
基於物品的協同過濾演算法ItemCF 基於item的協同過濾,通過用戶對不同item的評分來評測item之間的相似性,基於item之間的相似性做出推薦。簡單來講就是:給用戶推薦和他之前喜歡的物品相似的物品。 用例說明: 註:基於物品的協同過濾演算法,是目前商用最廣泛的推薦演算法。 剛開始看這個用例,感覺還 ...
基於物品的協同過濾演算法ItemCF
基於item的協同過濾,通過用戶對不同item的評分來評測item之間的相似性,基於item之間的相似性做出推薦。簡單來講就是:給用戶推薦和他之前喜歡的物品相似的物品。
用例說明:

註:基於物品的協同過濾演算法,是目前商用最廣泛的推薦演算法。
剛開始看這個用例,感覺還是基於用戶進行的推薦,用戶A,B,C都喜歡物品a,並且用戶A,B喜歡物品c,然後就將物品c推薦給用戶C。
再回過頭來看看基於物品的協同過濾的概念:給用戶推薦和他之前喜歡的物品相似的物品。按我的理解和其他用戶的喜好並沒有什麼直接關係;比如用戶C喜歡帽子a,再給他推薦個類似的商品帽子b就可以了。
比如:物品a為啤酒,物品c為尿布,符合圖例,則向用戶C推薦的物品為尿布,因為物品a和物品c相似?,所以就向用戶C推薦了此商品。顯然這裡的相似並不是決對的相同種類或類型的物品。
那物品的相似是怎麼計算出來的哪?
Iterm-based的基本思想是預先根據所有用戶的歷史偏好數據計算物品之間的相似性,然後把與用戶喜歡的物品相類似的物品推薦給用戶。
這樣解釋就可以很好的說明上面的疑問了。
當然也可以直接針對不同物品建立相似性關係。計算出不同物品的相似度。
相似度
當已經對用戶行為進行分析得到用戶喜好後,我們可以根據用戶喜好計算相似用戶和物品,然後基於相似用戶或者物品進行推薦,這就是最典型的 CF 的兩個分支:基於用戶的 CF 和基於物品的 CF。這兩種方法都需要計算相似度。
關於相似度的計算,現有的幾種基本方法都是基於向量(Vector)的,其實也就是計算兩個向量的距離,距離越近相似度越大。在推薦的場景中,在用戶 - 物品偏好的二維矩陣中,我們可以將一個用戶對所有物品的偏好作為一個向量來計算用戶之間的相似度,或者將所有用戶對某個物品的偏好作為一個向量來計算物品之間的相似度。
上一篇文章中基於用戶的協同過濾,建立的用戶相似矩陣,此篇文章是建立的物品相似度的矩陣。
同現矩陣(Co-occurrence Matrix): 反應物品關聯度的矩陣
生成同現矩陣
數據:user,item,grade
1,101,5.0 1,102,3.0 1,103,2.5 2,101,2.0 2,102,2.5 2,103,5.0 2,104,2.0 3,101,2.0 3,104,4.0 3,105,4.5 3,107,5.0 4,101,5.0 4,103,3.0 4,104,4.5 4,106,4.0 5,101,4.0 5,102,3.0 5,103,2.0 5,104,4.0 5,105,3.5 5,106,4.0
用戶1的三個item 101,102,103形成9種組合,相應位置加1.
[101] [102] [103]
[101] 1 1 1
[102] 1 1 1
[103] 1 1 1
最終結果: [101] [102] [103] [104] [105] [106] [107]
[101] 5 3 4 4 2 2 1
[102] 3 3 3 2 1 1 0
[103] 4 3 4 3 1 2 0
[104] 4 2 3 4 2 2 1
[105] 2 1 1 2 2 1 1
[106] 2 1 2 2 1 2 0
[107] 1 0 0 1 1 0 1
下麵內容摘自一論壇:
再談談Co-occurrence Matrix(同顯矩陣)和User Preference Vector(用戶評分向量)相乘得到的這個Recommended Vector(推薦向量)的意義
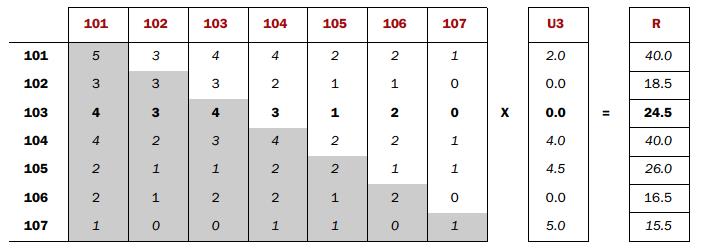
第一次聽完理論直接上這兩個東西相乘實現Item Based Cooperative Filtering(基於物品的協同過濾),一下子真沒反應過來,下麵就個人的理解通俗的解釋一下: ItemBased:基於物品的(區分於基於用戶的)體現在同現矩陣,把所有用戶對物品打過分的記錄都拿過來,形成一個個反應物品關聯度的矩陣Co-occurrence Matrix,下麵簡稱C矩陣。 為什麼乘以User Preference Vector用戶評分向量就是Recommended Vector(推薦向量),這個推薦向量又要怎麼用呢? 還是用R的第三項24.5來做一下解釋, R3的解釋:對於用戶U商品103的可推薦度。 這點很重要,理解這點就是要知道我們這一系列演算法過程在做什麼(What)。
我把R3也就是R103的計算用公式表示如下:
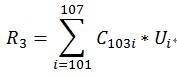 R3怎麼出來的
R3怎麼出來的
從上面可以看到C103i*Ui就是Ui代表用戶對i的喜愛度,C103i代表i和103同時出現的次數,i物品和103同時出現得越多C103i越大,用戶對i的喜愛度值越大Ui越大,自然R103值就越大,越值得推薦103。
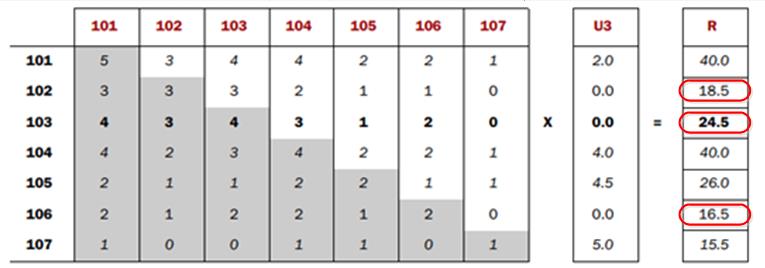 R向量裡面的R101, R104,R105和R107這三項值很大,但是我們可以忽略它們應用用戶已經對它們打過分,也就是已經看過這些電影了,可以不比推薦了,對於用戶沒有看過的電影的幾項裡面選出最大(或者TopN)對應的電影推薦就可以了,
R向量裡面的R101, R104,R105和R107這三項值很大,但是我們可以忽略它們應用用戶已經對它們打過分,也就是已經看過這些電影了,可以不比推薦了,對於用戶沒有看過的電影的幾項裡面選出最大(或者TopN)對應的電影推薦就可以了,
上面R102,R103,R106裡面選一個最大值103,103就是可以推薦的商品了

