
SQL 不同於與其他編程語言的最明顯特征是處理代碼的順序。在大數編程語言中,代碼按編碼順序被處理,但是在SQL語言中,第一個被處理的子句是FROM子句,儘管SELECT語句第一個出現,但是幾乎總是最後被處理。 每個步驟都會產生一個虛擬表,該虛擬表被用作下一個步驟的輸入。這些虛擬表對調用者(客戶端應用 ...
SQL 不同於與其他編程語言的最明顯特征是處理代碼的順序。在大數編程語言中,代碼按編碼順序被處理,但是在SQL語言中,第一個被處理的子句是FROM子句,儘管SELECT語句第一個出現,但是幾乎總是最後被處理。
每個步驟都會產生一個虛擬表,該虛擬表被用作下一個步驟的輸入。這些虛擬表對調用者(客戶端應用程式或者外部查詢)不可用。只是最後一步生成的表才會返回 給調用者。如果沒有在查詢中指定某一子句,將跳過相應的步驟。
先來一段偽代碼,首先你能看懂麽?
SELECT DISTINCT <select_list> FROM <left_table> <join_type> JOIN <right_table> ON <join_condition> WHERE <where_condition> GROUP BY <group_by_list> HAVING <having_condition> ORDER BY <order_by_condition> LIMIT <limit_number>
如果你知道每個關鍵字的意思,作用,如果你還用過的話,那再好不過了。但是,你知道這些語句,它們的執行順序你清楚麽?
準備工作
首先聲明下,一切測試操作都是在MySQL資料庫上完成,關於MySQL資料庫的一些簡單操作,請閱讀一下文章:
繼續做以下的前期準備工作:
1、新建一個測試資料庫TestDB;
create database TestDB;
2、創建測試表table1和table2;
CREATE TABLE table1 ( customer_id VARCHAR(10) NOT NULL, city VARCHAR(10) NOT NULL, PRIMARY KEY(customer_id) )ENGINE=INNODB DEFAULT CHARSET=UTF8; CREATE TABLE table2 ( order_id INT NOT NULL auto_increment, customer_id VARCHAR(10), PRIMARY KEY(order_id) )ENGINE=INNODB DEFAULT CHARSET=UTF8;
3、插入測試數據;
INSERT INTO table1(customer_id,city) VALUES('163','hangzhou'); INSERT INTO table1(customer_id,city) VALUES('9you','shanghai'); INSERT INTO table1(customer_id,city) VALUES('tx','hangzhou'); INSERT INTO table1(customer_id,city) VALUES('baidu','hangzhou'); INSERT INTO table2(customer_id) VALUES('163'); INSERT INTO table2(customer_id) VALUES('163'); INSERT INTO table2(customer_id) VALUES('9you'); INSERT INTO table2(customer_id) VALUES('9you'); INSERT INTO table2(customer_id) VALUES('9you'); INSERT INTO table2(customer_id) VALUES('tx'); INSERT INTO table2(customer_id) VALUES(NULL);
準備工作做完以後,table1和table2看起來應該像下麵這樣:
mysql> select * from table1; +-------------+----------+ | customer_id | city | +-------------+----------+ | 163 | hangzhou | | 9you | shanghai | | baidu | hangzhou | | tx | hangzhou | +-------------+----------+ 4 rows in set (0.00 sec) mysql> select * from table2; +----------+-------------+ | order_id | customer_id | +----------+-------------+ | 1 | 163 | | 2 | 163 | | 3 | 9you | | 4 | 9you | | 5 | 9you | | 6 | tx | | 7 | NULL | +----------+-------------+ 7 rows in set (0.00 sec)
4、準備SQL邏輯查詢測試語句
SELECT a.customer_id, COUNT(b.order_id) as total_orders FROM table1 AS a LEFT JOIN table2 AS b ON a.customer_id = b.customer_id WHERE a.city = 'hangzhou' GROUP BY a.customer_id HAVING count(b.order_id) < 2 ORDER BY total_orders DESC;
使用上述SQL查詢語句來獲得來自杭州,並且訂單數少於2的客戶。
SQL邏輯查詢語句執行順序
還記得上面給出的那一長串的SQL邏輯查詢規則麽?那麼,到底哪個先執行,哪個後執行呢?現在,我先給出一個查詢語句的執行順序:
(7) SELECT (8) DISTINCT <select_list> (1) FROM <left_table> (3) <join_type> JOIN <right_table> (2) ON <join_condition> (4) WHERE <where_condition> (5) GROUP BY <group_by_list> (6) HAVING <having_condition> (9) ORDER BY <order_by_condition> (10) LIMIT <limit_number>
上面在每條語句的前面都標明瞭執行順序號,那麼各條查詢語句是如何執行的呢?
邏輯查詢處理階段簡介
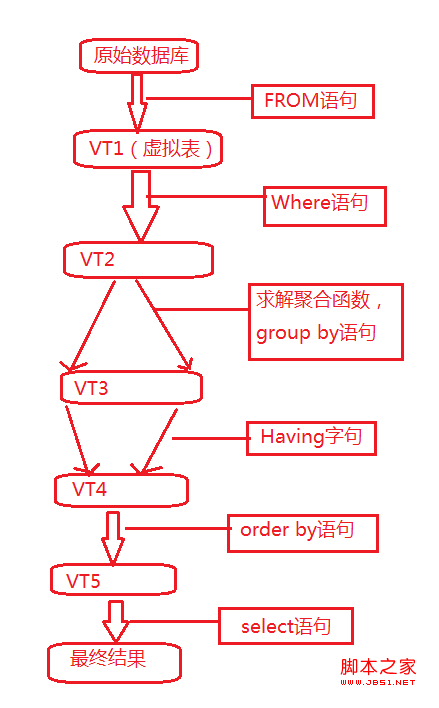
- FROM:對FROM子句中的前兩個表執行笛卡爾積(Cartesian product)(交叉聯接),生成虛擬表VT1
- ON:對VT1應用ON篩選器。只有那些使<join_condition>為真的行才被插入VT2。
- OUTER(JOIN):如 果指定了OUTER JOIN(相對於CROSS JOIN 或(INNER JOIN),保留表(preserved table:左外部聯接把左表標記為保留表,右外部聯接把右表標記為保留表,完全外部聯接把兩個表都標記為保留表)中未找到匹配的行將作為外部行添加到 VT2,生成VT3.如果FROM子句包含兩個以上的表,則對上一個聯接生成的結果表和下一個表重覆執行步驟1到步驟3,直到處理完所有的表為止。
- WHERE:對VT3應用WHERE篩選器。只有使<where_condition>為true的行才被插入VT4.
- GROUP BY:按GROUP BY子句中的列列表對VT4中的行分組,生成VT5.
- CUBE|ROLLUP:把超組(Suppergroups)插入VT5,生成VT6.
- HAVING:對VT6應用HAVING篩選器。只有使<having_condition>為true的組才會被插入VT7.
- SELECT:處理SELECT列表,產生VT8.
- DISTINCT:將重覆的行從VT8中移除,產生VT9.
- ORDER BY:將VT9中的行按ORDER BY 子句中的列列表排序,生成游標(VC10).
- TOP:從VC10的開始處選擇指定數量或比例的行,生成表VT11,並返回調用者。
註:步驟10,按ORDER BY子句中的列列表排序上步返回的行,返回游標VC10.這一步是第一步也是唯一一步可以使用SELECT列表中的列別名的步驟。這一步不同於其它步驟的 是,它不返回有效的表,而是返回一個游標。SQL是基於集合理論的。集合不會預先對它的行排序,它只是成員的邏輯集合,成員的順序無關緊要。對錶進行排序 的查詢可以返回一個對象,包含按特定物理順序組織的行。ANSI把這種對象稱為游標。理解這一步是正確理解SQL的基礎。
因為這一步不返回表(而是返回游標),使用了ORDER BY子句的查詢不能用作表表達式。表表達式包括:視圖、內聯表值函數、子查詢、派生表和共用表達式。它的結果必須返回給期望得到物理記錄的客戶端應用程式。例如,下麵的派生表查詢無效,並產生一個錯誤:
select * from(select orderid,customerid from orders order by orderid) as d
下麵的視圖也會產生錯誤:
create view my_view as select * from orders order by orderid
在SQL中,表表達式中不允許使用帶有ORDER BY子句的查詢,而在T—SQL中卻有一個例外(應用TOP選項)。
所以要記住,不要為表中的行假設任何特定的順序。換句話說,除非你確定要有序行,否則不要指定ORDER BY 子句。排序是需要成本的。
# 執行FROM語句
在這些SQL語句的執行過程中,都會產生一個虛擬表,用來保存SQL語句的執行結果(這是重點),我現在就來跟蹤這個虛擬表的變化,得到最終的查詢結果的過程,來分析整個SQL邏輯查詢的執行順序和過程。
第一步,執行FROM語句。我們首先需要知道最開始從哪個表開始的,這就是FROM告訴我們的。現在有了<left_table>和<right_table>兩個表,我們到底從哪個表開始,還是從兩個表進行某種聯繫以後再開始呢?它們之間如何產生聯繫呢?——笛卡爾積
關於什麼是笛卡爾積,請自行Google補腦。經過FROM語句對兩個表執行笛卡爾積,會得到一個虛擬表,暫且叫VT1(vitual table 1),內容如下:
+-------------+----------+----------+-------------+ | customer_id | city | order_id | customer_id | +-------------+----------+----------+-------------+ | 163 | hangzhou | 1 | 163 | | 9you | shanghai | 1 | 163 | | baidu | hangzhou | 1 | 163 | | tx | hangzhou | 1 | 163 | | 163 | hangzhou | 2 | 163 | | 9you | shanghai | 2 | 163 | | baidu | hangzhou | 2 | 163 | | tx | hangzhou | 2 | 163 | | 163 | hangzhou | 3 | 9you | | 9you | shanghai | 3 | 9you | | baidu | hangzhou | 3 | 9you | | tx | hangzhou | 3 | 9you | | 163 | hangzhou | 4 | 9you | | 9you | shanghai | 4 | 9you | | baidu | hangzhou | 4 | 9you | | tx | hangzhou | 4 | 9you | | 163 | hangzhou | 5 | 9you | | 9you | shanghai | 5 | 9you | | baidu | hangzhou | 5 | 9you | | tx | hangzhou | 5 | 9you | | 163 | hangzhou | 6 | tx | | 9you | shanghai | 6 | tx | | baidu | hangzhou | 6 | tx | | tx | hangzhou | 6 | tx | | 163 | hangzhou | 7 | NULL | | 9you | shanghai | 7 | NULL | | baidu | hangzhou | 7 | NULL | | tx | hangzhou | 7 | NULL | +-------------+----------+----------+-------------+
總共有28(table1的記錄條數 * table2的記錄條數)條記錄。這就是VT1的結果,接下來的操作就在VT1的基礎上進行。
# 執行ON過濾
執行完笛卡爾積以後,接著就進行ON a.customer_id = b.customer_id條件過濾,根據ON中指定的條件,去掉那些不符合條件的數據,得到VT2表,內容如下:
+-------------+----------+----------+-------------+ | customer_id | city | order_id | customer_id | +-------------+----------+----------+-------------+ | 163 | hangzhou | 1 | 163 | | 163 | hangzhou | 2 | 163 | | 9you | shanghai | 3 | 9you | | 9you | shanghai | 4 | 9you | | 9you | shanghai | 5 | 9you | | tx | hangzhou | 6 | tx | +-------------+----------+----------+-------------+
VT2就是經過ON條件篩選以後得到的有用數據,而接下來的操作將在VT2的基礎上繼續進行。
# 添加外部行
這一步只有在連接類型為OUTER JOIN時才發生,如LEFT OUTER JOIN、RIGHT OUTER JOIN和FULL OUTER JOIN。在大多數的時候,我們都是會省略掉OUTER關鍵字的,但OUTER表示的就是外部行的概念。
LEFT OUTER JOIN把左表記為保留表,得到的結果為:
+-------------+----------+----------+-------------+ | customer_id | city | order_id | customer_id | +-------------+----------+----------+-------------+ | 163 | hangzhou | 1 | 163 | | 163 | hangzhou | 2 | 163 | | 9you | shanghai | 3 | 9you | | 9you | shanghai | 4 | 9you | | 9you | shanghai | 5 | 9you | | tx | hangzhou | 6 | tx | | baidu | hangzhou | NULL | NULL | +-------------+----------+----------+-------------+
RIGHT OUTER JOIN把右表記為保留表,得到的結果為:
+-------------+----------+----------+-------------+ | customer_id | city | order_id | customer_id | +-------------+----------+----------+-------------+ | 163 | hangzhou | 1 | 163 | | 163 | hangzhou | 2 | 163 | | 9you | shanghai | 3 | 9you | | 9you | shanghai | 4 | 9you | | 9you | shanghai | 5 | 9you | | tx | hangzhou | 6 | tx | | NULL | NULL | 7 | NULL | +-------------+----------+----------+-------------+
FULL OUTER JOIN把左右表都作為保留表,得到的結果為:
+-------------+----------+----------+-------------+ | customer_id | city | order_id | customer_id | +-------------+----------+----------+-------------+ | 163 | hangzhou | 1 | 163 | | 163 | hangzhou | 2 | 163 | | 9you | shanghai | 3 | 9you | | 9you | shanghai | 4 | 9you | | 9you | shanghai | 5 | 9you | | tx | hangzhou | 6 | tx | | baidu | hangzhou | NULL | NULL | | NULL | NULL | 7 | NULL | +-------------+----------+----------+-------------+
添加外部行的工作就是在VT2表的基礎上添加保留表中被過濾條件過濾掉的數據,非保留表中的數據被賦予NULL值,最後生成虛擬表VT3。
由於我在準備的測試SQL查詢邏輯語句中使用的是LEFT JOIN,過濾掉了以下這條數據:
| baidu | hangzhou | NULL | NULL |
現在就把這條數據添加到VT2表中,得到的VT3表如下:
+-------------+----------+----------+-------------+ | customer_id | city | order_id | customer_id | +-------------+----------+----------+-------------+ | 163 | hangzhou | 1 | 163 | | 163 | hangzhou | 2 | 163 | | 9you | shanghai | 3 | 9you | | 9you | shanghai | 4 | 9you | | 9you | shanghai | 5 | 9you | | tx | hangzhou | 6 | tx | | baidu | hangzhou | NULL | NULL | +-------------+----------+----------+-------------+
接下來的操作都會在該VT3表上進行。
# 執行WHERE過濾
對添加外部行得到的VT3進行WHERE過濾,只有符合<where_condition>的記錄才會輸出到虛擬表VT4中。當我們執行WHERE a.city = 'hangzhou'的時候,就會得到以下內容,並存在虛擬表VT4中:
+-------------+----------+----------+-------------+ | customer_id | city | order_id | customer_id | +-------------+----------+----------+-------------+ | 163 | hangzhou | 1 | 163 | | 163 | hangzhou | 2 | 163 | | tx | hangzhou | 6 | tx | | baidu | hangzhou | NULL | NULL | +-------------+----------+----------+-------------+
但是在使用WHERE子句時,需要註意以下兩點:
- 由於數據還沒有分組,因此現在還不能在WHERE過濾器中使用
where_condition=MIN(col)這類對分組統計的過濾; - 由於還沒有進行列的選取操作,因此在SELECT中使用列的別名也是不被允許的,如:
SELECT city as c FROM t WHERE c='shanghai';是不允許出現的。
# 執行GROUP BY分組
GROU BY子句主要是對使用WHERE子句得到的虛擬表進行分組操作。我們執行測試語句中的GROUP BY a.customer_id,就會得到以下內容:
+-------------+----------+----------+-------------+ | customer_id | city | order_id | customer_id | +-------------+----------+----------+-------------+ | 163 | hangzhou | 1 | 163 | | baidu | hangzhou | NULL | NULL | | tx | hangzhou | 6 | tx | +-------------+----------+----------+-------------+
得到的內容會存入虛擬表VT5中,此時,我們就得到了一個VT5虛擬表,接下來的操作都會在該表上完成。
# 執行HAVING過濾
HAVING子句主要和GROUP BY子句配合使用,對分組得到的VT5虛擬表進行條件過濾。當我執行測試語句中的HAVING count(b.order_id) < 2時,將得到以下內容:
+-------------+----------+----------+-------------+ | customer_id | city | order_id | customer_id | +-------------+----------+----------+-------------+ | baidu | hangzhou | NULL | NULL | | tx | hangzhou | 6 | tx | +-------------+----------+----------+-------------+
這就是虛擬表VT6。
# SELECT列表
現在才會執行到SELECT子句,不要以為SELECT子句被寫在第一行,就是第一個被執行的。
我們執行測試語句中的SELECT a.customer_id, COUNT(b.order_id) as total_orders,從虛擬表VT6中選擇出我們需要的內容。我們將得到以下內容:
+-------------+--------------+ | customer_id | total_orders | +-------------+--------------+ | baidu | 0 | | tx | 1 | +-------------+--------------+
不,還沒有完,這隻是虛擬表VT7。
# 執行DISTINCT子句
如果在查詢中指定了DISTINCT子句,則會創建一張記憶體臨時表(如果記憶體放不下,就需要存放在硬碟了)。這張臨時表的表結構和上一步產生的虛擬表VT7是一樣的,不同的是對進行DISTINCT操作的列增加了一個唯一索引,以此來除重覆數據。
由於我的測試SQL語句中並沒有使用DISTINCT,所以,在該查詢中,這一步不會生成一個虛擬表。
# 執行ORDER BY子句
對虛擬表中的內容按照指定的列進行排序,然後返回一個新的虛擬表,我們執行測試SQL語句中的ORDER BY total_orders DESC,就會得到以下內容:
+-------------+--------------+ | customer_id | total_orders | +-------------+--------------+ | tx | 1 | | baidu | 0 | +-------------+--------------+
可以看到這是對total_orders列進行降序排列的。上述結果會存儲在VT8中。
執行LIMIT子句
LIMIT子句從上一步得到的VT8虛擬表中選出從指定位置開始的指定行數據。對於沒有應用ORDER BY的LIMIT子句,得到的結果同樣是無序的,所以,很多時候,我們都會看到LIMIT子句會和ORDER BY子句一起使用。
MySQL資料庫的LIMIT支持如下形式的選擇:
LIMIT n, m
表示從第n條記錄開始選擇m條記錄。而很多開發人員喜歡使用該語句來解決分頁問題。對於小數據,使用LIMIT子句沒有任何問題,當數據量非常大的時候,使用LIMIT n, m是非常低效的。因為LIMIT的機制是每次都是從頭開始掃描,如果需要從第60萬行開始,讀取3條數據,就需要先掃描定位到60萬行,然後再進行讀取,而掃描的過程是一個非常低效的過程。所以,對於大數據處理時,是非常有必要在應用層建立一定的緩存機制(貌似現在的大數據處理,都有緩存哦)。
參考文檔:


