
前幾天剛好同事問起在Cortex M上延時不准的問題,在網上也沒找到比較滿意的答案,乾脆自己對這個問題做一個總結。 根據我們的經驗,最容易想到的大概通過計算指令周期來解決。該思路在Cortex上並不是很適用:一方面MCU從Flash取指是有延時的,另一方面Cortex的指令集不是固定周期的,特別從M ...
前幾天剛好同事問起在Cortex-M上延時不准的問題,在網上也沒找到比較滿意的答案,乾脆自己對這個問題做一個總結。
根據我們的經驗,最容易想到的大概通過計算指令周期來解決。該思路在Cortex上並不是很適用:一方面MCU從Flash取指是有延時的,另一方面Cortex的指令集不是固定周期的,特別從M3加入分支預測後,分支指令在Cortex-M不同型號上的結果都不相同。因此除了指令周期外,我們需要考慮的東西還有很多,才能得到正確的結果。
不帶分支預測器的情況
仍然先從不帶分支預測器的Cortex-M0開始,通過計算指令周期延時的實現代碼如下:
void delay_us(us) {
delay_ntimes((us * sysclk - 8) / 4);
}
__asm void delay_ntimes(unsigned int n)
{
L1
SUBS R0, #1
BCS L1
BX LR
}從這段代碼可發現兩個主要問題:
一、delay_us里的公式是怎麼來的:
假如想延時us微秒,系統時鐘為48MHz,即sysclk=48,那麼周期數period_count滿足以下公式:
period_count = us * sysclk;
然後再delay_ntimes這個函數,又能推出period_count還滿足以下公式(見第二個問題的分析):
period_count = 8 + 4 n
於是:
n = (us sysclk - 8 ) / 4;
這就解決了第一個問題,需要註意的是:該公式忽略了跳轉到delay_us和(us * sysclk -8 )/4的幾個固定周期。
二、delay_ntimes的周期數怎麼算:
它的周期數滿足以下公式:
period_count = 8 + 4 * n;
這個要根據指令集的周期數來確定,請看下表:
| 操作 | 描述 | 彙編命令 | 周期 |
|---|---|---|---|
| Subtract | Lo to Lo | SUBS Rd,Rn,Rm | 1 |
| 3-bit immediate | SUBS Rd,Rn,#<imm> | 1 | |
| 8-bit immediate | SUBS Rd,Rd,#<imm> | 1 | |
| Branch | Conditional | B<cc> <label> | 1或3 |
| Unconditional | B<label> | 3 | |
| With link | BL<label> | 4 | |
| With exchange | BX Rm | 3 | |
| With link and exchange | BLX Rm | 3 |
先考慮n為0的情況,
SUBS為1周期+BCS為1周期+BX為3周期+外層調用delay_times(相當於BLX指令)的3周期=8周期。
當n不為0時,將再執行n次SUBS和BCS執行,SUBS仍為1周期,BCS有跳轉3周期,所以是4n個周期,因此該函數的執行周期數為:
period_count=8+4n;
好了,在瞭解了原理之後,是時候到真正的板子上去測試了。
然而在MCU上的實測結果卻不如預期,延時5MS,實測為7.5MS;延時10MS,實測15MS。為什麼會出現這樣的現象?
這個跟MCU的設計有關。一般代碼都放在FLASH上,MCU中Cortex核要從FLASH上先取出指令,然後才能將指令放到指令流水線上執行。而上面的分析忽略了Cortex核從FLASH取出指令的時間,因此實測值與理論值分析不一致。
不同的MCU從FLASH讀取指令的時間消耗各不相同,因此需要根據不同MCU去調整公式,這是一個比較繁瑣的過程,比如這款MCU,將公式修改為(us * sysclk - 8) / 6就得到了正確結果。
另外一個做法是不修改公式,將延時代碼放到RAM中,許多MCU從RAM取出指令沒有等待周期。使用該方法再次測試,延時結果與理論計算一致。
但值得註意的是,不是所有MCU都滿足RAM取值零等待周期的條件,因此一定要做測試。
讀者若對MCU如何從FLASH讀取指令感興趣,參考資料[4]的分析是比較清楚的。
帶分支預測器的情況
將上面的代碼放到Cortex-M3和Cortex-M4的晶元上測試,測試結果是錯誤的,不論在FLASH還是在RAM中,這個是由於Cortex-M3,Cortex-M4上的指令流水線帶有分支預測器引起的。
要瞭解分支預測器,就不得不提指令流水線。Cortex-M3是三級流水線:取指,解碼,執行。但是沒找到CORTEX方面較好的圖,以下討論就基於下圖的4級流水線,該圖多了一步:寫回。這並不影響我們的討論。
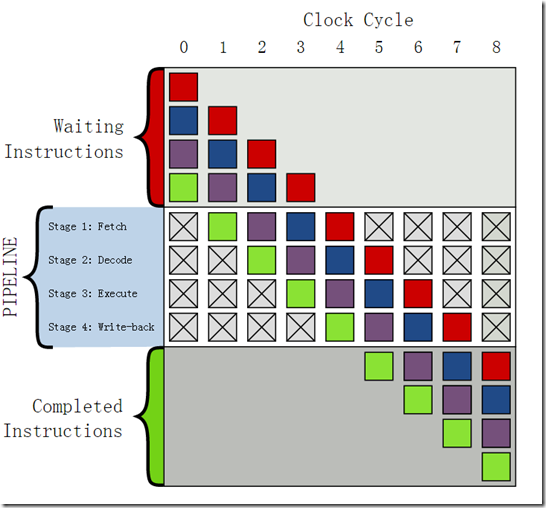
(該圖引用自參考資料[1])
假設一條指令從執行開始到執行結束需要4個時鐘周期,在沒有流水線的情況下,需要等待第一條指令執行結束,才能取第二條指令,這時兩條指令就用了8個周期,效率是很低的。
引入4級流水線將指令拆成4個步驟:取指、解碼、執行、寫回。當第一條指令處於解碼時,同時對第二條指令取指;對第一條指令執行時,同時對第二條指令解碼,對第三條指令取指;對第一條指令寫回時,同時對第二條執行,第三條解碼,第四條取指;如此這般。最終達到的效果就如上圖所示,只有第一條指令需要4個周期,其他後續的指令都只需要1個周期,極大地提高了處理效率。
流水線的高效率是基於指令順序執行的前提,在執行跳轉指令時,流水線將被清空,又回到了上圖中的第一步,跳轉後的第一條指令要執行仍然需要4周期。因此如果程式頻繁跳轉,流水線的作用就大打折扣。
為瞭解決這個問題,就引入了分支預測器:它會提前檢測到跳轉指令,並根據預判結果取指。如果預判結果是不跳轉,就按順序取下一條指令;如果預判結果是跳轉,就從跳轉的目的地址取下一條指令。假如預測對了,那麼流水線就不會被清空,仍然可以一條指令1個周期;如果預測錯了,下一條指令仍然要4周期。從這裡看出,分支預測器對於提高流水線效率是有幫助的。值得一提的是,預判對了能減少指令延遲,但是否是零延遲取決於MCU的設計;預判錯了清空流水線也未必是唯一的做法,同樣取決於MCU的設計。
回到Cortex-M3的延時問題,網路上找到的資料提到分支預測器將延遲減小到1個周期,沒有找到更詳細的說明。那麼理論上計算公式就應該調整為(us * sysclk - 8) / 3,在兩款Cortex-M3和兩款Cortex-M4上測試,測試結果與理論值一致。
微秒級精確延時的其他方法
對於Cortex而微秒級延時最通用的方法,大概便是通過比較SysTick的SYST_CVR寄存器來做延時,理論誤差在1us內(基於48MHz主頻)。以下為實現代碼:
/*
* 使用SysTick的CVR實現微秒級精確延時,一般SysTick周期設置為10MS,因此該方法適用於10MS以內的延時
*/
void delay_us(int us) {
unsigned t1, t2, count, delta, sysclk;
sysclk = 48;//假設為48MHz主頻
t1 = SYST_CVR;
while (1) {
t2 = SYST_CVR;
delta = t2 < t1 ? (t1 - t2) : (SYST_RVR - t2 + t1) ;
if (delta >= us * sysclk)
break;
}
}其他補充點
- 本文假設在延時過程中沒有產生任何中斷,如果有中斷產生,將影響延時精確性。
- 這部分的內容屬於電腦體繫結構。
- 以上測試時間範圍在[0,10MS),該範圍之外未詳細測試,建議採用其他方法。
- 覆蓋測試的MCU:1款Cortex-M0,2款Cortex-M3,2款Cortex-M4。
- 在我測試的兩款Cortex-M3 MCU上,將代碼都放RAM上,測試結果比放在FLASH差,而在Cortex-M4 MCU上,測試結果都一樣,目前沒有找到合理的解釋。
參考資料
- 淺談分支預測、流水線與條件轉移
- Cortex-M0指令集
- CPU性能衡量參數-主頻,MIPS,CPI,時鐘周期,機器周期,指令周期
- Cortex-M3的周期判斷的依據是什麼
- 電腦體繫結構——流水線中的相關——延遲分支方法


