建自定義調度器。
-
多調度器策略:在同一個集群中可以運行多個調度器,不同的Pod可以指定使用不同的調度器。
4.5 跨集群調度
跨集群調度是在多個Kubernetes集群之間進行Pod調度的高級技術,適用於大型或地理分散的部署。
-
聯邦調度:通過Kubernetes聯邦化(Federation),可以管理跨多個集群的資源,使得Pod可以根據負載、資源可用性或地理位置跨集群調度。
-
策略與挑戰:實現跨集群調度需要考慮網路策略、數據一致性和延遲等因素。
4.6 容量調度和擴展
自動化的容量調度和擴展機制允許Pod根據實際負載和性能指標動態調度和擴展。
-
水平Pod自動擴縮容(HPA):根據CPU使用率或其他指標自動增加或減少Pod的數量。
-
集群自動擴縮容(CA):根據需求自動增加或減少集群中的節點數。
4.7 Pod拓撲擴展約束
Pod拓撲擴展約束(Pod Topology Spread Constraints)是一種高級調度特性,用於控制Pod在集群中的分佈,以實現高可用性和容錯性。
-
工作原理:可以指定Pod應該如何跨不同的拓撲域(如節點、區域)分佈,以避免單點故障和提高應用的彈性。
-
應用示例:確保在不同的可用區中運行Pod的副本,以防止區域性故障影響服務。
4.8 調度器插件和擴展點
Kubernetes調度器支持插件化,允許在調度過程中的不同階段插入自定義邏輯。
-
調度器擴展點:包括預過濾、過濾、後過濾、評分、歸一化評分等。
-
自定義插件:可以開發插件來實現特定的調度需求,如基於應用特定指標的調度決策。
4.9 容器資源管理和調度
容器資源管理對於優化Pod的性能和調度至關重要。
-
資源請求和限制:在Pod規格中指定CPU和記憶體的請求和限制,以確保Pod獲得必要的資源。
-
資源過載和搶占:處理資源緊張的情況,如何在保證關鍵服務運行的同時進行資源搶占。
五、案例研究:實戰應用
場景描述
假設我們有一個大型電子商務平臺,該平臺使用Kubernetes集群來部署和管理其服務。在特定的促銷活動期間,流量激增,對應用的可用性和性能提出了極高的要求。為了應對這種流量峰值,我們需要確保Pod能夠有效地調度,並且資源得到合理利用。
遇到的問題
- 資源瓶頸:在流量高峰期間,某些節點由於過度負載而響應緩慢,導致服務中斷。
- 調度延遲:由於突發的高流量,新Pod的啟動和調度出現了明顯的延遲。
- 不均衡的資源分佈:一些節點資源利用率過高,而其他節點則資源閑置。
解決方案
1.自動擴縮容
利用Kubernetes的水平Pod自動擴縮容(HPA)和集群自動擴縮容(CA)特性來動態管理資源。
- HPA:根據CPU和記憶體使用情況自動增減Pod的數量,以應對流量變化。
- CA:在需要時增加更多的節點,併在流量下降時減少節點,以節省成本。
2.優化Pod調度策略
調整Pod的調度策略,確保Pod在集群中均勻分佈,避免某些節點過載。
- Pod親和性和反親和性:通過定義適當的親和性規則,確保相關服務的Pod分佈在不同的節點上,以提高可用性。
- Pod拓撲擴展約束:確保Pod在不同的可用區均勻分佈,避免單一區域的故障影響整個服務。
3.高級調度特性的應用
使用Taints和Tolerations以及自定義調度器來進一步優化資源分配。
- Taints和Tolerations:為處理高流量的節點設置taints,只允許具有特定tolerations的Pod在這些節點上運行。
- 自定義調度器:開發一個自定義調度器,根據實時流量和資源使用情況來優化Pod的調度決策。
4.性能監控和實時調整
實施全面的監控和日誌記錄系統,以實時追蹤集群的性能和資源使用情況。
- 監控工具:使用Prometheus和Grafana等工具監控資源使用情況和服務性能。
- 實時調整:
基於監控數據,快速調整調度策略和資源分配,以應對實時的性能需求和資源限制。
5.災難恢復和故障轉移
建立災難恢復計劃和故障轉移機制,以確保服務在遇到不可預見的問題時仍能持續運行。
- 多區域部署:將服務部署在不同的地理位置,確保單一區域的故障不會影響整個平臺。
- 快速恢復策略:實現快速故障檢測和自動化恢復流程,減少服務中斷時間。
6.測試和優化
在生產部署之前進行全面的測試,包括壓力測試和性能測試,以驗證調度策略和資源配置的有效性。
- 性能測試:模擬高流量情況,測試系統的響應能力和資源分配的有效性。
- 優化迭代:根據測試結果對調度策略和資源配置進行調整和優化。
7.反饋迴圈和持續改進
建立反饋機制,持續收集和分析性能數據,以不斷改進調度策略和資源管理。
- 持續監控:實施持續的性能監控,確保及時發現並解決任何問題。
- 改進迭代:基於收集的數據和反饋進行持續的調度策略和資源管理優化。
關註【TechLeadCloud】,分享互聯網架構、雲服務技術的全維度知識。作者擁有10+年互聯網服務架構、AI產品研發經驗、團隊管理經驗,同濟本復旦碩,復旦機器人智能實驗室成員,阿裡雲認證的資深架構師,項目管理專業人士,上億營收AI產品研發負責人
如有幫助,請多關註
TeahLead KrisChang,10+年的互聯網和人工智慧從業經驗,10年+技術和業務團隊管理經驗,同濟軟體工程本科,復旦工程管理碩士,阿裡雲認證雲服務資深架構師,上億營收AI產品業務負責人。


