
摘要:應用運維管理平臺(AOM)和Cassandra是兩個不可分割的組成部分,它們共同構成了一個高效的解決方案,可以幫助企業在應用運維業務上取得巨大的優勢。在這篇文章中,我們將介紹AOM和Cassandra的優勢和特點,揭曉它們如何為企業保持市場競爭力的秘密。 本文分享自華為雲社區《海量數據運維要給 ...
摘要:應用運維管理平臺(AOM)和Cassandra是兩個不可分割的組成部分,它們共同構成了一個高效的解決方案,可以幫助企業在應用運維業務上取得巨大的優勢。在這篇文章中,我們將介紹AOM和Cassandra的優勢和特點,揭曉它們如何為企業保持市場競爭力的秘密。
本文分享自華為雲社區《海量數據運維要給力,華為雲GaussDB(for Cassandra)來助力》,作者:華為雲社區精選 。
導讀
隨著容器技術的普及,越來越多的企業通過微服務框架開發應用,業務逐漸轉變為雲上實現服務,運維也逐漸轉向雲上運維服務。在此環境下,雲上應用的運維也遭遇了新的挑戰:
- 運維人員技能要求高,需要同時維護多套系統,配置繁雜。分散式追蹤系統的學習和使用成本高,穩定性差,性價比低。
- 雲化場景下的分散式應用問題分析困難,主要表現在如何可視化微服務間的依賴關係,如何提高應用性能體驗,如何將散落的日誌進行關聯分析,以及如何快速追蹤問題。
針對以上挑戰, AOM應運而生。
AOM是什麼
AOM是由華為雲研發的雲上應用一站式立體化運維管理平臺,由應用資源管理、監控中心(可觀測性分析)、自動化運維、採集管理四個子服務構成,提供一站式可觀測性分析和自動化運維方案,支持快速從雲端和本地採集指標、日誌和性能等數據,幫助用戶及時發現故障,全面掌握應用、資源及業務的實時運行狀況,提升企業海量數據運維的自動化能力和效率。
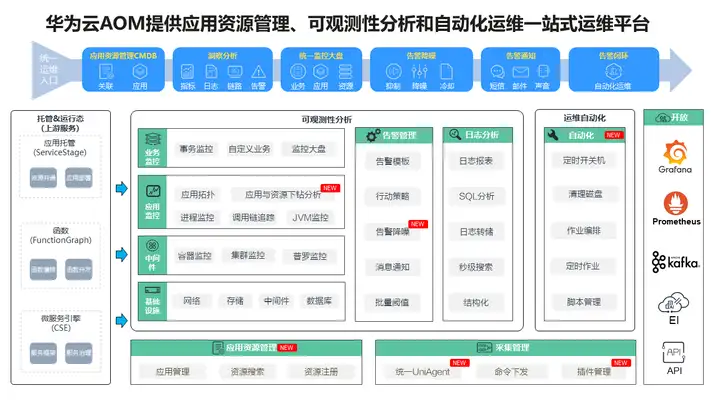
AOM優勢眾多,功能強大,其背後離不開支撐其海量數據運轉的智能數據底座——華為雲GaussDB(for Cassandra)。
為什麼選擇GaussDB(for Cassandra)?
華為雲GaussDB(for Cassandra)是一款相容Cassandra生態的雲原生NoSQL資料庫,支持類SQL語法CQL。在華為雲高性能、高可用、高可靠、高安全、可彈性伸縮的基礎上,提供了一鍵部署、快速備份恢復、計算存儲獨立擴容、監控告警等服務能力,尤其適用於各種海量數據處理和高併發業務場景。
- 出現數據熱點的業務。例如:某新聞時事APP需要管理大量新聞時事數據,當出現社會熱點事件時,相關新聞數據請求量急劇升高,此時需要保障APP正常運作,以及保持請求成功率穩定。
- 需要對時序數據建模的業務。例如:某氣象站需要每分鐘採集一次溫度,並存儲該次採集結果,同時需要保障數據的時效性,自動刪除過期數據。
- 需要對會話消息數據建模的業務。例如:某社交APP需要存儲大量的用戶及會話消息,需要保障用戶在不同會話消息間切換時耗時低、成功率高、響應時間短。
- 需要高速處理數據的業務。例如:某業務需要迅速處理來自不同設備或感測器的數據。
- 需要實時監測數據的業務。例如:某運維平臺需要實時監測不同維度的數據,準確採集指標,快速完成運維。
- 需要使用社交媒體分析和推薦引擎的業務。例如:某電商APP需要分析用戶喜好商品,基於用戶喜好實現商品推薦,提升用戶體驗和產品競爭力。
- ……
此外,華為雲GaussDB(for Cassandra)特性豐富,適用於廣泛業務場景。
- 大數據應用:GaussDB(for Cassandra)可以處理海量數據,支持高吞吐量和低延遲的讀寫操作,因此適合大數據應用場景。
- 互聯網應用:GaussDB(for Cassandra)可以處理高併發的讀寫請求,支持多數據中心部署,因此適合互聯網應用場景。
- 時間序列數據:GaussDB(for Cassandra)支持時間序列數據的存儲和查詢,因此適合需要存儲和查詢時間序列數據的應用場景,如物聯網、日誌分析等。
- 高可用性業務。GaussDB(for Cassandra)採用多副本複製的方式來保證數據的可用性和可靠性。當一個節點出現故障時,系統可以自動將數據從其他節點中恢復,從而保證數據的完整性和一致性。
- 可伸縮性業務。GaussDB(for Cassandra)可以輕鬆地擴展到數百個節點,處理PB級別的數據集,同時還支持動態添加和刪除節點,可以根據實際需求靈活地調整系統的規模和性能。
- 分散式存儲應用。GaussDB(for Cassandra)採用分散式存儲的方式,將數據分散存儲在多個節點上,每個節點都可以獨立地處理讀寫請求。這種方式可以有效地提高數據的可用性和可靠性,同時也可以提高系統的吞吐量和擴展性。
- 分散式查詢應用:GaussDB(for Cassandra)支持分散式查詢,可以將查詢請求分發到多個節點上並行處理,從而提高查詢的效率和響應速度。
- ……
綜上所述,GaussDB(for Cassandra)非常適合大數據分析、實時數據處理、社交網路、物聯網、分散式存儲和查詢等應用場景。
真實場景解讀——數據熱點問題
AOM功能強大,涉及多種典型業務場景,如數據熱點、時序數據、實時監測等,因此選擇GaussDB(for Cassandra)作為底層數據支撐引擎。接下來就數據熱點問題作為切入點,揭秘GaussDB(for Cassandra)如何保障AOM在發生數據熱點時穩定運行。
場景復現:
監控運維海量數據時,表中特定數據訪問頻率驟升,部分分區產生熱點流量。表中主鍵設置不合理,某個分區下的業務量驟增,流量衝擊會集中在一個分區上,導致該分區對應的token所在節點的CPU持續居高不下。
問題根因:
GaussDB(for Cassandra)是一個面向大數據場景的高度可擴展的高性能分散式資料庫,可用於管理海量的結構化數據。在業務使用的過程中,隨著業務量和數據流量的持續增長,一些業務的設計弊端逐漸暴露出來,降低了集群的穩定性和可用性。例如主鍵設計不合理、單個分區的記錄數或數據量過大、出現超大分區鍵等問題,導致了節點負載不均衡、集群穩定性下降等現象,這一類問題統稱為大key問題。產生大key的最主要原因是主鍵設計不合理,導致單個分區的記錄數或數據量過大。一旦某個分區存在海量數據時,對該分區的訪問會導致分區所在server的負載變高,嚴重時甚至會導致節點OOM等後果。
在日常生活中,經常會發生各種熱門事件,例如應用中對某熱點新聞進行上萬次的點擊瀏覽和評論時,會形成一個較大的請求量,這種情況下會在短時間內對同一個key頻繁操作,導致該key所在節點的CPU負載飆高,從而影響該節點上的其他請求,導致業務成功率下降。諸如此類的還有熱門商品促銷,網紅直播等場景,這些典型的讀多寫少的場景也會產生數據熱點問題。當某個key的請求在某一主機上的訪問超過server極限時,會導致熱key問題的產生。大key往往是熱key問題的間接原因。熱key會造成以下危害:流量集中,達到物理網卡上限;請求過多,緩存分片服務被擊垮;資料庫擊穿,引起業務雪崩等。
在上述場景中,主要是表中主鍵結構不合理,從而導致大key和熱key的產生,表結構如下所示。movie表保存了短視頻的相關信息,分區鍵為movieid,並且保存了用戶信息(uid)。如果movieid對應的視頻是一個熱門短視頻,有幾千萬甚至上億用戶點贊此短視頻,則該熱門短視頻所在的分區非常大。
CREATE TABLE movie ( movieid text, appid int, uid bigint, accessstring text, moviename text, access_time timestamp, PRIMARY KEY (movieid, appid, uid, accessstring, moviename) )
解決方案:
- 調整表結構。GaussDB(for Cassandra)與其他資料庫相比,具有更加靈活的數據結構,支持主鍵和分區鍵的靈活設置,通過合理設置主鍵和分區鍵,調整表結構與查詢語句,對錶中數據進行劃分,能夠有效優化查詢速度,提升運維效率。在上述場景中,movie表的主鍵設置不合理,查詢數據量十分龐大,耗時久。創建新表為如下所示表結構時,表中數據量顯著減少。新表用於保存熱門短視頻信息,只保留短視頻公共信息,不包含用戶信息,確保該表不會產生大的分區鍵。
CREATE TABLE hotmovieaccess ( movieid text, appid int, accessstring text, access time timestamp, PRIMARY KEY (movieid, appid) )
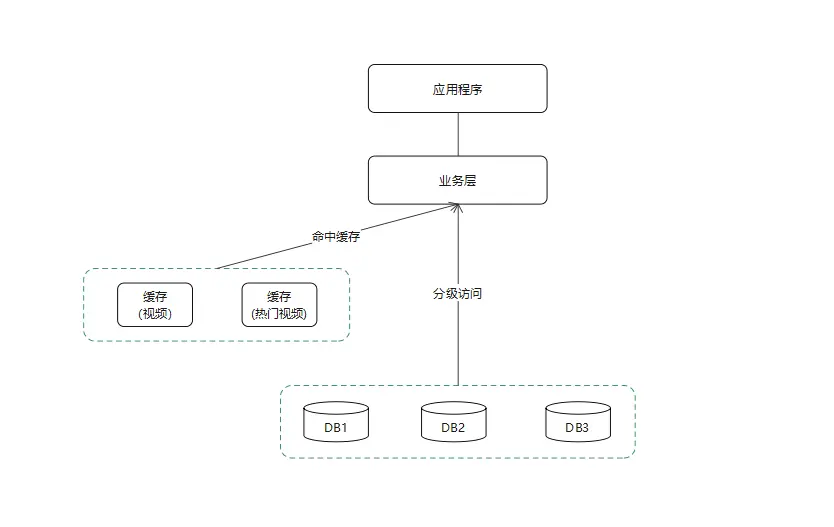
- 使用緩存。緩存可以提高讀操作的響應性,需要使用額外的記憶體來存儲數據,從而儘可能減少必須完成的磁碟讀。隨著緩存大小的增加,可以從記憶體提供服務的“命中”數也會增加。GaussDB(for Cassandra)內置的緩存包括鍵緩存和行緩存等類型。鍵緩存存儲了分區鍵與行索引之間的一個映射,以便於更快地訪問存儲在磁碟上的SSTable;行緩存可以為每個分區緩存一定的行,提高頻繁訪問的行的讀取速度。
在上述場景中,可以使用緩存來緩解流量衝擊。業務應用先從緩存中讀取熱點信息,沒有查詢到則從資料庫中查詢,減少資料庫查詢次數。整體邏輯流程如下所示。
數據熱點檢測工具:
數據熱點會給業務帶來壓力,影響業務正常運行。出現數據熱點後再去解決為時已晚,因此需要預知數據熱點問題,提前設計解決方法,保證業務正常運行。為此,GaussDB(for Cassandra)為業務提供了大key和熱key的檢測和預警工具。
- 大key檢測。通過大規模業務觀察學習,GaussDB(for Cassandra)定義超過以下任意閾值的key即為大key:1. 單個分區鍵的行數不能超過10萬行;2. 單個分區的大小不超過100MB。
- 熱key檢測。通過大規模業務觀察學習,GaussDB(for Cassandra)定義訪問頻率大於100000次/min的key即為熱key。
GaussDB(for Cassandra)支持大key和熱key的檢測和告警工具,客戶可根據實際業務需求,在產品界面配置實例的大key和熱key告警。同時,在發生大key和熱key事件時,系統會第一時間發送預警通知,客戶可在產品界面查看監控事件數據,及時處理相關告警,避免業務波動。
總結:
針對數據熱點問題,GaussDB(for Cassandra) 提供了大key和熱key的實時檢測,以幫助業務進行合理的方案設計,規避業務穩定性風險;提供了大key和熱key的實時監控,確保第一時間感知業務風險;提供了大key和熱key的解決方案,在面對大數據量洪峰場景時,增強了集群的穩定性與可用性,為客戶業務持續穩定運行保駕護航。
綜上所述,線上業務在使用GaussDB(for Cassandra)時,必須執行相關的開發規則和使用規範,在開發設計階段就降低使用風險。一般按照“制定規範”→“接入評審”→“定期巡檢”→“優化規則”的治理流程進行。合理的設計一般會降低大部分風險發生的概率,對於業務來說,任何表的設計都要考慮是否會導致大key和熱key的產生、是否會造成負載傾斜的問題。另外需要建立數據老化機制,表中的數據不能無限制的增長而不刪除或者老化。針對讀多寫少的場景,要增加緩存機制,來應對讀熱點問題,提升查詢性能;針對每個分區鍵以及每行數據,要控制其大小,超出限制後要及時優化,否則將影響性能和穩定性。
結論
AOM和GaussDB(for Cassandra)的組合成功打造了一套高效、可擴展、高性能、靈活和可定製的海量數據監控運維平臺,可以幫助企業更好地管理和利用監控數據,提高運維效率,助力企業在不斷變化的市場環境中保持競爭優勢。

