
存儲過程(stored procedure)有時候稱為sproc,它是真正的腳本-或者更準確的說,他是批處理(batch)-它存儲於資料庫中,而不是淡出的文件中。無論如何,這個比較並不是很確定。存儲過程有輸出參數,輸入參數已及返回值等。而腳本不會有這些內容。 存儲過程基本語法:CREATE PROC ...
存儲過程(stored procedure)有時候稱為sproc,它是真正的腳本-或者更準確的說,他是批處理(batch)-它存儲於資料庫中,而不是淡出的文件中。無論如何,這個比較並不是很確定。存儲過程有輸出參數,輸入參數已及返回值等。而腳本不會有這些內容。
存儲過程基本語法:CREATE PROCEDURE|PROC <sproc name>
[<parameter name> <data type> [VARYING][<default value>] [OUTPUT]],
[<parameter name> <data type> [VARYING][<default value>] [OUTPUT]]
[........,n]
[WITH PECOMPILE|ENCRYPTION|EXECUTE AS{ CALLER |SELF|OWNER|<'user name '>}]
[ FOR REPLICATION]
AS
<code>|EXTERNAL NAME<assembly name>.<assembly class>.<method>
試一試最簡單基本存儲過程:
USE AdventureWorks GO --切換到AdventureWorks資料庫 CREATE PROCEDURE sp_Employee AS SELECT * FROM HumanResources.Employee GO--提前處理語句。防止下麵EXEC sp_Employee拋出錯誤 exec sp_Employee
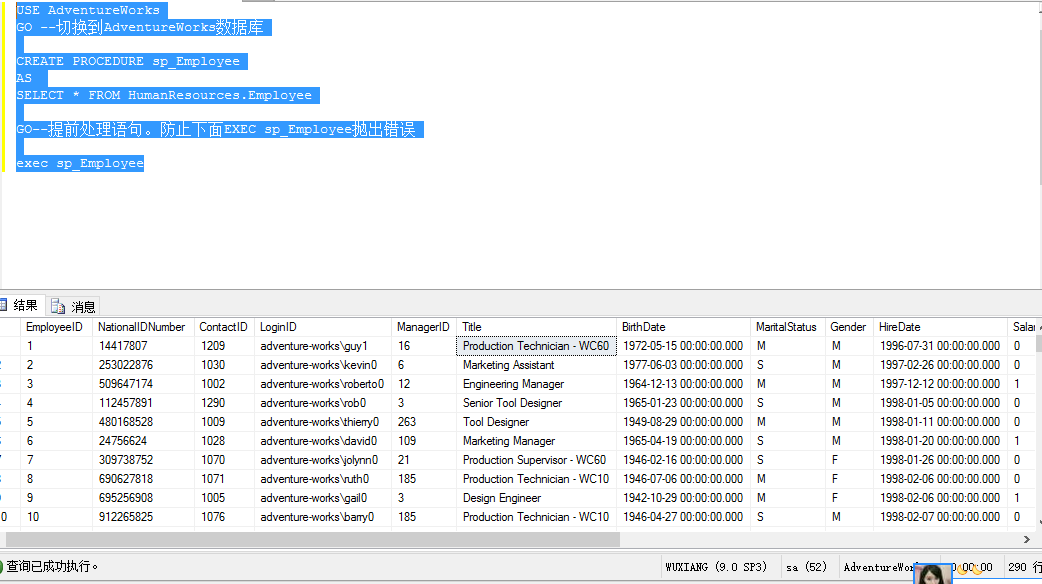
看起來是不是很簡單。返回一個data表。沒有參數的存儲過程。
使用ALTER 修改存儲過程。
在使用T-SQL編輯存儲過程需要註意,這是完全替換現有的存儲過程。使用ALTER PROC還是CREATE PROC語句的唯一缺點包括以下幾點:
1.ALTER PROC:期望找到一個已有的存儲過程,而CREATE不是。
2.ALTER PROC:保留存儲過程上已經建立的任何許可權。它在系統對象中保留了相同的對象ID並允許保留依賴關係。如:過程A調用過程B,並刪除和重新創建了過程B,那麼不能在看到這二者的依賴關係了。如果使用ALTER ,依賴關係仍然存在。
3.ALTER PROC:在可能調用被修改的存儲過程的其他對象上保留任何依賴信息(這一條也是最重要的)。
刪除儲存過程:這個最簡單不過了。還是刪除資料庫、表和視圖等對象通用語句,
DROP PROC|PROCEDURE <sporcedure name> 就完成整個刪除工作了。
使用參數化存儲過程:
聲明參數是需要下麵2-4條信息:名稱,數據類型,預設值,反向。其語法:@parameter_name [AS] datatype [=defalut|NULL] [VARYING ] [OUTPUT|OUT]
創建一個和前面不同版本的存儲過程
USE AdventureWorks GO --切換到AdventureWorks資料庫 CREATE PROCEDURE sp_Contact @LastName nvarchar(50) AS SELECT * FROM Person.Contact WHERE LastName LIKE '%'+@LastName+'%' exec sp_Contact --未提供值, 消息 201,級別 16,狀態 4,過程 sp_Contact,第 0 行 過程或函數 'sp_Contact' 需要參數 '@LastName',但未提供該參數。 exec sp_Contact 'ad' --查詢完成共233條信息
如何獲取輸出參數並有返回值:在做分頁查詢時候會用到這種。先看下存儲過程


CREATE PROCEDURE sp_ContactPage @pageStart int, @pageEnd int, @pageCount int OUTPUT AS begin SELECT @pageCount=count(1) FROM Person.Contact;--獲取總條數。並且設置@pageCount的值 WITH Contact as( select row_number() over(order by ContactID desc) as RowNumber,* from Person.Contact) SELECT * from Contact where RowNumber between @pageStart and @pageEnd; --分頁查詢,在sql server 2012有更簡單分頁查詢。這是SQL SERVER 2005以後支持。2000需要子查詢。博客後面會介紹漏掉的子查詢和索引,SQL腳本這些。 end declare @rowcount int exec sp_ContactPage 0,20,@rowcount output select @rowcountView Code
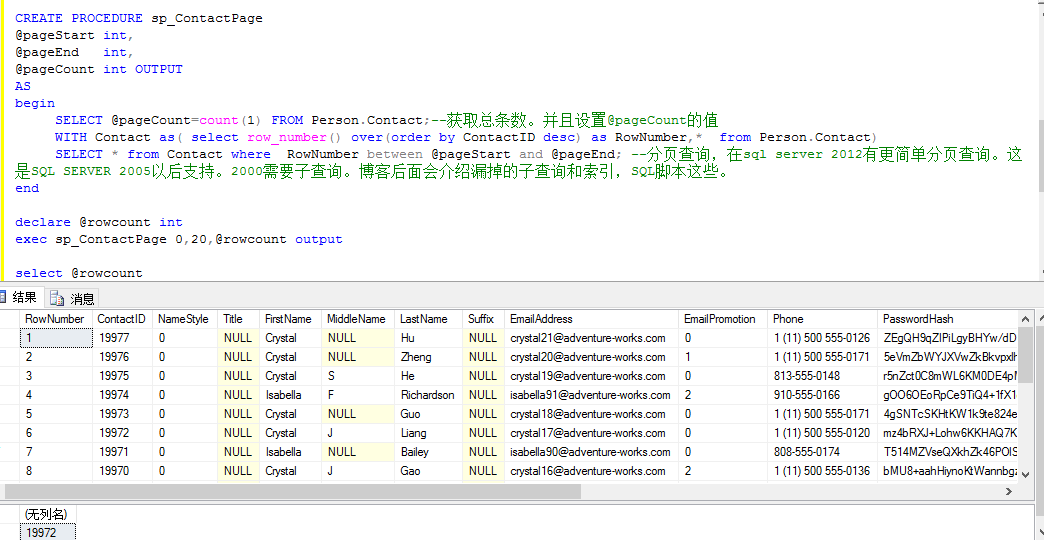
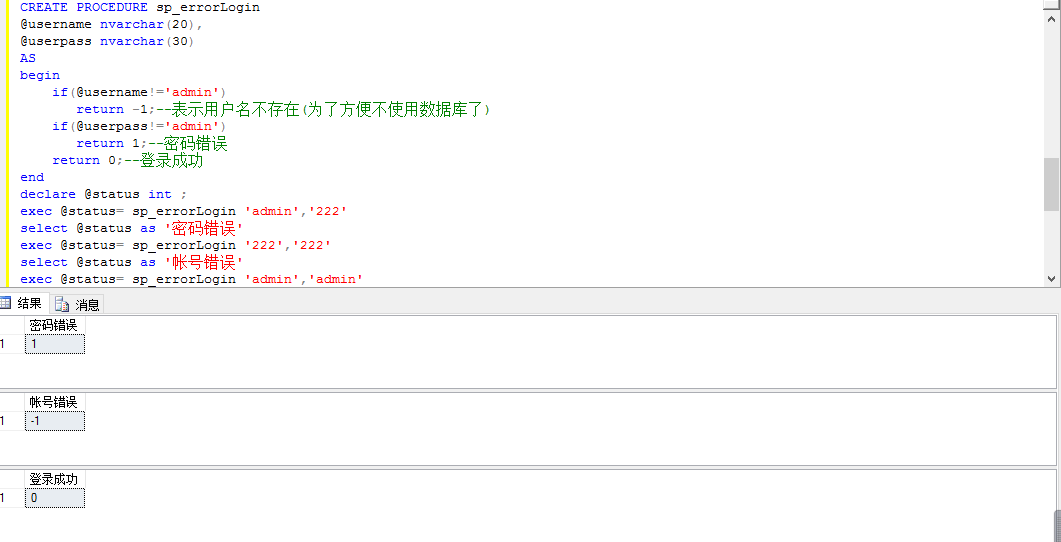
如何使用返回值來獲取錯誤結果:
CREATE PROCEDURE sp_errorLogin @username nvarchar(20), @userpass nvarchar(30) AS begin if(@username!='admin') return -1;--表示用戶名不存在(為了方便不使用資料庫了) if(@userpass!='admin') return 1;--密碼錯誤 return 0;--登錄成功 end declare @status int ; exec @status= sp_errorLogin 'admin','222' select @status as '密碼錯誤' exec @status= sp_errorLogin '222','222' select @status as '帳號錯誤' exec @status= sp_errorLogin 'admin','admin' select @status as '登錄成功'View Code
後面章節講@@Error和try....cacth的異常處理,我把它們放在事務里講了。因為事務發生錯誤就會rollback tran。
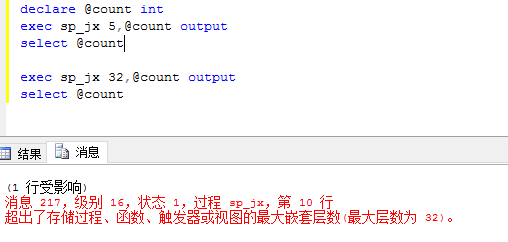
遞歸:編程很少會用到遞歸,有時候遞歸是最有效的解決方案,如菜單樹。遞歸是指一條代碼自身調用自身的情況,危險性也是很明顯-就是進行死迴圈的調用。如何調用取決你或者代碼。SQL遞歸調用最多只有32次,超過32次就會拋出異常。
最經典的就是階乘如:5的階乘120它是如何實現 5*4*3*2*1。
CREATE proc sp_jx @size int , @count int output AS declare @temp_s int ; declare @temp_c int ; if @size >=1 begin select @temp_s=@size-1; exec sp_jx @temp_s,@temp_c output select @count= @size*@temp_c; end else select @count=1 return GO declare @count int exec sp_jx 5,@count output select @count exec sp_jx 32,@count output select @countView Code
使用存儲過程的時機:(優點)
1.通常更佳的性能。
2.可以作為安全隔離層(控制數據訪問和跟新方式)
3.可以重用代碼
4.劃分代碼
5.根據在運行時建立的動態而可以靈活執行
缺點:
移植性差,不能跨平臺移植
在一些情況下可能因為錯誤的執行計劃而被鎖定(實際影響性能).
未完待續。


