
Java實現BP神經網路,內含BP神經網路類,採用MNIST數據集,包含伺服器和客戶端程式,可在伺服器訓練後使客戶端直接使用訓練結果,界面有畫板,可以手寫數字 ...
Java實現BP神經網路MNIST手寫數字識別
如果需要源碼,請在下方評論區留下郵箱,我看到就會發過去
一、神經網路的構建
(1):構建神經網路層次結構
由訓練集數據可知,手寫輸入的數據維數為784維,而對應的輸出結果為分別為0-9的10個數字,所以根據訓練集的數據可知,在構建的神經網路的輸入層的神經元的節點個數為784個,而對應的輸出層的神經元個數為10個。隱層可選擇單層或多層。
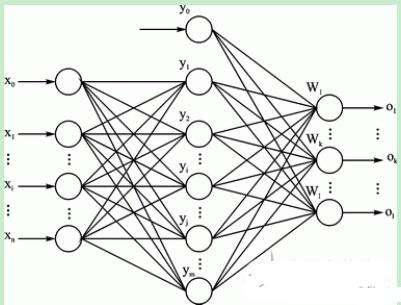
(2):確定隱層中的神經元的個數
因為對於隱層的神經元個數的確定目前還沒有什麼比較完美的解決方案,所以對此經過自己查閱書籍和上網查閱資料,有以下的幾種經驗方式來確定隱層的神經元的個數,方式分別如下所示:
-
一般取(輸入+輸出)/2
-
隱層一般小於輸入層
3)(輸入層+1)/2
-
log(輸入層)
-
log(輸入層)+10
實驗得到以第五種的方式得到的測試結果相對較高。
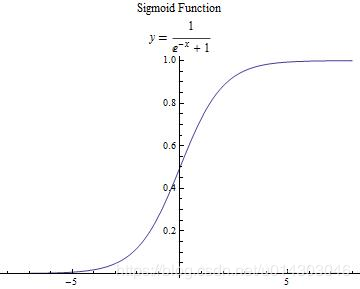
(3):設置神經元的激活函數
在《機器學習》的書中介紹了兩種比較常用的函數,分別是階躍函數和Sigmoid函數。最後自己採用了後者函數。
(4):初始化輸入層和隱層之間神經元間的權值信息
採用的是使用簡單的隨機數分配的方法,並且兩層之間的神經元權值是通過二維數組進行保留,數組的索引就代表著兩層對應的神經元的索引信息
(5):初始化隱層和輸出層之間神經元間的權值信息
採用的是使用簡單的隨機數分配的方法,並且兩層之間的神經元權值是通過二維數組進行保留,數組的索引就代表著兩層對應的神經元的索引信息
(6):讀取CSV測試集表格信息,並載入到程式用數據保存,其中將每個維數的數據都換成了0和1的二進位數進行處理。
(7):讀取CSV測試集結果表格信息,並載入到程式用數據保存
(8):計算輸入層與隱層中隱層神經元的閾值
這裡主要是採用了下麵的方法:
Sum=sum+weight[i][j] * layer0[i];
參數的含義:將每個輸入層中的神經元與神經元的權值信息weight[i][j]乘以對應的輸入層神經元的閾值累加,然後再調用激活函數得到對應的隱層神經元的閾值。
(9):計算隱層與輸出層中輸出層的神經元的閾值
方法和上面的類似,只是相對應的把權值信息進行了修改即可。
(10):計算誤差逆傳播(輸出層的逆誤差)
採用書上P103頁的方法(西瓜書)
(11):計算誤差傳播(隱層的逆誤差)
採用書上P103頁的方法(西瓜書)
(12):更新各層神經元之間的權值信息
double newVal = momentum * prevWeight[j][i] + eta * delta[i] * layer[j];
參數:其中設置momentum 為0.9,設置eta 為0.25,prevWeight[j][i]表示神經元之間的權值,layer[j]和delta[i]表示兩層不同神經元的閾值。
(13):迴圈迭代訓練5次
(14):輸入測試集數據
(15):輸出測試集預測結果和實際結果進行比較,得到精確度
此處放一個多隱層BP神經網路的類(自己寫的,有錯誤請指出):
/**
* BP神經網路類
* 使用了附加動量法進行優化
* 主要使用方法:
* 初始化: BP bp = new BP(new int[]{int,int*n,int}) //第一個int表示輸入層,中間n個int表示隱藏層,最後一個int表示輸出層
* 訓練: bp.train(double[],double[]) //第一個double[]表示輸入,第二個double[]表示期望輸出
* 測試 int result = bp.test(double[]) //參數表示輸入,返回值表示輸出層最大權值
* 另有設置學習率和動量參數方法
*/
import java.util.Random;
public class BP {
private final double[][] layers;//輸入層、隱含層、輸出層
private final double[][] deltas;//每層誤差
private final double[][][] weights;//權值
private final double[][][] prevUptWeights;//更新之前的權值信息
private final double[] target; //預測的輸出內容
private double eta; //學習率
private double momentum; //動量參數
private final Random random; //主要是對權值採取的是隨機產生的方法
//初始化
public BP(int[] size, double eta, double momentum) {
int len = size.length;
//初始化每層
layers = new double[len][];
for(int i = 0; i<len; i++) {
layers[i] = new double[size[i] + 1];
}
//初始化預測輸出
target = new double[size[len - 1] + 1];
//初始化隱藏層和輸出層的誤差
deltas = new double[len - 1][];
for(int i = 0; i < (len - 1); i++) {
deltas[i] = new double[size[i + 1] + 1];
}
//使每次產生的隨機數都是第一次的分配,這是有參數和沒參數的區別
random = new Random(100000);
//初始化權值
weights = new double[len - 1][][];
for(int i = 0; i < (len - 1); i++) {
weights[i] = new double[size[i] + 1][size[i + 1] + 1];
}
randomizeWeights(weights);
//初始化更新前的權值
prevUptWeights = new double[len - 1][][];
for(int i = 0; i < (len - 1); i++) {
prevUptWeights[i] = new double[size[i] + 1][size[i + 1] + 1];
}
this.eta = eta; //學習率
this.momentum = momentum; //動態量
}
//隨機產生神經元之間的權值信息
private void randomizeWeights(double[][][] matrix) {
for (int i = 0, len = matrix.length; i != len; i++) {
for (int j = 0, len2 = matrix[i].length; j != len2; j++) {
for(int k = 0, len3 = matrix[i][j].length; k != len3; k++) {
double real = random.nextDouble(); //隨機分配著產生0-1之間的值
matrix[i][j][k] = random.nextDouble() > 0.5 ? real : -real;
}
}
}
}
//初始化輸入層,隱含層,和輸出層
public BP(int[] size) {
this(size, 0.25, 0.9);
}
//訓練數據
public void train(double[] trainData, double[] target) {
loadValue(trainData,layers[0]); //載入輸入的數據
loadValue(target,this.target); //載入輸出的結果數據
forward(); //向前計算神經元權值(先算輸入到隱含層的,然後再算隱含到輸出層的權值)
calculateDelta(); //計算誤差逆傳播值
adjustWeight(); //調整更新神經元的權值
}
//載入數據
private void loadValue(double[] value,double [] layer) {
if (value.length != layer.length - 1)
throw new IllegalArgumentException("Size Do Not Match.");
System.arraycopy(value, 0, layer, 1, value.length); //調用系統複製數組的方法(存放輸入的訓練數據)
}
//向前計算(先算輸入到隱含層的,然後再算隱含到輸出層的權值)
private void forward() {
//計算隱含層到輸出層的權值
for(int i = 0; i < (layers.length - 1); i++) {
forward(layers[i], layers[i+1], weights[i]);
}
}
//計算每一層的誤差(因為在BP中,要達到使誤差最小)(就是逆傳播演算法,書上有P101)
private void calculateDelta() {
outputErr(deltas[deltas.length-1],layers[layers.length - 1],target); //計算輸出層的誤差(因為要反過來算,所以先算輸出層的)
for(int i = (layers.length - 1); i > 1; i--) {
hiddenErr(deltas[i - 2/*輸入層沒有誤差*/],layers[i - 1],deltas[i - 1],weights[i - 1]); //計算隱含層的誤差
}
}
//更新每層中的神經元的權值信息
private void adjustWeight() {
for(int i = (layers.length - 1); i > 0; i--) {
adjustWeight(deltas[i - 1], layers[i - 1], weights[i - 1], prevUptWeights[i - 1]);
}
}
//向前計算各個神經元的權值(layer0:某層的數據,layer1:下一層的內容,weight:某層到下一層的神經元的權值)
private void forward(double[] layer0, double[] layer1, double[][] weight) {
layer0[0] = 1.0;//給偏置神經元賦值為1(實際上添加了layer1層每個神經元的闕值)簡直漂亮!!!
for (int j = 1, len = layer1.length; j != len; ++j) {
double sum = 0;//保存權值
for (int i = 0, len2 = layer0.length; i != len2; ++i) {
sum += weight[i][j] * layer0[i];
}
layer1[j] = sigmoid(sum); //調用神經元的激活函數來得到結果(結果肯定是在0-1之間的)
}
}
//計算輸出層的誤差(delte:誤差,output:輸出,target:預測輸出)
private void outputErr(double[] delte, double[] output,double[] target) {
for (int idx = 1, len = delte.length; idx != len; ++idx) {
double o = output[idx];
delte[idx] = o * (1d - o) * (target[idx] - o);
}
}
//計算隱含層的誤差(delta:本層誤差,layer:本層,delta1:下一層誤差,weights:權值)
private void hiddenErr(double[] delta, double[] layer, double[] delta1, double[][] weights) {
for (int j = 1, len = delta.length; j != len; ++j) {
double o = layer[j]; //神經元權值
double sum = 0;
for (int k = 1, len2 = delta1.length; k != len2; ++k) //由輸出層來反向計算
sum += weights[j][k] * delta1[k];
delta[j] = o * (1d - o) * sum;
}
}
//更新每層中的神經元的權值信息(這也就是不斷的訓練過程)
private void adjustWeight(double[] delta, double[] layer, double[][] weight, double[][] prevWeight) {
layer[0] = 1;
for (int i = 1, len = delta.length; i != len; ++i) {
for (int j = 0, len2 = layer.length; j != len2; ++j) {
//通過公式計算誤差限=(動態量*之前的該神經元的閾值+學習率*誤差*對應神經元的閾值),來進行更新權值
double newVal = momentum * prevWeight[j][i] + eta * delta[i] * layer[j];
weight[j][i] += newVal; //得到新的神經元之間的權值
prevWeight[j][i] = newVal; //保存這一次得到的權值,方便下一次進行更新
}
}
}
//我這裡用的是sigmoid激活函數,當然也可以用階躍函數,看自己選擇吧
private double sigmoid(double val) {
return 1d / (1d + Math.exp(-val));
}
//測試神經網路
public int test(double[] inData) {
if (inData.length != layers[0].length - 1)
throw new IllegalArgumentException("Size Do Not Match.");
System.arraycopy(inData, 0, layers[0], 1, inData.length);
forward();
return getNetworkOutput();
}
//返回最後的輸出層的結果
private int getNetworkOutput() {
int len = layers[layers.length - 1].length;
double[] temp = new double[len - 1];
for (int i = 1; i != len; i++)
temp[i - 1] = layers[layers.length - 1][i];
//獲得最大權值下標
double max = temp[0];
int idx = -1;
for (int i = 0; i <temp.length; i++) {
if (temp[i] >= max) {
max = temp[i];
idx = i;
}
}
return idx;
}
//設置學習率
public void setEta(double eta) {
this.eta = eta;
}
//設置動量參數
public void setMomentum(double momentum){
this.momentum = momentum;
}
}
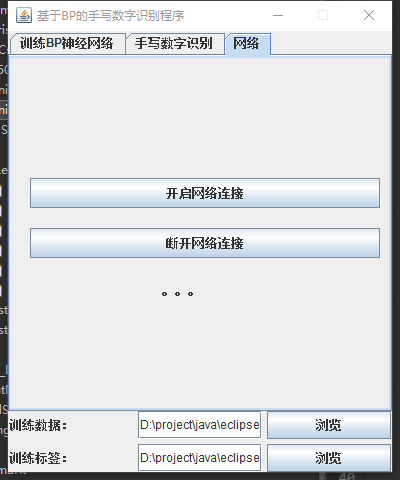
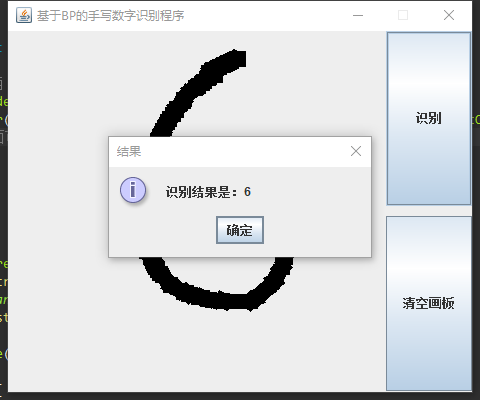
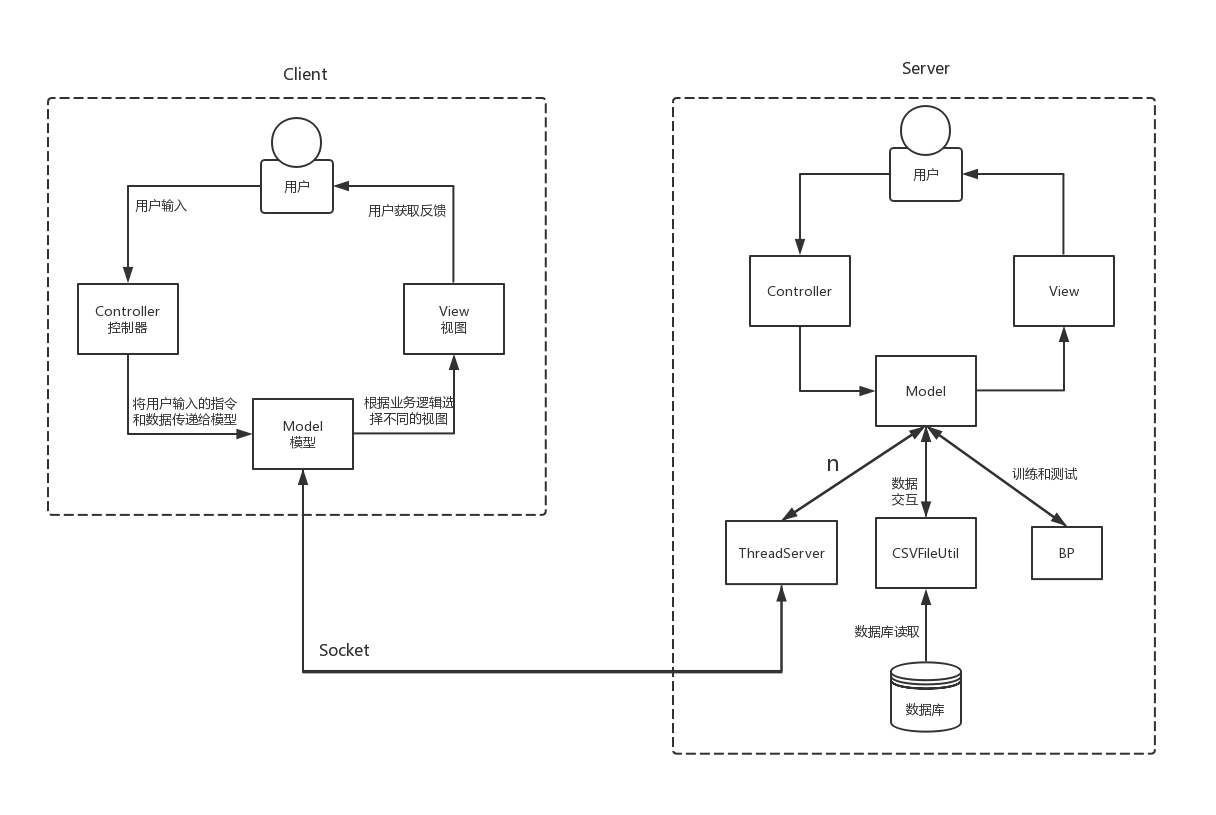
二、系統架構
由於BP神經網路訓練過程時間較長,所以採用客戶端伺服器(C/S)的形式,在伺服器進行訓練,在客戶端直接進行識別,使用套接字進行通訊。
伺服器:
客戶端:
採用MVC架構:
-
Model(模型)表示應用程式核心。
-
View(視圖)顯示數據。
-
Controller(控制器)處理輸入。
MNIST數字集經過整理存儲在CSV文件中。
以下是系統架構:
三、源碼
如果需要源碼,請在下方評論區留下郵箱,我看到就會發過去

