
sql(Structured Query Language: 結構化查詢語言)是高級的費過程化編程語言,允許用戶在高層數據結構上工作, 是一種數據查詢和程式設計語言, 也是(ANSI)的一項標準的電腦語言. but... 目前仍然存在著許多不同版本的sql語言,為了與ANSI標準相相容, 它們必須... ...
一、什麼是SQL
sql(Structured Query Language: 結構化查詢語言)是高級的費過程化編程語言,允許用戶在高層數據結構上工作, 是一種數據查詢和程式設計語言, 也是(ANSI)的一項標準的電腦語言. but... 目前仍然存在著許多不同版本的sql語言,為了與ANSI標準相相容, 它們必須以相似的方式共同地來支持一些主要的命令(比如SELECT、UPDATE、DELETE、INSERT、WHERE等等).
在標準SQL中, SQL語句包含四種類型
DML(Data Manipulation Language):數據操作語言,用來定義資料庫記錄(數據)。
DCL(Data Control Language):數據控制語言,用來定義訪問許可權和安全級別。
DQL(Data Query Language):數據查詢語言,用來查詢記錄(數據)。
DDL(Data Definition Language):數據定義語言,用來定義資料庫對象(庫,表,列等)
二、如何執行SQL
2.1 mysql
以mysql為例, sql執行流程大致分為以下節點(mysql server層代碼, 不包含引擎層事務/log等操作):
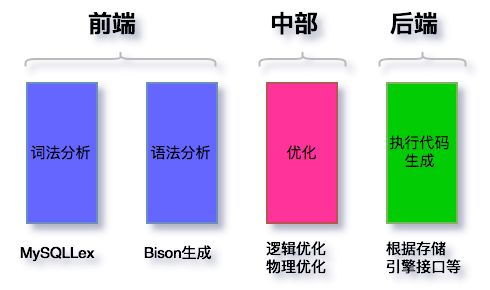
mysqlLex: mysql自身的詞法分析程式, C++語言開發, 基於輸入的語句進行分詞, 並解析除每個分詞的意義. 分詞的本質便是正則表達式的匹配過程. 源碼在sql/sql_lex.cc
Bision: 根據mysql定義的語法規則,進行語法解析,語法解析就是生成語法樹的過程. 核心是如何涉及合適的存儲結構以及相關演算法,去存儲和遍歷所有的信息
語法解析中,生成語法樹:
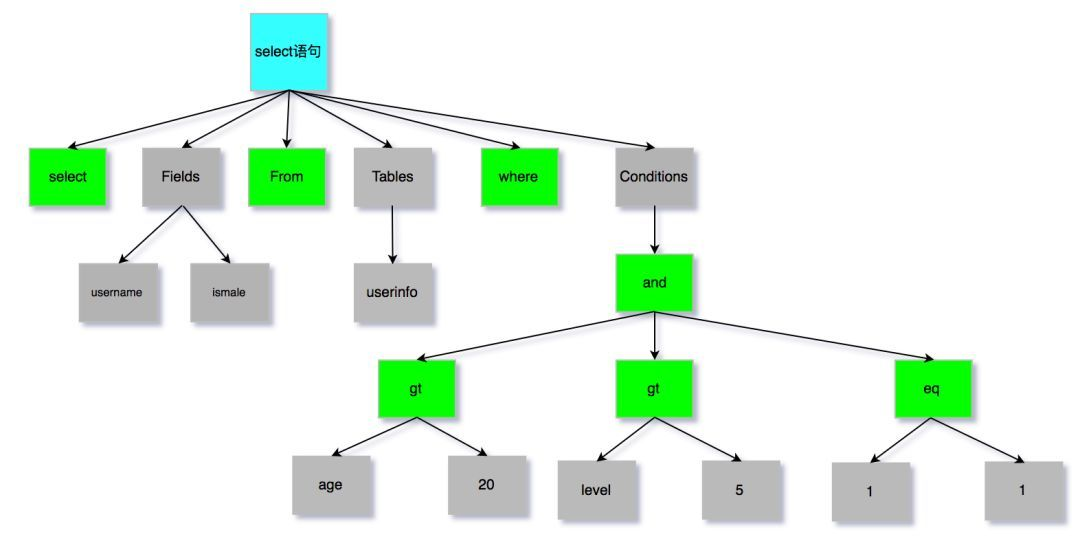
mysql分析器: SQL解析, 針對關鍵詞/非關鍵詞進行提取、解析, 並生成解析語法樹. 如果分析到語法錯誤,會拋出異常: ERROR: You have an error in your SQL syntax. 同時該階段也會做一些校驗, 如不存在欄位會拋出異常: unknow column in field list.
引申點:
a. 語法樹生成規則
b. mysql的優化規則
2.2 hive sql
Hive 是基於Hadoop 構建的一套數據倉庫分析系統,它提供了豐富的SQL查詢方式來分析存儲在Hadoop 分散式文件系統中的數據,可以將結構化的數據文件映射為一張資料庫表,並提供完整的SQL查詢功能,可以將SQL語句轉換為MapReduce任務進行運行,通過自己的SQL 去查詢分析需要的內容,這套SQL 簡稱Hive SQL,使不熟悉mapreduce 的用戶很方便的利用SQL 語言查詢,彙總,分析數據
hive架構圖:
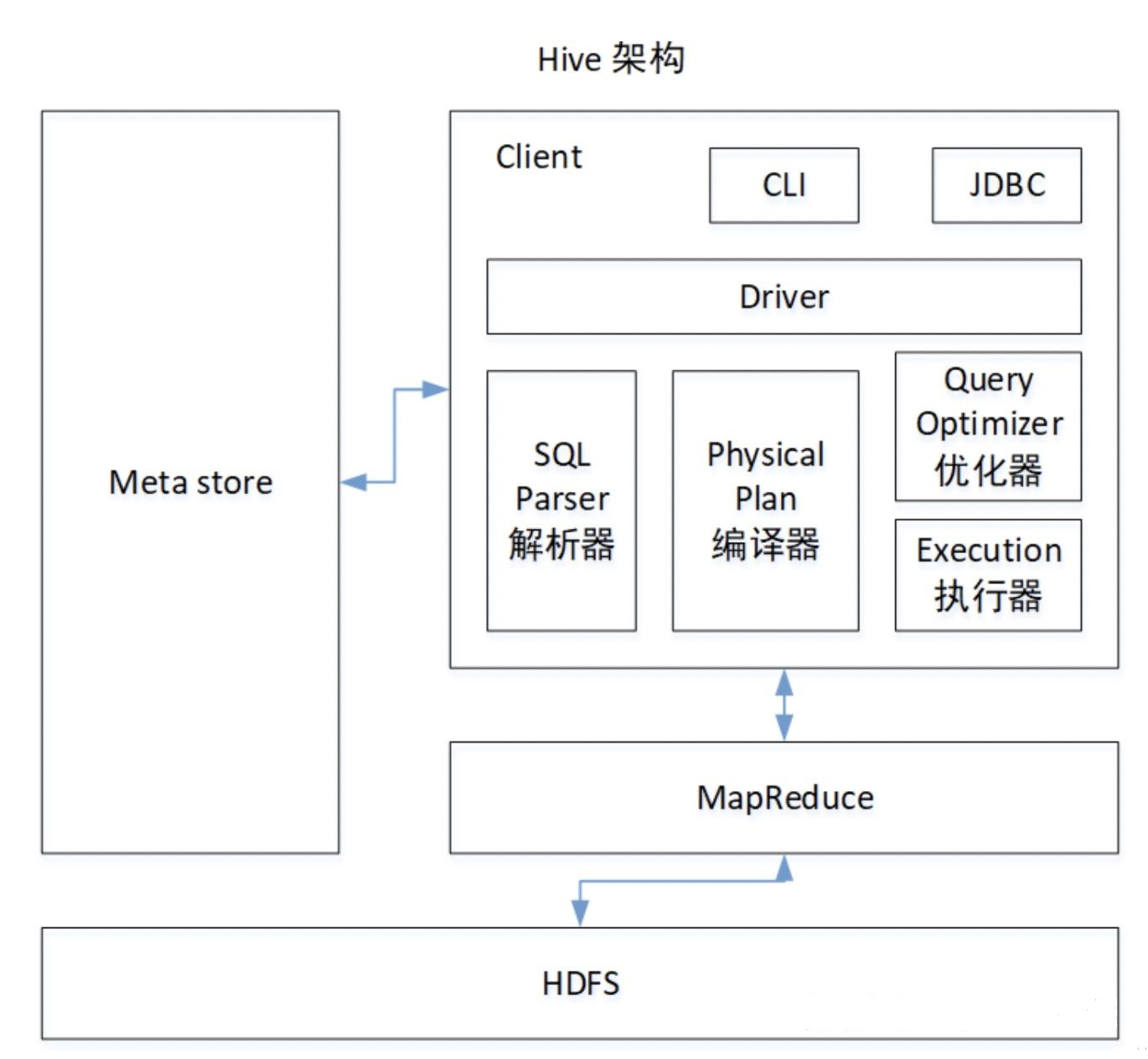
Driver:
輸入了sql字元串,對sql字元串進行解析,轉化程抽象語法樹,再轉化成邏輯計劃,然後使用優化工具對邏輯計划進行優化,最終生成物理計劃(序列化反序列化,UDF函數),交給Execution執行引擎,提交到MapReduce上執行(輸入和輸出可以是本地的也可以是HDFS/Hbase)見下圖的hive架構
hiveSql的執行流程如下:
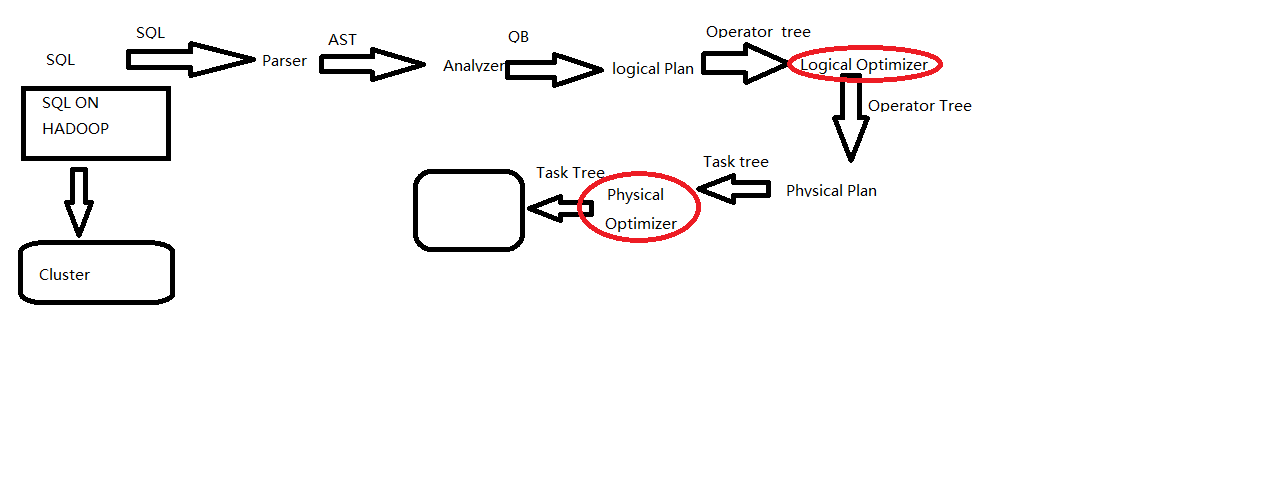
sql寫出來以後只是一些字元串的拼接,所以要經過一系列的解析處理,才能最終變成集群上的執行的作業
(1)Parser:將sql解析為AST(抽象語法樹),會進行語法校驗,AST本質還是字元串
(2)Analyzer:語法解析,生成QB(query block)
(3)Logicl Plan:邏輯執行計劃解析,生成一堆Opertator Tree
(4)Logical optimizer:進行邏輯執行計劃優化,生成一堆優化後的Opertator Tree
(5)Phsical plan:物理執行計劃解析,生成tasktree
(6)Phsical Optimizer:進行物理執行計劃優化,生成優化後的tasktree,該任務即是集群上的執行的作業
結論:經過以上的六步,普通的字元串sql被解析映射成了集群上的執行任務,最重要的兩步是 邏輯執行計劃優化和物理執行計劃優化(圖中紅線圈畫)
Antlr: Antrl是一種語言識別的工具, 基於java開發, 可以用來構造領域語言. 它提供了一個框架,可以通過包含java, C++, 或C#動作(action)的語法描述來構造語言識別器, 編譯器和解釋器.Antlr完成了hive 詞法分析、語法分析、語義分析、中間代碼生成的過程.
AST語法樹舉例:
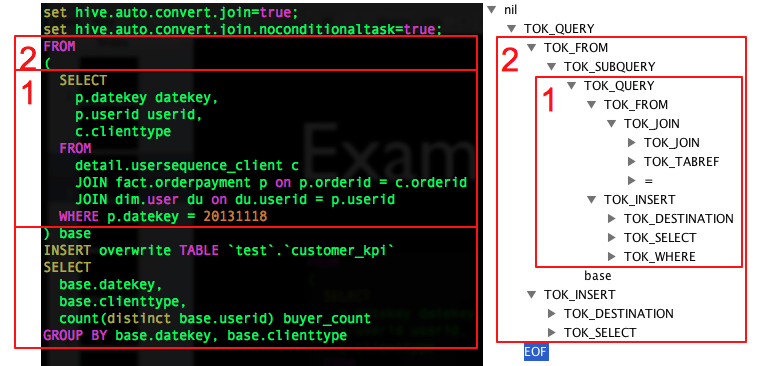
引申學習:
a. 從hivesql的執行機制可以看出, hive並不適合用於聯機事務處理, 無法提供實時查詢功能;最適合應用在基於大量不可變數據的批處理作業
b. Antlr的解析流程
c. hive的優化規則
2.3 flink sql
Flink SQL是Flink中最高級的抽象, 可以劃分為 SQL --> Table API --> DataStream/DataSetAPI --> Stateful Stream Processing
Flink SQL包含 DML 數據操作語言、 DDL 數據語言, DQL 數據查詢語言,不包含DCL語言。
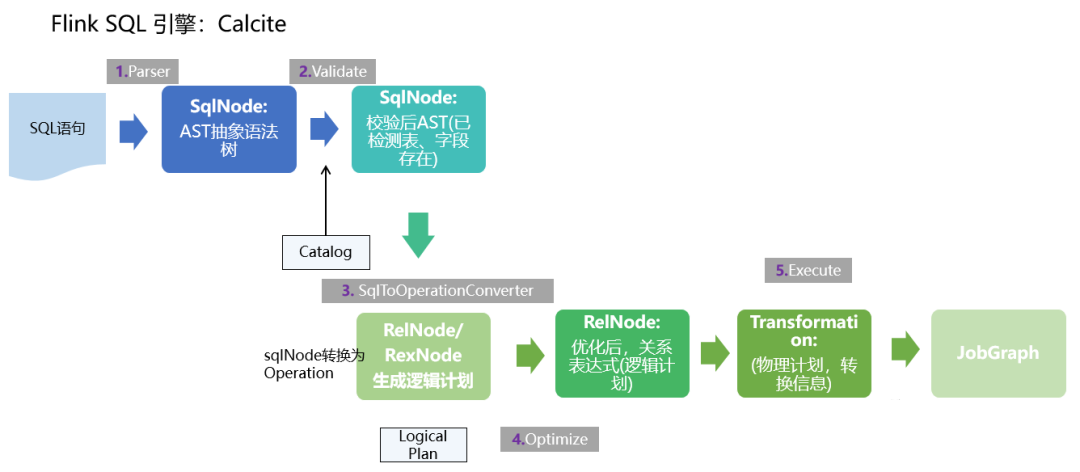
(1)首先,FlinkSQL 底層使用的是 apache Calcite 引擎來處理SQL語句,Calcite會使用 javaCC 做SQL解析,javaCC根據Calcite中定義的 Parser.jj 文件,生成一系列的java代碼,生成的java代碼會把SQL轉換成AST抽象語法樹(即SQLNode類型)。
(2)生成的 SqlNode 抽象語法樹,他是一個未經驗證的抽象語法樹,這時 SQL Validator 會獲取 Flink Catalog 中的元數據信息來驗證 sql 語法,元數據信息檢查包括表名,欄位名,函數名,數據類型等檢查。然後生成一個校驗後的SqlNode。
(3)到達這步後,只是將 SQL 解析到 java 數據結構的固定節點上,並沒有給出相關節點之間的關聯關係以及每個節點的類型信息。
所以,還需要將 SqlNode 轉換為邏輯計劃,也就是LogicalPlan,在轉換過程中,會使用 SqlToOperationConverter 類,來將 SqlNode 轉換為 Operation,Operation 會根據SQL語法來執行創建表或者刪除表等操作,同時FlinkPlannerImpl.rel()方法會將SQLNode轉換成RelNode樹,並返回RelRoot。
(4)第4步將執行 Optimize 操作,按照預定義的優化規則 RelOptRule 優化邏輯計劃。
Calcite 中的優化器RelOptPlanner有兩種,一是基於規則優化(RBO)的HepPlanner,二是基於代價優化(CBO)的VolcanoPlanner。然後得到優化後的RelNode, 再基於Flink裡面的rules將優化後的邏輯計劃轉換成物理計劃。
(5)第5步 執行 execute 操作,會通過代碼生成 transformation,然後遞歸遍歷各節點,將DataStreamRelNode 轉換成DataStream,在這期間,會依次遞歸調用DataStreamUnion、DataStreamCalc、DataStreamScan類中重寫的 translateToPlan方法。遞歸調用各節點的translateToPlan,實際是利用CodeGen元編成Flink的各種運算元,相當於直接利用Flink的DataSet或者DataStream開發程式。
(6)最後進一步編譯成可執行的 JobGraph 提交運行。
Flink SQL使用 Apache Calcite 作為解析器和優化器
Calcite : 一種動態數據管理框架,它具備很多典型資料庫管理系統的功能 如SQL 解析、 SQL 校驗、 SQL 查詢優化、 SQL 生成以及數據連接查詢等,但是又省略了一些關鍵的功能,如 Calcite並不存儲相關的元數據和基本數據,不完全包含相關處理數據的演算法等。
引申學習:
a. flink sql優化規則
三、常見SQL解析引擎
| 解析引擎 | 開發語言 | 使用場景 | 總結 |
|---|---|---|---|
| antlr | java | presto | 1. 包含三大主要功能: 詞法分析器、語法分析器、樹解析器2. 支持定義領域語言 |
| calcite | javaCC | flink | 1. 抽象語法樹2. 支持使用 FreeMarker 模版引擎擴展語法3. 能夠與資料庫創建查詢 |
持續補充ing...
四、總結
在實際工作過程中會涉及到相關的sql優化, 比如將非研發的業務老師寫的複雜嵌套sql後臺自動改為非嵌套執行,提高查詢性能. 支持redisSQL, 以標準SQL格式解析成後臺可執行的redis命令. 目前採用的開源jsqlparser框架來實現語法樹的解析, 好處是操作簡單, 只對sql語句進行拆分, 解析成java類的層次結構,支持visitor模式, 與資料庫無關. 缺點是只支持常見的SQL語法集, 如若要擴展語法需改其源碼, 對代碼的侵入性與維護性造成影響.想要做好sql解析優化相關的工作, 還是要深入瞭解sql的執行原理, 瞭解各個sql引擎的特點與優劣. 站在架構的角度來思考來思考問題.
工欲善其事,必先利其器.
作者:京東科技 李丹楓
來源:京東雲開發者社區 轉載請註明來源


