
決策引擎服務是風控系統的大腦,承載著風控策略編排和計算的任務,對決策的時耗和精度有著嚴格的要求,本文以決策流執行路徑實現方案為切入點,一窺風控決策引擎高效的原理。 ...
引言
決策引擎服務是風控系統的大腦,承載著風控策略編排和計算的任務,對決策的時耗和精度有著嚴格的要求,本文以決策流執行路徑實現方案為切入點,一窺風控決策引擎高效的原理。
背景
在上文 風控決策引擎——決策流構建實戰 中詳細介紹了風控決策引擎的發展歷程,決策流的編排能力,滿足了策略運營人員對當前風險場景下的防控策略足夠靈活、高效的部署。
“靈活”往往意味著不可控,從多年的開發經驗中來看,產品的功能在既定的範圍內,基本不會出現不可控的問題(除非是 BUG)。像 SQL 查詢語言,對數據分析人員來說非常的靈活,抽象的語法可以滿足任何數據組裝查詢組裝需求,但此時危機正在蔓延:隨時可能出現一個慢查詢導致性能問題!
“靈活”和“高效”往往在程式內是互斥的,足夠的靈活,往往是犧牲一定的效率得到的。研發人員能做的,就是在兩者中博弈,找到最佳平衡。
決策流執行演進
如下是策略運營人員配置的較常見的決策流圖:

流程圖看似簡單,但是在實際執行程式執行過程中會遇到各種各樣的問題和挑戰,根因還是上下游業務對風控決策執行的耗時有嚴格的控制要求。
一代目——串列執行工作流
此階段就像一個工作審批流,從開始節點一步一步的往下串列執行,直到終點。決策過程中,完全依賴節點路徑的複雜度,假設一個節點的平均耗時為 100ms,那麼如下紅色執行路徑需要耗時 500ms。

500ms 對風控來說是比較奢侈的,整個業務線一次請求耗時可能大半時間都被我們消耗掉了,這顯然是不能接受的。可以想象,隨著業務場景越來越複雜,策略人員對決策流的編排複雜度越來越高,導致整個決策流的決策路徑越來越長,耗時呈線性增長,這種技術實現方案肯定是不能接受的。
總結:
- 優點
- 所見即所得,不會多執行也不會少執行
- 串列執行對程式調試和日誌友好,方便調試
- 缺點
- 性能極差,策略人員不能接受
二代目——併發執行工作流
活乾不完,咱就堆人。同樣的,一個線程乾不完的,咱就堆線程併發計算。
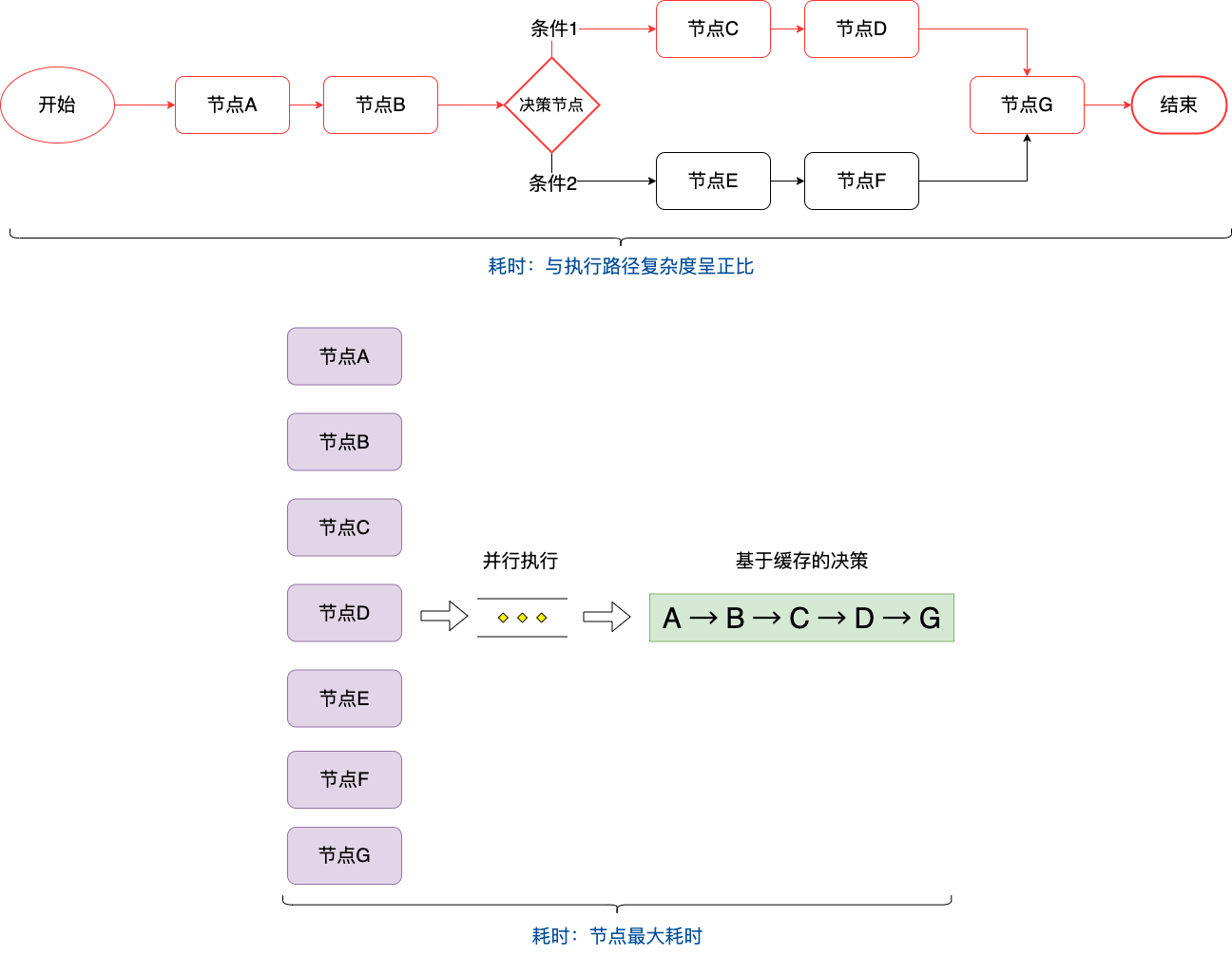
本著空間換時間的思想,預先將決策流內的節點全部預載入完成,將結果緩存住,真正執行決策流的時候,請求緩存直接計算執行,大大節省了決策時間。
此時影響決策性能的卡點在最耗時的那個節點,只需集中人力解決掉這個節點的性能問題就能降低決策流執行時間了。
總結:
- 優點
- 性能一流,空間換時間,最大化的提效
- 缺點
- 算力很大,所有節點都併發請求,對下游系統的負載要求很高
- 浪費巨大,當筆請求決策在節點 A 就被拒絕了,但是後續所有節點都計算了一遍,很浪費;又比如有些收費節點,提前調用了,但是並未使用,成本極大
- 未考慮節點依賴問題,假設節點 C 依賴 節點 A 的結果,此處會導致併發載入節點 C 時沒有相應的入參而出錯
三代目——依賴分析&並行
方案二除了不考慮成本問題外,最大的痛點在於依賴關係問題,這是致命的。此時需要在運行時動態分析決策流節點之間的依賴關係。
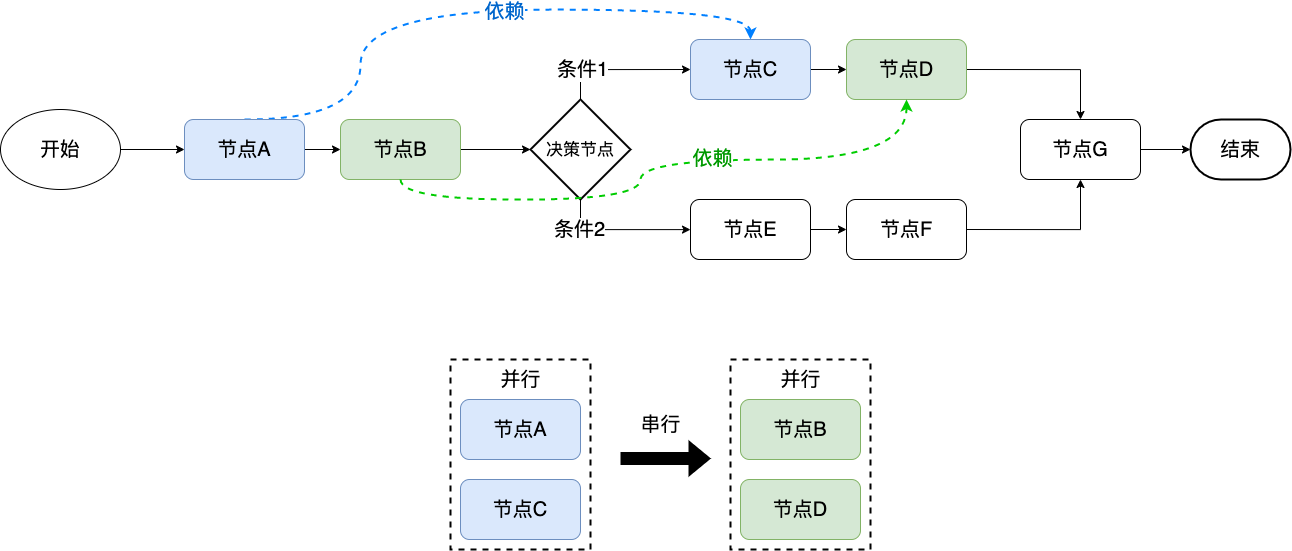
從圖中可以看出,節點 C 依賴節點 A,節點 D 依賴節點 B,其它節點相互不依賴,那麼此時可以通過依賴分析出節點與節點之間的分組關係,通過分組頭結點先後順序串列執行。
節點依賴分析
那麼如何實現節點的依賴分析及先後執行順序呢?
流程圖本身可以就是一個 DAG(有向無環圖),節點執行的先後順序可以用 BFS(廣度優先遍歷)遍歷出一維數組,然後遍歷分析每個節點的入參和之前的節點的出參是否有關聯,有關聯的歸併到之前節點組鏈表的“尾巴上”,否則即為不依賴,可並行執行。
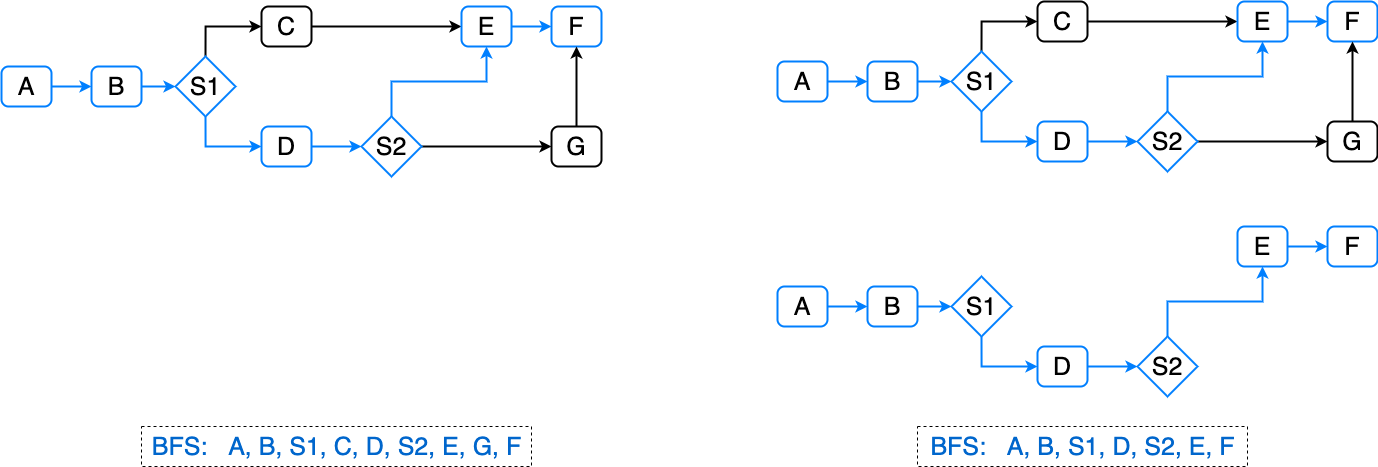
此時整個決策流執行耗時情況如下:
決策流執行耗時 = 並行組1耗時 + 並行組2耗時 + ... + 並行組 N耗時
總結:
- 優點
- 解決了決策流中並行處理中前後依賴問題
- 對策略人員的配置有一定的要求,需要儘量規避掉依賴關係,或者減少依賴分組
- 缺點
- 依然沒有解決方案 2 的成本問題,每個節點還是載入了一遍,算力浪費嚴重
四代目——路徑預測&動態剪枝
方案 2、3 都是全量並行載入各節點數據,對算力和成本的消耗是巨大的,實際在運行的過程中,公司在成本這塊肯定是不能接受的,可能資損召回都不定能抵得上伺服器和外部資源的開銷。
通過分析決策流圖,可以發現,分流節點的功能是排它,即決策數據流向只會選擇一條路徑執行,那麼此時我們能在並行執行之前確認哪些路徑在當次決策請求中不會經過,則可以排除掉不會經過路徑上的節點,從而減少不必要的算力和成本。
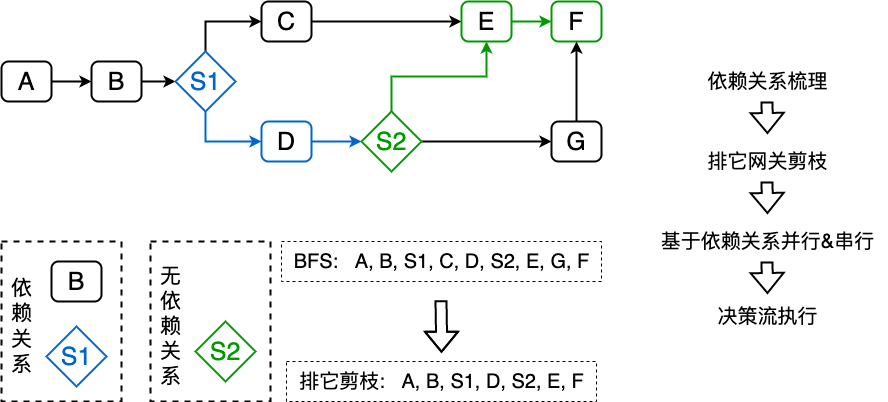
排它網關剪枝如上圖,優先找出排它網關節點 S1, S2,分析入參是否依賴上游節點,此時 S1 依賴節點 B,S2 無依賴,則可按照排它節點分組併發執行決策出排它路徑,此時 S1 節點對應的節點 C 被“剪枝”,S2 節點對應的節點 G 被“剪枝”。
總結:
- 優點
- 算力最小化,只併發載入行進路徑中的節點算力
- 缺點
- 行進路進中的節點未考慮成本問題,可能在前置節點已經拒絕,後直接點算力浪費
五代目——餓漢式&懶漢式
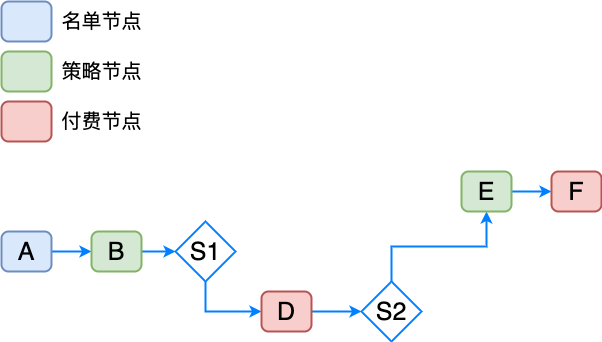
按照方案 4,已經解放了一大部分不會走到分支的算力,但是在正確的決策路徑上,依然存在浪費,舉例如上:
- A 節點是名單節點,如果命中名單,直接通過或者拒絕,後續節點並行載入都是浪費的
- 節點 D 和 節點 F 都是付費節點,併發調用,成本極高,可能在途中就被拒絕而未實際用到付費結果
此時,需要標識出付費節點(或者任何需要控制資源的節點),改為懶載入模式,即在前置併發載入所有節點時剔除懶載入節點,在決策流路徑真正執行到該節點時再去計算,確保調用了一定是有效的,此時,構建節點時需要區分設置節點類型是餓漢式 or 懶漢式。
總結:
- 優點
- 基本規避了上述方案涉及到的問題,在最大化利用率和性能之間取得平衡
- 缺點
- 決策流的編排需要通力合作,導致性能問題的點可能隨著編排而山下浮動,需要異動監控機制
總結
本文梳理了決策引擎編排決策流過程中為了提高決策性能和節約成本上做出的一些列優化方案,針對不同的場景,可自由選擇激進的方案 or 性能和成本兼顧的方案。
研發是站在產品規劃的角度去思考實現方案的,脫離規劃的設計再好,也不能真正的落地,謹記。
往期精彩
歡迎關註公眾號:咕咕雞技術專欄
個人技術博客:https://jifuwei.github.io/



