
問題 我們經常遇到一種情況,在SSMS中運行很慢的一個查詢,當把查詢轉化成從源到目的資料庫的SSIS數據流以後,需要花費幾倍的時間!源和數據源都沒有任何軟硬體瓶頸,並且沒有大量的格式轉換。之前看了很多關於這種情況的優化方案,例如擴大緩存大小等。雖然也能快一點,但是仍然遠遠比直接在SSMS中查詢的速度 ...
問題
我們經常遇到一種情況,在SSMS中運行很慢的一個查詢,當把查詢轉化成從源到目的資料庫的SSIS數據流以後,需要花費幾倍的時間!源和數據源都沒有任何軟硬體瓶頸,並且沒有大量的格式轉換。之前看了很多關於這種情況的優化方案,例如擴大緩存大小等。雖然也能快一點,但是仍然遠遠比直接在SSMS中查詢的速度滿的多。究竟是什麼原因導致的呢?
解決
首先這個數據流性能是有很多因素決定的,例如源數據的速度、目標庫的寫入速度、數據轉換和路徑數量的使用等等。但是,如果只是一個很簡單的數據流,那麼提高緩存的容量即可改善性能。例如,如果緩存設的更大,那麼數據流一次轉換更多的數據行,所以性能可以提升。當然很多其他情況就不是這麼容易優化了。並且緩存過大時一旦源讀取填充緩存時間過長導致了目標庫閑置一直處於等待狀態直到緩存完成。在這個技巧中,將會介紹如何解決這種問題。
測試場景
首先創建一個百萬數據的源表。表結構是一個典型的name-value 鍵值對錶,便於闡述我們的問題。其中value 列設為5000char。如下:
IF EXISTS (SELECT * FROM sys.objects WHERE object_id = OBJECT_ID(N'[dbo].[NameValuePairs]') AND [type] IN (N'U')) DROP TABLE [dbo].[NameValuePairs]; GO IF NOT EXISTS (SELECT 1 FROM sys.objects WHERE object_id = OBJECT_ID(N'[dbo].[NameValuePairs]') AND [type] IN (N'U')) BEGIN CREATE TABLE [dbo].[NameValuePairs] ([ID] [int] IDENTITY(1,1) NOT NULL ,[Type] [varchar](100) NOT NULL ,[Value] [varchar](5000) NULL PRIMARY KEY CLUSTERED ([ID] ASC)); END GO
使用AdventureWorksDW2012 樣板數據,你可以搜索下載。表中有各種用戶信息:names, gender, addresses, birth dates, email addresses 和phone numbers。如下:
INSERT INTO [dbo].[NameValuePairs]([Type],[Value]) SELECT [Type] = 'Customer Name' ,[Value] = [FirstName] + ' ' + [LastName] FROM [AdventureWorksDW2012].[dbo].[DimCustomer] UNION ALL SELECT [Type] = 'BirthDate' ,[Value] = CONVERT(CHAR(8),[BirthDate],112) FROM [AdventureWorksDW2012].[dbo].[DimCustomer] UNION ALL SELECT [Type] = 'Gender' ,[Value] = [Gender] FROM [AdventureWorksDW2012].[dbo].[DimCustomer] UNION ALL SELECT [Type] = 'Email Address' ,[Value] = [EmailAddress] FROM [AdventureWorksDW2012].[dbo].[DimCustomer] UNION ALL SELECT [Type] = 'Address' ,[Value] = [AddressLine1] FROM [AdventureWorksDW2012].[dbo].[DimCustomer] UNION ALL SELECT [Type] = 'Phone Number' ,[Value] = [Phone] FROM [AdventureWorksDW2012].[dbo].[DimCustomer]; GO 500
當然也可以自己寫一個迴圈腳本插入數據。DimCustomer 維度表中有18000行數據,通過不同的結果集能返回110,000行數據 。註意這個語句INSERT …SELECT … ,最後有個GO,這不是官方的,但是也是可以用的,後面緊跟的數字表示批處理執行的次數。本例中就是500次。意味著5,500,000行數據被插入,大概有2.3gb。

比如我們可查詢郵箱地址:
SELECT [Customer Email] = [Value] FROM [dbo].[NameValuePairs] WHERE [Type] = 'Email Address';
查詢會返回9,242,000 行數據用33秒左右。這個是我們包的最快運行的時間理論上。那麼包能不能運行的更快呢?SSIS中將郵件地址轉換成郵箱維度表,該列在新表中只有50個字元的寬度,但是在源表中的該列卻是5000個字元。但是我們知道在本例中這個郵箱地址不會超過50個字元。
CREATE TABLE dbo.DimEmail ([SK_Email] INT IDENTITY(1,1) NOT NULL ,[Email Address] VARCHAR(50) NOT NULL ,[InsertDate] DATE NOT NULL);
SSIS包
生成包是相對簡單的,整個控制流由4分任務組成:
- 第一個任務是記錄包開始的日誌。
- 第二個任務是清空目標表。
- 第三個任務是數據流任務,下麵詳細介紹。
- 最後日誌記錄任務結束。
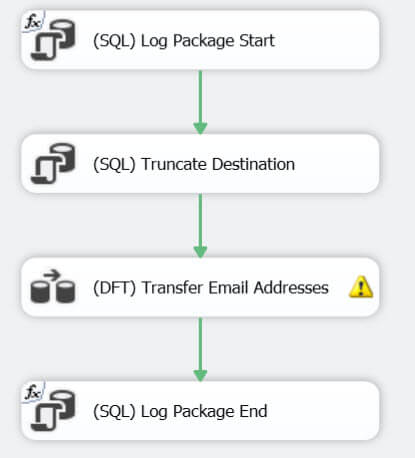
數據流本身也是很簡單:使用前面提到查詢讀取數據源,然後將加入了審核列和目標表的派生列將結果集寫入郵箱維度表。

目標資料庫展示了一個截斷警告,因為我們試圖將超過目標表欄位長度的數據插入進來。
初始性能
為了限制外部影響,目標資料庫的日誌和數據文件足夠大,不會影響整個事務。在開發環境下,整個包運行了大約40秒。這是要比直接查詢慢的!寫入操作是可以被優化的。下麵看一下如何優化行數據的插入…
優化數據流
之前提到的最佳實踐之一就是擴大緩衝區,具體操作就是修改數據流屬性裡面的DefaultBufferMaxRows(預設緩存最大行數) 和DefaultBufferSize(預設緩存大小)。SSIS引擎就是使用這個屬性來估計在管道中傳送數據的緩存大小。更大的緩存意味著更多行可以被同時處理。
當設定最大值行數為30000並且預設緩存為20M的時候,執行包花費了30秒,這也僅僅比之前源查詢快了一點。所以還應該有空間去優化。
在源組件端,估計行的大小是取決於查詢返回所有列中的最大列。這也是性能問題的所在:我們建立的鍵值對錶,最大列我5000字元,SSIS引擎將會認為這個列一定包含5000個字元,及時實際上小於50個字元。5000個非Unicode字元等於5000個位元組或者5kb。預設的緩存大小事10MB,因此意味著一次僅僅能存儲2000行數據,15分之一。這也意味著我們我們並沒有最優化的使用緩存。
那麼我們只需要調整源數據查詢映射的實際數據長度,就能夠實現潛在性能的提升。如下:
SELECT [Customer Email] = CONVERT(VARCHAR(50),[Value]) FROM [dbo].[NameValuePairs] WHERE [Type] = 'Email Address';
既然我們已經知道該列最大的是50個字元,改成這樣以後一次性能多放入一百倍的數據。當包運行時數據流執行僅僅用了12秒!
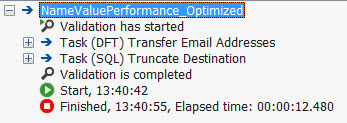
我們可以看一下三次不同的包的執行比較(預設配置--擴大緩存--擴大緩存並減小列寬),分別在SSIS catalog 中運行20次在,曲線圖如下:
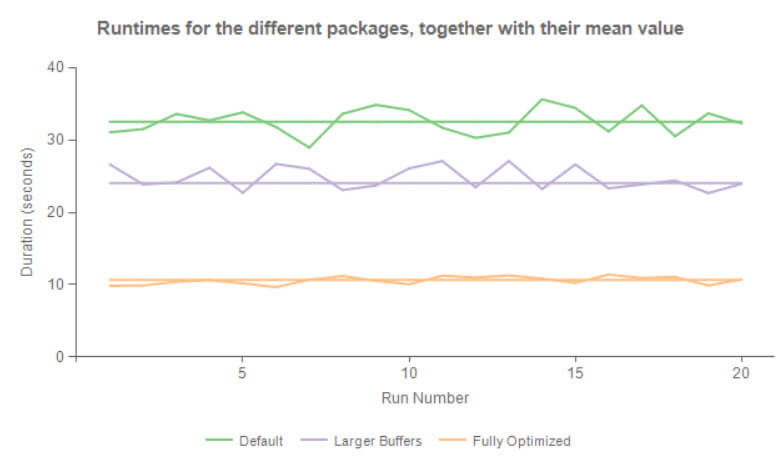
不用多說大家都知道這三種性能如何了。
總結
本篇只是針對數據流進行了優化,並不涉及SQL本身的優化,這裡偏重BI一點。通過關註返回源數據的列寬,極大的提高了性能,除此之更小的列性能更好。一次性緩存的行也越多。通過擴大緩存也進一步能提升性能


