
# 一、什麼是ByteBuf 我們前面說過,網路數據的基本單位總是位元組。Java NIO 提供了 ByteBuffer 作為它的位元組容器,但是這個類使用起來過於複雜,而且也有些繁瑣。**ByteBuffer 替代品是 ByteBuf**,一個強大的實現,既解決了 JDK API 的局限性,又為網路應 ...
一、什麼是ByteBuf
我們前面說過,網路數據的基本單位總是位元組。Java NIO 提供了 ByteBuffer 作為它的位元組容器,但是這個類使用起來過於複雜,而且也有些繁瑣。ByteBuffer 替代品是 ByteBuf,一個強大的實現,既解決了 JDK API 的局限性,又為網路應用程式的開發者提供了更好的 API。
下麵我們將會說明和 JDK 的 ByteBuffer 相比,ByteBuf 的卓越功能性和靈活性
二、 ByteBuf 的 API
Netty 的數據處理 API 通過兩個組件暴露——abstract class ByteBuf 和 interface ByteBufHolder。
下麵是一些 ByteBuf API 的優點:
- 它可以被用戶自定義的緩衝區類型擴展;
- 通過內置的複合緩衝區類型實現了透明的零拷貝;
- 容量可以按需增長(類似於 JDK 的 StringBuilder);
- 在讀和寫這兩種模式之間切換不需要調用 ByteBuffer 的 flip()方法;
- 讀和寫使用了不同的索引;
- 支持方法的鏈式調用;
- 支持引用計數;
- 支持池化。
其他類可用於管理 ByteBuf 實例的分配,以及執行各種針對於數據容器本身和它所持有的數據的操作。
三、ByteBuf 類——Netty 的數據容器
因為所有的網路通信都涉及位元組序列的移動,所以高效易用的數據結構明顯是必不可少的。Netty 的 ByteBuf 實現滿足並超越了這些需求。
3.1 ByteBuf如何工作?
ByteBuf 維護了兩個不同的索引:一個用於讀取,一個用於寫入。
當你從 ByteBuf 讀取時,它的 readerIndex 將會被遞增已經被讀取的位元組數。
當你寫入 ByteBuf 時,它的writerIndex 也會被遞增。
ByteBuf 的佈局結構和狀態如下:

那麼這兩個索引之間有什麼關係?如果讀取位元組直到 readerIndex 達到和 writerIndex 同樣的值時會發生什麼?
在那時,我們將會到達“可以讀取的”數據的末尾。就如同試圖讀取超出數組末尾的數據一樣,試圖讀取超出該點的數據將會觸發IndexOutOfBoundsException。
名稱以 read 或者 write 開頭的 ByteBuf 方法,將會推進其對應的索引,而名稱以 set 或者 get 開頭的操作則不會。
後面的這些方法將在作為一個參數傳入的一個相對索引上執行操作。可以指定 ByteBuf 的最大容量。試圖移動寫索引(即 writerIndex)超過這個值將會觸發一個異常。(預設的限制是Integer.MAX_VALUE。)
PS:也就是說用戶直接或者間接使 capacity(int)或者 ensureWritable(int)方法來增加超過該最大容量時拋出異常。
3.2 ByteBuf 的使用模式
首先我們記住ByteBuf:一個由不同的索引分別控制讀訪問和寫訪問的位元組數組。
3.2.1 堆緩衝區
最常用的 ByteBuf 模式是將數據存儲在 JVM 的堆空間中。這種模式被稱為支撐數組(backing array),它能在沒有使用池化的情況下提供快速的分配和釋放。這種方式,非常適合於有遺留的數據需要處理的情況。
代碼展示:
ByteBuf heapBuf = ...;
//檢查ByteBuf是否有一個支撐數組
if (heapBuf.hasArray()) {
//如果有,則獲取對該數組的引用
byte[] array = heapBuf.array();
//計算第一個位元組的偏移量
int offset = heapBuf.arrayOffset() + heapBuf.readerIndex();
//獲取可讀位元組數
int length = heapBuf.readableBytes();
//使用數組、偏移量和長度作為參數調用你的方法
handleArray(array, offset, length);
}
PS:當 hasArray()方法返回 false 時,嘗試訪問支撐數組將觸發一個 UnsupportedOperationException。這個模式類似於 JDK 的 ByteBuffer 的用法。
3.2.2 直接緩衝區
直接緩衝區是另外一種 ByteBuf 模式。
我們都希望用於對象創建的記憶體分配永遠都來自於堆中。但這並不是必須的,因為ByteBuffer 類允許 JVM 實現通過本地調用來分配記憶體。
這主要是為了避免在每次調用本地 I/O 操作之前(或者之後)將緩衝區的內容複製到一個中間緩衝區(或者從中間緩衝區把內容複製到緩衝區)。
直接緩衝區的內容將駐留在常規的會被垃圾回收的堆之外(它的內容可能不會被堆回收)。如果你的數據包含在一個在堆上分配的緩衝區中,那麼在通過套接字發送它之前,JVM將會在內部把你的緩衝區複製到一個直接緩衝區中。
直接緩衝區的主要缺點是:
1、相對於基於堆的緩衝區,它們的分配和釋放都較為昂貴。
2、因為數據不是在堆上,所以你不得不進行一次複製,如代碼所示。
ByteBuf directBuf = ...;
//檢查 ByteBuf 是否由數組支撐。如果不是,則這是一個直接緩衝區
if (!directBuf.hasArray()) {
//獲取位元組可讀數
int length = directBuf.readableBytes();
//分配一個新的數組來保存具有該長度的位元組數據
byte[] array = new byte[length];
//將位元組複製到該數組
directBuf.getBytes(directBuf.readerIndex(), array);
//開始調用
handleArray(array, 0, length);
}
顯然,與使用支撐數組相比,這涉及的工作更多。因此,如果事先知道容器中的數據將會被作為數組來訪問,你可能更願意使用堆記憶體。
3.2.3 複合緩衝區
第三種也是最後一種模式使用的是複合緩衝區,它為多個 ByteBuf 提供一個聚合視圖。
在這裡你可以根據需要添加或者刪除 ByteBuf 實例,這是一個 JDK 的 ByteBuffer 實現完全缺失的特性。Netty 通過一個 ByteBuf 子類——CompositeByteBuf——實現了這個模式,它提供了一個將多個緩衝區表示為單個合併緩衝區的虛擬表示。
註意:CompositeByteBuf 中的 ByteBuf 實例可能同時包含直接記憶體分配和非直接記憶體分配。如果其中只有一個實例,那麼對 CompositeByteBuf 上的 hasArray()方法的調用將返回該組件上的 hasArray()方法的值;否則它將返回 false
舉個粒子:
假設我們有一條由頭部和主體兩部分組成並通過 HTTP 協議傳輸的消息。且這兩部分分別由應用程式的不同模塊產生,然後在消息被髮送的時候組裝。該應用程式可以選擇為多個消息重用相同的消息主體。當這種情況發生時,對於每個消息都將會創建一個新的頭部。
如果我們不想為每個消息都重新分配這兩個緩衝區,那麼使用 CompositeByteBuf 是一個完美的選擇。
如圖為持有一個頭部和主體的 CompositeByteBuf:

JDK 的 ByteBuffer針對我們這個需求實現代碼會像下麵這樣:
// 使用數組保存消息部分
ByteBuffer[] message = new ByteBuffer[] { header, body };
// 創建一個新的ByteBuffer,並使用copy合併頭和正文
ByteBuffer message2 =ByteBuffer.allocate(header.remaining() + body.remaining());
message2.put(header);
message2.put(body);
message2.flip();
使用 CompositeByteBuf 的複合緩衝區模式則是這樣:
CompositeByteBuf messageBuf = Unpooled.compositeBuffer();
ByteBuf headerBuf = ...; // 可以是堆緩衝或直接緩衝
ByteBuf bodyBuf = ...; // 可以是堆緩衝或直接緩衝
//將 ByteBuf 實例追加到 CompositeByteBuf
messageBuf.addComponents(headerBuf, bodyBuf);
.....
//刪除位於索引位置為 0(第一個組件)的 ByteBuf
messageBuf.removeComponent(0); // 移除頭部
//迴圈遍歷所有的 ByteBuf 實例
for (ByteBuf buf : messageBuf) {
System.out.println(buf.toString());
}
CompositeByteBuf 不支持訪問其支撐數組,因此訪問 CompositeByteBuf 中的數據類似於(訪問)直接緩衝區的模式,像下麵這樣:
CompositeByteBuf compBuf = Unpooled.compositeBuffer();
//獲得可讀位元組數
int length = compBuf.readableBytes();
//分配一個具有可讀位元組數長度的新數組
byte[] array = new byte[length];
//將數組讀到該數組中
compBuf.getBytes(compBuf.readerIndex(), array);
//調用使用
handleArray(array, 0, array.length);
Netty使用了CompositeByteBuf來優化套接字的I/O操作,儘可能地消除了由JDK的緩衝區實現所導致的性能以及記憶體使用率的懲罰。
這種優化發生在Netty的核心代碼中,因此不會被暴露出來,但是我們應該知道它所帶來的影響。
四、位元組級操作
ByteBuf 提供了許多超出基本讀、寫操作的方法用於修改它的數據。
4.1 隨機訪問索引
如同在普通的 Java 位元組數組中一樣,ByteBuf 的索引是從零開始的:第一個位元組的索引是0,最後一個位元組的索引總是 capacity() - 1。對存儲機制的封裝使得遍歷 ByteBuf 的內容非常簡單。
像這樣的:
ByteBuf buffer = ...;
for (int i = 0; i < buffer.capacity(); i++) {
byte b = buffer.getByte(i);
System.out.println((char)b);
}
需要註意的是,使用那些需要一個索引值參數的方法(的其中)之一來訪問數據既不會改變readerIndex 也不會改變 writerIndex。如果有需要,也可以通過調用 readerIndex(index)或者 writerIndex(index)來手動移動這兩者。
4.2 順序訪問索引
雖然 ByteBuf 同時具有讀索引和寫索引,但是 JDK 的 ByteBuffer 卻只有一個索引,這也就是為什麼必須調用 flip()方法來在讀模式和寫模式之間進行切換的原因。
以下展示了ByteBuf 是如何被它的兩個索引劃分成 3 個區域的:
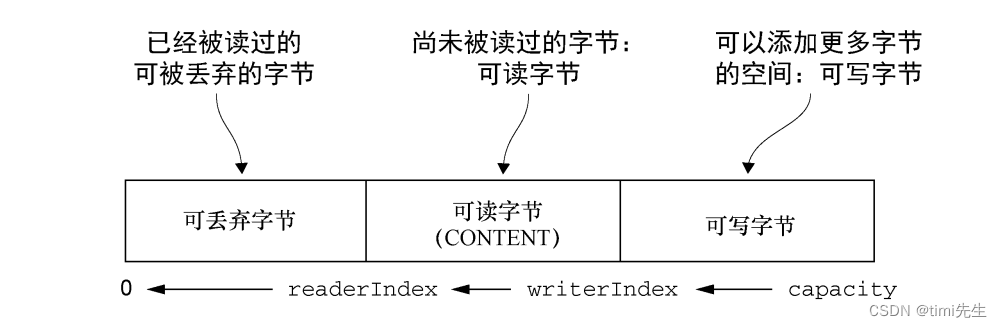
4.3 可丟棄位元組
可丟棄位元組的分段包含了已經被讀過的位元組。通過調用 discardReadBytes()方法,可以丟棄它們並回收空間。這個分段的初始大小為 0,存儲在 readerIndex 中,會隨著 read 操作的執行而增加(get*操作不會移動 readerIndex)。
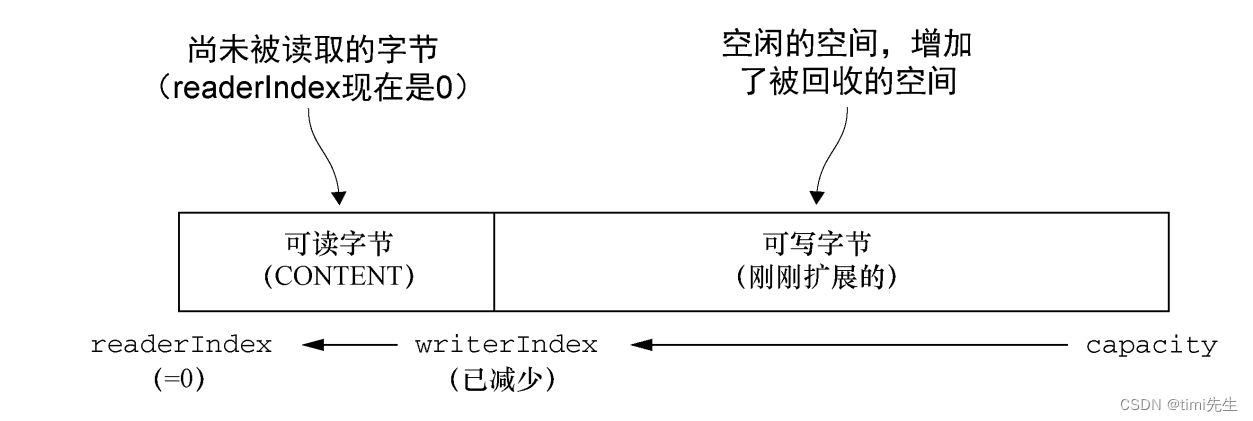
像圖中所展示的緩衝區上調用discardReadBytes()方法後的結果。可以看到,可丟棄位元組分段中的空間已經變為可寫的了。註意,在調用discardReadBytes()之後,對可寫分段的內容並沒有任何的保證 (因為只是移動了可以讀取的位元組以及 writerIndex,而沒有對所有可寫入的位元組進行擦除寫)。
有的同學可能會傾向於頻繁地調用 discardReadBytes()方法以確保可寫分段的最大化,但是請註意,這將極有可能會導致記憶體複製,因為可讀位元組(圖中標記為 CONTENT 的部分)必須被移動到緩衝區的開始位置。建議只在有真正需要的時候才這樣做,例如,當記憶體非常寶貴的時候。
4.4 可讀位元組
ByteBuf 的可讀位元組分段存儲了實際數據。新分配的、包裝的或者複製的緩衝區的預設的readerIndex 值為 0。任何名稱以 read 或者 skip 開頭的操作都將檢索或者跳過位於當前readerIndex 的數據,並且將它增加已讀位元組數。
如果被調用的方法需要一個 ByteBuf 參數作為寫入的目標,並且沒有指定目標索引參數,那麼該目標緩衝區的 writerIndex 也將被增加。例如:
readBytes(ByteBuf dest);
如果嘗試在緩衝區的可讀位元組數已經耗盡時從中讀取數據,那麼將會引發一個 IndexOutOfBoundsException。
下麵是一個讀取所有數據的代碼示例:
ByteBuf buffer = ...;
while (buffer.isReadable()) {
System.out.println(buffer.readByte());
}
4.5 可寫位元組
可寫位元組分段是指一個擁有未定義內容的、寫入就緒的記憶體區域。新分配的緩衝區的writerIndex 的預設值為 0。任何名稱以 write 開頭的操作都將從當前的 writerIndex 處開始寫數據,並將它增加已經寫入的位元組數。
如果寫操作的目標也是 ByteBuf,並且沒有指定源索引的值,則源緩衝區的 readerIndex 也同樣會被增加相同的大小。這個調用如下所示:
writeBytes(ByteBuf dest);
如果嘗試往目標寫入超過目標容量的數據,將會引發一個IndexOutOfBoundException(PS:在往 ByteBuf 中寫入數據時,其將首先確保目標 ByteBuf 具有足夠的可寫入空間來容納當前要寫入的數據,如果沒有,則將檢查當前的寫索引以及最大容量是否可以在擴展後容納該數據,可以則會分配並調整容量,否則就會拋出該異常。)
下麵代碼是一個用隨機整數值填充緩衝區,直到它空間不足為止的例子。writeableBytes()方法在這裡被用來確定該緩衝區中是否還有足夠的空間。
// 用隨機整數填充緩衝區的可寫位元組。
ByteBuf buffer = ...;
while (buffer.writableBytes() >= 4) {
buffer.writeInt(random.nextInt());
}
4.6 索引管理
JDK 的 InputStream 定義了 mark(int readlimit)和 reset()方法,這些方法分別被用來將流中的當前位置標記為指定的值,以及將流重置到該位置。(說白了就是給指定位置寫值,比如有四個位置可以指定第一個位置寫 “作”,第二個位置寫“者”,第三個位置寫“很”,第四個位置寫“帥”)。
也可以通過調用 readerIndex(int)或者 writerIndex(int)來將索引移動到指定位置。試圖將任何一個索引設置到一個無效的位置都將導致一個 IndexOutOfBoundsException。
可以通過調用 clear()方法來將 readerIndex 和 writerIndex 都設置為 0。註意,這並不會清除記憶體中的內容。
clear()未被調用:

clear()調用之後:
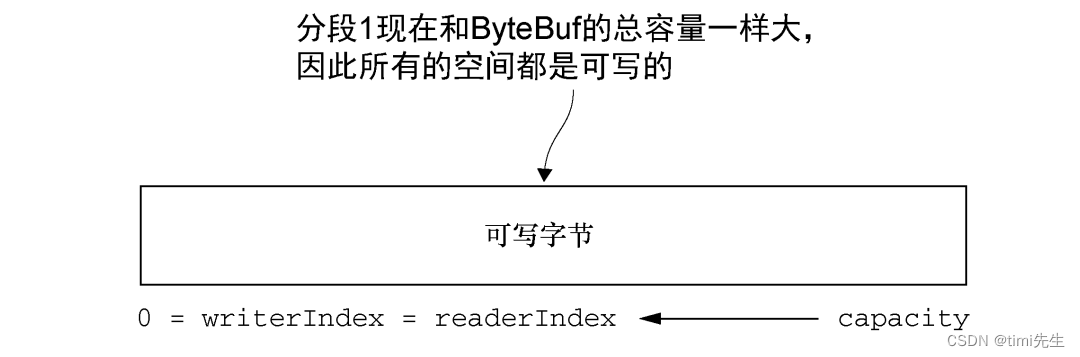
調用 clear()比調用 discardReadBytes()輕量得多,因為它將只是重置索引而不會複製任何的記憶體。
4.7 查找操作
在ByteBuf中有多種可以用來確定指定值的索引的方法。最簡單的是使用indexOf()方法。
較複雜的查找可以通過那些需要一個io.netty.util.ByteProcessor,這個介面只定義了一個方法:
boolean process(byte value)
ByteProcessor針對一些常見的值定義了許多便利的方法。假設你的應用程式需要和所謂的包含有以NULL結尾的內容的Flash套接字作為參數的方法達成。可以調用它將檢查輸入值是否是正在查找的值。
forEachByte(ByteBufProcessor.FIND_NUL)
展示一個查找回車符(\r)的例子:
ByteBuf buffer = ...;
int index = buffer.forEachByte(ByteBufProcessor.FIND_CR);
4.8 派生緩衝區
派生緩衝區為 ByteBuf 提供了以專門的方式來呈現其內容的視圖。這類視圖是通過以下方法被創建的:
- duplicate();
- slice();
- slice(int, int);
- Unpooled.unmodifiableBuffer(…);
- order(ByteOrder);
- readSlice(int)。
每個這些方法都將返回一個新的 ByteBuf 實例,它具有自己的讀索引、寫索引和標記索引。其內部存儲和 JDK 的 ByteBuffer 一樣也是共用的。這使得派生緩衝區的創建成本是很低廉的,但是這也意味著,如果你修改了它的內容,也同時修改了其對應的源實例,所以要小心。
ByteBuf 複製:
如果需要一個現有緩衝區的真實副本,請使用 copy()或者 copy(int, int)方法。不同於派生緩衝區,由這個調用所返回的 ByteBuf 擁有獨立的數據副本。
看段代碼:
1、使用 slice(int, int)方法來操作 ByteBuf 的一個分段
Charset utf8 = Charset.forName("UTF-8");
//創建一個用於保存給定字元串的位元組的 ByteBuf
ByteBuf buf = Unpooled.copiedBuffer("Netty in Action rocks!", utf8);
//創建該 ByteBuf 從索引 0 開始到索引 15結束的一個新切片
ByteBuf sliced = buf.slice(0, 15);
//將列印“Netty in Action”
System.out.println(sliced.toString(utf8));
//更新索引 0 處的位元組
buf.setByte(0, (byte)'J');
//將會成功,因為數據是共用的,對其中一個所做的更改對另外一個也是可見的
assert buf.getByte(0) == sliced.getByte(0);
2、利用副本切片來操作 ByteBuf 的一個分段
Charset utf8 = Charset.forName("UTF-8");
//創建 ByteBuf 以保存所提供的字元串的位元組
ByteBuf buf = Unpooled.copiedBuffer("Netty in Action rocks!", utf8);
//創建該 ByteBuf 從索引 0 開始到索引 15結束的分段的副本
ByteBuf copy = buf.copy(0, 15);
//將列印“Netty in Action”
System.out.println(copy.toString(utf8));
////更新索引 0 處的位元組
buf.setByte(0, (byte) 'J');
//將會失敗,因為數據不是共用的
assert buf.getByte(0) != copy.getByte(0);
4.9 讀/寫操作
正如我們所提到過的,有兩種類別的讀/寫操作:
- get()和 set()操作,從給定的索引開始,並且保持索引不變;
- read()和 write()操作,從給定的索引開始,並且會根據已經訪問過的位元組數對索引進行調整。
下麵是部分常用的get()方法:
| 名 稱 | 描 述 |
|---|---|
| getBoolean(int) | 返回給定索引處的 Boolean 值 |
| getByte(int) | 返回給定索引處的位元組 |
| getUnsignedByte(int) | 將給定索引處的無符號位元組值作為 short 返回 |
| getMedium(int) | 返回給定索引處的 24 位的中等 int 值 |
| getUnsignedMedium(int) | 返回給定索引處的無符號的 24 位的中等 int 值 |
| getInt(int) | 返回給定索引處的 int 值 |
| getUnsignedInt(int) | 將給定索引處的無符號 int 值作為 long 返回 |
| getLong(int) | 返回給定索引處的 long 值 |
| getShort(int) | 返回給定索引處的 short 值 |
| getUnsignedShort(int) | 將給定索引處的無符號 short 值作為 int 返回 |
| getBytes(int, ...) | 將該緩衝區中從給定索引開始的數據傳送到指定的目的地 |
下麵是部分常用的set()方法:
| 名 稱 | 描 述 |
|---|---|
| setBoolean(int, boolean) | 設定給定索引處的 Boolean 值 |
| setByte(int index, int value) | 設定給定索引處的位元組值 |
| setMedium(int index, int value) | 設定給定索引處的 24 位的中等 int 值 |
| setInt(int index, int value) | 設定給定索引處的 int 值 |
| setLong(int index, long value) | 設定給定索引處的 long 值 |
| setShort(int index, int value) | 設定給定索引處的 short 值 |
get()和 set()方法的用法大家可以參照下麵的例子:
Charset utf8 = Charset.forName("UTF-8");
//創建一個新的 ByteBuf以保存給定字元串的位元組
ByteBuf buf = Unpooled.copiedBuffer("Netty in Action rocks!", utf8);
//列印第一個字元'N'
System.out.println((char)buf.getByte(0));
//存儲當前的 readerIndex和 writerIndex
int readerIndex = buf.readerIndex();
int writerIndex = buf.writerIndex();
//將索引 0 處的位元組更新為字元'B'
buf.setByte(0, (byte)'B');
////列印第一個字元'B'
System.out.println((char)buf.getByte(0));
//將會成功,因為這些操作並不會修改相應的索引
assert readerIndex == buf.readerIndex();
assert writerIndex == buf.writerIndex();
然後我們看一下read()操作,其作用於當前的 readerIndex 或 writerIndex。這些方法將用於從 ByteBuf 中讀取數據,如同它是一個流。
常用的read()方法:
| 名 稱 | 描 述 |
|---|---|
| readBoolean() | 返回當前 readerIndex 處的 Boolean,並將 readerIndex 增加 1 |
| readByte() | 返回當前 readerIndex 處的位元組,並將 readerIndex 增加 1 |
| readUnsignedByte() | 將當前 readerIndex 處的無符號位元組值作為 short 返回,並將readerIndex 增加 1 |
| readMedium() | 返回當前 readerIndex 處的 24 位的中等 int 值,並將 readerIndex增加 3 |
| readUnsignedMedium() 返回當前 readerIndex 處的 24 位的無符號的中等 int 值,並將readerIndex 增加 3 | |
| readInt() | 返回當前 readerIndex 的 int 值,並將 readerIndex 增加 4 |
| readUnsignedInt() | 將當前 readerIndex 處的無符號的 int 值作為 long 值返回,並將readerIndex 增加 4 |
| readLong() | 返回當前 readerIndex 處的 long 值,並將 readerIndex 增加 8 |
| readShort() | 返回當前 readerIndex 處的 short 值,並將 readerIndex 增加 2 |
| readUnsignedShort() | 將當前 readerIndex 處的無符號 short 值作為 int 值返回,並將readerIndex 增加 2 |
| readBytes(ByteBuf byte[] destination,int dstIndex [,intlength]) | 將當前 ByteBuf 中從當前 readerIndex 處開始的(如果設置了,length 長度的位元組)數據傳送到一個目標 ByteBuf 或者 byte[],從目標的 dstIndex 開始的位置。本地的 readerIndex 將被增加已經傳輸的位元組數 |
常見的writer()方法(PS:幾乎每個 read()方法都有對應的 write()方法,用於將數據追加到 ByteBuf 中。註意:下列所列出的這些方法的參數是需要寫入的值,而不是索引值。)
| 名 稱 | 描 述 |
|---|---|
| writeBoolean(boolean) | 在當前 writerIndex 處寫入一個 Boolean,並將 writerIndex 增加 1 |
| writeByte(int) | 在當前 writerIndex 處寫入一個位元組值,並將 writerIndex 增加 1 |
| writeMedium(int) | 在當前 writerIndex 處寫入一個中等的 int 值,並將 writerIndex增加 3 |
| writeInt(int) | 在當前 writerIndex 處寫入一個 int 值,並將 writerIndex 增加 4 |
| writeLong(long) | 在當前 writerIndex 處寫入一個 long 值,並將 writerIndex 增加 8 |
| writeShort(int) | 在當前 writerIndex 處寫入一個 short 值,並將 writerIndex 增加 2 |
| writeBytes(sourceByteBuf byte[][,int srcIndex,int length]) | 從當前 writerIndex 開始,傳輸來自於指定源(ByteBuf 或者 byte[])的數據。如果提供了 srcIndex 和 length,則從 srcIndex 開始讀取,並且處理長度為 length 的位元組。當前 writerIndex 將會被增加所寫入的位元組數 |
ByteBuf 上的 read()和 write()操作大家可以參照下列的代碼:
Charset utf8 = Charset.forName("UTF-8");
//創建一個新的ByteBuf 以保存給定字元串的位元組
ByteBuf buf = Unpooled.copiedBuffer("Netty in Action rocks!", utf8);
//列印第一個字元'N'
System.out.println((char)buf.readByte());
//存儲當前的存儲當前的 readerIndex
int readerIndex = buf.readerIndex();
////存儲當前的存儲當前的 writerIndex
int writerIndex = buf.writerIndex();
//將字元'?'追加到緩衝區
buf.writeByte((byte)'?');
assert readerIndex == buf.readerIndex();
//將會成功,因為 writeByte()方法移動了 writerIndex
assert writerIndex != buf.writerIndex();
4.10 更多的操作
ByteBuf 還為我們提供了其他有用操作:
| 名 稱 | 描 述 |
|---|---|
| readableBytes() | 返回可被讀取的位元組數 |
| writableBytes() | 返回可被寫入的位元組數 |
| capacity() | 返回 ByteBuf 可容納的位元組數。在此之後,它會嘗試再次擴展直到達到 maxCapacity() |
| maxCapacity() | 返回 ByteBuf 可以容納的最大位元組數 |
| hasArray() | 如果 ByteBuf 由一個位元組數組支撐,則返回 true |
| array() | 如果 ByteBuf 由一個位元組數組支撐則返回該數組;否則,它將拋出一個UnsupportedOperationException 異常 |
五、ByteBufHolder 介面
為了處理我們除了數據負載之外,還需要存儲各種屬性值的需求,Netty 提供了 ByteBufHolder。
ByteBufHolder 也為 Netty 的高級特性提供了支持,如緩衝區池化,其中可以從池中借用 ByteBuf,並且在需要時自動釋放。ByteBufHolder 只有幾種用於訪問底層數據和引用計數的方法。
ByteBufHolder 的常見操作如下:
| 名 稱 | 描 述 |
|---|---|
| content() | 返回由這個 ByteBufHolder 所持有的 ByteBuf |
| copy() | 返回這個 ByteBufHolder 的一個深拷貝,包括一個其所包含的 ByteBuf 的非共用拷貝 |
| duplicate() | 返回這個 ByteBufHolder 的一個淺拷貝,包括一個其所包含的 ByteBuf 的共用拷貝 |
如果想要實現一個將其有效負載存儲在 ByteBuf 中的消息對象,那麼 ByteBufHolder 將是個不錯的選擇。
六、ByteBuf 分配
6.1 按需分配:ByteBufAllocator 介面
為了降低分配和釋放記憶體的開銷,Netty 通過 interface ByteBufAllocator 實現了(ByteBuf 的)池化,它可以用來分配我們所描述過的任意類型的 ByteBuf 實例。
使用池化是特定於應用程式的決定,其並不會以任何方式改變 ByteBuf API。
下麵列出了 ByteBufAllocator 常見的一些操作:
| 名 稱 | 描 述 |
|---|---|
| buffer()、buffer(int initialCapacity)、buffer(int initialCapacity, int maxCapacity) | 返回一個基於堆或者直接記憶體存儲的 ByteBuf |
| heapBuffer()、heapBuffer(int initialCapacity)、heapBuffer(int initialCapacity, int maxCapacity) | 返回一個基於堆記憶體存儲的ByteBuf |
| directBuffer()、directBuffer(int initialCapacity)、directBuffer(int initialCapacity, int maxCapacity) | 返回一個基於直接記憶體存儲的ByteBuf |
| compositeBuffer()、compositeBuffer(int maxNumComponents)、compositeDirectBuffer()、compositeDirectBuffer(int maxNumComponents)、compositeHeapBuffer()、compositeHeapBuffer(int maxNumComponents) | 返回一個可以通過添加最大到指定數目的基於堆的或者直接記憶體存儲的緩衝區來擴展的CompositeByteBuf |
| ioBuffer() | 返回一個用於套接字的 I/O 操作的 ByteBuf |
可以通過 Channel(每個都可以有一個不同的 ByteBufAllocator 實例)或者綁定到ChannelHandler 的 ChannelHandlerContext 獲取一個到 ByteBufAllocator 的引用。
大家可以參考下麵的代碼:
Channel channel = ...;
//從 Channel 獲取一個到ByteBufAllocator 的引用
ByteBufAllocator allocator = channel.alloc();
....
ChannelHandlerContext ctx = ...;
//從 ChannelHandlerContext 獲取一個到 ByteBufAllocator 的引用
ByteBufAllocator allocator2 = ctx.alloc();
...
Netty提供了兩種ByteBufAllocator的實現:PooledByteBufAllocator和UnpooledByteBufAllocator。
前者池化了ByteBuf的實例以提高性能並最大限度地減少記憶體碎片。
後者的實現不池化ByteBuf實例,並且在每次它被調用時都會返回一個新的實例。
雖然Netty預設使用了PooledByteBufAllocator,但這可以很容易地通過ChannelConfig API或者在引導你的應用程式時指定一個不同的分配器來更改。
6.2 Unpooled 緩衝區
可能某些情況下,未能獲取一個到 ByteBufAllocator 的引用。對於這種情況,Netty 提供了一個簡單的稱為 Unpooled 的工具類,它提供了靜態的輔助方法來創建未池化的 ByteBuf實例。
下麵是寫常用的Unpooled方法:
| 名 稱 | 描 述 |
|---|---|
| buffer()、buffer(int initialCapacity)、buffer(int initialCapacity, int maxCapacity) | 返回一個未池化的基於堆記憶體存儲的ByteBuf |
| directBuffer()、directBuffer(int initialCapacity)、directBuffer(int initialCapacity, int maxCapacity) | 返回一個未池化的基於直接記憶體存儲的 ByteBuf |
| wrappedBuffer() | 返回一個包裝了給定數據的 ByteBuf |
| copiedBuffer() | 返回一個複製了給定數據的 ByteBuf |
Unpooled 類還使得 ByteBuf 同樣可用於那些並不需要 Netty 的其他組件的非網路項目,使得其能得益於高性能的可擴展的緩衝區 API。
6.3 ByteBufUtil 類
ByteBufUtil 提供了用於操作 ByteBuf 的靜態的輔助方法。因為這個 API 是通用的,並且和池化無關,所以這些方法已然在分配類的外部實現。
這些靜態方法中最有價值方法:
- hexdump()方法:它以十六進位的表示形式列印ByteBuf 的內容。這在各種情況下都很有用,例如,出於調試的目的記錄 ByteBuf 的內容。十六進位的表示通常會提供一個比位元組值的直接表示形式更加有用的日誌條目,此外,十六進位的版本還可以很容易地轉換回實際的位元組表示。
- boolean equals(ByteBuf, ByteBuf):它被用來判斷兩個 ByteBuf實例的相等性。如果你實現自己的 ByteBuf 子類,你可能會發現 ByteBufUtil 的其他有用方法。
七、引用計數
引用計數是一種通過在某個對象所持有的資源不再被其他對象引用時釋放該對象所持有的資源來優化記憶體使用和性能的技術。
引用計數背後的想法並不是特別的複雜;它主要涉及跟蹤到某個特定對象的活動引用的數量。一個 ReferenceCounted 實現的實例將通常以活動的引用計數為 1 作為開始。只要引用計數大於 0,就能保證對象不會被釋放。當活動引用的數量減少到 0 時,該實例就會被釋放。
PS,雖然釋放的確切語義可能是特定於實現的,但是至少已經釋放的對象應該不可再用了。
引用計數對於池化實現(如 PooledByteBufAllocator)來說是至關重要的,它降低了記憶體分配的開銷。
引用計數演示代碼:
Channel channel = ...;
//從 Channel 獲取ByteBufAllocator
ByteBufAllocator allocator = channel.alloc();
....
//從 ByteBufAllocator分配一個 ByteBuf
ByteBuf buffer = allocator.directBuffer();
//檢查引用計數是否為預期的 1
assert buffer.refCnt() == 1;
...
釋放引用計數:
ByteBuf buffer = ...;
//減少到該對象的活動引用。當減少到 0 時,該對象被釋放,並且該方法返回 true
boolean released = buffer.release();
..
試圖訪問一個已經被釋放的引用計數的對象,將會導致一個 IllegalReferenceCountException。註意,一個特定的(ReferenceCounted 的實現)類,可以用它自己的獨特方式來定義它的引用計數規則。例如,我們可以設想一個類,其 release()方法的實現總是將引用計數設為
零,而不用關心它的當前值,從而一次性地使所有的活動引用都失效

