
內容介紹 hive on spark的調優,那必然涉及到這一系列框架的記憶體模型。本章就是來講一下這些框架的記憶體模型。 hive on spark的任務,從開始到結束。總共涉及了3個框架。分別是:yarn、hive、spark 其中,hive只是一個客戶端的角色。就不涉及任務運行時的記憶體。所以這裡主要 ...
內容介紹
hive on spark的調優,那必然涉及到這一系列框架的記憶體模型。本章就是來講一下這些框架的記憶體模型。
hive on spark的任務,從開始到結束。總共涉及了3個框架。分別是:yarn、hive、spark
其中,hive只是一個客戶端的角色。就不涉及任務運行時的記憶體。所以這裡主要講的yarn和spark的記憶體模型。
其中,由於spark是運行在yarn的container中。所以我們從外到內。先將yarn的資源分配。後講spark的記憶體模型。
hive on spark提交流程
hive階段
首先上場的是hive框架。當我們寫了一個SQL語句的時候,會被hive進行解析(hive用的SQL解析框架是Antlr4)。解析的流程是:
- 解析器將SQL解析成AST(抽象語法樹)
- 邏輯生成器
- 邏輯優化器 (這裡主要做一些謂詞下推的操作)
- 物理生成器
- 物理優化器(這裡則是做基於代價的優化,簡稱CBO)
- 執行器 (在這裡就會將Spark任務提交給yarn)
這裡是進行物理優化器的地方,可以看見,從這裡開始,就已經根據引擎的不同,進行不同的優化了。
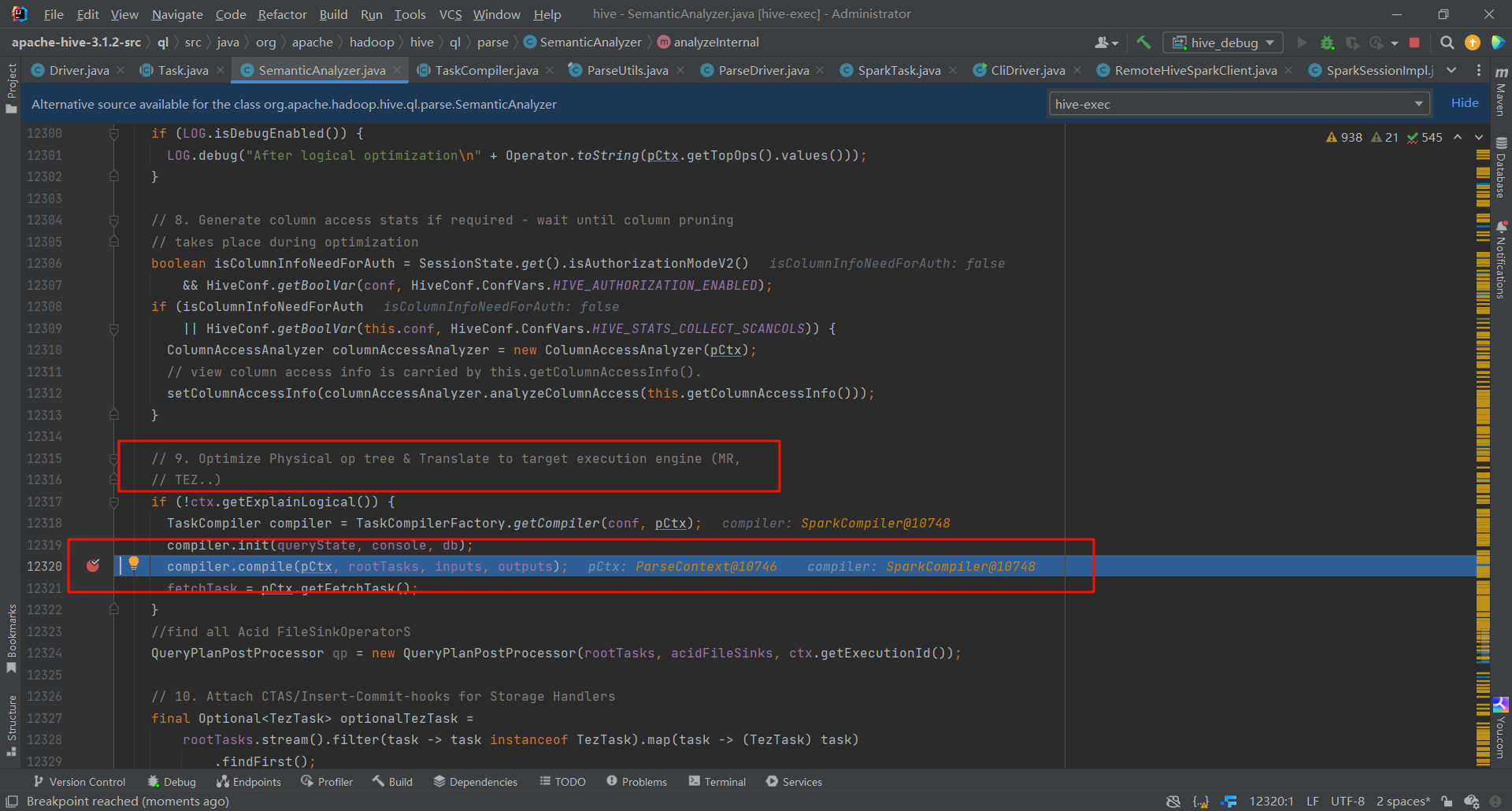
此處就是執行器
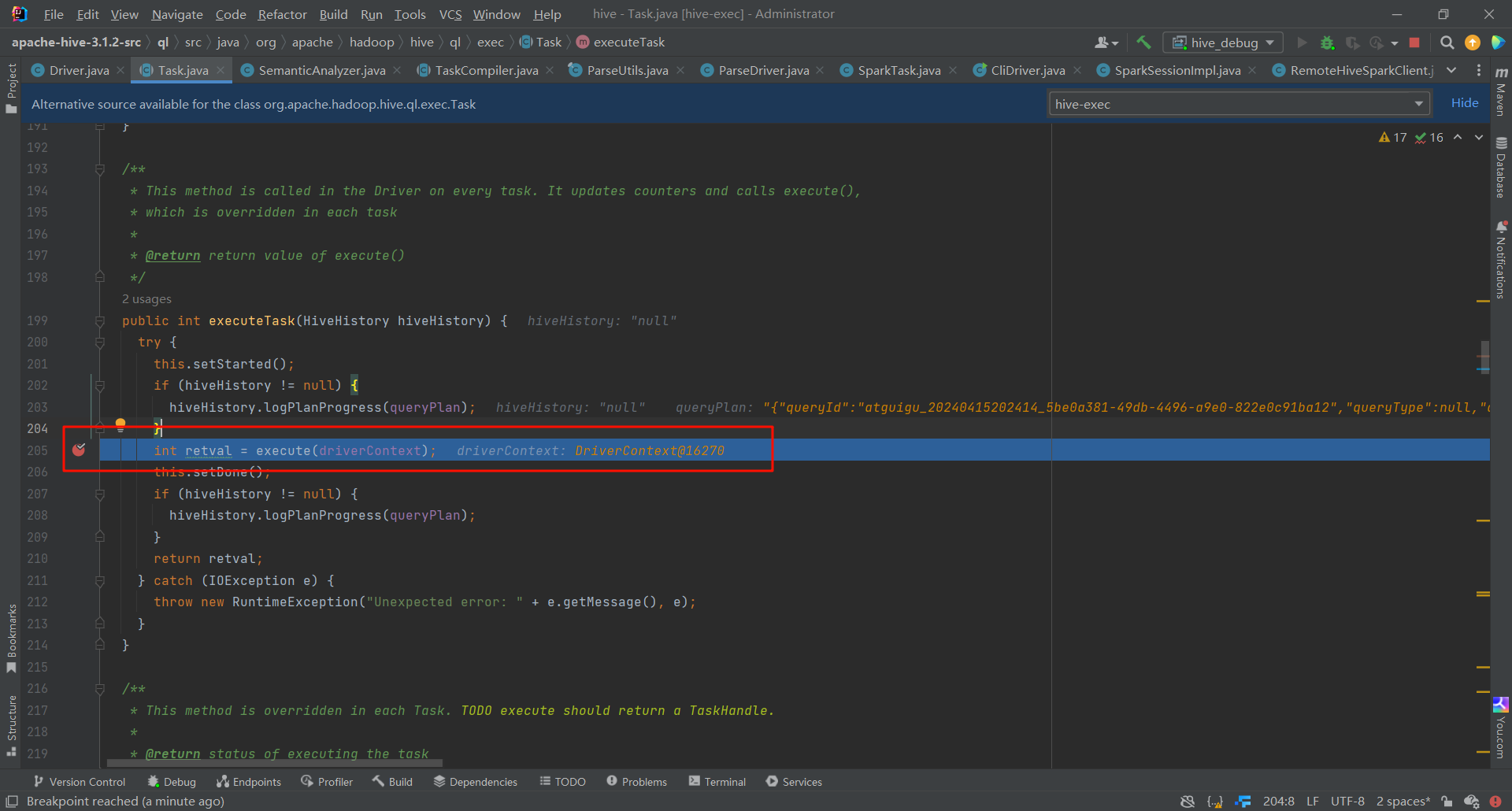
我們進去之後就可以看見 提交Spark任務
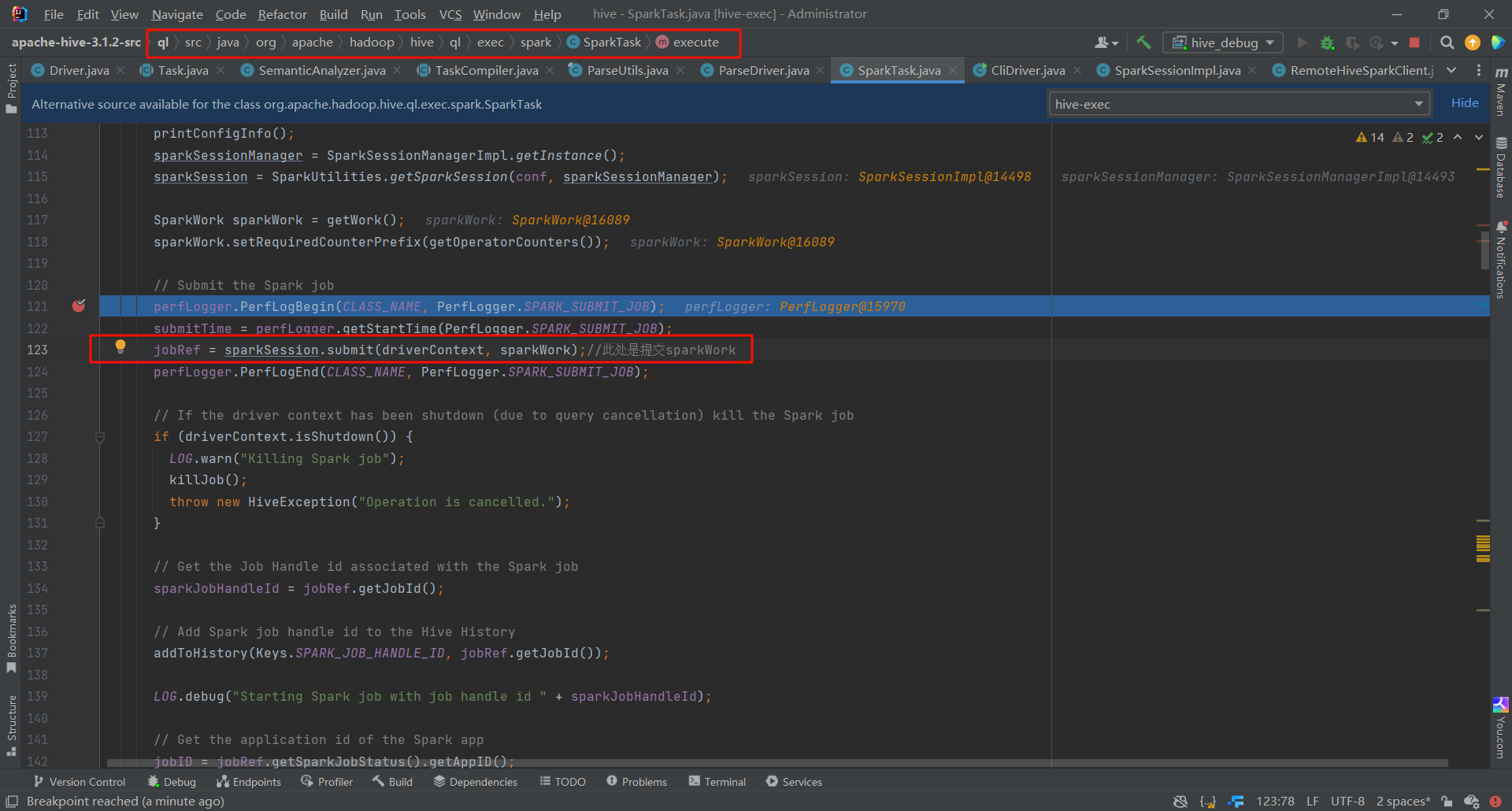
我們可以在這裡看見,把job上傳到yarn上,並且添加了一些監聽器來獲取job的狀態
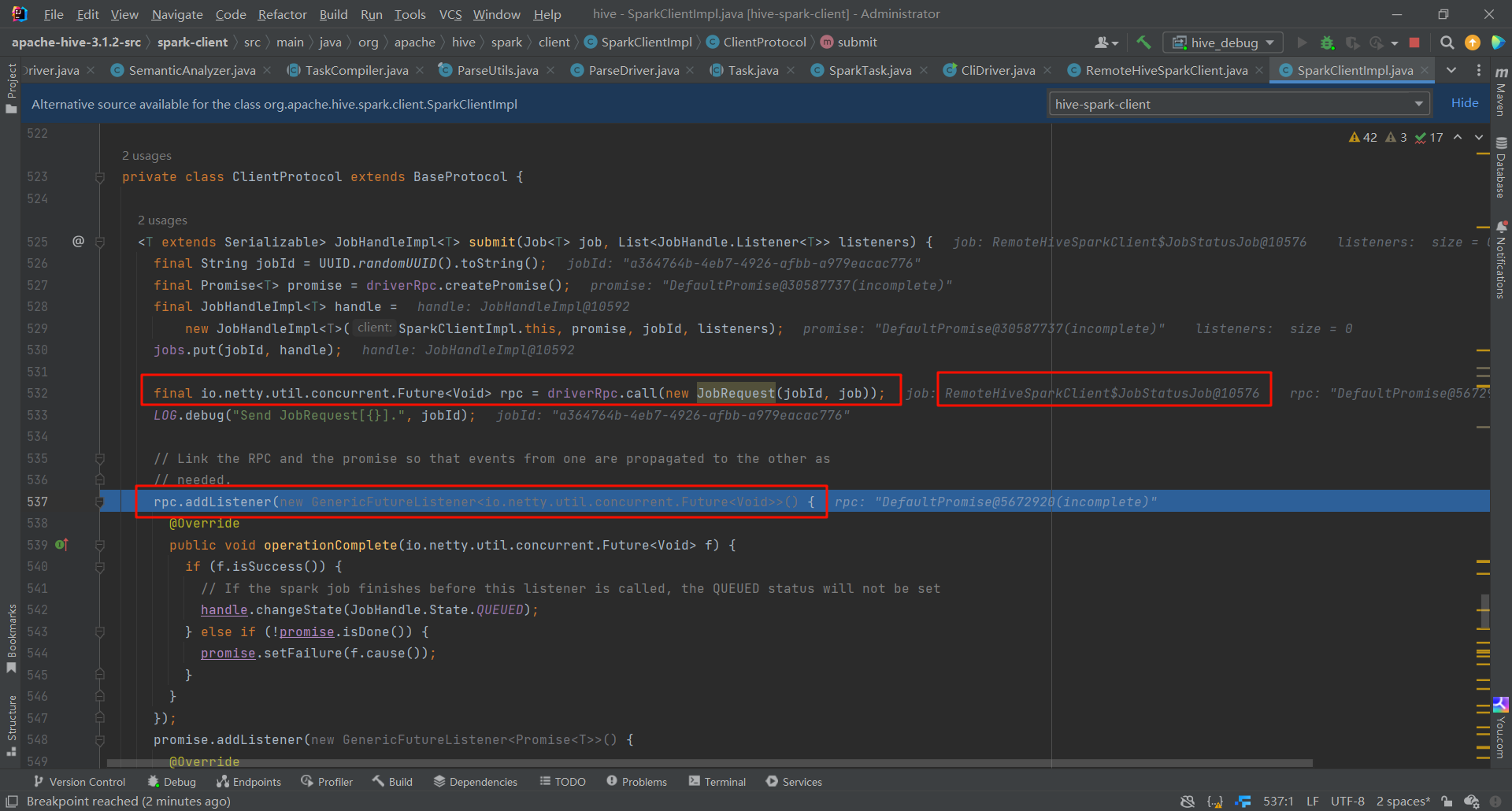
這樣之後,SQL就會被轉為Spark一系列的RDD。
yarn資源
在hive中,我們已經把spark job提交到yarn上面。現在我們就來看一下yarn的記憶體模型。
yarn的組成很簡單,有ResourceManager和NodeManager,其中ResourceManager是大哥。對客戶端傳來的請求做處理。NodeManager是小弟。負責運行任務。
就此而言,我們就可以做出一個簡單的判斷:對於資源(記憶體和CPU)的分配,我們要多給NodeManager資源。ResourceManager無需很多的資源。因為ResourceManager僅僅是處理客戶端的請求和管理NodeManager。並不進行任務的計算。
NodeManager裡面是很多的Container,我們的Spark任務就是跑在Container裡面的。
yarn中關於資源的參數
由於spark任務是跑在NodeManager下的Container中。所以我們可以對NodeManager和Contaniner進行參數的調整(資源的配置)
NodeManager的參數
- yarn.nodemanager.resource.memory-mb : NodeManager可以給Container分配記憶體
- yarn.nodemanager.resource.cpu-vcores :NodeManager可以給Container分配的虛擬核數(因為不同的CPU可能計算能力不同。有可能一個i7的CPU頂兩個i5的。所以就可以把i7的cpu映射為兩個虛擬核。這樣的話,就不會出現因為CPU的差異,而導致的:相同的任務跑多次。每次所耗的時間相差特別大。)
Container的參數
- yarn.scheduler.maximum-allocation-mb : 單個Container可以使用的最大記憶體
- yarn.scheduler.minimum-allocation-mb : 單個Container可以使用的最小記憶體
Spark資源
Spark的記憶體模型可以大致分為堆內記憶體和堆外記憶體
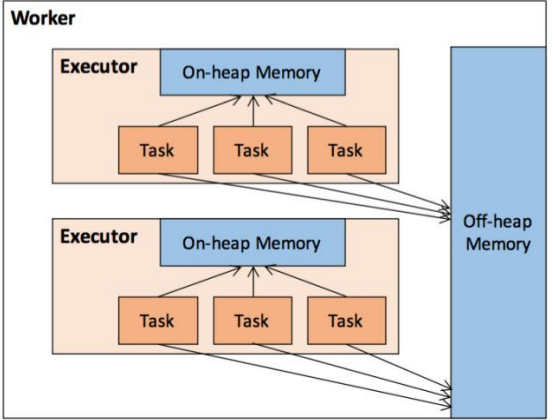
堆內記憶體
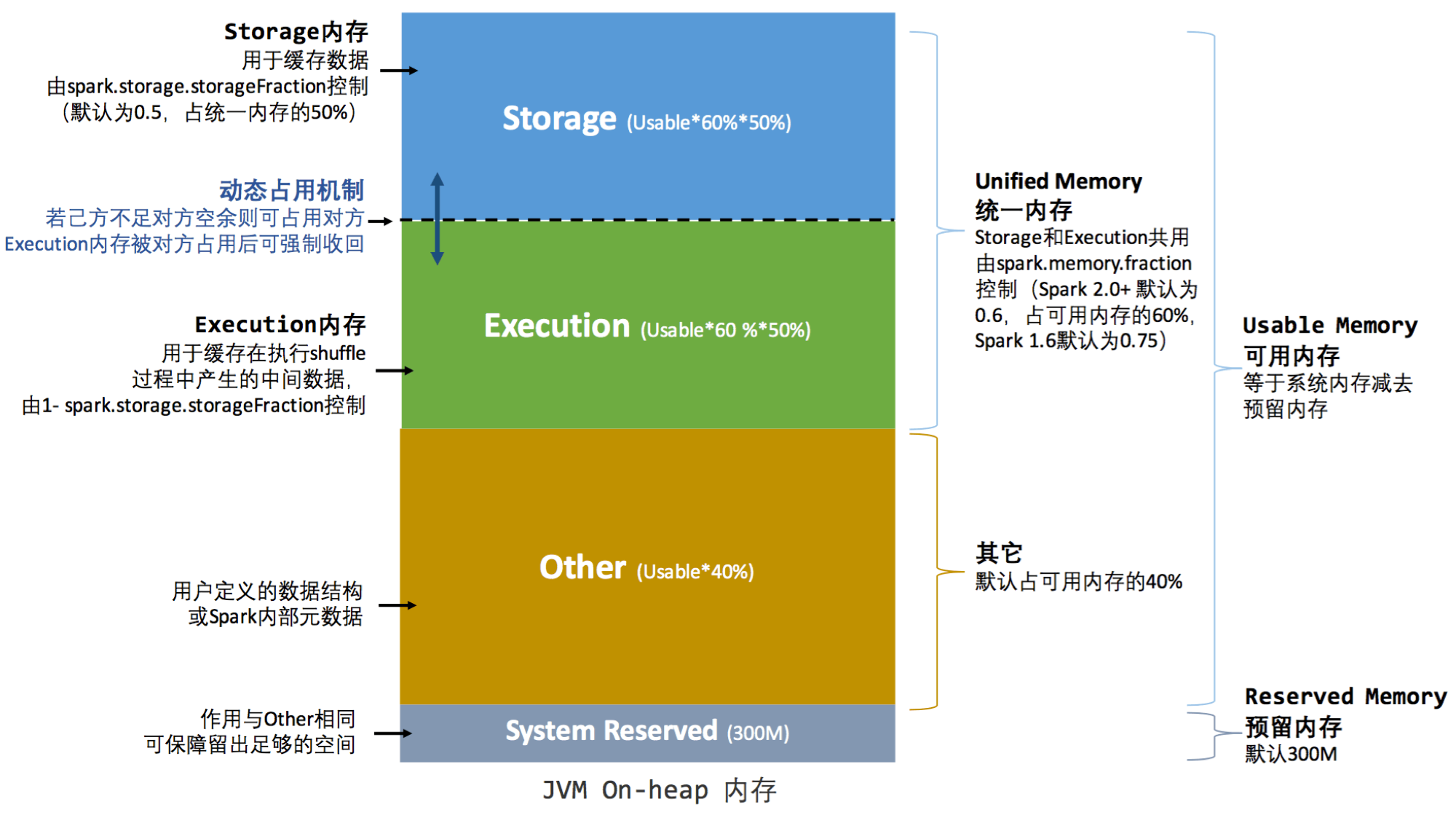
動態占用機制:簡單的來說,
- 當存儲和執行的記憶體都不足時。存儲會存放到硬碟。
- 當存儲占用了執行的記憶體後,執行想收回記憶體時。存儲會將占用的部分轉存到硬碟。歸還記憶體
- 當執行占用了存儲的記憶體後,存儲想收回記憶體時,執行無法歸還記憶體。需要等到執行使用完畢,才可以歸還記憶體。(朴素的想一想,比較計算重要。不能停止,只好讓存儲等一等。等執行計算完畢,再歸還記憶體)
堆外記憶體
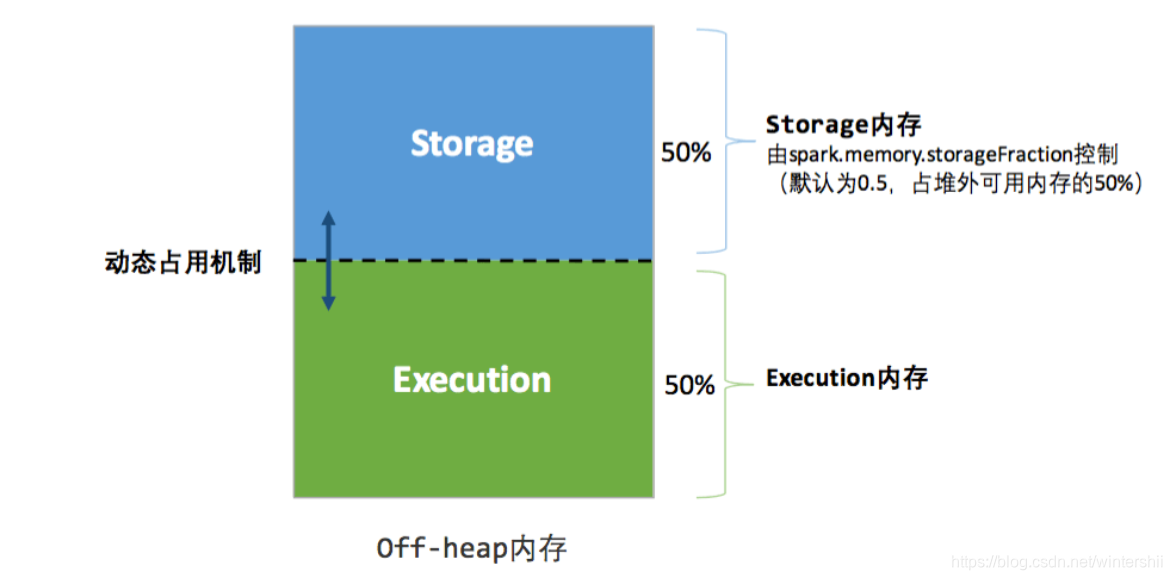
在預設情況下,堆外記憶體並不啟用。可以通過spark.memory.offHeap.enabled開啟。
堆外記憶體的大小由spark.memory.offHeap.size指定。
堆外記憶體的優點:
- Spark直接操作系統堆外記憶體,減少了不必要的記憶體開銷,和頻繁的GC的掃描和回收,提高了性能
- 可以被精準的申請和釋放。(因為堆內記憶體是由JVM管理的。所以無法實現精準的釋放)
整合yarn和Spark
我們先對一臺伺服器的資源配置做出假設,並根據這些假設,對資源進行合理的分配。
伺服器的資源情況: 32核CPU,128G記憶體
因為我們的伺服器不可能只是為yarn一個框架提供資源。其他的框架也需要資源。所以我們可用分配給yarn的資源為:16核CPU,64G記憶體
Spark任務分為Driver和Executor。
Executor
由於 Spark 的Executor的CPU建議數量是4~6個。 然後伺服器中yarn可用的CPU資源數是16。
16/4=4;16/5=3...1;16/6=2...4;可以看出。單個Executor的CPU核數為5、6的時候,都會有一些CPU核未使用上,造成CPU的浪費。所以我們選取 單個Executor的CPU核數為4。然後我們根據1CU原則(1個CPU對應4G記憶體)。所以Executor的記憶體數為4*4G。
單個Executo資源情況: 4核CPU,16G記憶體。
根據資源的配置情況可知, 一個節點能運行的Executo數量為 4
這樣,我們對於單個Executor 的資源分配好了。我們再來看Executor內部的記憶體分配。
由上面的Spark的記憶體模型可知。Spark的記憶體分為堆內和堆外記憶體。在預設情況下 堆外記憶體=堆內記憶體0.1 (spark.executor.memoryOverhead=spark.executor.memory0.1)
所以簡單的計算一下就可知:
spark.executor.memoryOverhead=$\frac{1}{11}*16G(單個Executor的可用的總記憶體)$spark.executor.memory=$\frac{10}{11}*16G(單個Executor的可用總記憶體)$
當然,很多情況下這個結果都不是整數。所以計算出結果後,再進行一些個人的調整就好。
在這裡Executor內部實際的記憶體分配情況如下:
spark.executor.memoryOverhead=2G
spark.executor.memory=14G
到這裡,我們給各個組件的資源就已經分配完畢了。
下麵我們來從Spark任務的角度談一下,一個Spark任務,應該使用多少個Executor合適。
對於一個Spark任務的Executor數量,有靜態分配和動態分配兩種選擇。
我們當然是選擇動態分配。(因為靜態分配相比於動態分配,更容易造成資源的浪費或者Spark任務資源的不足。)
動態分配: 根據Spark任務的工作負載,可用動態的調整所占用的資源(Executor的數量)。需要時申請,不需要時釋放。下麵是動態分配的一些參數的設置
#啟動動態分配
spark.dynamicAllocation.enabled true
#啟用Spark shuffle服務
spark.shuffle.service.enabled true
#Executor個數初始值
spark.dynamicAllocation.initialExecutors 1
#Executor個數最小值
spark.dynamicAllocation.minExecutors 1
#Executor個數最大值
spark.dynamicAllocation.maxExecutors 12
#Executor空閑時長,若某Executor空閑時間超過此值,則會被關閉
spark.dynamicAllocation.executorIdleTimeout 60s
#積壓任務等待時長,若有Task等待時間超過此值,則申請啟動新的Executor
spark.dynamicAllocation.schedulerBacklogTimeout 1s
#spark shuffle老版本協議
spark.shuffle.useOldFetchProtocol true
$\color{ForestGreen}{為什麼啟動Spark的shuffle}$:作用是將map的輸出文件落盤。供後續的reduce使用。
$\color{ForestGreen}{為什麼落盤}$:因為如果map的輸出的文件不落盤。map就不會被釋放。也就無法釋放這個空閑的Executor。只有將輸出文件落盤後,這個Executor才會被釋放。
Driver
Driver主要的配置參數有spark.driver.memory和spark.driver.memoryOverhead。
此處spark.driver.memory和spark.driver.memoryOverhead的分配的記憶體比例和Executor一樣。都是spark.driver.memoryOverhead=spark.driver.memory*0.1
對於Driver的總記憶體,有一個經驗公式:(假定yarn.nodemanager.resource.memory-mb設為$X$)
- 若$X>50G$,則Driver設為12G
- 若$12G<X<50G$,則Driver設為4G
- 若$1G<X<12G$,則Driver設為1G
因為我們的yarn.nodemanager.resource.memory-mb=64G。所以:
spark.driver.memory= 10Gspark.driver.memoryOverhead= 2G
配置文件的設置
spark-defaults.conf
配置文件的位置:$HivE_HOME/conf/spark-defaults.conf
由於我們多個節點有Spark。所以可能會有一些疑問:$\color{ForestGreen}{這麼多Spark,這麼多配置文件,究竟是Spark任務運行的節點 的配置文件生效呢?還是Hive目錄下的配置文件生效呢?}$
答案:當然是Hive目錄下的配置文件生效。如果我們瞭解過Spark的任務提交流程就知道。當我們運行了一條命令行後。Spark-submit會解析參數。然後再向yarn提交請求。
spark.master yarn
spark.eventLog.enabled true
spark.eventLog.dir hdfs://myNameService1/spark-history
spark.executor.cores 4
spark.executor.memory 14g
spark.executor.memoryOverhead 2g
spark.driver.memory 10g
spark.driver.memoryOverhead 2g
spark.dynamicAllocation.enabled true
spark.shuffle.service.enabled true
spark.dynamicAllocation.executorIdleTimeout 60s
spark.dynamicAllocation.initialExecutors 1
spark.dynamicAllocation.minExecutors 1
spark.dynamicAllocation.maxExecutors 12
spark.dynamicAllocation.schedulerBacklogTimeout 1s
spark.shuffle.useOldFetchProtocol true
spark-shullfe
Spark的shullfe會因為Cluster Manager(standalone、Mesos、Yarn)的不同而不同。
此處我們是yarn。
步驟如下:
- 拷貝
$SPARK_HOME/yarn/spark-3.0.0-yarn-shuffle.jar到$HADOOP_HOME/share/hadoop/yarn/lib - 向集群分發
$HADOOP_HOME/share/hadoop/yarn/lib/spark-3.0.0-yarn-shuffle.jar - 修改
$HADOOP_HOME/etc/hadoop/yarn-site.xml
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle,spark_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.spark_shuffle.class</name>
<value>org.apache.spark.network.yarn.YarnShuffleService</value>
</property>
- 分發
$HADOOP_HOME/etc/hadoop/yarn-site.xml - 重啟yarn


