
第一章 LinkedList源碼分析 目標: 理解LinkedList的底層數據結構 深入源碼掌握LinkedList查詢慢,新增快的原因 一、LinkedList的簡介 List介面的鏈接列表實現。實現所有可選的列表操作,並且允許所有元素(包括null)。除了實現List介面外,LinkedLis ...
第一章 LinkedList源碼分析
目標:
- 理解LinkedList的底層數據結構
- 深入源碼掌握LinkedList查詢慢,新增快的原因
一、LinkedList的簡介
List介面的鏈接列表實現。實現所有可選的列表操作,並且允許所有元素(包括null)。除了實現List介面外,LinkedList類為在列表的開頭及結尾get、remove和insert元素提供了統一的命名方法。這些操作允許將鏈接列表用作堆棧、隊列或雙端隊列。
特點:
- 有序性:存入和取出的順序是一致的
- 元素可以重覆
- 含有帶索引的方法
- 獨有特點:數據結構是鏈表,可以作為棧、隊列或雙端隊列!
LinkedList是一個雙向的鏈表結構,雙向鏈表的長相,如下圖!

二、LinkedList原理分析
2.1LinkedList的數據結構
LinkedList是一個雙向鏈表!
底層數據結構的源碼:
public class LinkedList<E>
extends AbstractSequentialList<E>
implements List<E>, Deque<E>, Cloneable, java.io.Serializable
{
transient int size = 0;
//雙向鏈表的頭節點
transient Node<E> first;
//雙向鏈表的最後一個節點
transient Node<E> last;
//節點類【內部類】
private static class Node<E> {
E item;//數據元素
Node<E> next;//下一個節點
Node<E> prev;//上一個節點
//節點的構造方法
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
//...
}
LinkedList是雙向鏈表,在代碼中是一個Node類。 內部並沒有數組的結構。雙向鏈表肯定存在一個頭節點和一個尾節點。node節點類,是以內部類的形式存在與LinkedList中的。Node類都有兩個成員變數。
- prev:當前節點上一個節點,頭節點的上一個節點是null
- next:當前節點下一個節點,尾節點的下一個節點是null
鏈表數據結構的特點:查詢慢,增刪快!
- 鏈表數據結構基本構成,是一個node類
- 每個node類中,有上一個節點【prev】和下一個節點【next】
- 鏈表一定存在至少兩個節點,first和last節點
- 如果LinkedList沒有數據,first和last都是為null
2.2LinkedList預設容量&最大容量
沒有預設容量,也沒有最大容量
2.3LinkedList擴容機制
無需擴容機制,只要你的記憶體足夠大,可以無限制擴容下去。前提是不考慮查詢的效率。
2.4為什麼LinkedList查詢慢,增刪快?
LinkedList的數據結構的特點,鏈表的數據結構就是這樣的特點!
- 鏈表是一種查詢慢的結構【相對於數組來說】
- 鏈表是一種增刪快的結構【相對於數組來說】

2.5LinkedList源碼刨析-為什麼增刪快?
新增add
//向LinkedList添加一個元素
public boolean add(E e) {
//連接到鏈表的末尾
linkLast(e);
return true;
}
//連接到最後一個節點上去
void linkLast(E e) {
//將全局末尾節點賦值給1
final Node<E> l = last;
//創建一個新節點:(上一個節點,當前插入元素,null)
final Node<E> newNode = new Node<>(l, e, null);
//將當前節點作為末尾節點
last = newNode;
//判斷l節點是否為null
if (l == null)
//即是尾節點也是頭節點
first = newNode;
else
//之前的末尾節點,下一個節點是末尾節點
l.next = newNode;
size++;//當前集合的元素數量+1
modCount++;//操作集合數+1,modCount屬性是修改計數器
}
//-----------------------------------------------------------------
//向鏈表的中部添加
//參數1,添加的索引位置,添加元素
public void add(int index, E element) {
//檢查索引位是否符合要求
checkPositionIndex(index);
//判斷當前索引位是否存儲元素個數
if (index == size)//true,最後一個元素
linkLast(element);
else
//連接到指定節點的後面【鏈表中部插入】
linkBefore(element, node(index));
}
//根據索引查詢鏈表中節點!
Node<E> node(int index) {
//判斷索引是否小於 已經存儲元素個數的1/2
if (index < (size >> 1)) {//二分法查找:提高查找節點效率
Node<E> x = first;
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else {
Node<E> x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}
//將當前元素添加到指定節點之前
void linkBefore(E e, Node<E> succ) {
//取出當前節點的前一個節點
final Node<E> pred = succ.prev;
//創建當前元素的節點:上一個節點,當前元素,下一個節點
final Node<E> newNode = new Node<>(pred, e, succ);
//為指定節點上一個節點重賦新值
succ.prev = newNode;
//判斷當前節點的上一個節點是否為null
if (pred == null)
first = newNode;//當前節點作為頭部節點
else
pred.next = newNode;//將新插入節點作為上一個節點的下一個節點
size++;//新增元素+1
modCount++;//操作次數+1
}
remove刪除指定索引元素
//刪除指定索引位置元素
public E remove(int index) {
//檢查元素索引
checkElementIndex(index);
//刪除元素節點
//node(index) 根據索引查到要刪除的節點
//unlink()刪除節點
return unlink(node(index));
}
//根據索引查詢鏈表中節點!
Node<E> node(int index) {
//判斷索引是否小於 已經存儲元素個數的1/2
if (index < (size >> 1)) {//二分法查找:提高查找節點效率
Node<E> x = first;
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else {
Node<E> x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}
//刪除一個指定節點
E unlink(Node<E> x) {
//獲取當前節點的元素
final E element = x.item;
//獲取當前節點的上一個節點
final Node<E> next = x.next;
//獲取當前節點的下一個節點
final Node<E> prev = x.prev;
//判斷上一個節點是否為null
if (prev == null) {
//如果為null,說明當前節點為頭部節點
first = next;
} else {
//上一個節點 的下一個節點改為下下節點
prev.next = next;
//將當前節點的上一個節點置空
x.prev = null;
}
//判斷下一個節點是否為null
if (next == null) {
//如果為null,說明當前節點為尾部節點
last = prev;
} else {
//下一個節點的上節點,改為上上節點
next.prev = prev;
//當前節點的上節點置空
x.next = null;
}
//刪除當前節點內的元素
x.item = null;
size--;//集合中的元素個數-1
modCount++;//當前集合操作數+1,modCount計數器,記錄當前集合操作數次數
return element;//返回刪除的元素
}
2.6LinkedList源碼刨析-為什麼查詢慢?
查詢快和慢是一個相對概念!相對於數組來說
//根據索引查詢一個元素
public E get(int index) {
//檢查索引是否存在
checkElementIndex(index);
//node(index)獲取索引對應節點,獲取節點中的數據item
return node(index).item;
}
//根據索引獲取對應節點對象
Node<E> node(int index) {
//二分法查找索引對應的元素
if (index < (size >> 1)) {
Node<E> x = first;
//前半部分查找【遍歷節點】
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else {
Node<E> x = last;
//後半部分查找【遍歷】
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}
//查看ArrayList里的數組獲取元素的方式
public E get(int index) {
rangeCheck(index);//檢查範圍
return elementData(index);//獲取元素
}
E elementData(int index) {
return (E) elementData[index];//一次性操作
}
第二章 經典面試題
1、ArrayList的JDK1.8之前與之後的實現區別?
- JDK1.6:ArrayList像餓漢模式,直接創建一個初始化容量為10的數組。缺點就是占用空間較大。
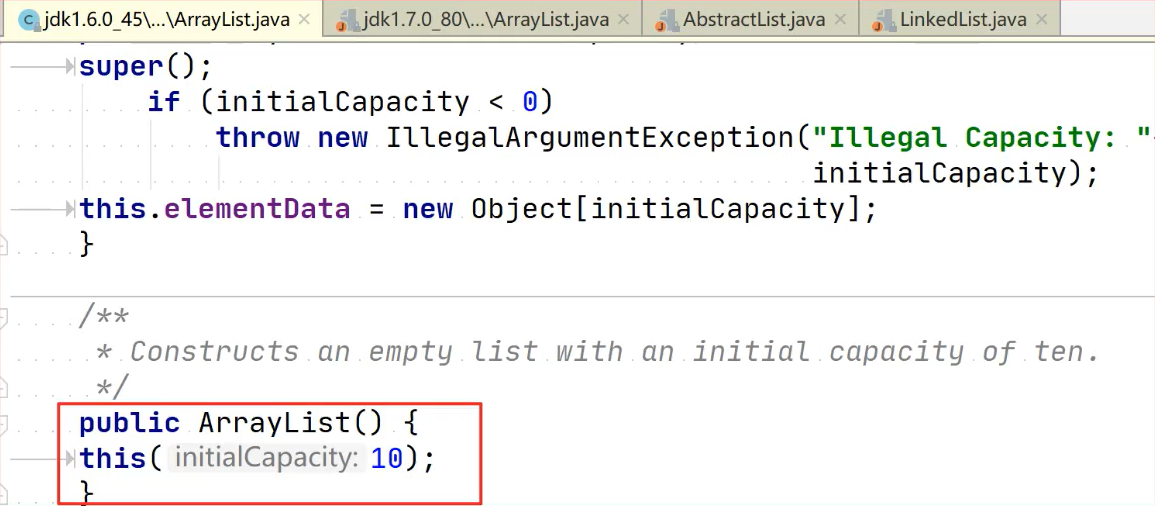
- JDK1.7&JDK1.8:ArrayList像懶漢式,一開始創建一個長度為0的數組,當添加第一個元素時再創建一個初始容量為10的數組
private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {};
public ArrayList() {
this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;
}
2、List和Map區別?
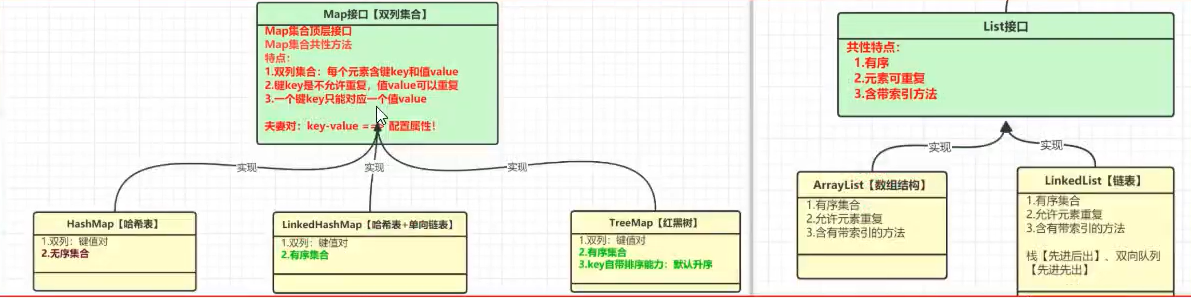
Map集合
- 雙列集合:一次存一對
- key是不允許重覆的,value可以重覆
- 一個key只能對應一個值value
- Map集合三兄弟:HashMap【無序集合】、LinkedHashMap【有序集合】、TreeMap【有序集合、自帶排序能力】
List集合
- 單列集合:一次存一個
- 有序集合
- 元素重覆
- 帶索引
- List集合主要有兩個實現類:ArrayList和LinkedList
3、Array和ArrayList有何區別?什麼時候更適合用Arry?
區別:
- Array可以容納基本類型和對象,而ArrayList只能容納對象【底層是一個對象數組】
- Array指定大小的固定不變,而ArrayList大小是動態的,可自動擴容。
- Array沒有ArrayList方法多。、
儘管ArrayList明顯是更好的選擇,但也有些時候Array比較好用,比如下麵的三種情況。
- 1、如果列表的大小已經指定,大部分情況是存儲和遍歷它們
- 基本數據類型使用Array更合適
4、ArrayList與LinkedList區別?
ArrayList
- 優點:ArrayList是實現了基於動態數組的數據結構,因為地址連續,一旦數據存儲好了,查詢操作效率會比較高(在記憶體里是連著放的)。查詢快,增刪相對慢。
- 缺點:因為地址連續,ArrayList要移動數據,所以插入和刪除操作效率比較低。
LinkedList
- 優點:LinkedList基於鏈表的數據結構,地址是任意的,所以在開闢記憶體空間的時候不需要等一個連續的地址。對於新增和刪除操作add和remove,LinkedList比較占優勢。LinkedList使用於要頭尾操作或插入指定位置的場景。
- 缺點:因為LinkedList要移動指針,所以查詢操作性能比較低。查詢慢,增刪快。
適用場景分析:
- 當需要對數據進行隨機訪問的情況下,選用ArrayList。
- 當需要對數據進行多次增加刪除修改時,採用LinkedList。
- 當然,絕大數業務的場景下,使用ArrayList就夠了。主要是,註意:最好避免ArrayList擴容,以及非順序的插入。
ArrayList是如何擴容的?
- 如果通過無參構造的話,初始數組容量為0,當真正對數組進行添加時,才真正分配容量。每次按照1.5倍(位運算)的比率通過copyOf的方式擴容。
重點是1.5倍擴容,這是和HashMap 2倍擴容不同的地方。
5、ArrayList集合加入10萬條數據,應該怎麼提高效率?
ArrayList的預設初始容量為10,要插入大量數據的時候需要不斷擴容,而擴容是非常影響性能的。因此,現在明確了10萬條數據了,我們可以直接在初始化的時候就設置ArrayList的容量!
這樣就可以提高效率了~
6、ArrayList和Vector區別?
ArrayList和Vector都是用數組實現的,主要有這麼三個區別:
- 1、Vector是多線程安全的,線程安全就是說多線程訪問同一代碼,不會產生不確定的結果,而ArrayList不是。這個可以從源碼中看出,Vector類中的方法很多有
synchronized進行修飾,這樣導致了Vector在效率上無法與ArrayList相比。
Vector是一種老的動態數組,是線程同步的,效率很低,一般不贊成使用。
- 2、兩個都是採用的線性連續空間存儲元素,但是當空間不足的時候,兩個類的增加方式是不同。
- 3、Vector可以設置增長因數,而ArrayList不可以,ArrayList集合沒有增長因數。
適用場景分析:
- 1、Vector是線程同步的,所以它也是線程安全的,而ArrayList是線程無需同步的,是不安全的。如果不考慮到線程的安全因素,一般用ArrayList效率比較高。
實際場景下,如果需要多線程訪問安全的數組,使用CopyOnWriteArrayList。


