
隨著唯品會業務的快速發展,訂單量的不斷增長,原有的訂單存儲架構已經不能滿足公司的發展了,特別是在大促高峰期,原訂單庫已經成為搶購瓶頸,已經嚴重製約公司的發展。 唯品會舊訂單庫包含幾十張訂單相關表,舊訂單庫是典型的一主多從架構;主庫容量已接近伺服器物理空間上限,同時也已經達到MySQL的處理上限,很快 ...
隨著唯品會業務的快速發展,訂單量的不斷增長,原有的訂單存儲架構已經不能滿足公司的發展了,特別是在大促高峰期,原訂單庫已經成為搶購瓶頸,已經嚴重製約公司的發展。
唯品會舊訂單庫包含幾十張訂單相關表,舊訂單庫是典型的一主多從架構;主庫容量已接近伺服器物理空間上限,同時也已經達到MySQL的處理上限,很快將無法再處理新增訂單。
舊訂單庫面臨的問題有:
1、超大容量問題
-
訂單相關表都已經是超大表,最大表的數據量已經是幾十億,資料庫處理能力已經到了極限;
-
單庫包含多個超大表,占用的硬碟空間已經接近了伺服器的硬碟極限,很快將無空間可用;
2、性能問題
單一伺服器處理能力是有限的,單一訂單庫的TPS也有上限,不管如何優化,總會有達到上限,這限制了單位時間的訂單處理能力,這個問題在大促時更加明顯,如果不重構,訂單達到一定量以後,就無法再繼續增長,嚴重影響到用戶體驗。
3、升級擴展問題
-
單一主庫無法靈活的進行升級和擴展,無法滿足公司快速發展要求;
-
所有的訂單數據都放在同一庫裡面,存在單點故障的風險;
綜上所述,容量、性能問題是急需解決的問題,擴展是為了將來3~5年內能夠很好的滿足唯品會快速發展的需要,而不需要每隔幾個月花費人力物力去考慮擴容等問題。
解決方法思考
1、解決容量問題
我們可以考慮到最直接的方式是增加大容量硬碟,或者對IO有更高要求,還可以考慮增加SSD硬碟來解決容量的問題。此方法無法解決單表數據量問題。
可以對數據表歷史數據進行歸檔,但也需要頻繁進行歸檔操作,而且不能解決性能問題。
2、解決性能問題
提高資料庫伺服器的配置,這個可以提升一定數量的QPS和TPS,但仍然不能解決單伺服器連接數、IO讀寫存在上限的問題,此方法仍然存在單點故障的問題。
拆分方法探討
常見的資料庫拆分方式有三種:垂直拆分、水平拆分、垂直水平拆分。
1、垂直拆分
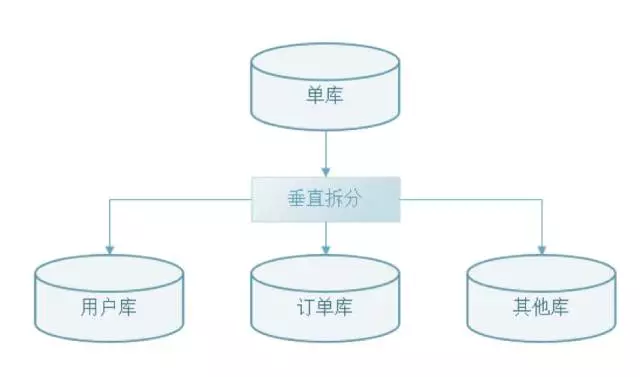
垂直拆庫是根據資料庫裡面的數據表的相關性進行拆分,比如:一個資料庫裡面既存在用戶數據,又存在訂單數據,那麼垂直拆分可以把用戶數據放到用戶庫、把訂單數據放到訂單庫。如下圖:
垂直拆表是對數據表進行垂直拆分的一種方式,常見的是把一個多欄位的大表按常用欄位和非常用欄位進行拆分,每個表裡面的數據記錄數一般情況下是相同的,只是欄位不一樣,使用主鍵關聯,如下圖: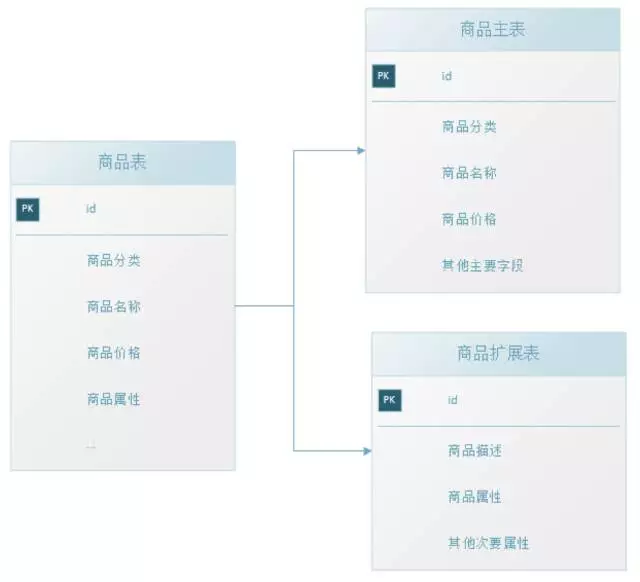
2、水平拆分
水平拆分是把單表按某個規則把數據分散到多個表的拆分方式,比如:把單表1億數據按某個規則拆分,分別存儲到10個相同結果的表,每個表的數據是1千萬,拆分出來的表,可以分別放至到不同資料庫中,即同時進行水平拆庫操作,如下圖:
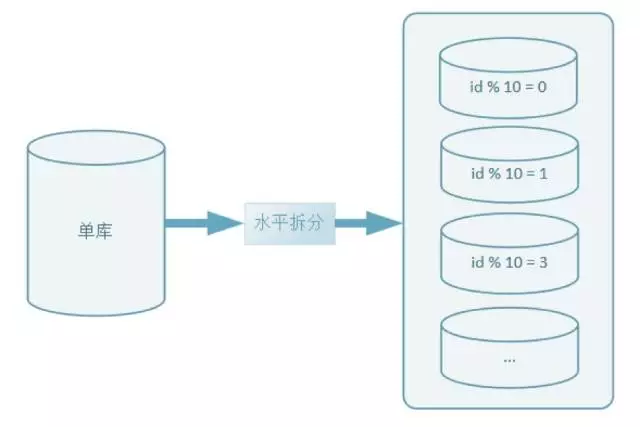
水平拆分可以降低單表數據量,讓每個單表的數據量保持在一定範圍內,從而提升單表讀寫性能。但水平拆分後,同一業務數據分佈在不同的表或庫中,可能需要把單表事務改成跨表事務,需要轉變數據統計方式等。
3、垂直水平拆分
垂直水平拆分,是綜合了垂直和水平拆分方式的一種混合方式,垂直拆分把不同類型的數據存儲到不同庫中,再結合水平拆分,使單表數據量保持在合理範圍內,提升總TPS,提升性能,如下圖:
垂直拆分策略
原訂單庫把所有訂單相關的數據(訂單銷售、訂單售後、訂單任務處理等數據)都放在同一資料庫中,不符合電商系統分層設計,對於訂單銷售數據,性能第一,需要能夠在大促高峰承受每分鐘幾萬到幾十萬訂單的壓力;而售後數據,是在訂單生成以後,用於訂單物流、訂單客服等,性能壓力不明顯,只要保證數據的及時性即可;所以根據這種情況,把原訂單庫進行垂直拆分,拆分成訂單售後數據、訂單銷售數據、其他數據等,如下圖: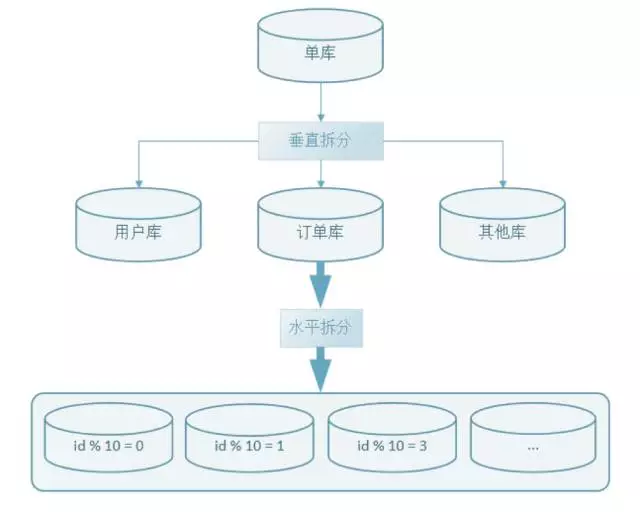
水平拆分策略
垂直拆分從業務上把訂單下單數據與下單後處理數據分開,但對於訂單銷售數據,由於數據量仍然巨大,最大的訂單銷售相關表達到幾十億的數據量,如果遇到大型促銷(如:店慶128、419、618、雙十一等等),資料庫TPS達到上限,單銷售庫單訂單表仍然無法滿足需求,還需要進一步進行拆分,在這裡使用水平拆分策略。
訂單分表是首先考慮的,分表的目標是保證每個數據表的數量保持在1000~5000萬左右,在這個量級下,數據表的大小與性能是最理想的。
如果幾十個分表都放到一個訂單庫裡面,運行於單組伺服器上,則受限於單組伺服器的處理能力,資料庫的TPS有限,所以需要考慮分庫,把分表放到分庫裡面,減輕單庫的壓力,增加總的訂單TPS。
1、用戶編號HASH切分
使用用戶編號哈希取模,根據數據量評估,把單庫拆分成n個庫,n個庫分別存放到m組伺服器中,如下圖:
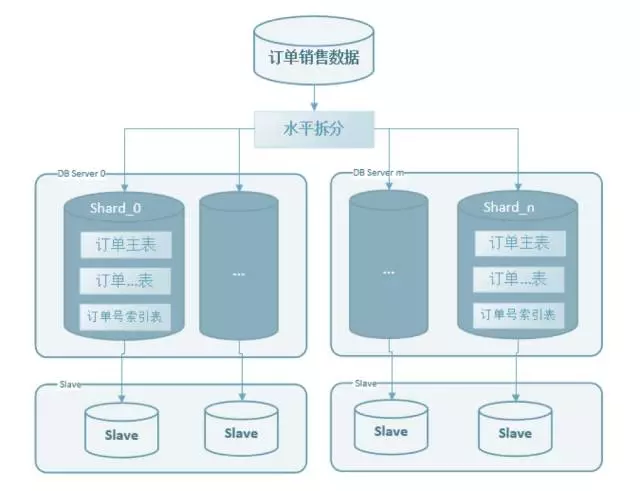
每組伺服器容納4個庫,如果將來單伺服器達到性能、容量等瓶頸,可以直接把資料庫水平擴展為2倍伺服器集群,還可以繼續擴展為4倍伺服器集群。水平擴展可以支撐公司在未來3~5年的快速訂單增長。
使用用戶編號進行 sharding,可以使得創建訂單的處理更簡單,不需要進行跨庫的事務處理,提高下單的性能與成功率。
2、訂單號索引表
根據用戶編號進行哈希分庫分表,可以滿足創建訂單和通過用戶編號維度進行查詢操作的需求,但是根據統計,按訂單號進行查詢的占比達到80%以上,所以需要解決通過訂單號進行訂單的CURD等操作,所以需要建立訂單號索引表。
訂單號索引表是用於用戶編號與訂單號的對應關係表,根據訂單號進行哈希取模,放到分庫裡面。根據訂單號進行查詢時,先查出訂單號對應的用戶編號,再根據用戶編號取模查詢去對應的庫查詢訂單數據。
訂單號與用戶編號的關係在創建訂單後是不會更改的,為了進一步提高性能,引入緩存,把訂單號與用戶編號的關係存放到緩存裡面,減少查表操作,提升性能,索引不命中時再去查表,並把查詢結果更新到緩存中。
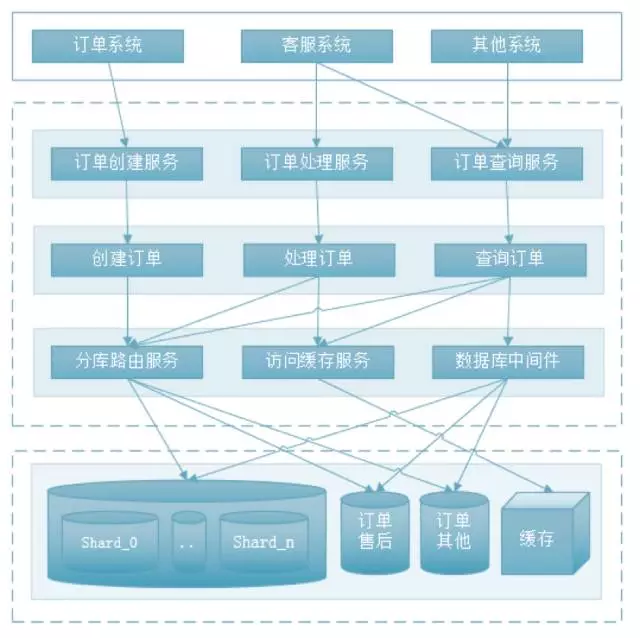
3、分散式資料庫集群
訂單水平分庫分表以後,通過用戶編號,訂單號的查詢可以通過上面的方法快速定位到訂單數據,但對於其他條件的查詢、統計操作,無法簡單做到,所以引入分散式資料庫中間件。
下圖是基本構架:
總結與思考
技術架構與業務場景息息相關,不能脫離實際的業務場景、歷史架構、團隊能力、數據體量等等去做架構重構,對於一家快速發展的電子商務公司,訂單系統是核心,訂單庫是核心的核心,訂單庫的重構就像汽車在高速公路上跑著的過程中更換輪胎。
本文是對唯品會訂單庫重構——採用分庫分表策略對原訂單庫表進行拆分的粗略總結,在訂單庫重構過程中遇到的問題遠遠超過這些,比如:歷史數據的遷移、各外圍系統的對接等,但這些在公司強大的技術團隊面前,最終都順利的解決,新舊訂單庫順利的切換,給公司快速的業務發展提供堅實的保障。


