
隨著CYQ.Data 開始回歸免費使用之後,發現用戶的情緒越來越激動,為了保持這持續的激動性,讓我有了開源的念頭。同時,由於框架經過這5-6年來的不斷演進,以前發的早期教程已經太落後了,包括使用方式,及相關介紹,都容易引人誤解。為此,我打算重新寫個系列來介紹最新的版本,讓大伙從傳統的ORM編程過渡到... ...
前言:
隨著CYQ.Data 開始回歸免費使用之後,發現用戶的情緒越來越激動,為了保持這持續的激動性,讓我有了開源的念頭。
同時,由於框架經過這5-6年來的不斷演進,以前發的早期教程已經太落後了,包括使用方式,及相關介紹,都容易引人誤解。
為此,我打算重新寫個系列來介紹最新的版本,讓大伙從傳統的ORM編程過渡到自動化框架型思維編程(自已造的詞)。
於是:這個新系列的名稱就叫:CYQ.Data 從入門到放棄ORM系列
什麼是:CYQ.Data
1:它是一個ORM框架。
2:它是一個數據層組件。
3:它是一個工具集類庫。
下麵看一張圖:

從上面的圖可以看出,它已不僅僅是一個ORM,還附帶一些帶用功能。
因此:
寫日誌:你不再需要:Log4net.dll
操作Json:你不再需要newtonjson.dll
分散式緩存:你不再需要Memcached.ClientLibrary.dll
目前框架只有340K,後續版本將沒有混淆工作,體積將更小一些。
傳統ORM的發展過程:
看一張千篇一律的發展趨勢圖:

在開源中國里搜.NET系的:ORM,數量有110左右,在CodeProject里搜.NET系的:ORM,數量有530左右。
經過大量的查看,很容易就發現,市場上的ORM都幾乎一樣,唯一不同的:
就是在自定義查詢語法,每家都在玩自己的花樣,而且必須玩的與眾不同,不然大伙都一個樣,顯示不出優越感。
同時這種各式各樣無釐頭的查詢語法糖,也浪費了不少開發人員的時間,因為學習的成本是要看一本書或一個從入門到精通系列。
綜合看來,能跳出這個趨勢的,木有!說明造ORM是有套路的,創新,是需要藝術細胞的。
曾經,我也有一個很簡單又傳統的ORM叫XQData:
是我2009年時造的,發現現在還躺在硬碟里,任性地就開源分享給各位還沒造過ORM的小伙伴們當入門指南用了。
XQData源碼(SVN下載)地址:http://code.taobao.org/svn/cyqopen/trunk/XQData
CYQ.Data 的自動化框架思維:
在早期的CYQ.Data版本里(具體多早不好說),和傳統實體型ORM比起來,除了不拘一格,看起來有點潮,值的鼓勵和關註之外,用起來的確沒感覺爽在哪。
隨著自動化框架思維的形成,經過多年的完善,如今,和實體型ORM的差距已經不在同一個層次上了。
先看實體型ORM的代碼編寫方式:實體繼承自CYQ.Data.Orm.OrmBase
using (Users u = new Users()) { u.Name = "路過秋天"; u.TypeID = Request["typeid"]; //.... u.Insert(); }
看起來很簡潔是不?的確是,只是它太固定化了,不夠智能,一經寫死,就是天造地設耦合的一對。
為什麼我都推薦用MAction?因為它有自動化框架思維:
看以下代碼:
using (MAction action = new MAction(TableNames.Users)) { action.Insert(true);//這中間是沒有單個賦值過程的 }
相比較一下代碼就可以看出優勢來了:
1:代碼少了,沒了中間的賦值過程;
2:和屬性和資料庫欄位無依賴了:不管你前端修改界面,還是修改資料庫,後臺代碼都不作調整;
如果增加切換表操作和事務,這時候優勢又多了兩個:
1:實體ORM:只能用分散式事務包含代碼段,不能復用鏈接。
2:MAction:可以用本地事務,可以復用鏈接。
上面的MAction代碼,還有一個TableNames.Users表名依賴,如果把它變成參數,你就會發現不一樣的天空:
using (MAction action = new MAction(參數表名)) { action.Insert(true); }
就這麼兩行代碼,你發現完全和資料庫和界面解耦了。
到這裡你就發現,這就是這款框架和實體型ORM不在一個Level的地方:
1:因為它實現了數據層和UI層真正意義上的解耦。
2:因為它是基於自動化框架編程的思維的,不再有一個一個屬性賦值的過程。
看到這裡,再回看ASP.NET Aries 開源框架里的AjaxBase,就能理解為啥後臺總那麼點代碼,能處理自動處理任意表和數據了:
下麵的方法只需要前端頁面只需要傳遞一個表名(+對應的數據):

如果進一步,把表名配置在資料庫里的Url菜單欄位,那麼就形成一個自動化的頁面了:
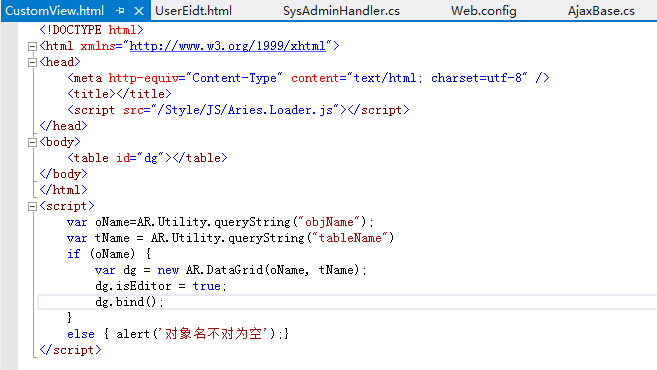
而這些自動自動化框架編程思維,都是實體ORM不具備的,實體ORM只能小打小鬧的針對某個界面一堆代碼一堆代碼的敲。
看一個API介面設計:
假設,有個App項目,有Android版和IOS,它們都需要調用後臺API,這時候,你怎麼設計?
先不動,等著App產品經理把界面原型都定稿了,再針對App的界面需要哪些元素,和開發App開發工程師商量一下,再針對請求寫方法?
畢竟你要知道讀哪個表,查哪些數據,所以你只能被動?每新增一個頁面或功能,你都要跑去後臺寫一堆業務邏輯代碼,然後又進行聯調?
是不是特累?
看一下直接用此框架後,你的設計的過程會變的怎麼簡單、優雅和具有抽象思維:
介面核心代碼:
using (MAction action = new MAction(tableName)) { action.Select(pageIndex, pageSize,where).ToJson(); }
接下來你要設計的是:
1:給App定好客戶端請求參數的格式:{key:'xx',pageindex:1,pagesize:10,wherekey:'xxxx'}
2:將表名映射放到資料庫(Key,Value),App只傳遞Key當請求名稱
3:根據實際業務,構造好where條件。
多設計幾個這樣通用介面,給到app開發人員就可以了,看看有什麼優勢:
1:可以減少很多溝通成本。
2:API的設計是通用型的,減少大量的代碼,後續維護簡單可配置。
3:一開始就可以動工了,不需要等到App原型啟動後再動手。
4:連表是否存在,長成什麼樣,都可以事先不管用,後期可資料庫配置。
5:實現一套之後,換公司換項目換業務也可以用,因為你的設計與具體業務是解耦的。
試想換成實體ORM,你是不是要事先有資料庫,生成一堆實體吧,然後具體業務不斷New實例吧,思維的局限就只能被限制在具體的業務。
框架的抽象思維及where條件的智能化推導
先看一張圖:

對於表的常見數據增刪改查操作,從上圖可見,框架最終抽象出兩個核心參數:
表名+where條件:
曾經我也曾思考過語法糖,是否把Where這一塊設計成:.Select(...).Where(...).Having(...).GroupBy(...).OrderBy(...)...
後來還是堅持初心保持原生:
1:開發人員沒有學習成本。
2:保持框架的青春創造力。
3:具備自動化框架思維。
語法糖的壞處:
1:框架自身復設計雜度增加。
2:使用者學習成本高,使用複雜度增加。
3:不適合自動化擴展:設計已成表達式,無法動態根據某Key和表去動態構造查詢條件!只適合具體實例和業務,不適合自動化編程。
當然,在大多數的Where條件里,很多是根據主鍵或唯一鍵件的條件,為了進一步抽象及適應自動化編程,我設計出了自能化推導機制。
針對where的智能化推導:
看以下兩個代碼:左邊是構造相對完整的的where,右邊的能自動推導出where。(內部有防SQL註入,所以不用擔心where條件註入問題)。
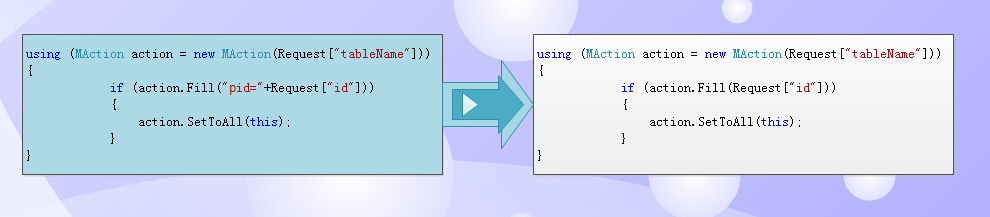
通過智能化推導,去掉了主鍵名參數(因為不同的表的主鍵表不一樣),智能推導產生,可以讓編程者主要關心傳過來的值,而不用關註具體的主鍵名叫什麼。
如果值的是是“1,2,3"這種按逗號分隔的多值,框架會自動推導轉成 主鍵 in (1,2,3) 條件。
再看兩組代碼:左邊依舊是相對完成where條件,右邊是智能推導型編程。
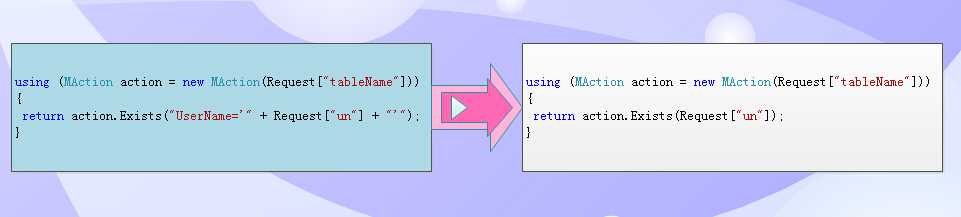
註意:同樣是傳值,但我們要的是UserName,不是主鍵,系統也能推導出來?
這時候系統會根據值的類型、主鍵、唯一鍵等值的類型綜合分析,得到該值應該用主鍵或是唯一鍵去構造出where。
(PS:唯一鍵推導是昨天才完成的功能,所以只有最新版本才有。)
正因框架有智能推導功能,屏蔽欄位差異,讓使用者只需要關註傳值即可。它也是讓你實現自動化框架編程思維的重要功能。
自動化批量式編程:
看一張圖:MDataTable:它能和各種數據類型直接產生批量式互相轉換:

MDataTable 是框架的核心之一,上篇文章就有對它的專屬介紹。
當然,Table的構建,往往基於行,所以再看一張圖:MDataRow (它是單行數據的核心)
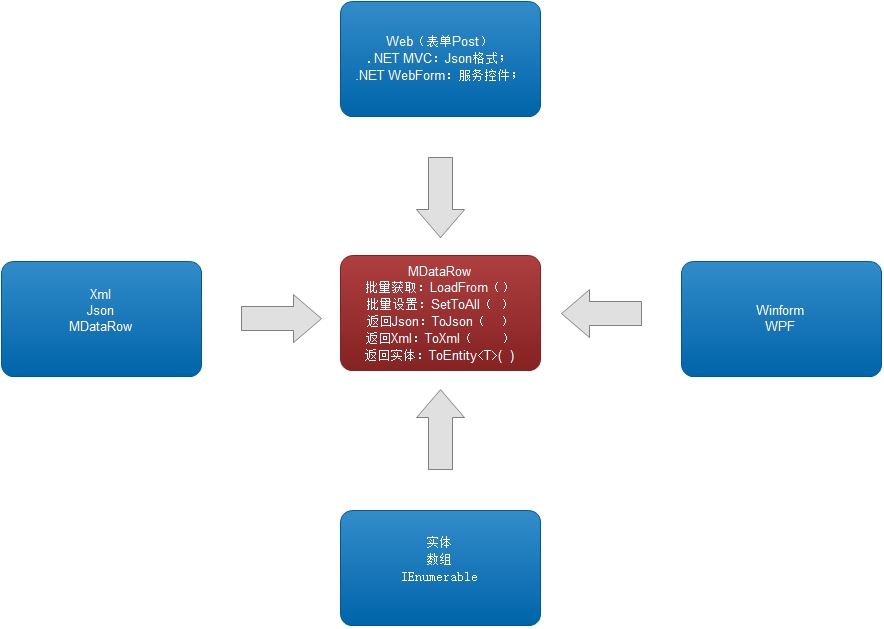
其實正因為MDataRow打通了單行的數據的批量來來去去,所以才造就了MDataTable的多行數據的批量處理。
事實上MDataRow是核心實現層,只是它比較低調。
總結:
在使用框架編程時,你會發現更多關心的是:數據的流向、及如何為抽象的參數構建配置系統。
在大部分的編程時間里,除了特定的欄位意義需要具體關註,多數都是基於自動化編程思維,數據流向思維。
早期的系列:沒有這種編程思維,難免看了介紹後會有種違各感。
而今的系統:自動化框架編程思維,也是用戶忠誠度高喜歡上的原因,特別是免費之後。
當然,後續也會針對此系列,重新寫使用教程,並且教程源碼也會同步更新到SVN,敬請期待。

