MPP MPP:Massively Parallel Processing, 即大規模並行處理. 一般用來指多個SQL資料庫節點搭建的數據倉庫系統. 執行查詢的時候, 查詢可以分散到多個SQL資料庫節點上執行, 然後彙總返回給用戶. Doris Doris 作為一款開源的 MPP 架構 OLAP 高 ...
MPP
MPP:Massively Parallel Processing, 即大規模並行處理.
一般用來指多個SQL資料庫節點搭建的數據倉庫系統. 執行查詢的時候, 查詢可以分散到多個SQL資料庫節點上執行, 然後彙總返回給用戶.
Doris
Doris 作為一款開源的 MPP 架構 OLAP 高性能、實時的分析型資料庫,能夠運行在絕大多數主流的商用伺服器上。
使用場景
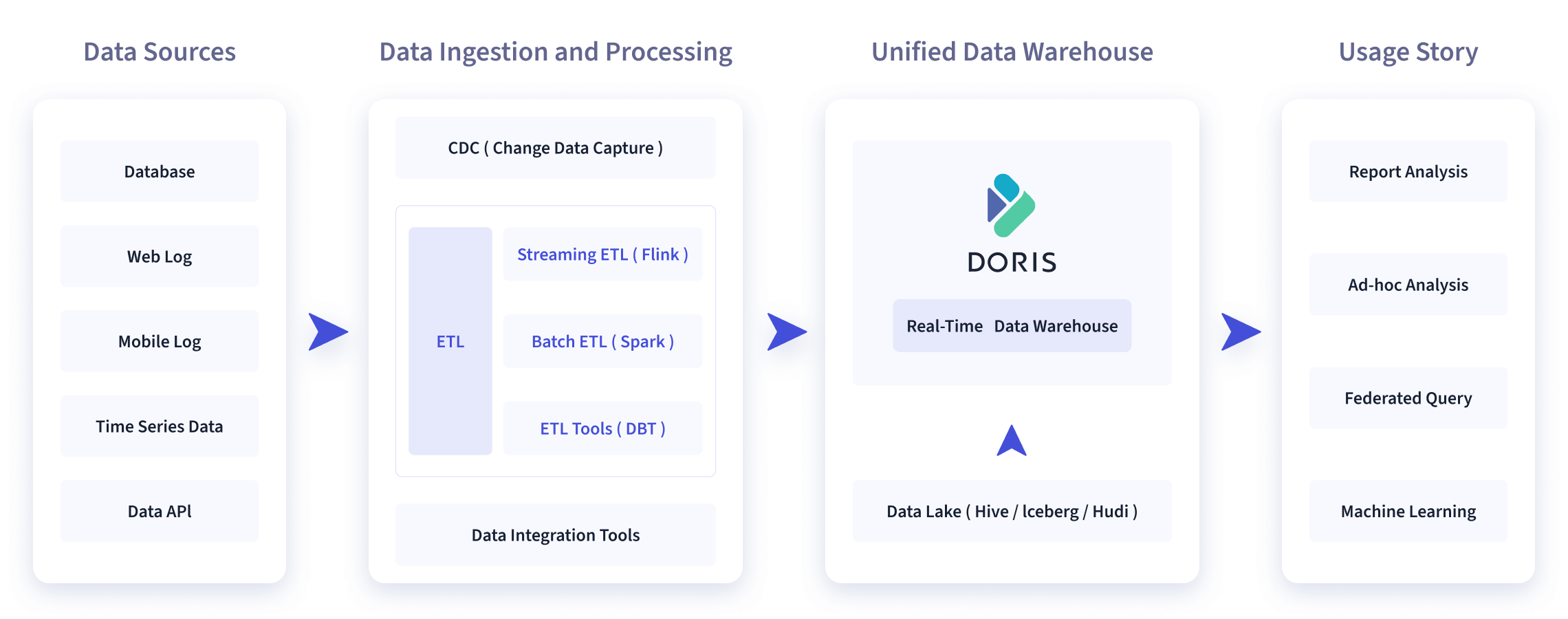
如下圖所示,數據源經過各種數據集成和加工處理後,通常會入庫到實時數倉 Doris 和離線湖倉(Hive, Iceberg, Hudi 中),Apache Doris 被廣泛應用在以下場景中。
-
報表分析
- 實時看板 (Dashboards)
- 面向企業內部分析師和管理者的報表
- 面向用戶或者客戶的高併發報表分析(Customer Facing Analytics)。比如面向網站主的站點分析、面向廣告主的廣告報表,併發通常要求成千上萬的 QPS ,查詢延時要求毫秒級響應。著名的電商公司京東在廣告報表中使用 Apache Doris ,每天寫入 100 億行數據,查詢併發 QPS 上萬,99 分位的查詢延時 150ms。
-
即席查詢(Ad-hoc Query):面向分析師的自助分析,查詢模式不固定,要求較高的吞吐。小米公司基於 Doris 構建了增長分析平臺(Growing Analytics,GA),利用用戶行為數據對業務進行增長分析,平均查詢延時 10s,95 分位的查詢延時 30s 以內,每天的 SQL 查詢量為數萬條。
-
統一數倉構建 :一個平臺滿足統一的數據倉庫建設需求,簡化繁瑣的大數據軟體棧。海底撈基於 Doris 構建的統一數倉,替換了原來由 Spark、Hive、Kudu、Hbase、Phoenix 組成的舊架構,架構大大簡化。
-
數據湖聯邦查詢:通過外表的方式聯邦分析位於 Hive、Iceberg、Hudi 中的數據,在避免數據拷貝的前提下,查詢性能大幅提升。
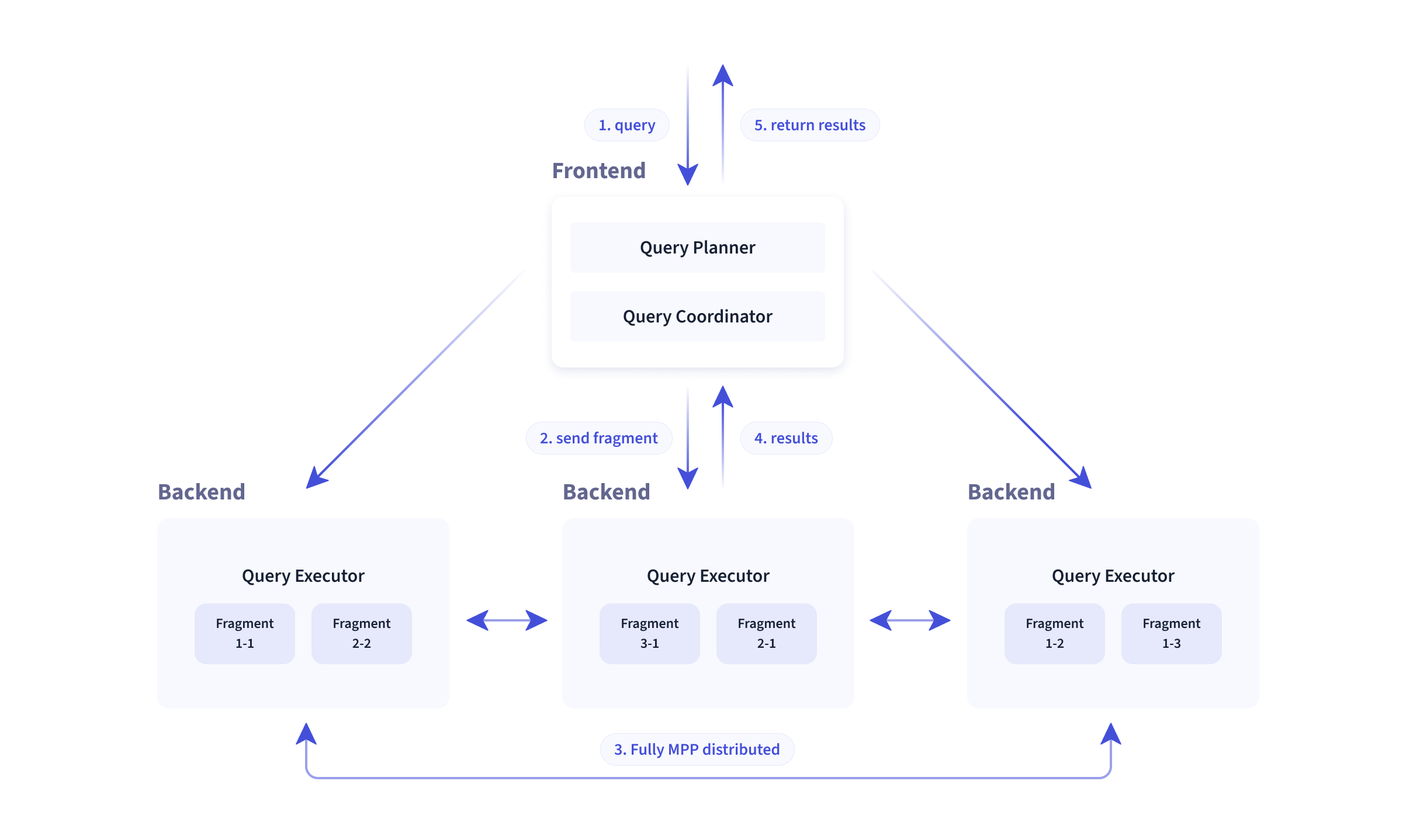
架構概述
Doris整體架構如下圖所示,Doris 架構非常簡單,只有兩類進程
- Frontend(FE), 主要負責用戶請求的接入、查詢解析規劃、元數據的管理、節點管理、生成查詢計劃相關工作。
- Backend(BE), 主要負責數據存儲、查詢計劃的執行。
這兩類進程都是可以橫向擴展的,單集群可以支持到數百台機器,數十 PB 的存儲容量。並且這兩類進程通過一致性協議來保證服務的高可用和數據的高可靠。這種高度集成的架構設計極大的降低了一款分散式系統的運維成本。
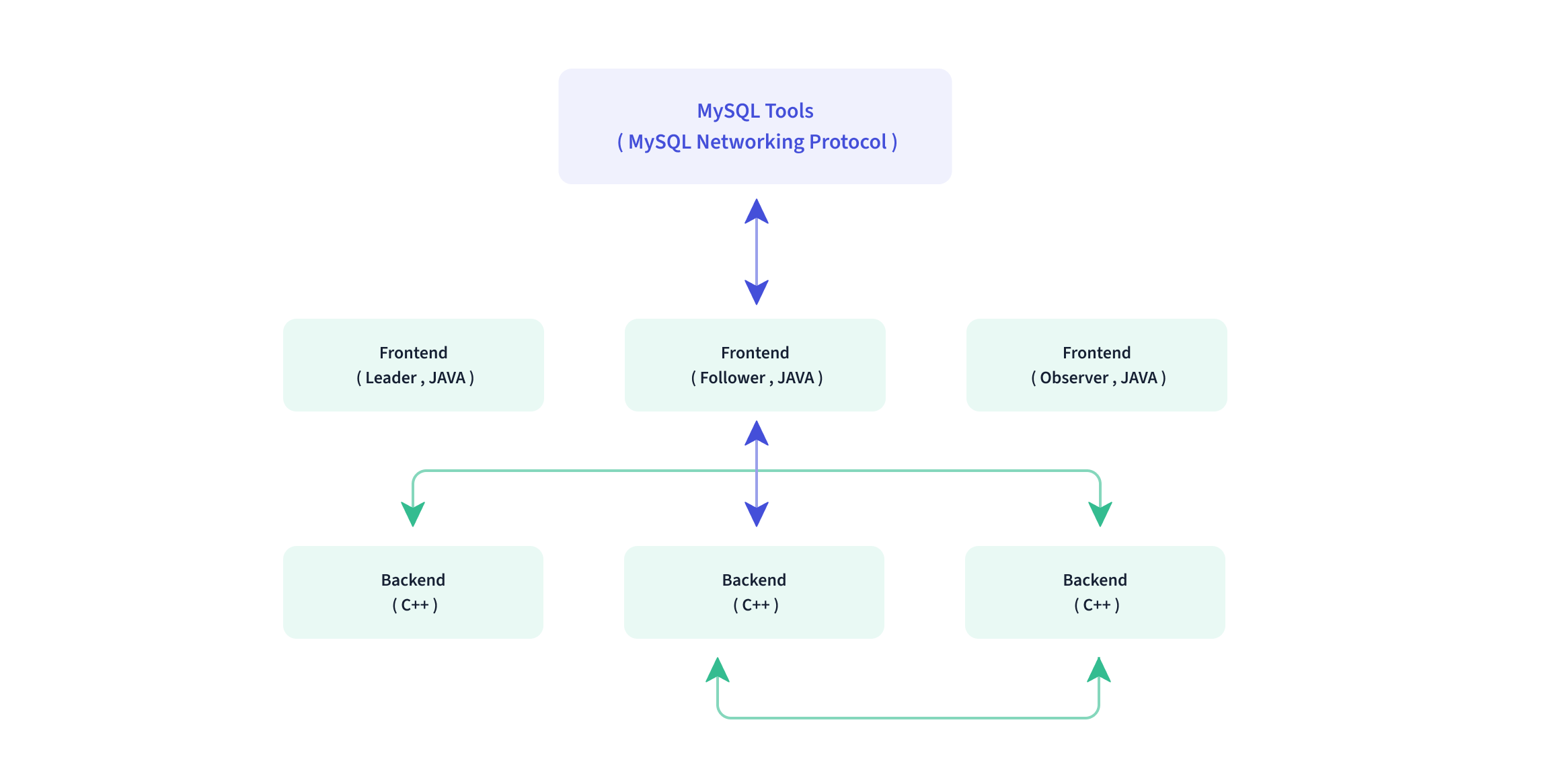
FE主要分為三個角色:Leader、Follower、Observer及其作用:
- leader, follower: 在Leader宕機之後,Follower節點能夠迅速代替Leader的工作,能夠實現實時恢復元數據,從而保證對Doris集群不造成任何影響;leader負責數據的寫入.
- observer: 用來拓展查詢節點, 僅從leader節點同步元數據, Observer只參與讀取,不參與寫入
類似Zookeeper中的節點角色及其職責。
在使用介面方面,Doris 採用 MySQL 協議,高度相容 MySQL 語法,支持標準 SQL,用戶可以通過各類客戶端工具來訪問 Doris,並支持與 BI 工具的無縫對接。Doris 當前支持多種主流的 BI 產品,包括不限於 SmartBI、DataEase、FineBI、Tableau、Power BI、SuperSet 等,只要支持 MySQL 協議的 BI 工具,Doris 就可以作為數據源提供查詢支持。
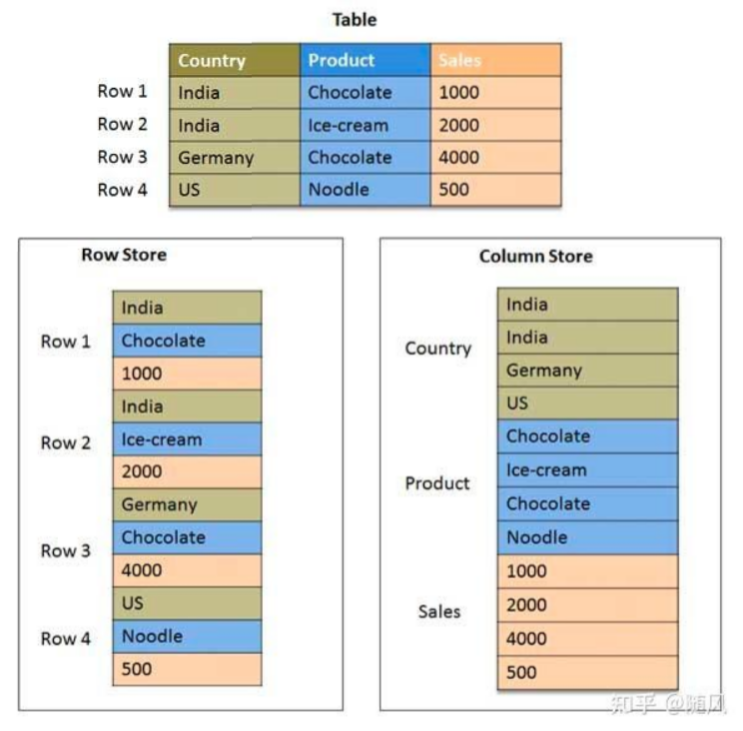
在存儲引擎方面,Doris 採用列式存儲,按列進行數據的編碼壓縮和讀取,能夠實現極高的壓縮比,同時減少大量非相關數據的掃描,從而更加有效利用 IO 和 CPU 資源。
列式存儲(column-based) 是相對於傳統關係型資料庫的行式存儲(Row-basedstorage)來說的。簡單來說兩者的區別就是如何組織表:
Doris 也支持比較豐富的索引結構,來減少數據的掃描:
- Sorted Compound Key Index,可以最多指定三個列組成複合排序鍵,通過該索引,能夠有效進行數據裁剪,從而能夠更好支持高併發的報表場景
- Min/Max :有效過濾數值類型的等值和範圍查詢
- Bloom Filter :對高基數列的等值過濾裁剪非常有效
- Invert Index :能夠對任意欄位實現快速檢索
在存儲模型方面,Doris 支持多種存儲模型,針對不同的場景做了針對性的優化:
- Aggregate Key 模型:相同 Key 的 Value 列合併,通過提前聚合大幅提升性能
- Unique Key 模型:Key 唯一,相同 Key 的數據覆蓋,實現行級別數據更新
- Duplicate Key 模型:明細數據模型,滿足事實表的明細存儲
Doris 也支持強一致的物化視圖,物化視圖的更新和選擇都在系統內自動進行,不需要用戶手動選擇,從而大幅減少了物化視圖維護的代價。
在查詢引擎方面,Doris 採用 MPP 的模型,節點間和節點內都並行執行,也支持多個大表的分散式 Shuffle Join,從而能夠更好應對複雜查詢。