
上篇文章談到BlockingQueue的使用場景,並重點分析了ArrayBlockingQueue的實現原理,瞭解到ArrayBlockingQueue底層是基於數組實現的阻塞隊列。 但是BlockingQueue的實現類中,有一種阻塞隊列比較特殊,就是SynchronousQueue(同步移交隊... ...
上篇文章談到BlockingQueue的使用場景,並重點分析了ArrayBlockingQueue的實現原理,瞭解到ArrayBlockingQueue底層是基於數組實現的阻塞隊列。
但是BlockingQueue的實現類中,有一種阻塞隊列比較特殊,就是SynchronousQueue(同步移交隊列),隊列長度為0。
作用就是一個線程往隊列放數據的時候,必須等待另一個線程從隊列中取走數據。同樣,從隊列中取數據的時候,必須等待另一個線程往隊列中放數據。
這樣特殊的隊列,有什麼應用場景呢?
1. SynchronousQueue用法
先看一個SynchronousQueue的簡單用例:
/**
* @author 一燈架構
* @apiNote SynchronousQueue示例
**/
public class SynchronousQueueDemo {
public static void main(String[] args) throws InterruptedException {
// 1. 創建SynchronousQueue隊列
BlockingQueue<Integer> synchronousQueue = new SynchronousQueue<>();
// 2. 啟動一個線程,往隊列中放3個元素
new Thread(() -> {
try {
System.out.println(Thread.currentThread().getName() + " 入隊列 1");
synchronousQueue.put(1);
Thread.sleep(1);
System.out.println(Thread.currentThread().getName() + " 入隊列 2");
synchronousQueue.put(2);
Thread.sleep(1);
System.out.println(Thread.currentThread().getName() + " 入隊列 3");
synchronousQueue.put(3);
} catch (InterruptedException e) {
e.printStackTrace();
}
}).start();
// 3. 等待1000毫秒
Thread.sleep(1000L);
// 4. 再啟動一個線程,從隊列中取出3個元素
new Thread(() -> {
try {
System.out.println(Thread.currentThread().getName() + " 出隊列 " + synchronousQueue.take());
Thread.sleep(1);
System.out.println(Thread.currentThread().getName() + " 出隊列 " + synchronousQueue.take());
Thread.sleep(1);
System.out.println(Thread.currentThread().getName() + " 出隊列 " + synchronousQueue.take());
} catch (InterruptedException e) {
e.printStackTrace();
}
}).start();
}
}
輸出結果:
Thread-0 入隊列 1
Thread-1 出隊列 1
Thread-0 入隊列 2
Thread-1 出隊列 2
Thread-0 入隊列 3
Thread-1 出隊列 3
從輸出結果中可以看到,第一個線程Thread-0往隊列放入一個元素1後,就被阻塞了。直到第二個線程Thread-1從隊列中取走元素1後,Thread-0才能繼續放入第二個元素2。
由於SynchronousQueue是BlockingQueue的實現類,所以也實現類BlockingQueue中幾組抽象方法:
為了滿足不同的使用場景,BlockingQueue設計了很多的放數據和取數據的方法。
| 操作 | 拋出異常 | 返回特定值 | 阻塞 | 阻塞一段時間 |
|---|---|---|---|---|
| 放數據 | add |
offer |
put |
offer(e, time, unit) |
| 取數據 | remove |
poll |
take |
poll(time, unit) |
| 查看數據(不刪除) | element() |
peek() |
不支持 | 不支持 |
這幾組方法的不同之處就是:
- 當隊列滿了,再往隊列中放數據,add方法拋異常,offer方法返回false,put方法會一直阻塞(直到有其他線程從隊列中取走數據),offer(e, time, unit)方法阻塞指定時間然後返回false。
- 當隊列是空,再從隊列中取數據,remove方法拋異常,poll方法返回null,take方法會一直阻塞(直到有其他線程往隊列中放數據),poll(time, unit)方法阻塞指定時間然後返回null。
- 當隊列是空,再去隊列中查看數據(並不刪除數據),element方法拋異常,peek方法返回null。
工作中使用最多的就是offer、poll阻塞指定時間的方法。
2. SynchronousQueue應用場景
SynchronousQueue的特點:
隊列長度是0,一個線程往隊列放數據,必須等待另一個線程取走數據。同樣,一個線程從隊列中取數據,必須等待另一個線程往隊列中放數據。
這種特殊的實現邏輯有什麼應用場景呢?
我的理解就是,如果你希望你的任務需要被快速處理,就可以使用這種隊列。
Java線程池中的newCachedThreadPool(帶緩存的線程池)底層就是使用SynchronousQueue實現的。
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>());
}
newCachedThreadPool線程池的核心線程數是0,最大線程數是Integer的最大值,線程存活時間是60秒。
如果你使用newCachedThreadPool線程池,你提交的任務會被更快速的處理,因為你每次提交任務,都會有一個空閑的線程等著處理任務。如果沒有空閑的線程,也會立即創建一個線程處理你的任務。
你想想,這處理效率,杠杠滴!
當然也有弊端,如果你提交了太多的任務,導致創建了大量的線程,這些線程都在競爭CPU時間片,等待CPU調度,處理任務速度也會變慢,所以在使用過程中也要綜合考慮。
3. SynchronousQueue源碼解析
3.1 SynchronousQueue類屬性
public class SynchronousQueue<E> extends AbstractQueue<E> implements BlockingQueue<E> {
// 轉換器,取數據和放數據的核心邏輯都在這個類裡面
private transient volatile Transferer<E> transferer;
// 預設的構造方法(使用非公平隊列)
public SynchronousQueue() {
this(false);
}
// 有參構造方法,可以指定是否使用公平隊列
public SynchronousQueue(boolean fair) {
transferer = fair ? new TransferQueue<E>() : new TransferStack<E>();
}
// 轉換器實現類
abstract static class Transferer<E> {
abstract E transfer(E e, boolean timed, long nanos);
}
// 基於棧實現的非公平隊列
static final class TransferStack<E> extends Transferer<E> {
}
// 基於隊列實現的公平隊列
static final class TransferQueue<E> extends Transferer<E> {
}
}
可以看到SynchronousQueue預設的無參構造方法,內部使用的是基於棧實現的非公平隊列,當然也可以調用有參構造方法,傳參是true,使用基於隊列實現的公平隊列。
// 使用非公平隊列(基於棧實現)
BlockingQueue<Integer> synchronousQueue = new SynchronousQueue<>();
// 使用公平隊列(基於隊列實現)
BlockingQueue<Integer> synchronousQueue = new SynchronousQueue<>(true);
本次就常用的棧實現來剖析SynchronousQueue的底層實現原理。
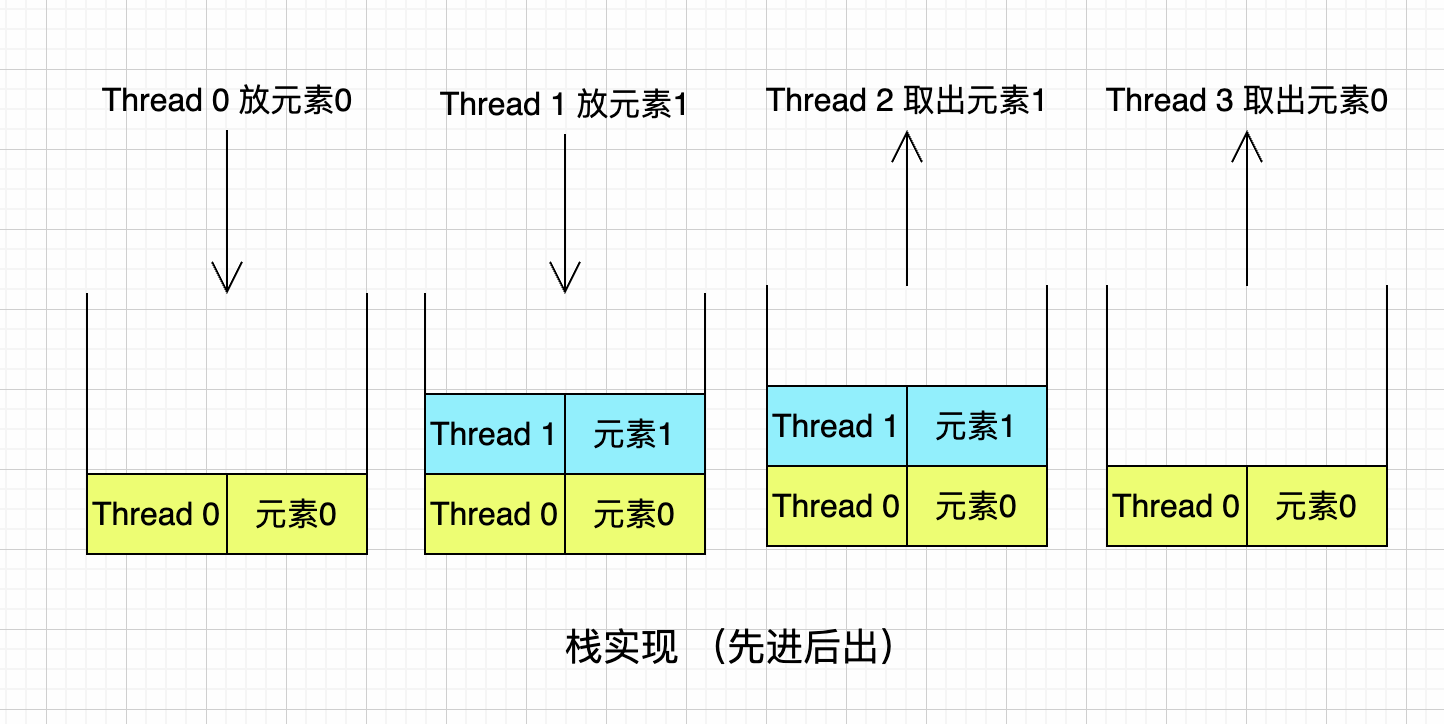
3.2 棧底層結構
棧結構,是非公平的,遵循先進後出。
使用個case測試一下:
/**
* @author 一燈架構
* @apiNote SynchronousQueue示例
**/
public class SynchronousQueueDemo {
public static void main(String[] args) throws InterruptedException {
// 1. 創建SynchronousQueue隊列
SynchronousQueue<Integer> synchronousQueue = new SynchronousQueue<>();
// 2. 啟動一個線程,往隊列中放1個元素
new Thread(() -> {
try {
System.out.println(Thread.currentThread().getName() + " 入隊列 0");
synchronousQueue.put(0);
} catch (InterruptedException e) {
e.printStackTrace();
}
}).start();
// 3. 等待1000毫秒
Thread.sleep(1000L);
// 4. 啟動一個線程,往隊列中放1個元素
new Thread(() -> {
try {
System.out.println(Thread.currentThread().getName() + " 入隊列 1");
synchronousQueue.put(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
}).start();
// 5. 等待1000毫秒
Thread.sleep(1000L);
// 6. 再啟動一個線程,從隊列中取出1個元素
new Thread(() -> {
try {
System.out.println(Thread.currentThread().getName() + " 出隊列 " + synchronousQueue.take());
} catch (InterruptedException e) {
e.printStackTrace();
}
}).start();
// 7. 等待1000毫秒
Thread.sleep(1000L);
// 8. 再啟動一個線程,從隊列中取出1個元素
new Thread(() -> {
try {
System.out.println(Thread.currentThread().getName() + " 出隊列 " + synchronousQueue.take());
} catch (InterruptedException e) {
e.printStackTrace();
}
}).start();
}
}
輸出結果:
Thread-0 入隊列 0
Thread-1 入隊列 1
Thread-2 出隊列 1
Thread-3 出隊列 0
從輸出結果中可以看出,符合棧結構先進後出的順序。
3.3 棧節點源碼
棧中的數據都是由一個個的節點組成的,先看一下節點類的源碼:
// 節點
static final class SNode {
// 節點值(取數據的時候,該欄位為null)
Object item;
// 存取數據的線程
volatile Thread waiter;
// 節點模式
int mode;
// 匹配到的節點
volatile SNode match;
// 後繼節點
volatile SNode next;
}
-
item
節點值,只在存數據的時候用。取數據的時候,這個值是null。
-
waiter
存取數據的線程,如果沒有對應的接收線程,這個線程會被阻塞。
-
mode
節點模式,共有3種類型:
類型值 類型描述 類型的作用 0 REQUEST 表示取數據 1 DATA 表示存數據 2 FULFILLING 表示正在等待執行(比如取數據的線程,等待其他線程放數據)
3.4 put/take流程
放數據和取數據的邏輯,在底層復用的是同一個方法,以put/take方法為例,另外兩個放數據的方法,add和offer方法底層實現是一樣的。
先看一下數據流轉的過程,方便理解源碼。
還是以上面的case為例:
- Thread0先往SynchronousQueue隊列中放入元素0
- Thread1再往SynchronousQueue隊列放入元素1
- Thread2從SynchronousQueue隊列中取出一個元素
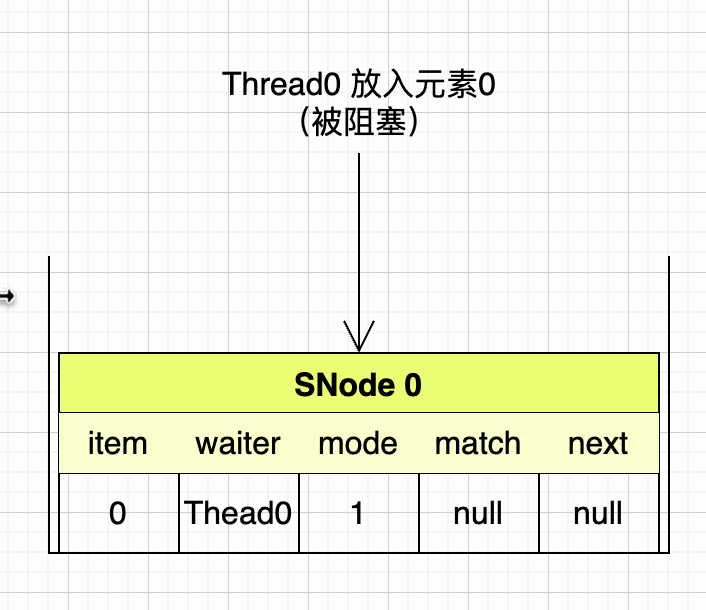
第一步:Thread0先往SynchronousQueue隊列中放入元素0
把本次操作組裝成SNode壓入棧頂,item是元素0,waiter是當前線程Thread0,mode是1表示放入數據。
第二步:Thread1再往SynchronousQueue隊列放入元素1
把本次操作組裝成SNode壓入棧頂,item是元素1,waiter是當前線程Thread1,mode是1表示放入數據,next是SNode0。

第三步:Thread2從SynchronousQueue隊列中取出一個元素
這次的操作比較複雜,也是先把本次的操作包裝成SNode壓入棧頂。
item是null(取數據的時候,這個欄位沒有值),waiter是null(當前線程Thread2正在操作,所以不用賦值了),mode是2表示正在操作(即將跟後繼節點進行匹配),next是SNode1。
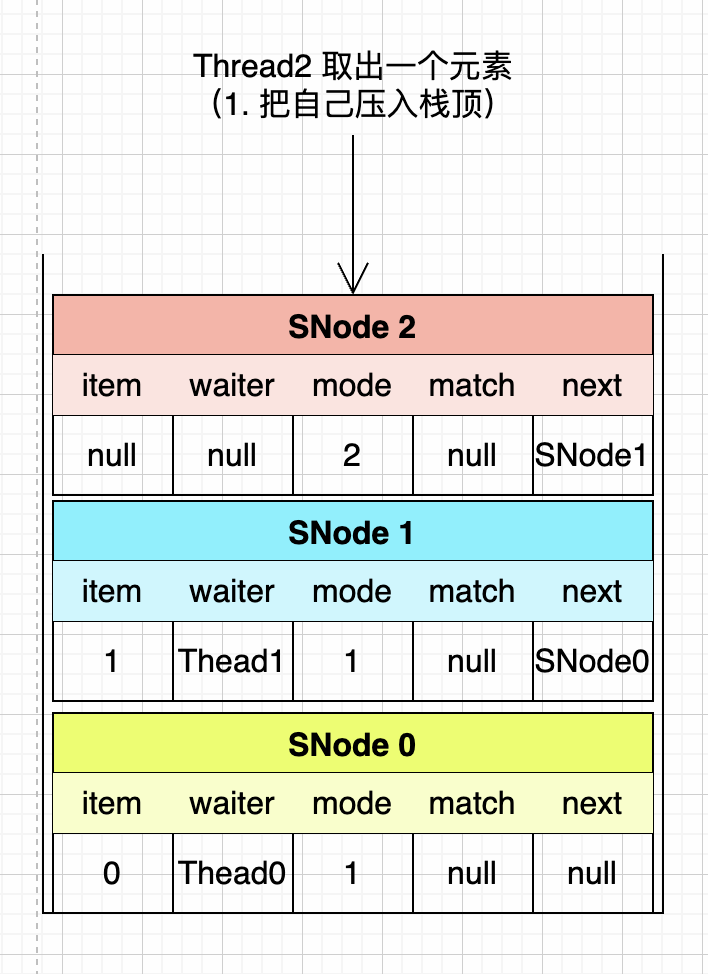
然後,Thread2開始把棧頂的兩個節點進行匹配,匹配成功後,就把SNode2賦值給SNode1的match屬性,喚醒SNode1中的Thread1線程,然後彈出SNode2節點和SNode1節點。


3.5 put/take源碼實現
看完 了put/take流程,再來看源碼就簡單多了。
先看一下put方法源碼:
// 放數據
public void put(E e) throws InterruptedException {
// 不允許放null元素
if (e == null)
throw new NullPointerException();
// 調用轉換器實現類,放元素
if (transferer.transfer(e, false, 0) == null) {
// 如果放數據失敗,就中斷當前線程,並拋出異常
Thread.interrupted();
throw new InterruptedException();
}
}
核心邏輯都在transfer方法中,代碼很長,理清邏輯後,也很容易理解。
// 取數據和放數據操作,共用一個方法
E transfer(E e, boolean timed, long nanos) {
SNode s = null;
// e為空,說明是取數據,否則是放數據
int mode = (e == null) ? REQUEST : DATA;
for (; ; ) {
SNode h = head;
// 1. 如果棧頂節點為空,或者棧頂節點類型跟本次操作相同(都是取數據,或者都是放數據)
if (h == null || h.mode == mode) {
// 2. 判斷節點是否已經超時
if (timed && nanos <= 0) {
// 3. 如果棧頂節點已經被取消,就刪除棧頂節點
if (h != null && h.isCancelled())
casHead(h, h.next);
else
return null;
// 4. 把本次操作包裝成SNode,壓入棧頂
} else if (casHead(h, s = snode(s, e, h, mode))) {
// 5. 掛起當前線程,等待被喚醒
SNode m = awaitFulfill(s, timed, nanos);
// 6. 如果這個節點已經被取消,就刪除這個節點
if (m == s) {
clean(s);
return null;
}
// 7. 把s.next設置成head
if ((h = head) != null && h.next == s)
casHead(h, s.next);
return (E) ((mode == REQUEST) ? m.item : s.item);
}
// 8. 如果棧頂節點類型跟本次操作不同,並且不是FULFILLING類型
} else if (!isFulfilling(h.mode)) {
// 9. 再次判斷如果棧頂節點已經被取消,就刪除棧頂節點
if (h.isCancelled())
casHead(h, h.next);
// 10. 把本次操作包裝成SNode(類型是FULFILLING),壓入棧頂
else if (casHead(h, s = snode(s, e, h, FULFILLING | mode))) {
// 11. 使用死迴圈,直到匹配到對應的節點
for (; ; ) {
// 12. 遍歷下個節點
SNode m = s.next;
// 13. 如果節點是null,表示遍歷到末尾,設置棧頂節點是null,結束。
if (m == null) {
casHead(s, null);
s = null;
break;
}
SNode mn = m.next;
// 14. 如果棧頂的後繼節點跟棧頂節點匹配成功,就刪除這兩個節點,結束。
if (m.tryMatch(s)) {
casHead(s, mn);
return (E) ((mode == REQUEST) ? m.item : s.item);
} else
// 15. 如果沒有匹配成功,就刪除棧頂的後繼節點,繼續匹配
s.casNext(m, mn);
}
}
} else {
// 16. 如果棧頂節點類型跟本次操作不同,並且是FULFILLING類型,
// 就再執行一遍上面第11步for迴圈中的邏輯(很少概率出現)
SNode m = h.next;
if (m == null)
casHead(h, null);
else {
SNode mn = m.next;
if (m.tryMatch(h))
casHead(h, mn);
else
h.casNext(m, mn);
}
}
}
}
transfer方法邏輯也很簡單,就是判斷本次操作類型是否跟棧頂節點相同,如果相同,就把本次操作壓入棧頂。否則就跟棧頂節點匹配,喚醒棧頂節點線程,彈出棧頂節點。
transfer方法中調用了awaitFulfill方法,作用是掛起當前線程。
// 等待被喚醒
SNode awaitFulfill(SNode s, boolean timed, long nanos) {
// 1. 計算超時時間
final long deadline = timed ? System.nanoTime() + nanos : 0L;
Thread w = Thread.currentThread();
// 2. 計算自旋次數
int spins = (shouldSpin(s) ?
(timed ? maxTimedSpins : maxUntimedSpins) : 0);
for (;;) {
if (w.isInterrupted())
s.tryCancel();
// 3. 如果已經匹配到其他節點,直接返回
SNode m = s.match;
if (m != null)
return m;
if (timed) {
// 4. 超時時間遞減
nanos = deadline - System.nanoTime();
if (nanos <= 0L) {
s.tryCancel();
continue;
}
}
// 5. 自旋次數減一
if (spins > 0)
spins = shouldSpin(s) ? (spins-1) : 0;
else if (s.waiter == null)
s.waiter = w;
// 6. 開始掛起當前線程
else if (!timed)
LockSupport.park(this);
else if (nanos > spinForTimeoutThreshold)
LockSupport.parkNanos(this, nanos);
}
}
awaitFulfill方法的邏輯也很簡單,就是掛起當前線程。
take方法底層使用的也是transfer方法:
// 取數據
public E take() throws InterruptedException {
// // 調用轉換器實現類,取數據
E e = transferer.transfer(null, false, 0);
if (e != null)
return e;
// 沒取到,就中斷當前線程
Thread.interrupted();
throw new InterruptedException();
}
4. 總結
- SynchronousQueue是一種特殊的阻塞隊列,隊列長度是0,一個線程往隊列放數據,必須等待另一個線程取走數據。同樣,一個線程從隊列中取數據,必須等待另一個線程往隊列中放數據。
- SynchronousQueue底層是基於棧和隊列兩種數據結構實現的。
- Java線程池中的newCachedThreadPool(帶緩存的線程池)底層就是使用SynchronousQueue實現的。
- 如果希望你的任務需要被快速處理,可以使用SynchronousQueue隊列。
我是「一燈架構」,如果本文對你有幫助,歡迎各位小伙伴點贊、評論和關註,感謝各位老鐵,我們下期見



