
# Redis Redis是一個開源(BSD許可高性能的記憶體存儲的key-value資料庫! 可用作資料庫,高速緩存和消息隊列代理。它支持字元串、哈希表、列表(List)、集合(Set)、有序集合(Ordered Sets),點陣圖(bitmap),hyperloglogs,GEO等數據類型。內置複製 ...
02_重要的兩個日誌 redo log 和 binlog
MySQL 45 講Note:
課程專欄名稱:《MySQL實戰45講》課程
筆記參考:MYSQL45 講
想要理解這兩個日誌 redo log 和 binlog ;我們需要對MySQL 的備份恢復機制有一個基本的瞭解。
之前你可能經常聽 DBA 同事說,MySQL 可以恢復到半個月內任意一秒的狀態,帶著好奇的態度,這是怎樣做到的呢?
如果你使用的是 InnoDB 引擎,那麼一般我們會使用 物理日誌 redo log 和邏輯日誌 binlog 來進行備份恢復。
redo log 是物理日誌,記錄的是“在某個數據頁上做了什麼修改”;binlog 是邏輯日誌,記錄的是這個語句的原始邏輯,比如“給 ID=2 這一行的 c 欄位加 1 ”。
一條SQL更新語句如何執行
在講述日誌內容之前,我們先回顧一下查詢語句的執行過程:
一條查詢語句的執行過程一般是經過連接器、分析器、優化器、執行器等功能模塊,最後到達存儲引擎。
在Mysql 執行更新語句的時候,查詢語句的那一套流程,更新語句也是同樣會走一遍。
與查詢流程不一樣的是,更新流程還涉及兩個重要的日誌模塊,它們正是我們今天要討論的主角:redo log(重做日誌)和 binlog(歸檔日誌)。
日誌模塊:redo log
粉板和賬本
redo log 的機制,我們可以先看一下孔乙己中酒店掌柜記賬的方式。
《孔乙己》這篇文章中的酒店掌柜有一個粉板,專門用來記錄客人的賒賬記錄。如果賒賬的人不多,那麼他可以把顧客名和賬目寫在板上。但如果賒賬的人多了,粉板總會有記不下的時候,這個時候掌柜一定還有一個專門記錄賒賬的賬本。
如果有人要賒賬或者還賬的話,掌柜一般有兩種做法:
- 一種做法是直接把賬本翻出來,把這次賒的賬加上去或者扣除掉;
- 另一種做法是先在粉板上記下這次的賬,等打烊以後再把賬本翻出來核算。
在生意紅火櫃臺很忙時,掌柜一定會選擇後者,因為前者操作實在是太麻煩了。首先,你得找到這個人的賒賬總額那條記錄。你想想,密密麻麻幾十頁,掌柜要找到那個名字,可能還得帶上老花鏡慢慢找,找到之後再拿出算盤計算,最後再將結果寫回到賬本上。
粉板和賬本配合的整個過程,就是 MySQL 里經常說到的 WAL 技術,WAL 的全稱是 Write-Ahead Logging,它的關鍵點就是先寫日誌,再寫磁碟,也就是先寫粉板,等不忙的時候再寫賬本。[先寫記憶體,再寫磁碟]
具體來說,當有一條記錄需要更新的時候,InnoDB 引擎就會先把記錄寫到 redo log(粉板)裡面,並更新記憶體,這個時候更新就算完成了。
同時,InnoDB 引擎會在適當的時候,將這個操作記錄更新到磁碟裡面,而這個更新往往是在系統比較空閑的時候做,這就像打烊以後掌柜做的事。
操作流程
InnoDB 的 redo log 是固定大小的,比如可以配置為一組 4 個文件,每個文件的大小是 1GB,那麼這塊“粉板”總共就可以記錄 4GB 的操作。從頭開始寫,寫到末尾就又回到開頭迴圈寫,如下麵所示。
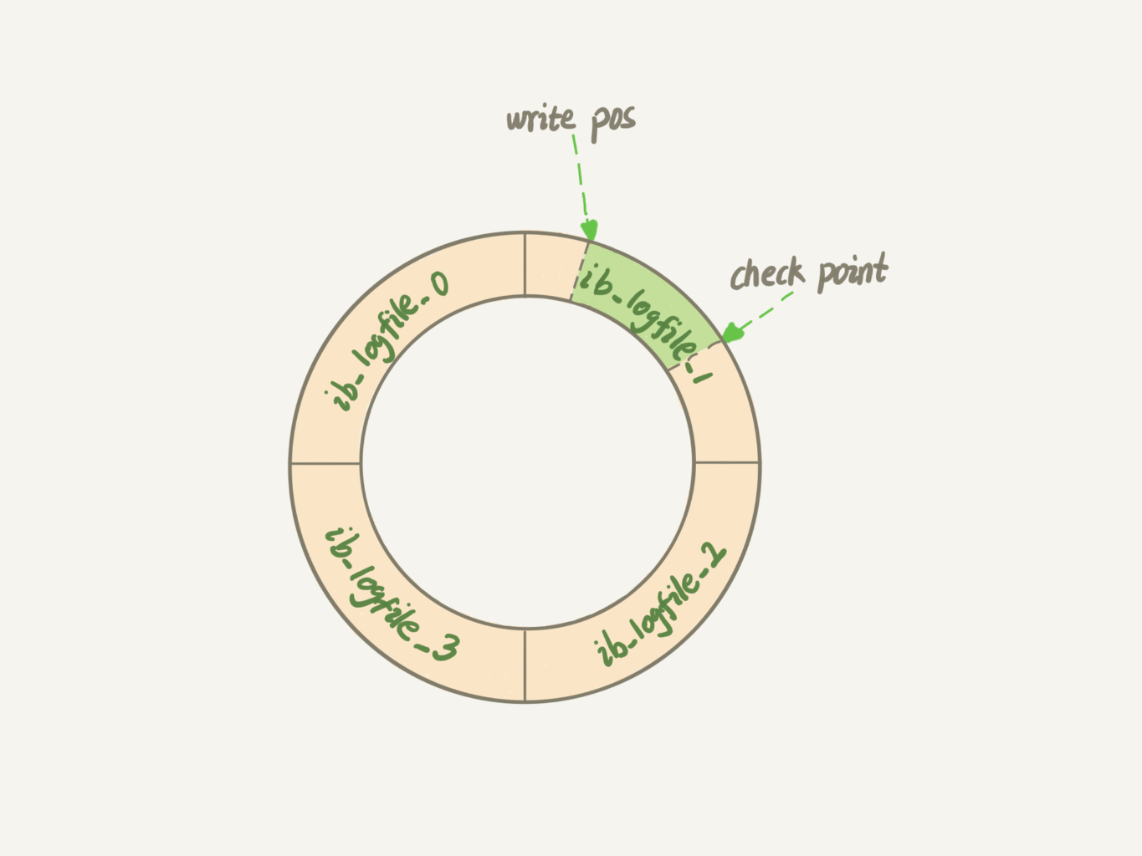
裡面有一個 write pos 和 check point 的概念:
write pos 是當前記錄的位置,一邊寫一邊後移,寫到第 3 號文件末尾後就回到 0 號文件開頭。
checkpoint 是當前要擦除的位置,也是往後推移並且迴圈的,擦除記錄前要把記錄更新到數據文件。
write pos 和 checkpoint 之間的是“粉板”上還空著的部分,可以用來記錄新的操作。如果 write pos 追上 checkpoint,表示“粉板”滿了,這時候不能再執行新的更新,得停下來先擦掉一些記錄,把 checkpoint 推進一下。
有了 redo log,InnoDB 就可以保證即使資料庫發生異常重啟,之前提交的記錄都不會丟失,這個能力稱為crash-safe。
crash-safe
crash-safe 是指在MySQL資料庫發生異常崩潰時,資料庫能夠保證數據的完整性和一致性,從而避免數據丟失或數據損壞的情況。
redo log 用於保證 crash-safe 能力。
- innodb_flush_log_at_trx_commit 這個參數設置成 1 的時候,表示每次事務的 redo log 都直接持久化到磁碟。這個參數我建議你設置成 1,這樣可以保證 MySQL 異常重啟之後數據不丟失。
- sync_binlog 這個參數設置成 1 的時候,表示每次事務的 binlog 都持久化到磁碟。這個參數我也建議你設置成 1,這樣可以保證 MySQL 異常重啟之後 binlog 不丟失。
日誌模塊:binlog
上面聊到的粉板 redo log 是 InnoDB 引擎特有的日誌,而 Server 層也有自己的日誌,稱為 binlog(歸檔日誌)。
redo log 是 InnoDB 兩種日誌有以下三點不同:
- redo log 是 InnoDB 引擎特有的;binlog 是 MySQL 的 Server 層實現的,所有引擎都可以使用。
- redo log 是物理日誌,記錄的是“在某個數據頁上做了什麼修改”;binlog 是邏輯日誌,記錄的是這個語句的原始邏輯,比如“給 ID=2 這一行的 c 欄位加 1 ”。
- redo log 是迴圈寫的,空間固定會用完;binlog 是可以追加寫入的。“追加寫”是指 binlog 文件寫到一定大小後會切換到下一個,並不會覆蓋以前的日誌。
update 語句內部執行流程
-
有了對這兩個日誌的概念性理解,我們再來看執行器和 InnoDB 引擎在執行這個簡單的 update 語句時的內部流程。
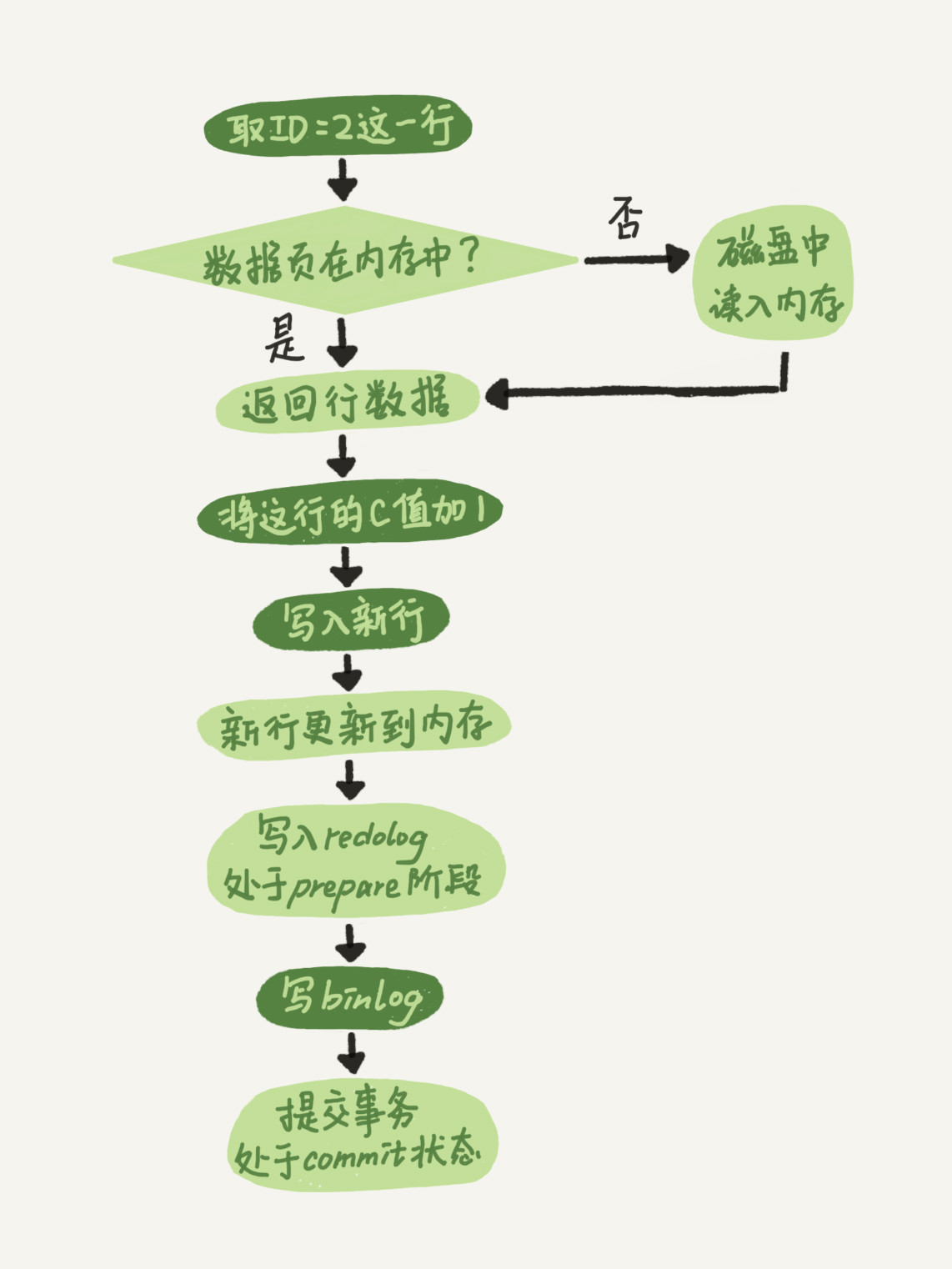
- 執行器先找引擎取 ID=2 這一行。ID 是主鍵,引擎直接用樹搜索找到這一行。如果 ID=2 這一行所在的數據頁本來就在記憶體中,就直接返回給執行器;否則,需要先從磁碟讀入記憶體,然後再返回。
- 執行器拿到引擎給的行數據,把這個值加上 1,比如原來是 N,現在就是 N+1,得到新的一行數據,再調用引擎介面寫入這行新數據。
- 引擎將這行新數據更新到記憶體中,同時將這個更新操作記錄到 redo log 裡面,此時 redo log 處於 prepare 狀態。然後告知執行器執行完成了,隨時可以提交事務。
- 執行器生成這個操作的 binlog,並把 binlog 寫入磁碟。
- 執行器調用引擎的提交事務介面,引擎把剛剛寫入的 redo log 改成提交(commit)狀態,更新完成。
update 語句的執行流程圖,圖中淺色框表示是在 InnoDB 內部執行的,深色框表示是在執行器中執行。
兩階段提交
你可能註意到了,最後三步看上去有點“繞”,將 redo log 的寫入拆成了兩個步驟:prepare 和 commit,這就是"兩階段提交"。
兩階段提交操作是為了讓兩份日誌之間的邏輯一致;
兩階段提交的具體操作和不使用“兩階段提交”會發生的內容(反證證明需要兩階段提交操作)。
更新操作的兩階段提交
- 當一條SQL語句執行時,如果需要修改InnoDB表的數據,那麼會先將修改操作記錄在redo log中,然後再將數據修改到記憶體中。【redo log處於 Prepare狀態】
- 之後執行器會生成這個操作的binlog,並把 binlog 寫入磁碟
- 當事務提交時,redo log會被刷入磁碟,保證數據的持久化。【執行器調用引擎的提交事務介面,引擎把剛剛寫入的 redo log 改成提交(commit)狀態,更新完成。】
如果不使用“兩階段提交”,那麼資料庫的狀態就有可能和用它的日誌恢復出來的庫的狀態不一致
-
先寫 redo log 後寫 binlog。
- 假設在 redo log 寫完,binlog 還沒有寫完的時候,MySQL 進程異常重啟。由於我們前面說過的,redo log 寫完之後,系統即使崩潰,仍然能夠把數據恢復回來,所以恢復後這一行 c 的值是 1。 但是由於 binlog 沒寫完就 crash 了,這時候 binlog 裡面就沒有記錄這個語句。因此,之後備份日誌的時候,存起來的 binlog 裡面就沒有這條語句。
- 然後你會發現,如果需要用這個 binlog 來恢復臨時庫的話,由於這個語句的 binlog 丟失,這個臨時庫就會少了這一次更新,恢復出來的這一行 c 的值就是 0,與原庫的值不同。
-
先寫 binlog 後寫 redo log。
- 如果在 binlog 寫完之後 crash,由於 redo log 還沒寫,崩潰恢復以後這個事務無效,所以這一行 c 的值是 0。但是 binlog 裡面已經記錄了“把 c 從 0 改成 1”這個日誌。
- 所以,在之後用 binlog 來恢復的時候就多了一個事務出來,恢復出來的這一行 c 的值就是 1,與原庫的值不同。
怎樣讓資料庫恢復到半個月內任意一秒的狀態?
binlog 會記錄所有的邏輯操作,並且是採用“追加寫”的形式。如果你的 DBA 承諾說半個月內可以恢復,那麼備份系統中一定會保存最近半個月的所有 binlog,同時系統會定期做整庫備份。這裡的“定期”取決於系統的重要性,可以是一天一備,也可以是一周一備。
當需要恢復到指定的某一秒時,比如某天下午兩點發現中午十二點有一次誤刪表,需要找回數據,那你可以這麼做:
- 首先,找到最近的一次全量備份,如果你運氣好,可能就是昨天晚上的一個備份,從這個備份恢復到臨時庫;
- 然後,從備份的時間點開始,將備份的 binlog 依次取出來,重放到中午誤刪表之前的那個時刻。
這樣你的臨時庫就跟誤刪之前的線上庫一樣了,然後你可以把表數據從臨時庫取出來,按需要恢復到線上庫去。
小結
redo log 用於保證 crash-safe 能力,可以保證 MySQL 異常重啟之後數據不丟失。
兩階段提交是跨系統維持數據邏輯一致性時常用的一個方案。
通過 binlog 日誌的備份文件將數據恢復到臨時庫,從臨時庫的數據按需恢複數據。


