
在上篇文章 [《深入理解 slab cache 記憶體分配全鏈路實現》](https://mp.weixin.qq.com/s?__biz=Mzg2MzU3Mjc3Ng==&mid=2247488152&idx=1&sn=7c65f8ee28e9cc14a86e9df92b6d2b93&chksm=c ...
在上篇文章 《深入理解 slab cache 記憶體分配全鏈路實現》 中,筆者詳細地為大家介紹了 slab cache 進行記憶體分配的整個鏈路實現,本文我們就來到了 slab cache 最後的一部分內容了,當申請的記憶體使用完畢之後,下麵就該釋放記憶體了。
在接下來的內容中,筆者為大家介紹一下內核是如何將記憶體塊釋放回 slab cache 的。我們還是先從 slab cache 釋放記憶體的內核 API 開始聊起~~~
內核提供了 kmem_cache_free 函數,用於將對象釋放回其所屬的 slab cache 中,參數 x 表示我們要釋放的記憶體塊(對象)的虛擬記憶體地址,參數 s 指向記憶體塊所屬的 slab cache。
void kmem_cache_free(struct kmem_cache *s, void *x)
{
// 確保指定的是 slab cache : s 為對象真正所屬的 slab cache
s = cache_from_obj(s, x);
if (!s)
return;
// 將對象釋放會 slab cache 中
slab_free(s, virt_to_head_page(x), x, NULL, 1, _RET_IP_);
}
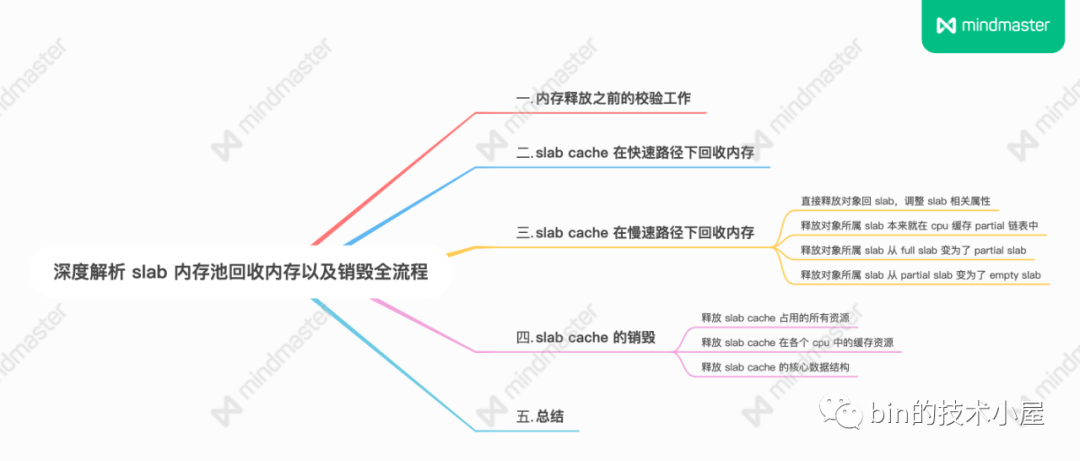
1. 記憶體釋放之前的校驗工作
在開始釋放記憶體塊 x 之前,內核需要首先通過 cache_from_obj 函數確認記憶體塊 x 是否真正屬於我們指定的 slab cache。不能將記憶體塊釋放到其他的 slab cache 中。
隨後在 virt_to_head_page 函數中通過記憶體塊的虛擬記憶體地址 x 找到其所在的物理記憶體頁 page。然後調用 slab_free 將記憶體塊釋放回 slab cache 中。
通過虛擬記憶體地址尋找物理記憶體頁 page 的過程涉及到的背景知識比較複雜,這個筆者後面會單獨拎出來介紹,這裡大家只需要簡單瞭解 virt_to_head_page 函數的作用即可。
static inline struct kmem_cache *cache_from_obj(struct kmem_cache *s, void *x)
{
struct kmem_cache *cachep;
// 通過對象的虛擬記憶體地址 x 找到對象所屬的 slab cache
cachep = virt_to_cache(x);
// 校驗指定的 slab cache : s 是否是對象真正所屬的 slab cache : cachep
WARN_ONCE(cachep && !slab_equal_or_root(cachep, s),
"%s: Wrong slab cache. %s but object is from %s\n",
__func__, s->name, cachep->name);
return cachep;
}
virt_to_cache 函數首先會通過釋放對象的虛擬記憶體地址找到其所在的物理記憶體頁 page,然後通過 struct page 結構中的 slab_cache 指針找到 page 所屬的 slab cache。

static inline struct kmem_cache *virt_to_cache(const void *obj)
{
struct page *page;
// 根據對象的虛擬記憶體地址 *obj 找到其所在的記憶體頁 page
// 如果 slub 背後是多個記憶體頁(複合頁),則返回覆合頁的首頁 head page
page = virt_to_head_page(obj);
if (WARN_ONCE(!PageSlab(page), "%s: Object is not a Slab page!\n",
__func__))
return NULL;
// 通過 page 結構中的 slab_cache 屬性找到其所屬的 slub
return page->slab_cache;
}
2. slab cache 在快速路徑下回收記憶體
static __always_inline void slab_free(struct kmem_cache *s, struct page *page,
void *head, void *tail, int cnt,
unsigned long addr)
{
if (slab_free_freelist_hook(s, &head, &tail))
do_slab_free(s, page, head, tail, cnt, addr);
}
slab cache 回收記憶體相關的邏輯封裝在 do_slab_free 函數中:
static __always_inline void do_slab_free(struct kmem_cache *s,
struct page *page, void *head, void *tail,
int cnt, unsigned long addr)
- 參數 kmem_cache *s 表示釋放對象所在的 slab cache,指定我們要將對象釋放到哪裡。
- 參數 page 表示釋放對象所在的 slab,slab 在內核中使用 struct page 結構來表示。
- 參數 head 指向釋放對象的虛擬記憶體地址(起始記憶體地址)。
- 該函數支持向 slab cache 批量的釋放多個對象,參數 tail 指向批量釋放對象中最後一個對象的虛擬記憶體地址。
- 參數 cnt 表示釋放對象的個數,也是用於批量釋放對象
- 參數 addr 用於 slab 調試,這裡我們不需要關心。
slab cache 針對記憶體的回收流程其實和我們在上篇文章 《深入理解 slab cache 記憶體分配全鏈路實現》 中介紹的 slab cache 記憶體分配流程是相似的。
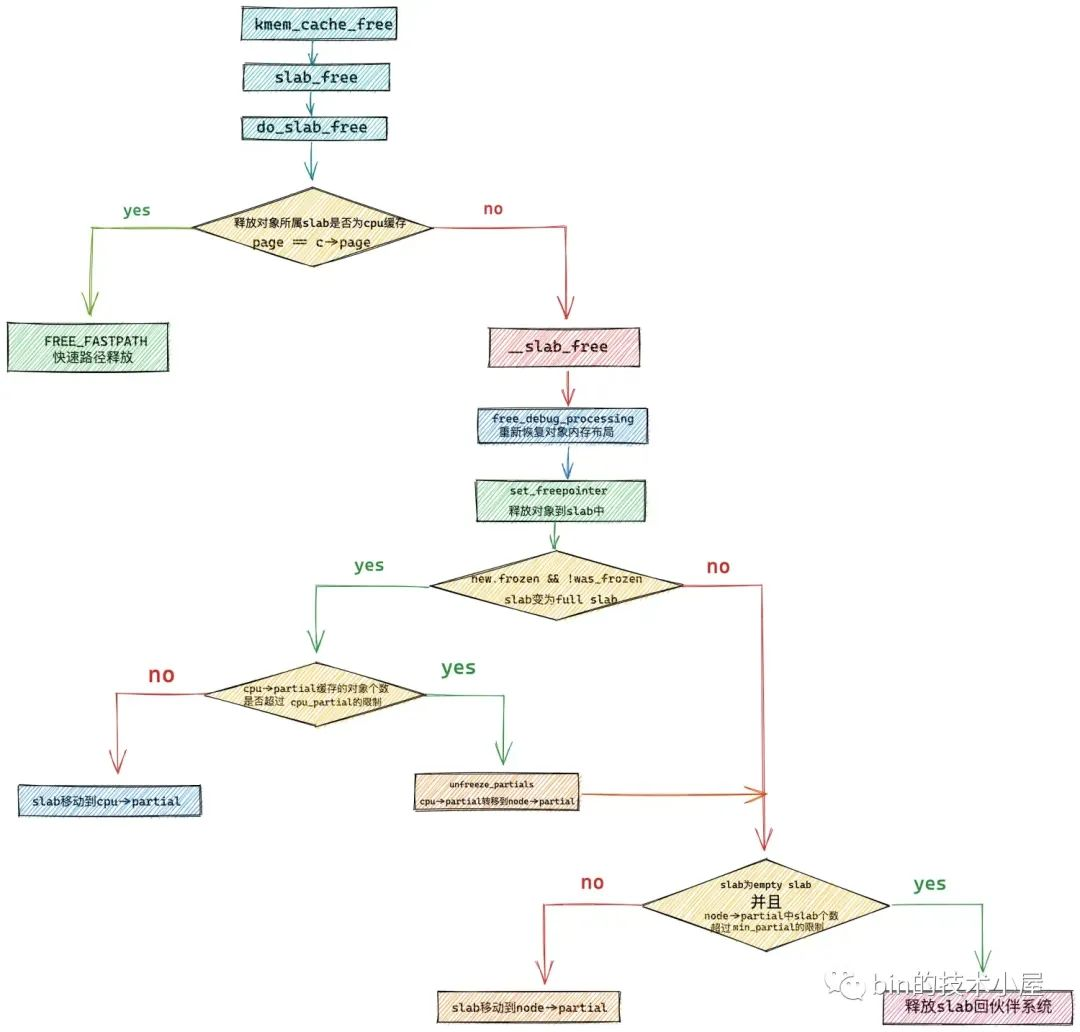
記憶體回收總體也是分為快速路徑 fastpath 和慢速路徑 slow path,在 do_slab_free 函數中內核會首先嘗試 fastpath 的回收流程。
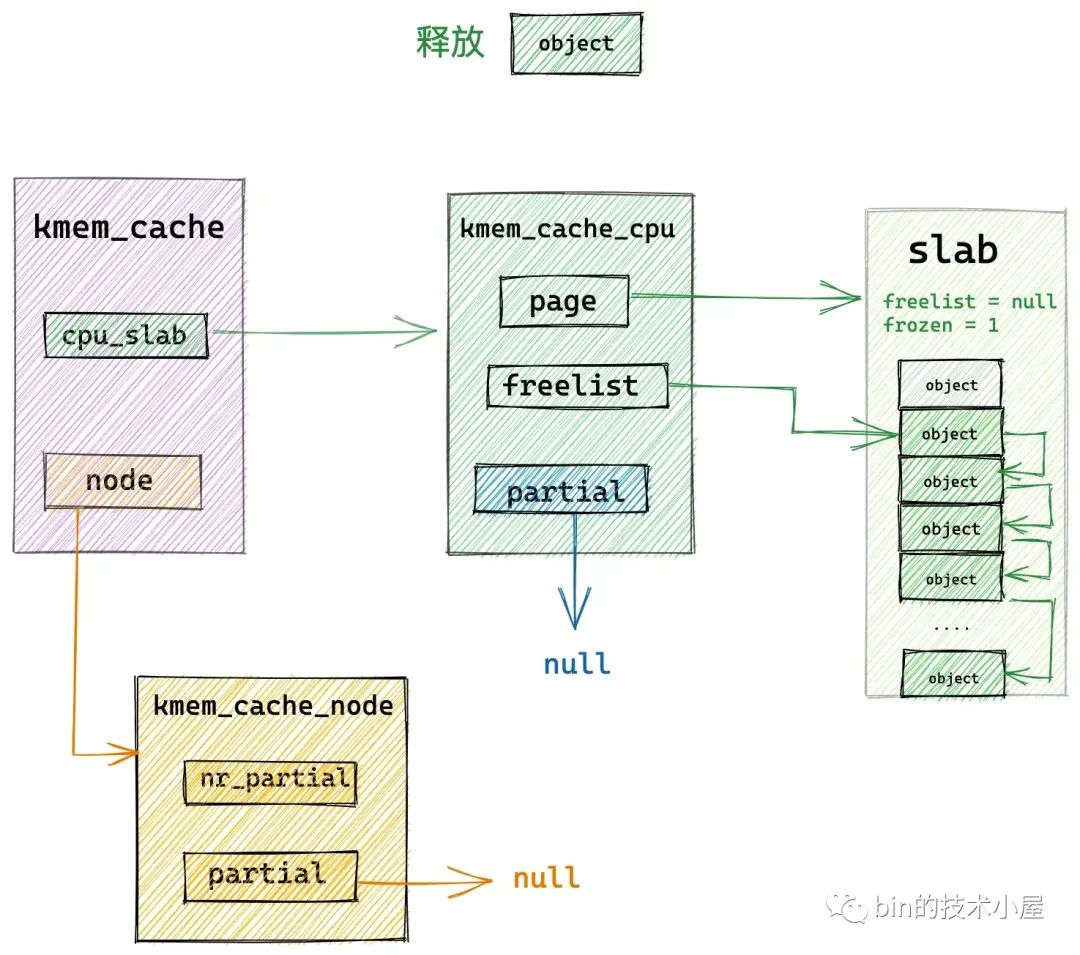
如果釋放對象所在的 slab 剛好是 slab cache 在本地 cpu 緩存 kmem_cache_cpu->page 緩存的 slab,那麼內核就會直接將對象釋放回緩存 slab 中。
static __always_inline void do_slab_free(struct kmem_cache *s,
struct page *page, void *head, void *tail,
int cnt, unsigned long addr)
{
void *tail_obj = tail ? : head;
struct kmem_cache_cpu *c;
// slub 中對象分配與釋放流程的全局事務 id
// 既可以用來標識同一個分配或者釋放的事務流程,也可以用來標識區分所屬 cpu 本地緩存
unsigned long tid;
redo:
// 接下來我們需要獲取 slab cache 的 cpu 本地緩存
// 這裡的 do..while 迴圈是要保證獲取到的 cpu 本地緩存 c 是屬於執行進程的當前 cpu
// 因為進程可能由於搶占或者中斷的原因被調度到其他 cpu 上執行,所需需要確保兩者的 tid 是否一致
do {
// 獲取執行當前進程的 cpu 中的 tid 欄位
tid = this_cpu_read(s->cpu_slab->tid);
// 獲取 cpu 本地緩存 cpu_slab
c = raw_cpu_ptr(s->cpu_slab);
// 如果兩者的 tid 欄位不一致,說明進程已經被調度到其他 cpu 上了
// 需要再次獲取正確的 cpu 本地緩存
} while (IS_ENABLED(CONFIG_PREEMPT) &&
unlikely(tid != READ_ONCE(c->tid)));
// 如果釋放對象所屬的 slub (page 表示)正好是 cpu 本地緩存的 slub
// 那麼直接將對象釋放到 cpu 緩存的 slub 中即可,這裡就是快速釋放路徑 fastpath
if (likely(page == c->page)) {
// 將對象釋放至 cpu 本地緩存 freelist 中的頭結點處
// 釋放對象中的 freepointer 指向原來的 c->freelist
set_freepointer(s, tail_obj, c->freelist);
// cas 更新 cpu 本地緩存 s->cpu_slab 中的 freelist,以及 tid
if (unlikely(!this_cpu_cmpxchg_double(
s->cpu_slab->freelist, s->cpu_slab->tid,
c->freelist, tid,
head, next_tid(tid)))) {
note_cmpxchg_failure("slab_free", s, tid);
goto redo;
}
stat(s, FREE_FASTPATH);
} else
// 如果當前釋放對象並不在 cpu 本地緩存中,那麼就進入慢速釋放路徑 slowpath
__slab_free(s, page, head, tail_obj, cnt, addr);
}
既然是快速路徑釋放,那麼在 do_slab_free 函數的開始首先就獲取 slab cache 的本地 cpu 緩存結構 kmem_cache_cpu,為了保證我們獲取到的 cpu 本地緩存結構與運行當前進程所在的 cpu 是相符的,所以這裡還是需要在 do .... while 迴圈內判斷兩者的 tid。這一點,筆者已經在本文之前的內容里多次強調過了,這裡不在贅述。
內核在確保已經獲取了正確的 kmem_cache_cpu 結構之後,就會馬上判斷該釋放對象所在的 slab 是否正是 slab cache 本地 cpu 緩存了的 slab —— page == c->page。
如果是的話,直接將對象釋放回緩存 slab 中,調整 kmem_cache_cpu->freelist 指向剛剛釋放的對象,調整釋放對象的 freepointer 指針指向原來的 kmem_cache_cpu->freelist 。
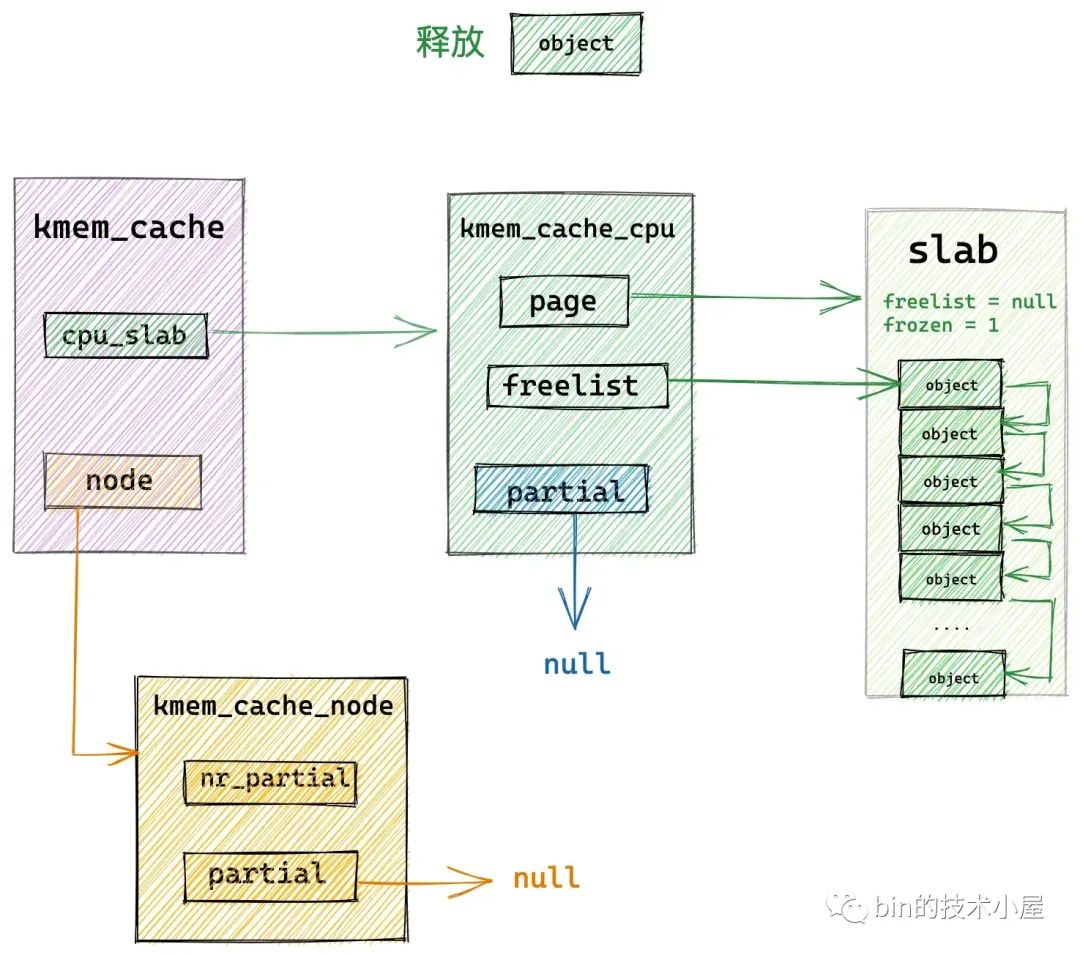
如果當前釋放對象並不在 slab cache 的本地 cpu 緩存中,那麼就會進入慢速路徑 slowpath 釋放記憶體。
3. slab cache 在慢速路徑下回收記憶體
slab cache 在慢速路徑下回收記憶體的邏輯比較複雜,因為這裡涉及到很多的場景,需要改變釋放對象所屬 slab 在 slab cache 架構中的位置。
下麵筆者會帶大家一一梳理這些場景,我們一起來看一下內核在這些不同場景中到底是如何處理的?
在開始閱讀本小節的內容之前,建議大家先回顧下 《細節拉滿,80 張圖帶你一步一步推演 slab 記憶體池的設計與實現》 一文中的 ”8. slab 記憶體釋放原理“ 小節。
在將對象釋放回對應的 slab 中之前,內核需要首先清理一下對象所占的記憶體,重新填充對象的記憶體佈局恢復到初始未使用狀態。因為對象所占的記憶體此時包含了很多已經被使用過的無用信息。這項工作內核在 free_debug_processing 函數中完成。
在將對象所在記憶體恢復到初始狀態之後,內核首先會將對象直接釋放回其所屬的 slab 中,並調整 slab 結構 page 的相關屬性。
接下來就到複雜的處理部分了,內核會在這裡處理多種場景,並改變 slab 在 slab cache 架構中的位置。
-
如果 slab 本來就在 slab cache 本地 cpu 緩存 kmem_cache_cpu->partial 鏈表中,那麼對象在釋放之後,slab 的位置不做任何改變。
-
如果 slab 不在 kmem_cache_cpu->partial 鏈表中,並且該 slab 由於對象的釋放剛好由一個 full slab 變為了一個 partial slab,為了利用局部性的優勢,內核需要將該 slab 插入到 kmem_cache_cpu->partial 鏈表中。

- 如果 slab 不在 kmem_cache_cpu->partial 鏈表中,並且該 slab 由於對象的釋放剛好由一個 partial slab 變為了一個 empty slab,說明該 slab 並不是很活躍,內核會將該 slab 放入對應 NUMA 節點緩存 kmem_cache_node->partial 鏈表中,刀槍入庫,馬放南山。
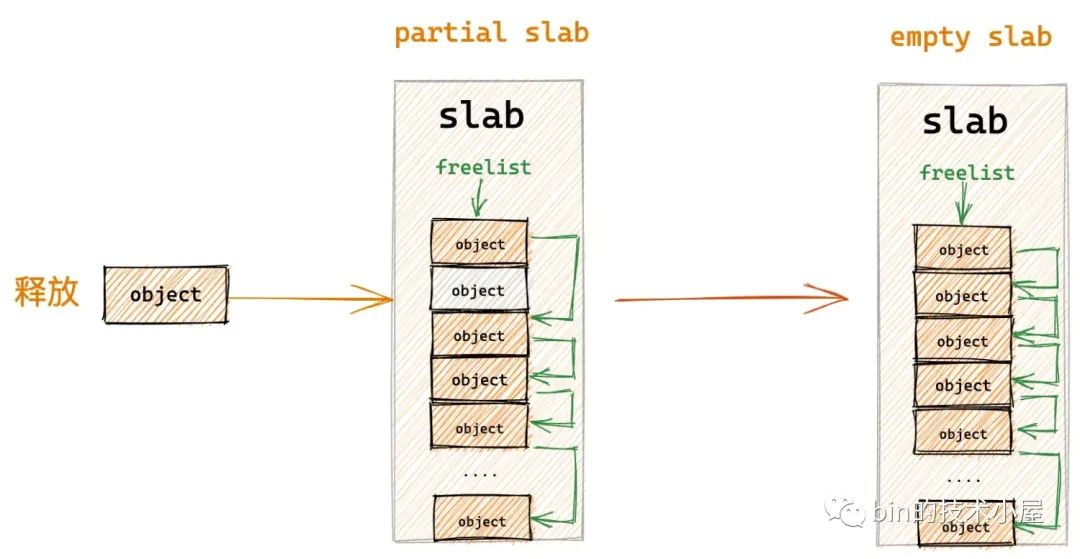
- 如果不符合第 2, 3 種場景,但是 slab 本來就在對應的 NUMA 節點緩存 kmem_cache_node->partial 鏈表中,那麼對象在釋放之後,slab 的位置不做任何改變。
下麵我們就到內核的源碼實現中,來一一驗證這四種慢速釋放場景。
static void __slab_free(struct kmem_cache *s, struct page *page,
void *head, void *tail, int cnt,
unsigned long addr)
{
// 用於指向對象釋放回 slub 之前,slub 的 freelist
void *prior;
// 對象所屬的 slub 之前是否在本地 cpu 緩存 partial 鏈表中
int was_frozen;
// 後續會對 slub 對應的 page 結構相關屬性進行修改
// 修改後的屬性會臨時保存在 new 中,後面通過 cas 替換
struct page new;
unsigned long counters;
struct kmem_cache_node *n = NULL;
stat(s, FREE_SLOWPATH);
// free_debug_processing 中會調用 init_object,清理對象記憶體無用信息,重新恢復對象記憶體佈局到初始狀態
if (kmem_cache_debug(s) &&
!free_debug_processing(s, page, head, tail, cnt, addr))
return;
do {
// 獲取 slub 中的空閑對象列表,prior = null 表示此時 slub 是一個 full slub,意思就是該 slub 中的對象已經全部被分配出去了
prior = page->freelist;
counters = page->counters;
// 將釋放的對象插入到 freelist 的頭部,將對象釋放回 slub
// 將 tail 對象的 freepointer 設置為 prior
set_freepointer(s, tail, prior);
// 將原有 slab 的相應屬性賦值給 new page
new.counters = counters;
// 獲取原來 slub 中的 frozen 狀態,是否在 cpu 緩存 partial 鏈表中
was_frozen = new.frozen;
// inuse 表示 slub 已經分配出去的對象個數,這裡是釋放 cnt 個對象,所以 inuse 要減去 cnt
new.inuse -= cnt;
// !new.inuse 表示此時 slub 變為了一個 empty slub,意思就是該 slub 中的對象還沒有分配出去,全部在 slub 中
// !prior 表示由於本次對象的釋放,slub 剛剛從一個 full slub 變成了一個 partial slub (意思就是該 slub 中的對象部分分配出去了,部分沒有分配出去)
// !was_frozen 表示該 slub 不在 cpu 本地緩存中
if ((!new.inuse || !prior) && !was_frozen) {
// 註意:進入該分支的 slub 之前都不在 cpu 本地緩存中
// 如果配置了 CONFIG_SLUB_CPU_PARTIAL 選項,那麼表示 cpu 本地緩存 kmem_cache_cpu 結構中包含 partial 列表,用於 cpu 緩存部分分配的 slub
if (kmem_cache_has_cpu_partial(s) && !prior) {
// 如果 kmem_cache_cpu 包含 partial 列表並且該 slub 剛剛由 full slub 變為 partial slub
// 凍結該 slub,後續會將該 slub 插入到 kmem_cache_cpu 的 partial 列表中
new.frozen = 1;
} else {
// 如果 kmem_cache_cpu 中沒有配置 partial 列表,那麼直接釋放至 kmem_cache_node 中
// 或者該 slub 由一個 partial slub 變為了 empty slub,調整 slub 的位置到 kmem_cache_node->partial 鏈表中
n = get_node(s, page_to_nid(page));
// 後續會操作 kmem_cache_node 中的 partial 列表,所以這裡需要獲取 list_lock
spin_lock_irqsave(&n->list_lock, flags);
}
}
// cas 更新 slub 中的 freelist 以及 counters
} while (!cmpxchg_double_slab(s, page,
prior, counters,
head, new.counters,
"__slab_free"));
// 該分支要處理的場景是:
// 1: 該 slub 原來不在 cpu 本地緩存的 partial 列表中(!was_frozen),但是該 slub 剛剛從 full slub 變為了 partial slub,需要放入 cpu-> partial 列表中
// 2: 該 slub 原來就在 cpu 本地緩存的 partial 列表中,直接將對象釋放回 slub 即可
if (likely(!n)) {
// 處理場景 1
if (new.frozen && !was_frozen) {
// 將 slub 插入到 kmem_cache_cpu 中的 partial 列表中
put_cpu_partial(s, page, 1);
stat(s, CPU_PARTIAL_FREE);
}
// 處理場景2,因為之前已經通過 set_freepointer 將對象釋放回 slub 了,這裡只需要記錄 slub 狀態即可
if (was_frozen)
stat(s, FREE_FROZEN);
return;
}
// 後續的邏輯就是處理需要將 slub 放入 kmem_cache_node 中的 partial 列表的情形
// 在將 slub 放入 node 緩存之前,需要判斷 node 緩存的 nr_partial 是否超過了指定閾值 min_partial(位於 kmem_cache 結構)
// nr_partial 表示 kmem_cache_node 中 partial 列表中緩存的 slub 個數
// min_partial 表示 slab cache 規定 kmem_cache_node 中 partial 列表可以容納的 slub 最大個數
// 如果 nr_partial 超過了最大閾值 min_partial,則不能放入 kmem_cache_node 里
if (unlikely(!new.inuse && n->nr_partial >= s->min_partial))
// 如果 slub 變為了一個 empty slub 並且 nr_partial 超過了最大閾值 min_partial
// 跳轉到 slab_empty 分支,將 slub 釋放回伙伴系統中
goto slab_empty;
// 如果 cpu 本地緩存中沒有配置 partial 列表並且 slub 剛剛從 full slub 變為 partial slub
// 則將 slub 插入到 kmem_cache_node 中
if (!kmem_cache_has_cpu_partial(s) && unlikely(!prior)) {
remove_full(s, n, page);
add_partial(n, page, DEACTIVATE_TO_TAIL);
stat(s, FREE_ADD_PARTIAL);
}
spin_unlock_irqrestore(&n->list_lock, flags);
// 剩下的情況均屬於 slub 原來就在 kmem_cache_node 中的 partial 列表中
// 直接將對象釋放回 slub 即可,無需改變 slub 的位置,直接返回
return;
slab_empty:
// 該分支處理的場景是: slub 太多了,將 empty slub 釋放會伙伴系統
// 首先將 slub 從對應的管理鏈表上刪除
if (prior) {
/*
* Slab on the partial list.
*/
remove_partial(n, page);
stat(s, FREE_REMOVE_PARTIAL);
} else {
/* Slab must be on the full list */
remove_full(s, n, page);
}
spin_unlock_irqrestore(&n->list_lock, flags);
stat(s, FREE_SLAB);
// 釋放 slub 回伙伴系統,底層調用 __free_pages 將 slub 所管理的所有 page 釋放回伙伴系統
discard_slab(s, page);
}
3.1 直接釋放對象回 slab,調整 slab 相關屬性
static void __slab_free(struct kmem_cache *s, struct page *page,
void *head, void *tail, int cnt,
unsigned long addr)
{
// 後續會對 slub 對應的 page 結構相關屬性進行修改
// 修改後的屬性會臨時保存在 new 中,後面通過 cas 替換
struct page new;
....... 省略 ..........
do {
prior = page->freelist;
counters = page->counters;
// 將對象直接釋放回 slab 中,調整 slab 的 freelist 指針,以及對象的 freepointer 指針
set_freepointer(s, tail, prior);
new.counters = counters;
// 獲取原來 slub 中的 frozen 狀態,是否在 cpu 緩存 partial 中
was_frozen = new.frozen;
// inuse 表示 slub 已經分配出去的對象個數,這裡是釋放 cnt 個對象,所以 inuse 要減去 cnt
new.inuse -= cnt;
....... 省略 ..........
// cas 更新 slub 中的 freelist
} while (!cmpxchg_double_slab(s, page,
prior, counters,
head, new.counters,
"__slab_free"));
. ...... 省略 ..........
}
這一部分的邏輯比較簡單,在 __slab_free 記憶體釋放流程的開始,內核不管三七二十一,首先會將對象直接釋放回其所在的 slab 中。
當對象被釋放回 slab 中之後,slab 結構中的相應屬於就需要做出相應的調整,比如:
- 調整 page 結構中的 freelist,它需要指向剛剛被釋放的對象。
- 調整 page 結構中的 inuse,inuse 表示 slab 中已經被分配出去的對象個數,此時對象已經釋放回 slab 中,需要調整 inuse 欄位。
- 後續內核會根據不同情況,調整 page 結構的 frozen 屬性。
內核會定義一個新的 page 結構 new,將原有 slab 的 page 結構需要更新的上述屬性的新值,先一一複製給 new 的對應屬性,最後通過 cmpxchg_double_slab 原子更新 slab 對應的屬性。
struct page {
struct { /* slub 相關欄位 */
........ 省略 .........
// 指向 page 所屬的 slab cache
struct kmem_cache *slab_cache;
// 指向 slab 中第一個空閑對象
void *freelist; /* first free object */
union {
unsigned long counters;
struct { /* SLUB */
// slab 中已經分配出去的對象
unsigned inuse:16;
// slab 中包含的對象總數
unsigned objects:15;
// 該 slab 是否在對應 slab cache 的本地 CPU 緩存中
// frozen = 1 表示緩存再本地 cpu 緩存中
unsigned frozen:1;
};
};
};
}
按照正常的更新套路來說,我們在更新原有 slab 結構中的 freelist,inuse,frozen 這三個屬性之前,首先需要將原有 slab 的這三個舊的屬性值一一賦值到臨時結構 new page 中,然後在 slab 結構舊值的基礎上調整著三個屬性的新值,最後通過 cmpxchg_double_slab 將這三個屬性的新值原子地更新回 slab 中。
但是我們查看 __slab_free 的代碼發現,內核並不是這樣操作的,內核只是將原有 slab 的 counter 屬性賦值給 new page,而原有 slab 中的 frozen,inuse 屬性並沒有賦值過去。
此時 new page 結構中的 frozen,inuse 屬性依然是上述 struct page 結構中展示的初始值。
而內核後續的操作就更加奇怪了,直接使用 new.frozen 來判斷原有 slab 是否在 slab cache 本地 cpu 的 partial 鏈表中,直接把 new.inuse 屬性當做原有 slab 中已經分配出去對象的個數。
而 new.frozen, new.inuse 是 page 結構初始狀態的值,並不是原有 slab 結構中的值,這樣做肯定不對啊,難道是內核的一個 bug ?
其實並不是,這是內核非常騷的一個操作,這一點對於 Java 程式員來說很難理解。我們在仔細看一下 struct page 結構,就會發現 counter 屬性和 inuse,frozen 屬性被定義在一個 union 結構體中。
union 結構體中定義的欄位全部共用一片記憶體,union 結構體的記憶體占用由其中最大的屬性決定。而 struct 結構體中的每個欄位都是獨占一片記憶體的。
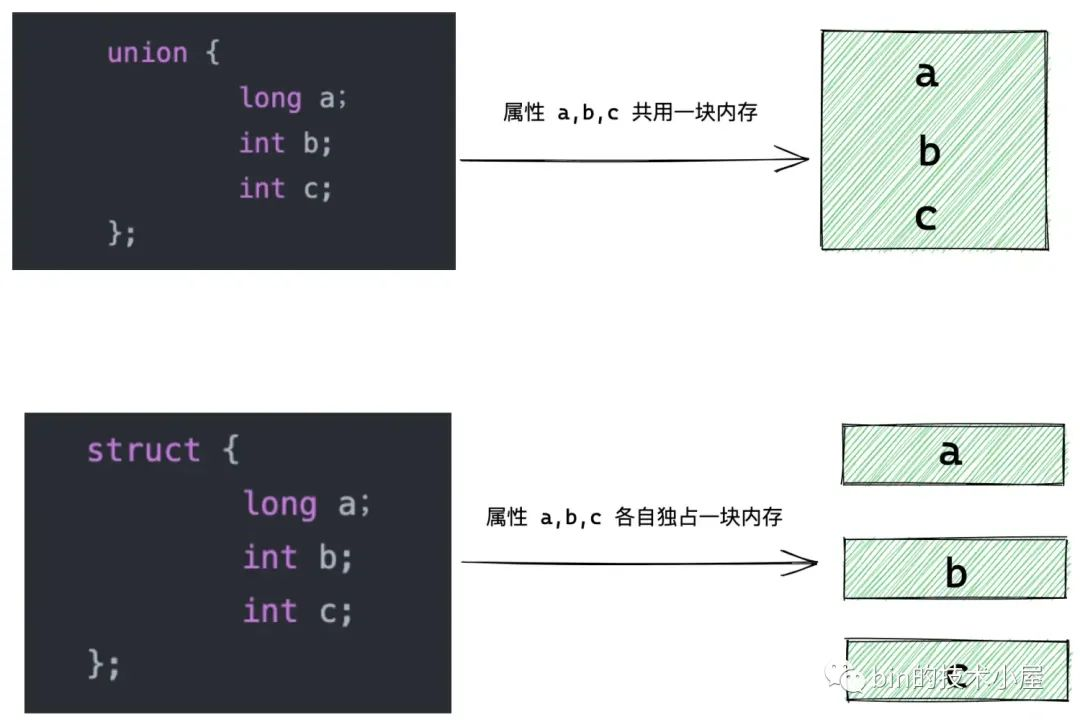
由於 union 結構體中各個欄位都是共用一塊記憶體,所以一個欄位的改變就會影響其他欄位的值,從另一方面來看,通過一個欄位就可以將整個 union 結構占用的記憶體塊拿出來。明白這些,我們在回頭來看內核的操作。
struct page {
union {
unsigned long counters;
struct { /* SLUB */
// slab 中已經分配出去的對象
unsigned inuse:16;
// slab 中包含的對象總數
unsigned objects:15;
// 該 slab 是否在對應 slab cache 的本地 CPU 緩存中
// frozen = 1 表示緩存再本地 cpu 緩存中
unsigned frozen:1;
};
};
}
page 結構中的 counters 是和 inuse,frozen 共用同一塊記憶體的,內核在 __slab_free 中將原有 slab 的 counters 屬性賦值給 new.counters 的一瞬間,counters 所在的記憶體塊也就賦值到 new page 的 union 結構中了。
而 inuse,frozen 屬性的值也在這個記憶體塊中,所以原有 slab 中的 inuse,frozen 屬性也就跟著一起賦值到 new page 的對應屬性中了。這樣一來,後續的邏輯處理也就通順了。
counters = page->counters;
new.counters = counters;
// 獲取原來 slub 中的 frozen 狀態,是否在 cpu 緩存 partial 中
was_frozen = new.frozen;
// inuse 表示 slub 已經分配出去的對象個數,這裡是釋放 cnt 個對象,所以 inuse 要減去 cnt
new.inuse -= cnt;
同樣的道理,我們再來看內核 cmpxchg_double_slab 中的更新操作:
內核明明在 do .... while 迴圈中更新了 freelist,inuse,frozen 這三個屬性,而 counters 屬性只是讀取並沒有更新操作,那麼為什麼在 cmpxchg_double_slab 只是更新 page 結構的 freelist 和 counters 呢?inuse,frozen 這兩個屬性又在哪裡更新的呢?
do {
....... 省略 ..........
// cas 更新 slub 中的 freelist
} while (!cmpxchg_double_slab(s, page,
prior, counters,
head, new.counters,
"__slab_free"));
我想大家現在一定能夠解釋這個問題了,由於 counters,inuse,frozen 共用一塊記憶體,當 inuse,frozen 的值發生變化之後,雖然 counters 的值沒有發生變化,但是我們可以通過更新 counters 來將原有 slab 中的這塊記憶體一起更新掉,這樣 inuse,frozen 的值也跟著被更新了。
由於 page 的 freelist 指針在 union 結構體之外,所以需要在cmpxchg_double_slab 中單獨更新。
筆者曾經為了想給大家解釋清楚 page->counters 這個屬性的作用,而翻遍了 slab 的所有源碼,發現內核源碼中對於 page->counters 的使用都是只做簡單的讀取,並不做改變,然後直接在更新,這個問題也困擾了筆者很久。
直到為大家寫這篇文章的時候,才頓悟。原來 page->counters 的作用只是為了指向 inuse,frozen 所在的記憶體,方便在 cmpxchg_double_slab 中同時原子地更新這兩個屬性。
接下來的內容就到了 slab cache 回收記憶體最為複雜的環節了,大家需要多一些耐心,繼續跟著筆者的思路走下去,我們一起來看下內核如何處理三種記憶體慢速釋放的場景。
3.2 釋放對象所屬 slab 本來就在 cpu 緩存 partial 鏈表中

was_frozen 指向釋放對象所屬 slab 結構中的 frozen 屬性,用來表示 slab 是否在 slab cache 的本地 cpu 緩存 partial 鏈表中。
was_frozen = new.frozen;
如果 was_frozen == true 表示釋放對象所屬 slab 本來就在 kmem_cache_cpu->partial 鏈表中,內核將對象直接釋放回 slab 中,slab 的原有位置不做改變。
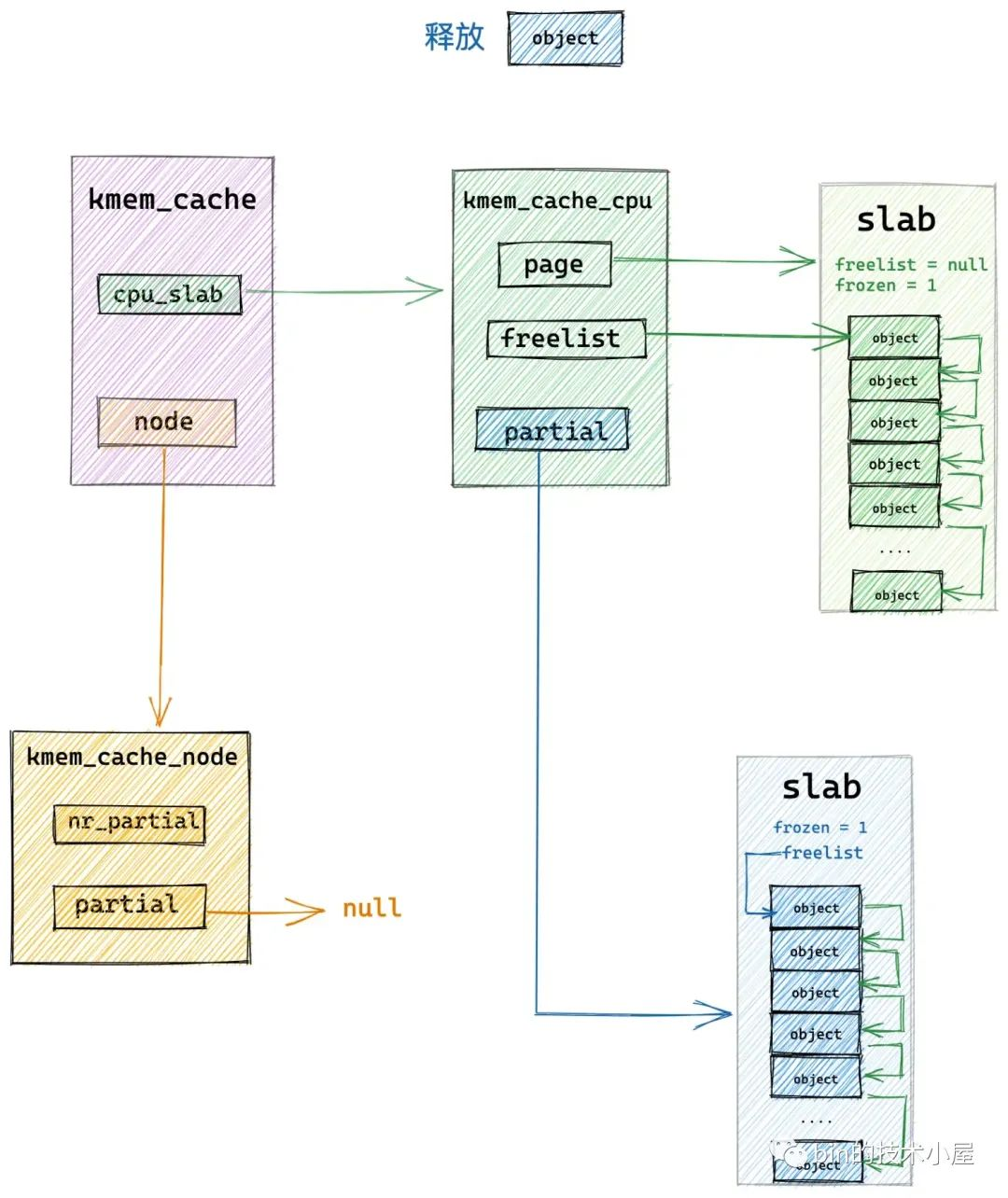
下麵我們看下 was_frozen == fasle 也就是 slab 不在 kmem_cache_cpu->partial 鏈表中 的時候,內核又是如何處理的 ?
3.3 釋放對象所屬 slab 從 full slab 變為了 partial slab
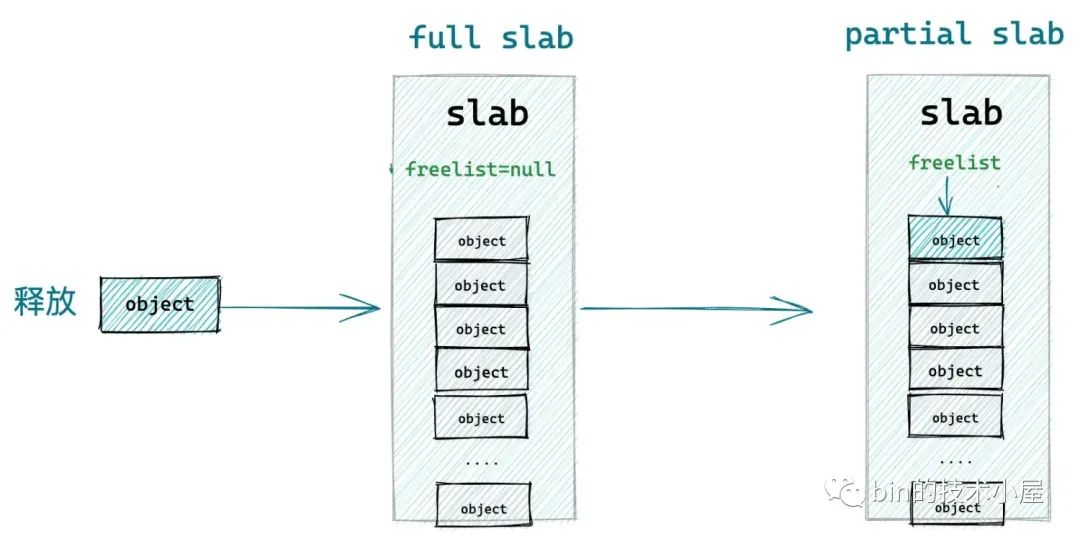
如果釋放對象所屬 slab 原來是一個 full slab,恰恰說明該 slab 擁有比較好的局部性,進程經常從該 slab 中分配對象,slab 十分活躍,才導致它變為了一個 full slab
prior = page->freelist = null
隨著對象的釋放,該 slab 從一個 full slab 變為了 partial slab,內核為了更好的利用該 slab 的局部性,所以需要將該 slab 插入到 slab cache 的本地 cpu 緩存 kmem_cache_cpu->partial 鏈表中。
if (kmem_cache_has_cpu_partial(s) && !prior) {
new.frozen = 1;
}
if (new.frozen && !was_frozen) {
// 將 slub 插入到 kmem_cache_cpu 中的 partial 列表中
put_cpu_partial(s, page, 1);
stat(s, CPU_PARTIAL_FREE);
}
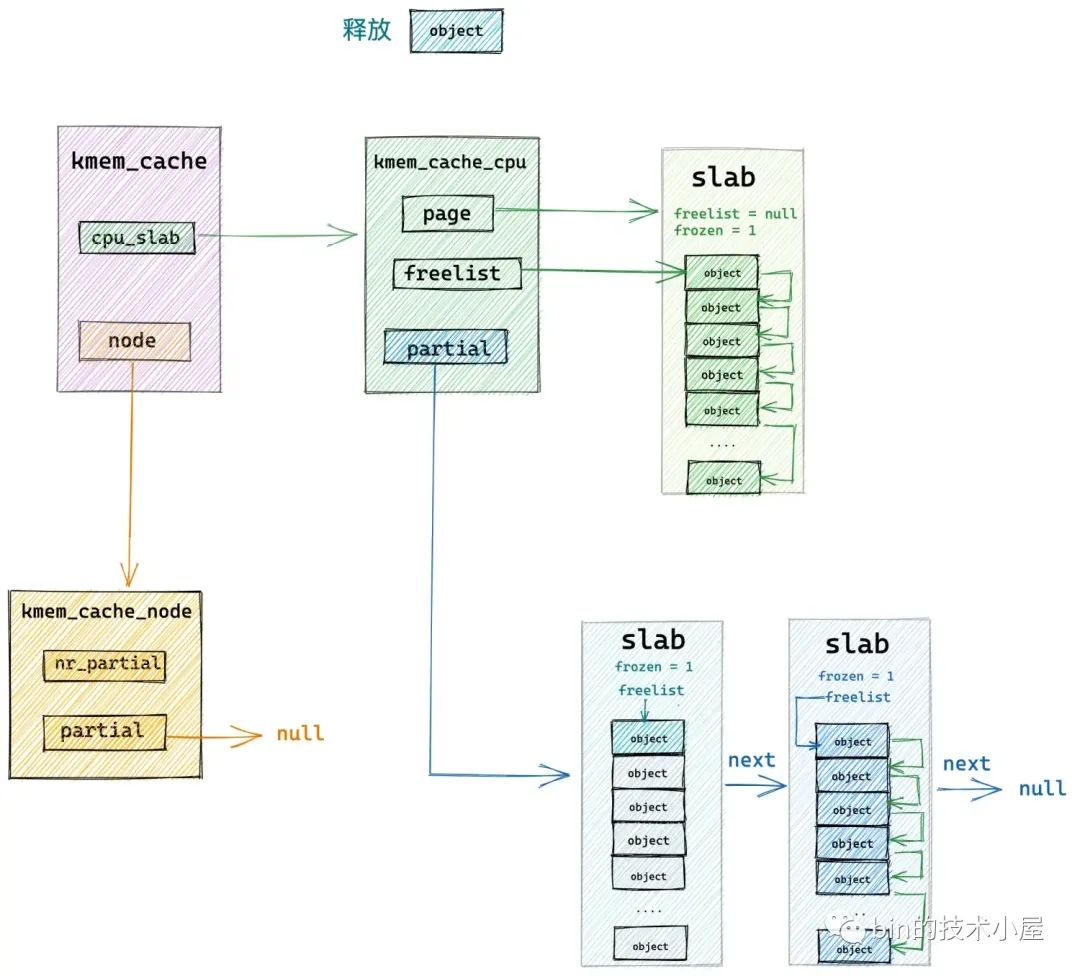
將 slab 插入到 kmem_cache_cpu->partial 鏈表的邏輯封裝在 put_cpu_partial 中,put_cpu_partial 函數最重要的一個考量邏輯是需要確保 kmem_cache_cpu->partial 鏈表中所有 slab 中包含的空閑對象總數不能超過 kmem_cache->cpu_partial 的限制。
struct kmem_cache {
// 限定 slab cache 在每個 cpu 本地緩存 partial 鏈表中所有 slab 中空閑對象的總數
unsigned int cpu_partial;
};
在釋放對象所在的 slab 插入到 kmem_cache_cpu->partial 鏈表之前,put_cpu_partial 函數需要判斷當前 kmem_cache_cpu->partial 鏈表中包含的空閑對象總數 pobjects 是否超過了 kmem_cache->cpu_partial 的限制。
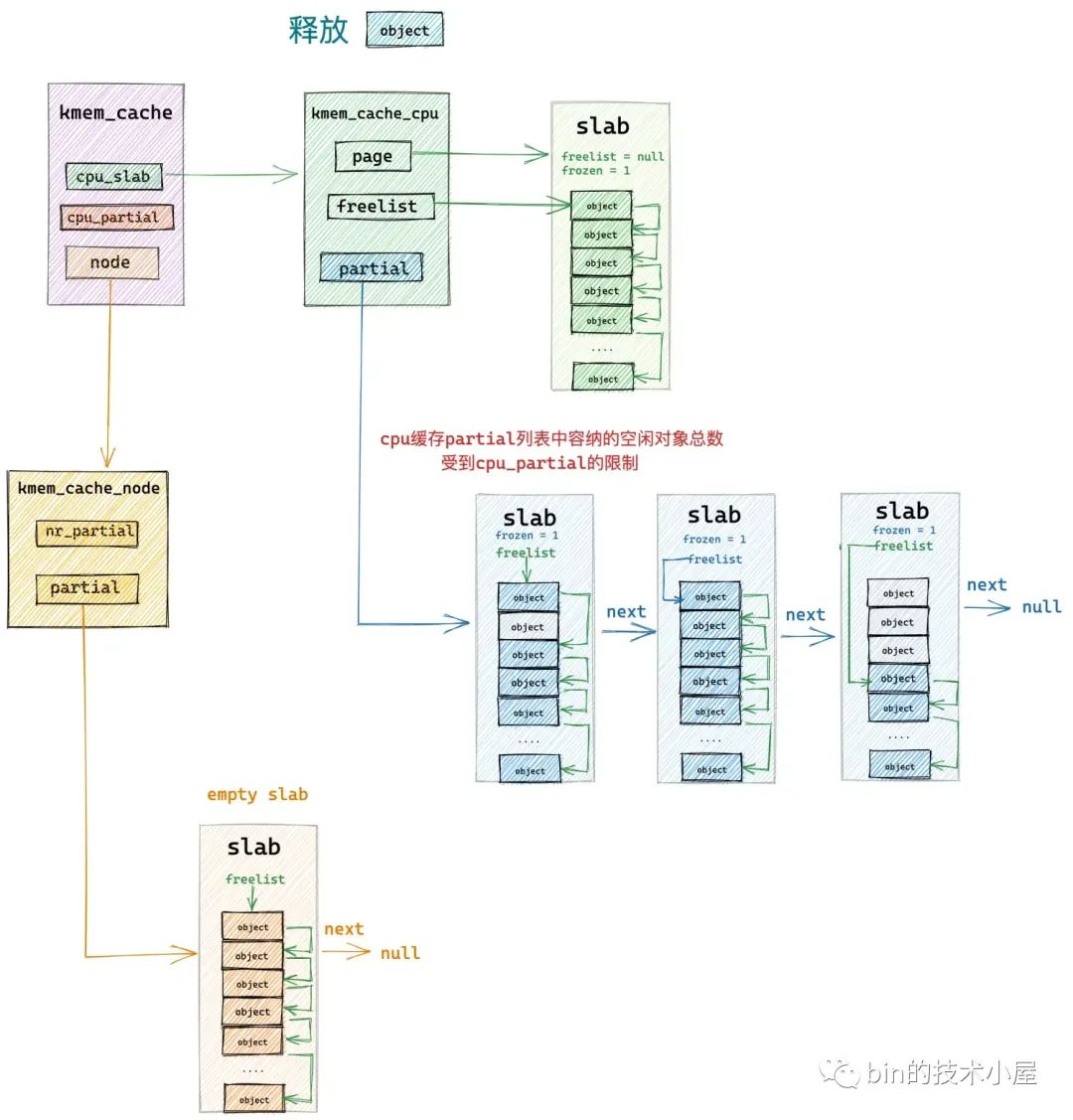
如果超過了,則需要先將當前 kmem_cache_cpu->partial 鏈表中所有的 slab 轉移到其對應的 NUMA 節點緩存 kmem_cache_node->partial 鏈表中。轉移完成之後,在將釋放對象所屬的 slab 插入到 kmem_cache_cpu->partial 鏈表中。
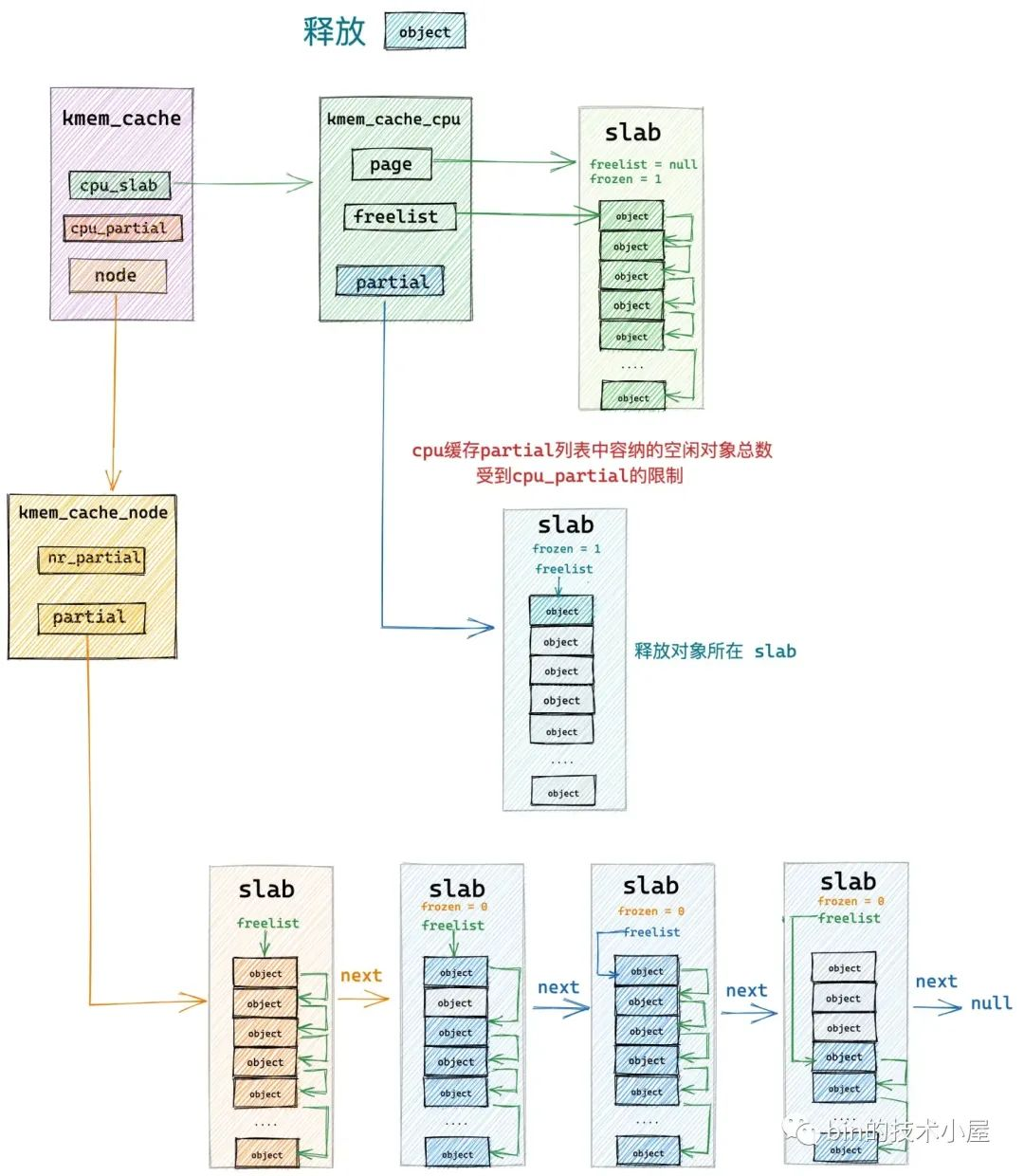
static void put_cpu_partial(struct kmem_cache *s, struct page *page, int drain)
{
// 只有配置了 CONFIG_SLUB_CPU_PARTIAL 選項,kmem_cache_cpu 中才有會 partial 列表
#ifdef CONFIG_SLUB_CPU_PARTIAL
// 指向原有 kmem_cache_cpu 中的 partial 列表
struct page *oldpage;
// slub 所在管理列表中的 slub 個數,這裡的列表是指 partial 列表
int pages;
// slub 所在管理列表中的包含的空閑對象總數,這裡的列表是指 partial 列表
// 內核會將列表總體的信息存放在列表首頁 page 的相關欄位中
int pobjects;
// 禁止搶占
preempt_disable();
do {
pages = 0;
pobjects = 0;
// 獲取 slab cache 中原有的 cpu 本地緩存 partial 列表首頁
oldpage = this_cpu_read(s->cpu_slab->partial);
// 如果 partial 列表不為空,則需要判斷 partial 列表中所有 slub 包含的空閑對象總數是否超過了 s->cpu_partial 規定的閾值
// 超過 s->cpu_partial 則需要將 kmem_cache_cpu->partial 列表中原有的所有 slub 轉移到 kmem_cache_node-> partial 列表中
// 轉移之後,再把當前 slub 插入到 kmem_cache_cpu->partial 列表中
// 如果沒有超過 s->cpu_partial ,則無需轉移直接插入
if (oldpage) {
// 從 partial 列表首頁中獲取列表中包含的空閑對象總數
pobjects = oldpage->pobjects;
// 從 partial 列表首頁中獲取列表中包含的 slub 總數
pages = oldpage->pages;
if (drain && pobjects > s->cpu_partial) {
unsigned long flags;
// 關閉中斷,防止併發訪問
local_irq_save(flags);
// partial 列表中所包含的空閑對象總數 pobjects 超過了 s->cpu_partial 規定的閾值
// 則需要將現有 partial 列表中的所有 slub 轉移到相應的 kmem_cache_node->partial 列表中
unfreeze_partials(s, this_cpu_ptr(s->cpu_slab));
// 恢復中斷
local_irq_restore(flags);
// 重置 partial 列表
oldpage = NULL;
pobjects = 0;
pages = 0;
stat(s, CPU_PARTIAL_DRAIN);
}
}
// 無論 kmem_cache_cpu-> partial 列表中的 slub 是否需要轉移
// 釋放對象所在的 slub 都需要填加到 kmem_cache_cpu-> partial 列表中
pages++;
pobjects += page->objects - page->inuse;
page->pages = pages;
page->pobjects = pobjects;
page->next = oldpage;
// 通過 cas 將 slub 插入到 partial 列表的頭部
} while (this_cpu_cmpxchg(s->cpu_slab->partial, oldpage, page)
!= oldpage);
// s->cpu_partial = 0 表示 kmem_cache_cpu->partial 列表不能存放 slub
// 將釋放對象所在的 slub 轉移到 kmem_cache_node-> partial 列表中
if (unlikely(!s->cpu_partial)) {
unsigned long flags;
local_irq_save(flags);
unfreeze_partials(s, this_cpu_ptr(s->cpu_slab));
local_irq_restore(flags);
}
preempt_enable();
#endif /* CONFIG_SLUB_CPU_PARTIAL */
}
那麼我們如何知道 kmem_cache_cpu->partial 鏈表所包含的空閑對象總數到底是多少呢?
這就用到了 struct page 結構中的兩個重要屬性:
struct page {
// slab 所在鏈表中的包含的 slab 總數
int pages;
// slab 所在鏈表中包含的對象總數
int pobjects;
}
我們都知道 slab 在內核中的數據結構用 struct page 中的相關結構體表示,slab 在 slab cache 架構中一般是由 kmem_cache_cpu->partial 鏈表和 kmem_cache_node->partial 鏈表來組織管理。
那麼我們如何知道 partial 鏈表中包含多少個 slab ?包含多少個空閑對象呢?
答案是內核會將 parital 鏈表中的這些總體統計信息存儲在鏈表首個 slab 結構中。也就是說存儲在首個 page 結構中的 pages 屬性和 pobjects 屬性中。
在 put_cpu_partial 函數的開始,內核直接獲取 parital 鏈表的首個 slab —— oldpage,並通過 oldpage->pobjects 與 s->cpu_partial 比較,來判斷當前 kmem_cache_cpu->partial 鏈表中包含的空閑對象總數是否超過了 kmem_cache 結構中規定的 cpu_partial 閾值。
如果超過了,則通過 unfreeze_partials 轉移 kmem_cache_cpu->partial 鏈表中的所有 slab 到對應的 kmem_cache_node->partial 鏈表中。
既然 kmem_cache_cpu->partial 鏈表有容量的限制,那麼同樣 kmem_cache_node->partial 鏈表中的容量也會有限制。
kmem_cache_node->partial 鏈表中所包含 slab 個數的上限由 kmem_cache 結構中的 min_partial 屬性決定。
struct kmem_cache {
// slab cache 在 numa node 中緩存的 slab 個數上限,slab 個數超過該值,空閑的 empty slab 則會被回收至伙伴系統
unsigned long min_partial;
}
如果當前要轉移的 slab 是一個 empty slab,並且此時 kmem_cache_node->partial 鏈表所包含的 slab 個數 kmem_cache_node->nr_partial 已經超過了 kmem_cache-> min_partial 的限制,那麼內核就會直接將這個 empty slab 釋放回伙伴系統中。
// 將 kmem_cache_cpu->partial 列表中包含的 slub unfreeze
// 並轉移到對應的 kmem_cache_node->partial 列表中
static void unfreeze_partials(struct kmem_cache *s,
struct kmem_cache_cpu *c)
{
#ifdef CONFIG_SLUB_CPU_PARTIAL
struct kmem_cache_node *n = NULL, *n2 = NULL;
struct page *page, *discard_page = NULL;
// 挨個遍歷 kmem_cache_cpu->partial 列表,將列表中的 slub 轉移到對應 kmem_cache_node->partial 列表中
while ((page = c->partial)) {
struct page new;
struct page old;
// 將當前遍歷到的 slub 從 kmem_cache_cpu->partial 列表摘下
c->partial = page->next;
// 獲取當前 slub 所在的 numa 節點對應的 kmem_cache_node 緩存
n2 = get_node(s, page_to_nid(page));
// 如果和上一個轉移的 slub 所在的 numa 節點不一樣
// 則需要釋放上一個 numa 節點的 list_lock,並對當前 numa 節點的 list_lock 加鎖
if (n != n2) {
if (n)
spin_unlock(&n->list_lock);
n = n2;
spin_lock(&n->list_lock);
}
do {
old.freelist = page->freelist;
old.counters = page->counters;
VM_BUG_ON(!old.frozen);
new.counters = old.counters;
new.freelist = old.freelist;
// unfrozen 當前 slub,因為即將被轉移到對應的 kmem_cache_node->partial 列表
new.frozen = 0;
// cas 更新當前 slub 的 freelist,frozen 屬性
} while (!__cmpxchg_double_slab(s, page,
old.freelist, old.counters,
new.freelist, new.counters,
"unfreezing slab"));
// 因為 kmem_cache_node->partial 列表中所包含的 slub 個數是受 s->min_partial 閾值限制的
// 所以這裡還需要檢查 nr_partial 是否超過了 min_partial
// 如果當前被轉移的 slub 是一個 empty slub 並且 nr_partial 超過了 min_partial 的限制,則需要將 slub 釋放回伙伴系統中
if (unlikely(!new.inuse && n->nr_partial >= s->min_partial)) {
// discard_page 用於將需要釋放回伙伴系統的 slub 串聯起來
// 後續統一將 discard_page 鏈表中的 slub 釋放回伙伴系統
page->next = discard_page;
discard_page = page;
} else {
// 其他情況,只要 slub 不為 empty ,不管 nr_partial 是否超過了 min_partial
// 都需要將 slub 轉移到對應 kmem_cache_node->partial 列表的末尾
add_partial(n, page, DEACTIVATE_TO_TAIL);
stat(s, FREE_ADD_PARTIAL);
}
}
if (n)
spin_unlock(&n->list_lock);
// 將 discard_page 鏈表中的 slub 統一釋放回伙伴系統
while (discard_page) {
page = discard_page;
discard_page = discard_page->next;
stat(s, DEACTIVATE_EMPTY);
// 底層調用 __free_pages 將 slub 所管理的所有 page 釋放回伙伴系統
discard_slab(s, page);
stat(s, FREE_SLAB);
}
#endif /* CONFIG_SLUB_CPU_PARTIAL */
}
3.4 釋放對象所屬 slab 從 partial slab 變為了 empty slab
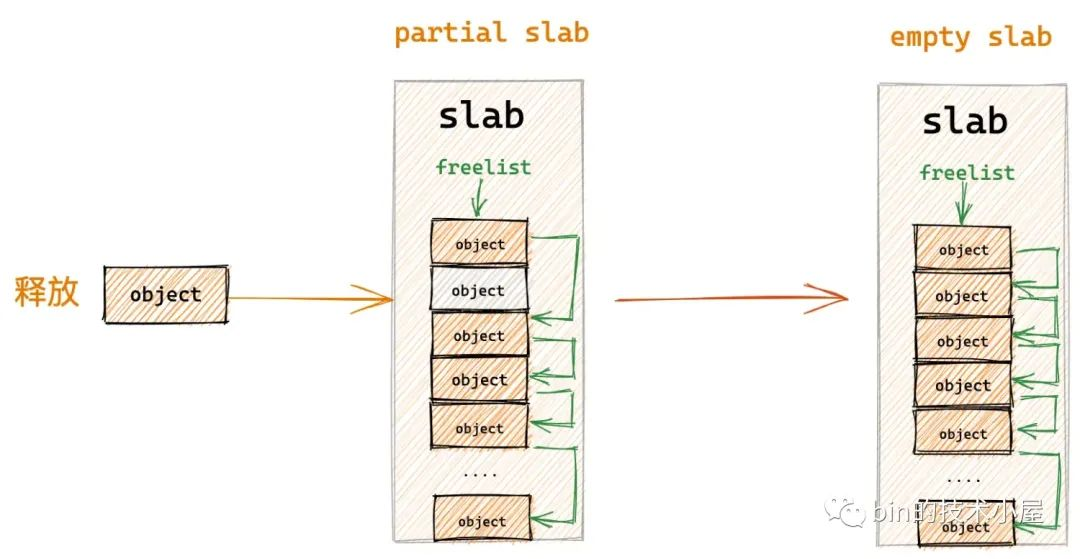
如果釋放對象所在的 slab 原來是一個 partial slab ,由於對象的釋放剛好變成了一個 empty slab,恰恰說明該 slab 並不是一個活躍的 slab,它的局部性不好,內核已經好久沒有從該 slab 中分配對象了,所以內核選擇刀槍入庫,馬放南山。將它釋放回 kmem_cache_node->partial 鏈表中作為本地 cpu 緩存的後備選項。
在將這個 empty slab 插入到 kmem_cache_node->partial 鏈表之前,同樣需要檢查當前 partial 鏈表中的容量 kmem_cache_node->nr_partial 不能超過 kmem_cache-> min_partial 的限制。如果超過限制了,直接將這個 empty slab 釋放回伙伴系統中。

if ((!new.inuse || !prior) && !was_frozen) {
if (kmem_cache_has_cpu_partial(s) && !prior) {
new.frozen = 1;
} else {
// !new.inuse 表示當前 slab 剛剛從一個 partial slab 變為了 empty slab
n = get_node(s, page_to_nid(page));
spin_lock_irqsave(&n->list_lock, flags);
}
}
if (unlikely(!new.inuse && n->nr_partial >= s->min_partial))
// 如果 slub 變為了一個 empty slub 並且 nr_partial 超過了最大閾值 min_partial
// 跳轉到 slab_empty 分支,將 slub 釋放回伙伴系統中
goto slab_empty;
釋放對象所屬的 slab 本來就在 kmem_cache_node->partial 鏈表中,這種情況下就是直接釋放對象回 slab 中,無需改變 slab 的位置。

4. slab cache 的銷毀
終於到了本文最後一個小節了, slab cache 最為複雜的內容我們已經踏過去了,本小節的內容將會非常的輕鬆愉悅,這一次筆者來為大家介紹一下 slab cache 的銷毀過程。
slab cache 的銷毀過程剛剛好和 slab cache 的創建過程相反,筆者在 《從內核源碼看 slab 記憶體池的創建初始化流程》的內容中,通過一步一步的源碼演示,最終勾勒出 slab cache 的完整架構:
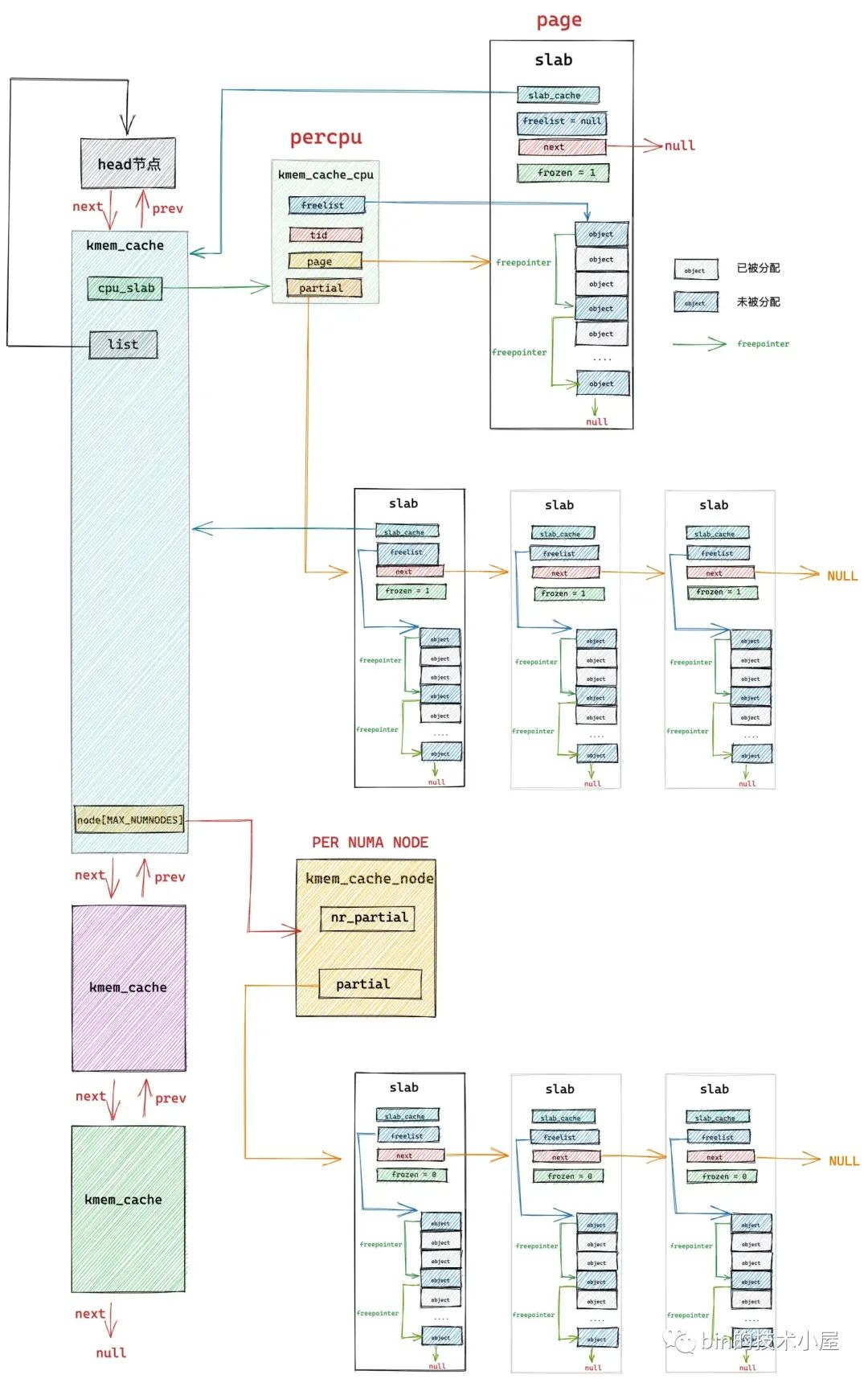
slab cache 銷毀的核心步驟如下:
-
首先需要釋放 slab cache 在所有 cpu 中的緩存 kmem_cache_cpu 中占用的資源,包括被 cpu 緩存的 slab (kmem_cache_cpu->page),以及 kmem_cache_cpu->partial 鏈表中緩存的所有 slab,將它們統統歸還到伙伴系統中。
-
釋放 slab cache 在所有 NUMA 節點中的緩存 kmem_cache_node 占用的資源,也就是將 kmem_cache_node->partial 鏈表中緩存的所有 slab ,統統釋放回伙伴系統中。
-
在 sys 文件系統中移除
/sys/kernel/slab/<cacchename>節點相關信息。 -
從 slab cache 的全局列表中刪除該 slab cache。
-
釋放 kmem_cache_cpu 結構,kmem_cache_node 結構,kmem_cache 結構。釋放對象的過程就是 《1. slab cache 如何回收記憶體》小節中介紹的內容。
下麵我們一起到內核源碼中看一下具體的銷毀過程:

void kmem_cache_destroy(struct kmem_cache *s)
{
int err;
if (unlikely(!s))
return;
// 獲取 cpu_hotplug_lock,防止 cpu 熱插拔改變 online cpu map
get_online_cpus();
// 獲取 mem_hotplug_lock,防止訪問記憶體的時候進行記憶體熱插拔
get_online_mems();
// 獲取 slab cache 鏈表的全局互斥鎖
mutex_lock(&slab_mutex);
// 將 slab cache 的引用技術減 1
s->refcount--;
// 判斷 slab cache 是否還存在其他地方的引用
if (s->refcount)
// 如果該 slab cache 還存在引用,則不能銷毀,跳轉到 out_unlock 分支
goto out_unlock;
// 銷毀 memory cgroup 相關的 cache ,這裡不是本文重點
err = shutdown_memcg_caches(s);
if (!err)
// slab cache 銷毀的核心函數,銷毀邏輯就封裝在這裡
err = shutdown_cache(s);
if (err) {
pr_err("kmem_cache_destroy %s: Slab cache still has objects\n",
s->name);
dump_stack();
}
out_unlock:
// 釋放相關的自旋鎖和信號量
mutex_unlock(&slab_mutex);
put_online_mems();
put_online_cpus();
}
在開始正式銷毀 slab cache 之前,首先需要將 slab cache 的引用計數 refcount 減 1。並需要判斷 slab cache 是否還存在其他地方的引用。
slab cache 這裡在其他地方存在引用的可能性,相關細節筆者在《從內核源碼看 slab 記憶體池的創建初始化流程》 一文中的 ”1. __kmem_cache_alias“ 小節的內容中已經詳細介紹過了。
當我們利用 kmem_cache_create 創建 slab cache 的時候,內核會檢查當前系統中是否存在一個各項參數和我們要創建 slab cache 參數差不多的一個 slab cache,如果存在,那麼內核就不會再繼續創建新的 slab cache,而是復用已有的 slab cache。
一個可以被覆用的 slab cache 需要滿足以下四個條件:
-
指定的 slab_flags_t 相同。
-
指定對象的 object size 要小於等於已有 slab cache 中的對象 size (kmem_cache->size)。
-
如果指定對象的 object size 與已有 kmem_cache->size 不相同,那麼它們之間的差值需要再一個 word size 之內。
-
已有 slab cache 中的 slab 對象對齊 align (kmem_cache->align)要大於等於指定的 align 並且可以整除 align 。 。
隨後會在 sys 文件系統中為復用 slab cache 起一個別名 alias 並創建一個 /sys/kernel/slab/aliasname 目錄,但是該目錄下的文件需要軟鏈接到原有 slab cache 在 sys 文件系統對應目錄下的文件。這裡的 aliasname 就是我們通過 kmem_cache_create 指定的 slab cache 名稱。
在這種情況,系統中的 slab cache 就可能在多個地方產生引用,所以在銷毀的時候需要判斷這一點。
如果存在其他地方的引用,則需要停止銷毀流程,如果沒有其他地方的引用,則調用 shutdown_cache 開始正式的銷毀流程。
static int shutdown_cache(struct kmem_cache *s)
{
// 這裡會釋放 slab cache 占用的所有資源
if (__kmem_cache_shutdown(s) != 0)
return -EBUSY;
// 從 slab cache 的全局列表中刪除該 slab cache
list_del(&s->list);
// 釋放 sys 文件系統中移除 /sys/kernel/slab/name 節點的相關資源
sysfs_slab_unlink(s);
sysfs_slab_release(s);
// 釋放 kmem_cache_cpu 結構
// 釋放 kmem_cache_node 結構
// 釋放 kmem_cache 結構
slab_kmem_cache_release(s);
}
return 0;
}
4.1 釋放 slab cache 占用的所有資源
-
首先需要釋放 slab cache 在所有 cpu 中的緩存 kmem_cache_cpu 中占用的資源,包括被 cpu 緩存的 slab (kmem_cache_cpu->page),以及 kmem_cache_cpu->partial 鏈表中緩存的所有 slab,將它們統統歸還到伙伴系統中。
-
釋放 slab cache 在所有 NUMA 節點中的緩存 kmem_cache_node 占用的資源,也就是將 kmem_cache_node->partial 鏈表中緩存的所有 slab ,統統釋放回伙伴系統中。
-
在 sys 文件系統中移除
/sys/kernel/slab/<cacchename>節點相關信息。
/*
* Release all resources used by a slab cache.
*/
int __kmem_cache_shutdown(struct kmem_cache *s)
{
int node;
struct kmem_cache_node *n;
// 釋放 slab cache 本地 cpu 緩存 kmem_cache_cpu 中緩存的 slub 以及 partial 列表中的 slub,統統歸還給伙伴系統
flush_all(s);
// 釋放 slab cache 中 numa 節點緩存 kmem_cache_node 中 partial 列表上的所有 slub
for_each_kmem_cache_node(s, node, n) {
free_partial(s, n);
if (n->nr_partial || slabs_node(s, node))
return 1;
}
// 在 sys 文件系統中移除 /sys/kernel/slab/name 節點相關信息
sysfs_slab_remove(s);
return 0;
}
4.2 釋放 slab cache 在各個 cpu 中的緩存資源
內核通過 on_each_cpu_cond 挨個遍歷所有 cpu,在遍歷的過程中通過 has_cpu_slab 判斷 slab cache 是否在該 cpu 中還占有緩存資源,如果是則調用 flush_cpu_slab 將緩存資源釋放回伙伴系統中。
// 釋放 kmem_cache_cpu 中占用的所有記憶體資源
static void flush_all(struct kmem_cache *s)
{
// 遍歷每個 cpu,通過 has_cpu_slab 函數檢查 cpu 上是否還有 slab cache 的相關緩存資源
// 如果有,則調用 flush_cpu_slab 進行資源的釋放
on_each_cpu_cond(has_cpu_slab, flush_cpu_slab, s, 1, GFP_ATOMIC);
}
static bool has_cpu_slab(int cpu, void *info)
{
struct kmem_cache *s = info;
// 獲取 cpu 在 slab cache 上的本地緩存
struct kmem_cache_cpu *c = per_cpu_ptr(s->cpu_slab, cpu);
// 判斷 cpu 本地緩存中是否還有緩存的 slub
return c->page || slub_percpu_partial(c);
}
static void flush_cpu_slab(void *d)
{
struct kmem_cache *s = d;
// 釋放 slab cache 在 cpu 上的本地緩存資源
__flush_cpu_slab(s, smp_processor_id());
}
static inline void __flush_cpu_slab(struct kmem_cache *s, int cpu)
{
struct kmem_cache_cpu *c = per_cpu_ptr(s->cpu_slab, cpu);
if (c->page)
// 釋放 cpu 本地緩存的 slub 到伙伴系統
flush_slab(s, c);
// 將 cpu 本地緩存中的 partial 列表裡的 slub 全部釋放回伙伴系統
unfreeze_partials(s, c);
}
4.3 釋放 slab cache 的核心數據結構
這裡的釋放流程正是筆者在本文 《1. slab cache 如何回收記憶體》小節中介紹的內容。
void slab_kmem_cache_release(struct kmem_cache *s)
{
// 釋放 slab cache 中的 kmem_cache_cpu 結構以及 kmem_cache_node 結構
__kmem_cache_release(s);
// 最後釋放 slab cache 的核心數據結構 kmem_cache
kmem_cache_free(kmem_cache, s);
}
總結
整個 slab cache 系列篇幅非常龐大,涉及到的細節非常豐富,為了方便大家回顧,筆者這裡將 slab cache 系列涉及到的重點內容再次梳理總結一下。
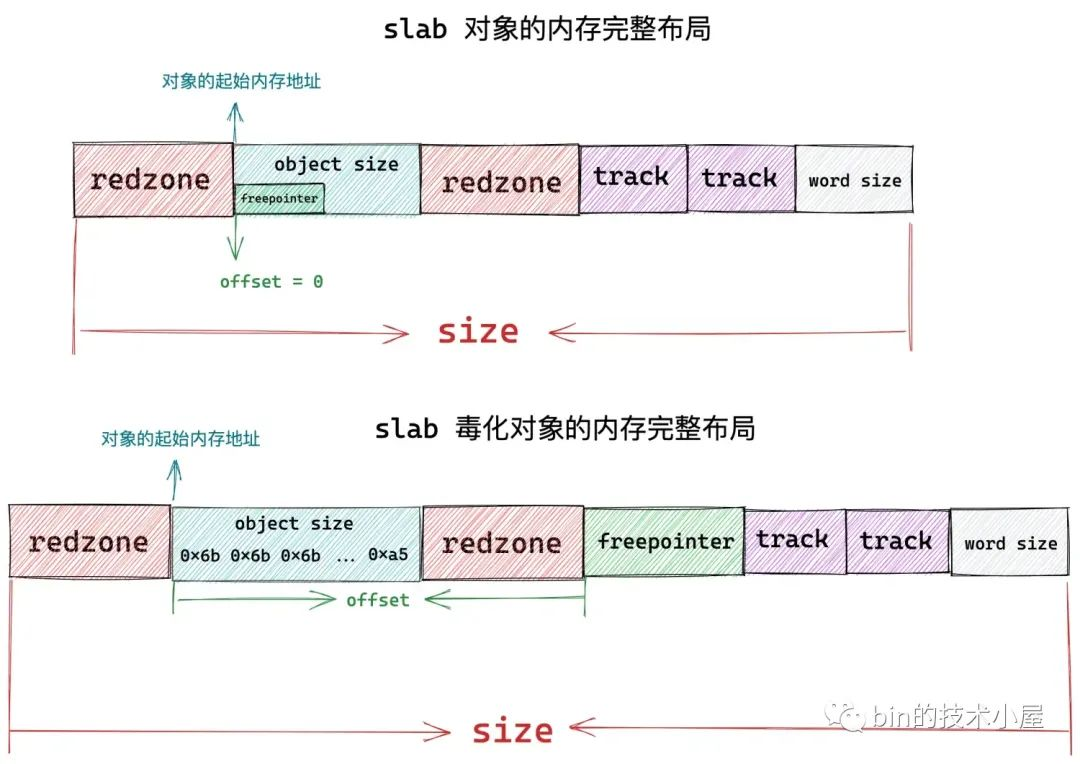
在本文正式進入 slab 相關內容之後,筆者首先為大家詳細介紹了 slab 記憶體池中對象的記憶體佈局情況,如下圖所示:

在此基礎之上,我們繼續採用一步一圖的方式,一步一步推演出 slab 記憶體池的整體架構,如下圖所示:

隨後基於此架構,筆者介紹了在不同場景下 slab 記憶體池分配記憶體以及回收記憶體的核心原理。在交代完核心原理之後,我們進一步深入到內核源碼實現中來一一驗證。
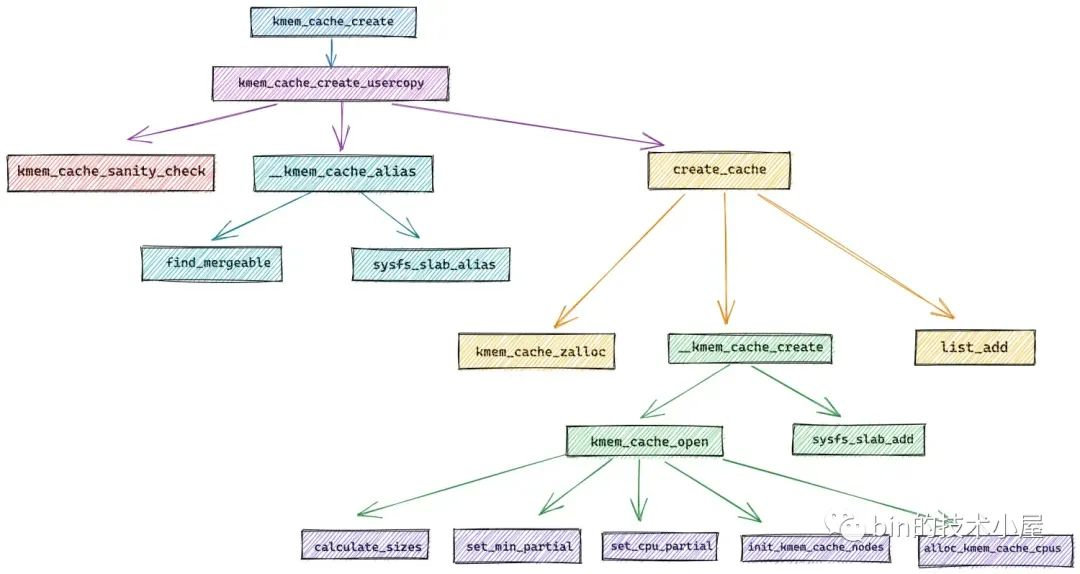
在內核源碼章節的開始,筆者首先為大家介紹了 slab 記憶體池的創建流程,流程圖如下:
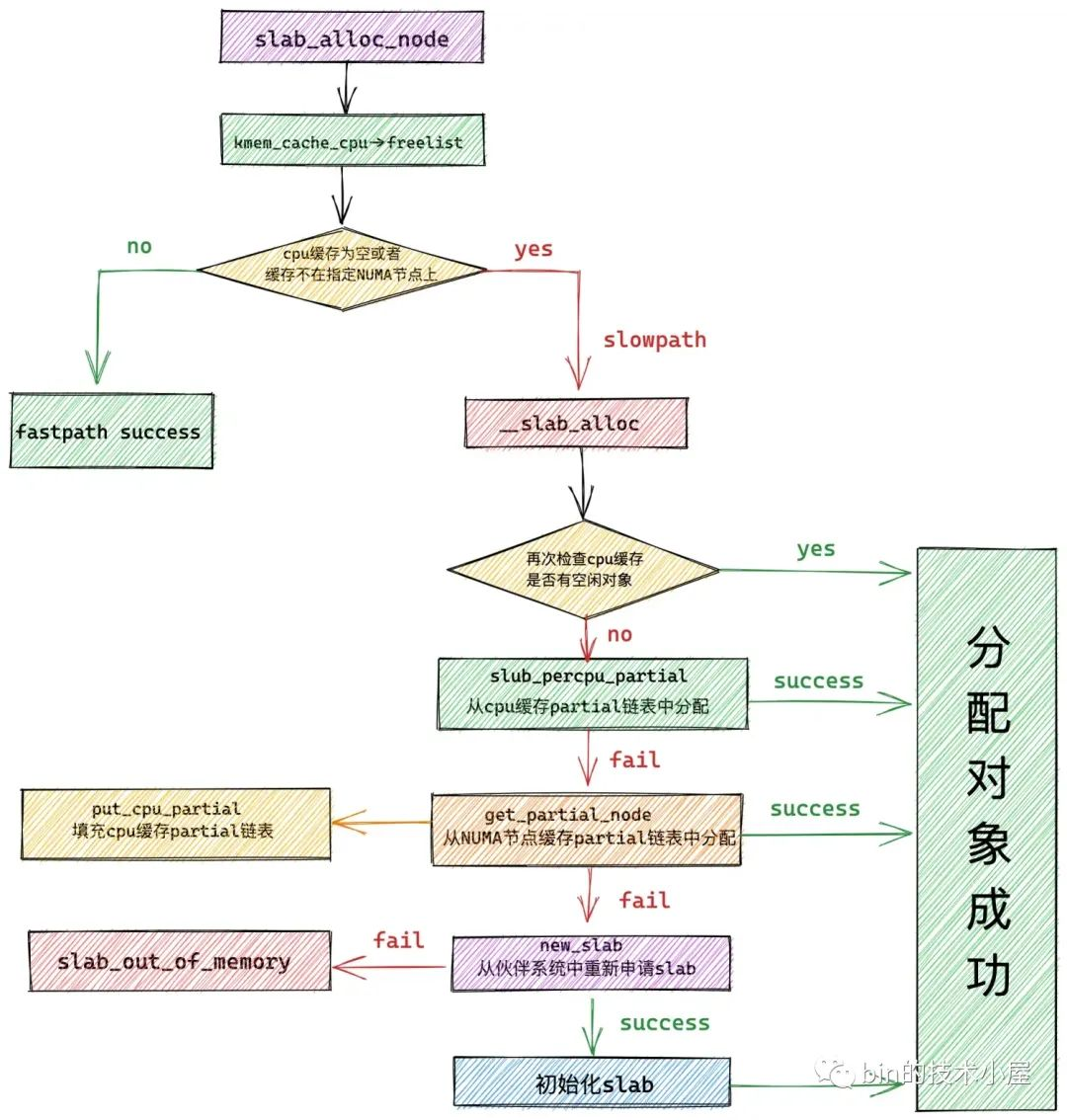
在 slab 記憶體池創建出來之後,隨後筆者又深入介紹了 slab 記憶體池如何分配記憶體塊的相關源碼實現,其中詳細介紹了在多種不同場景下,內核如何處理記憶體塊的分配。
在我們清除了 slab 記憶體池如何分配記憶體塊的源碼實現之後,緊接著筆者又介紹了 slab 記憶體池如何進行記憶體塊的回收,回收過程要比分配過程複雜很多,同樣也涉及到多種複雜場景的處理:
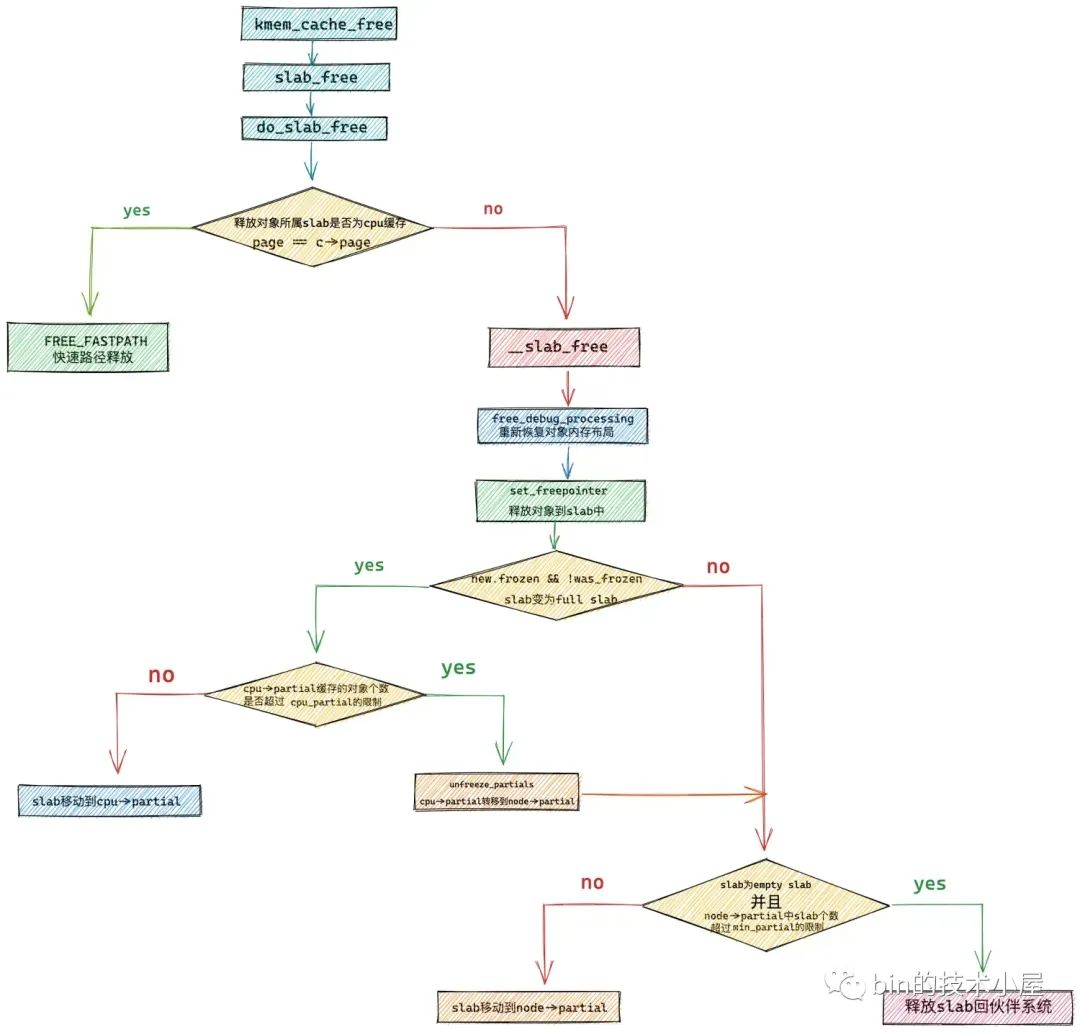
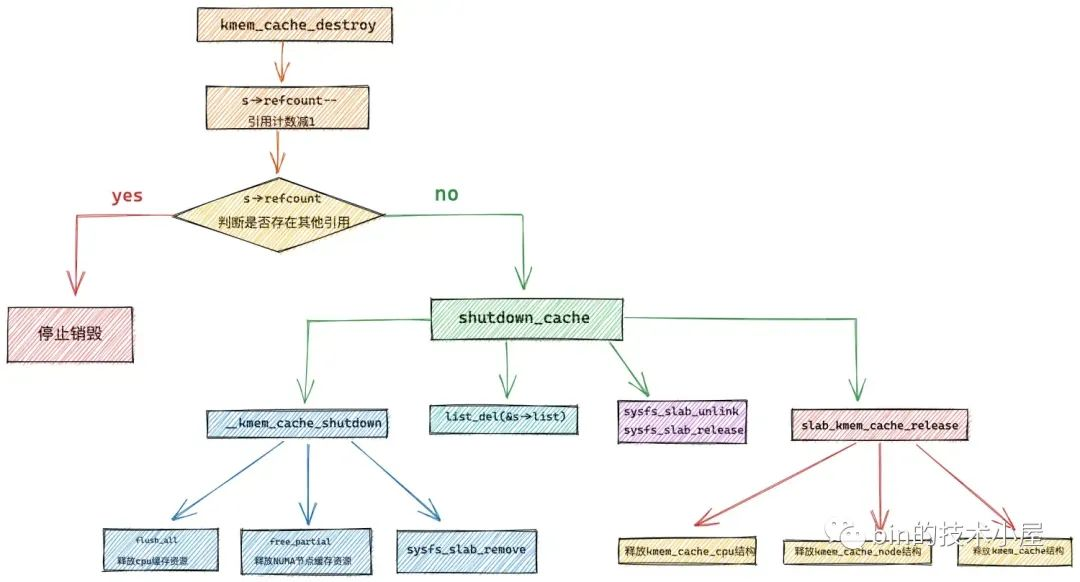
最後筆者介紹了 slab 記憶體池的銷毀過程:
好了,整個 slab cache 相關的內容到此就結束了,感謝大家的收看,我們下篇文章見~~~


