MySQL基本知識 1.資料庫 1.1.創建資料庫 語法: CREATE DATABASE [IF NOT EXISTS] db_name [create_specification[,create_specification]...] create_specification: [DEFAULT] ...
MySQL基本知識
1.資料庫
1.1.創建資料庫
語法:
CREATE DATABASE [IF NOT EXISTS] db_name [create_specification[,create_specification]...]
create_specification:
[DEFAULT]CHARACTER SET charset_name
[DEFAULT]COLLATE collation_name
- CHARACTER SET:指定資料庫採用的字元集,如果不指定字元集,預設為utf8
- COLLATE:指定資料庫字元集的校對規則(常用的uft8_bin[區分大小寫]、utf8_general_ci[不區分大小寫] 預設是 utf8_general_ci)
練習:
-
創建一個名為hsp_db01的資料庫[圖形和指令演示]
-
創建一個utf8字元集的hsp_db02的資料庫
-
創建一個使用utf8字元集,並帶校對隊則的hsp_db03資料庫
指令創建:
#演示資料庫的操作
#1. 創建一個名為hsp_db01的資料庫
CREATE DATABASE hsp_db01;
#刪除資料庫指令
DROP DATABASE hsp_db01;
#2. 創建一個utf8字元集的hsp_db02的資料庫
CREATE DATABASE hsp_db02 CHARACTER SET utf8
#3. 創建一個使用utf8字元集,並帶校對隊則的hsp_db03資料庫
CREATE DATABASE hsp_db03 CHARACTER SET utf8 COLLATE utf8_bin
#校對規則 utf8_bin 區分大小寫 預設utf8_general_ci 不區分大小寫
可以看見在不指定採用字元集和校驗規則的情況下,字元集預設為utf8,校驗規則預設為utf8_general_ci
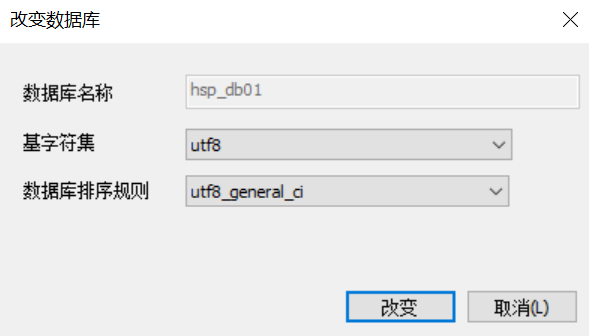
關於字元集和校驗規則:
如果在創建表的時候沒有指定字元集和校驗規則,則遵循和資料庫一樣的規則
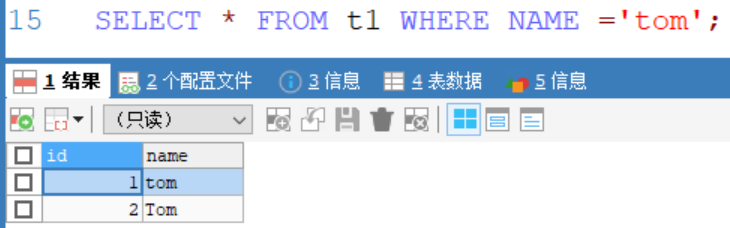
如下:在資料庫hsp_db02中創建表t1,t1設為預設字元集和校驗規則。
在表t1中用select查詢可以得到不區分大小寫的兩條數據:
在資料庫hsp_03中創建同樣的表t1並插入同樣的數據,查詢後只得到一條數據:
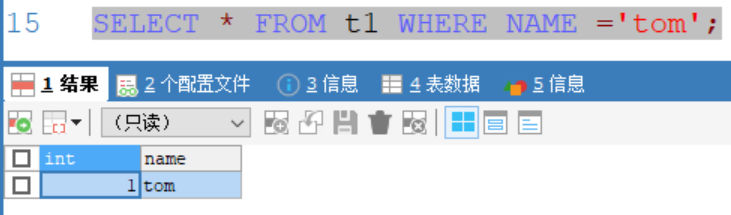
因為資料庫hsp_03在創建時指定校驗規則為utf8_bin,區分大小寫,查詢返回的數據也區分了大小寫
資料庫hsp_02沒有指定大小寫,返回的查詢沒有區分大小寫
因此可知當表設置預設的字元集和校驗規則時,其則遵循資料庫的字元集和校驗規則
1.2查看、刪除資料庫
- 語法:
#顯示資料庫語句
#顯示資料庫創建時的語句
#資料庫刪除語句[一定要慎用]
練習
-
查看當前伺服器中的所有資料庫
SHOW DATABASES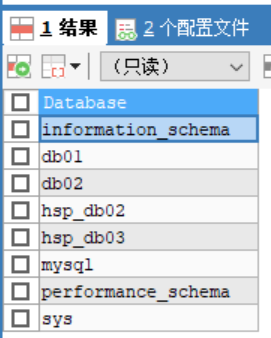
-
查看前面創建的hsp_02資料庫的定義信息
SHOW CREATE DATABASE hsp_db02
-
刪除前面創建的資料庫
-
關鍵字作名字創建資料庫:
- 說明1:資料庫名用反引號括起來,是為了規避數據名字為關鍵字
例如:創建一個名為create的資料庫,不使用反引號就會報錯
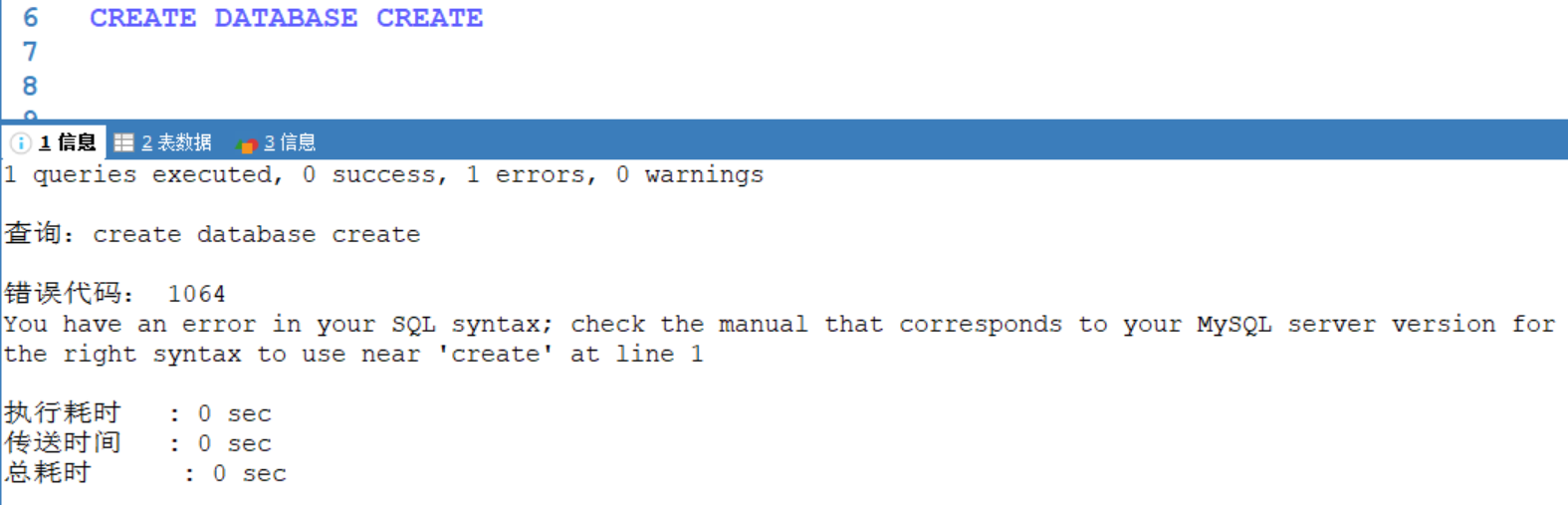
使用了反引號之後,就可以成功創建資料庫

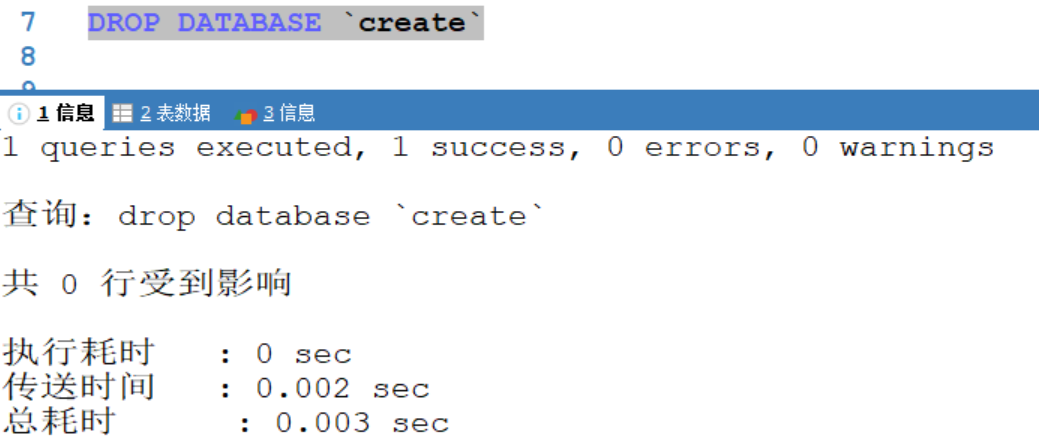
使用關鍵字創建,在刪除的時候也要在名字旁邊反引號
- 說明2:後面的語句用/*!40100...*/ 說明版本要在4以上執行這條語句
1.3備份恢復
1.3.1備份恢複數據庫
- 語法:
備份資料庫 (註意:在DOS執行)
mysqldump -u 用戶名 -p -B 資料庫1 資料庫2 資料庫n > 文件名.sql
恢複數據庫(註意:進入MySQL命令行再執行)
Source 文件名.sql
練習:備份恢複數據庫
備份hsp_db02和hsp_db03庫中的數據,並恢復
-
備份:
如下,在Dos視窗下輸入指令,指明備份的資料庫和保存的文件名
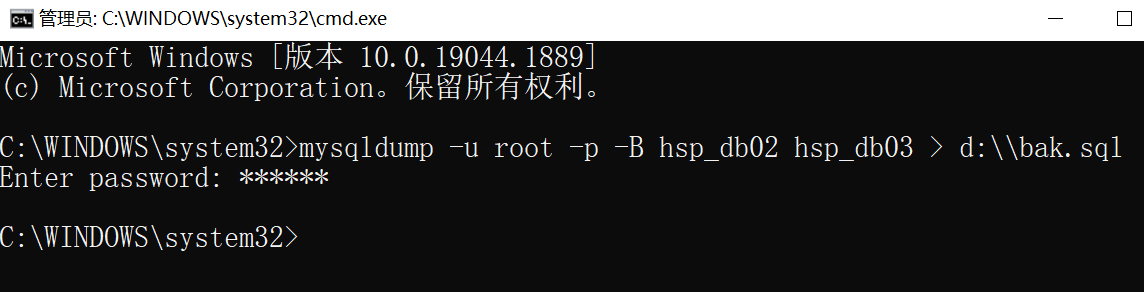
在指定的路徑下生成了對應的sql文件

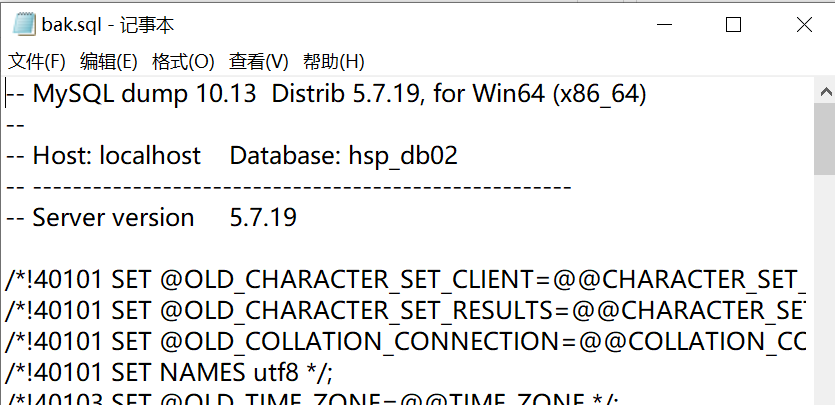
這個備份的文件就是對應的sql語句:
- 恢復
首先刪除掉資料庫hsp_db02和hsp_db03
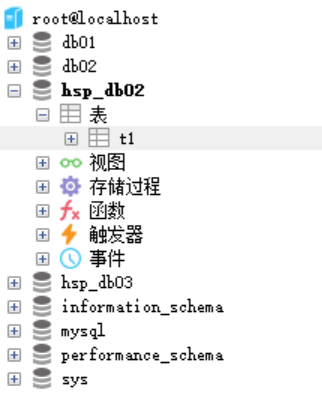
登錄賬號,進入mysql命令行,輸入指令 Source d:\\\bak.sql

可以看到資料庫及裡面的信息成功恢復:
1.3.2備份恢複數據庫表
- 語法:
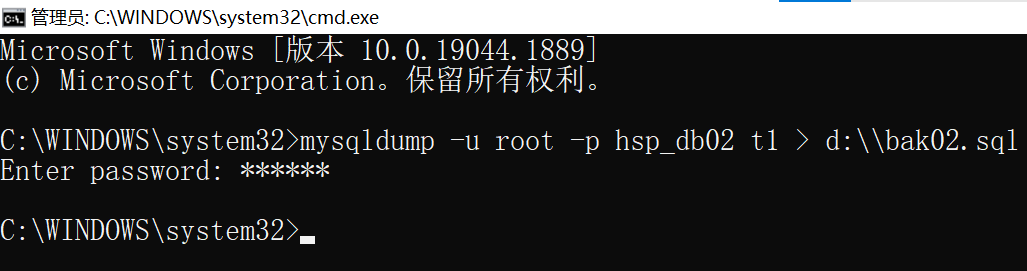
備份資料庫的表
mysqldump -u 用戶名 -p 資料庫 表1 表2 表n > 文件名.sql
(註意:在DOS執行)
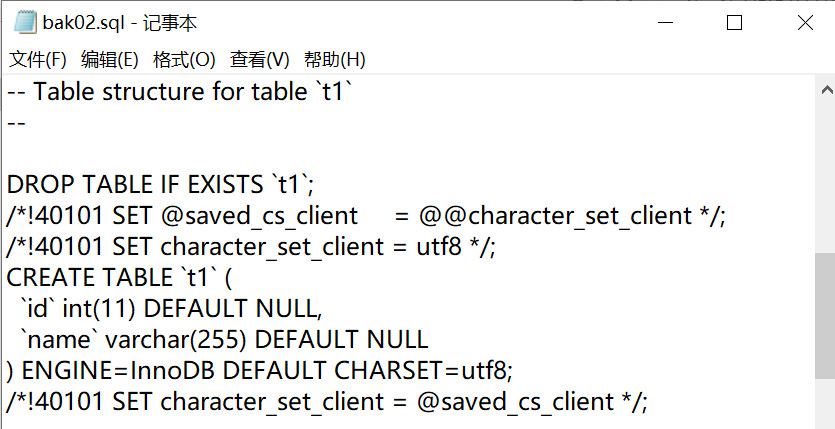
恢復和資料庫同理(註意進入mysql命令行執行)
2.表
2.1創建表
- 語法:
CREATE TABLE table_name
(
field1 datatype,
field2 datatype,
field3 datatype
)character set 字元集 collate 校對規則 engine 存儲引擎
# field:指定列名 datatype:指定列類型(欄位類型)
# character set:如不指定則為所在的資料庫字元集
# collate:如不指定則為所在的資料庫的校驗規則
# engine:引擎(這個涉及較多,後面單獨講解)
練習
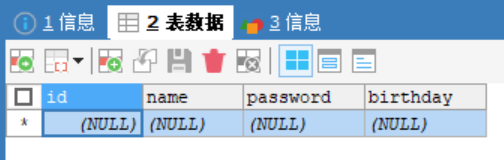
在資料庫hsp_db02創建一張表,根據需求的數據創建相應的列,並根據數據的類型定義相應的列類型
user表:
id 整形
name 字元串
passwoed 字元串
birthday 日期
#id 整形
#name 字元串
#passwoed 字元串
#birthday 日期
CREATE TABLE `user`(
id INT,
`name` VARCHAR(255),
`password` VARCHAR(255),
`birthday` DATE)
CHARACTER SET utf8 COLLATE utf8_bin ENGINE INNODB;
3.MySQL常用數據類型(列類型)
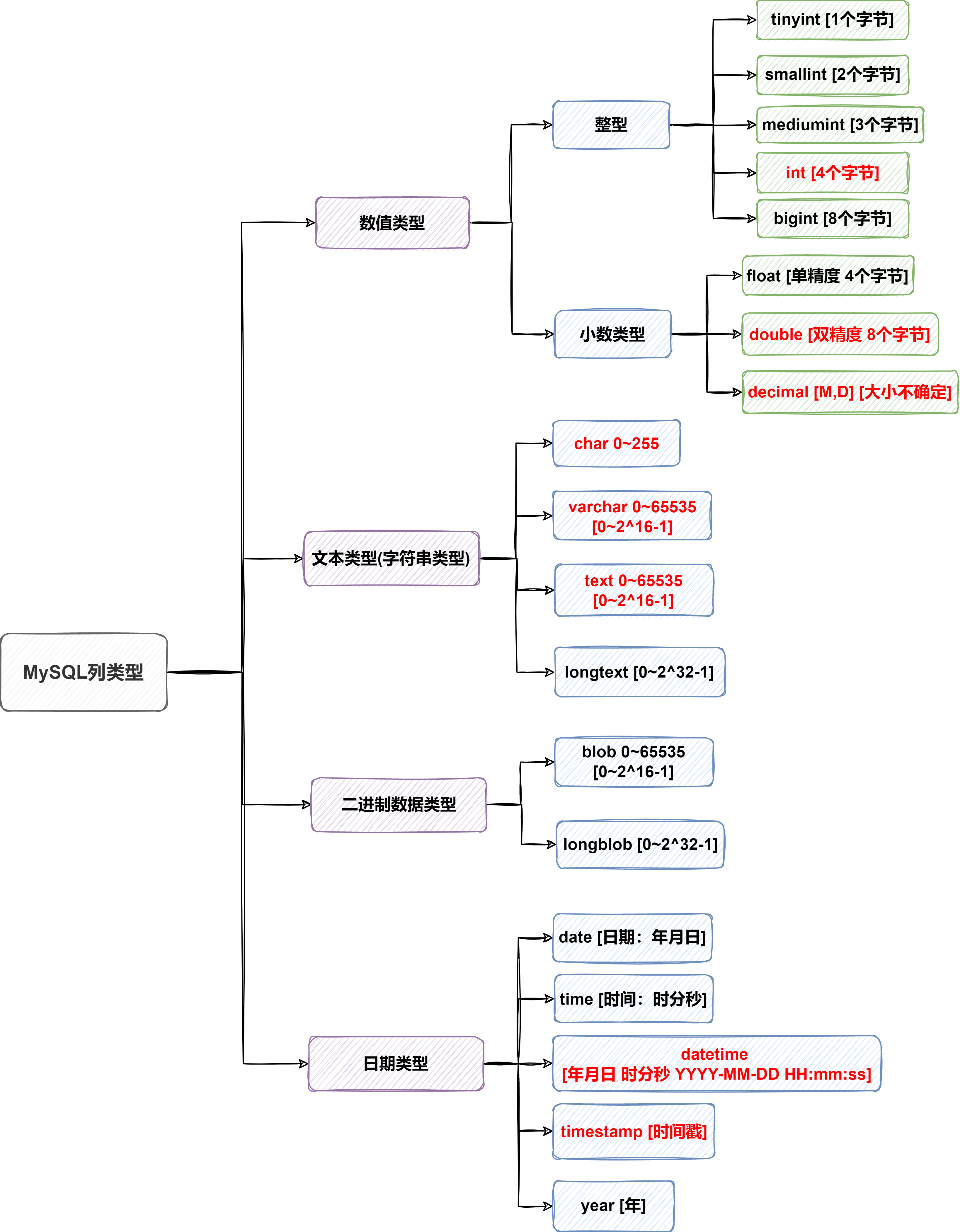

Mysql列類型即mysql的數據類型
詳見MySQL的參考手冊
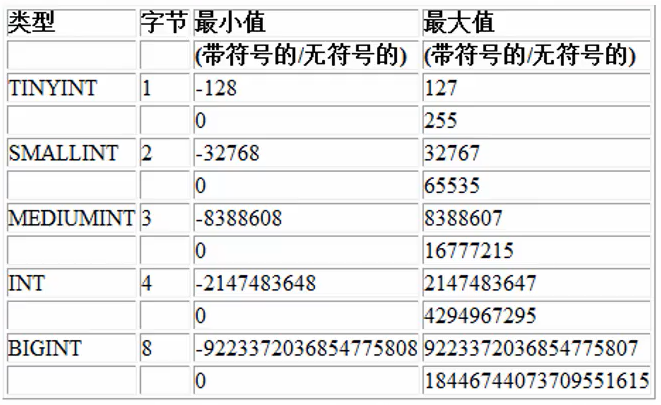
3.1列類型之整型
- 說明
數值型(整型)的基本使用
說明:使用規範:在能夠滿足需求的情況下儘量選擇空間小的類型
應用實例
- 3.1.2.1無符號TINYINT
- 在資料庫hsp_02中創建一個表t2,在表中插入列類型tinyint,列名為id
CREATE TABLE t2(
id TINYINT);
- 在表中插入數據 -129,執行後提示錯誤,可以看到t2為空表
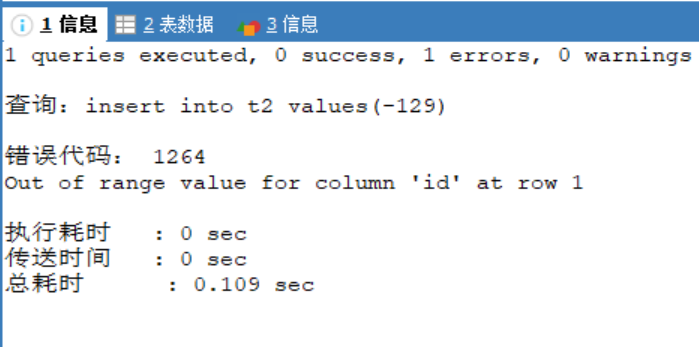
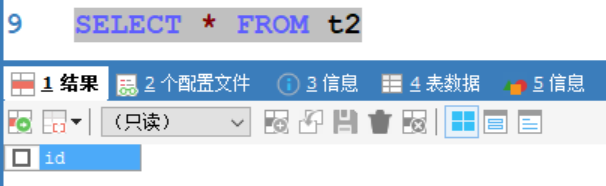
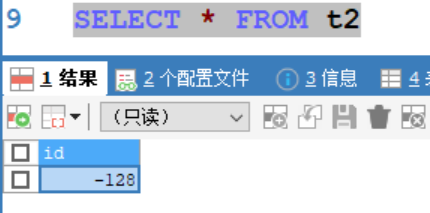
- 往表中插入數據-128,執行成功,表中成功插入數據

-
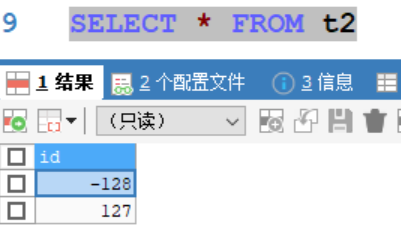
同理,分別往表中插入數據128、127,只有127插入成功
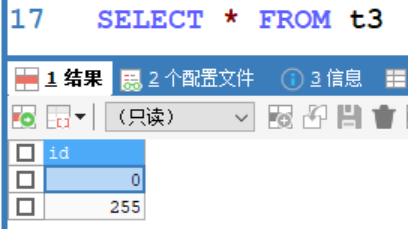
說明在有符號情況下,tinyint的範圍為-128~127
- 有符號TINYINT
在列類型後面指定無符號
CREATE TABLE t3(
id TINYINT UNSIGNED);
INSERT INTO t3 VALUES(-1);#錯誤,超出範圍
INSERT INTO t3 VALUES(0);
INSERT INTO t3 VALUES(256);#錯誤,超出範圍
INSERT INTO t3 VALUES(255);
3.2列類型之BIT
- 說明
- bit欄位顯示時,按照位的方式顯示(按照指定位數的二進位顯示)
- 查詢的時候仍然可以使用 添加時的數值(比如十進位)來查詢
- 如果一個值只有0,1,可以考慮使用bit(1),可以節省空間
- 位類型。M指定位數,預設值1,範圍1-64
練習
#演示bit類型使用
#說明
#1.bit(M) M在1-64位
#2.添加數據 的範圍是按照你給定的M的位數來確定,例如M=8 表示一個位元組(8bit) 0~255
create table t5 (num bit(8));
INSERT INTO t5 VALUES(5);
insert into t5 values(3);
select * from t5;
#3.查詢時仍然可以按照十進位數來查詢
select * from t5 where num = 5;
3.3列類型之小數類型
- 說明
-
FLOAT/DOUBLE[UNSIDNED]
float 單精度,double 雙精度
-
DECIMAL[M,D] [UNSIGNED]
-
可以支持更加精確的小數位。M是小數位數(精度)的總數,D是小數點(標度)後面的位數。
-
如果D是0,則值沒有小數點或分數部分。M最大65,D最大是30。如果D被省略,預設D是0;如果M被省略,預設M是10.
-
建議:如果希望小數點的精度高,推薦使用decimal
-
練習
#案例演示 float、double、decimal的使用
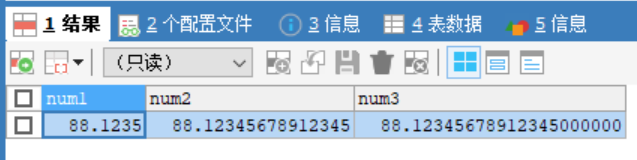
CREATE TABLE t6(
num1 FLOAT,
num2 DOUBLE,
num3 DECIMAL(30,20));
#添加數據
INSERT INTO t6 VALUES(88.12345678912345,88.12345678912345,88.12345678912345);
#查詢
SELECT * FROM t6;
#decimal可以存放很大的數
3.4列類型之字元串(文本類型)
-
說明
字元串的基本使用:
CHAR(size)
固定長度字元串 最大255字元
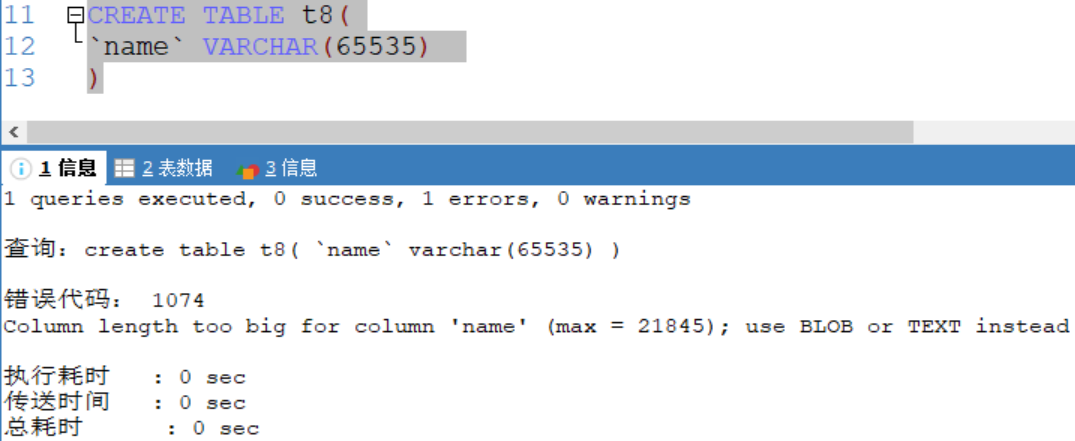
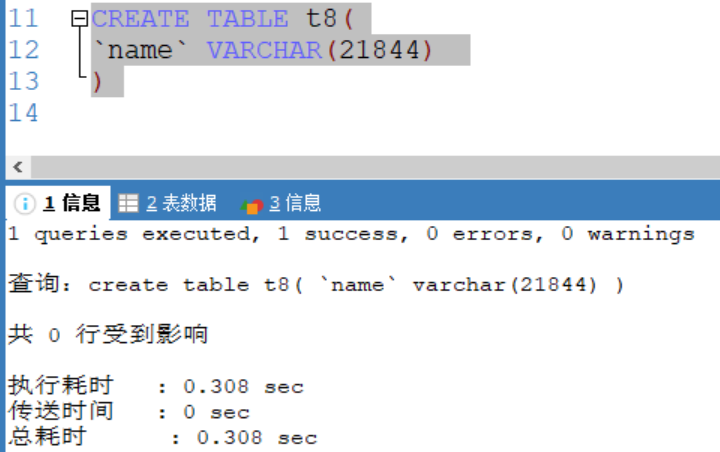
VARCHAR(size)
可變長度字元串 最大65532位元組
[ utf8編碼最大字元為21844字元,1-3個位元組用於記錄大小,uft8編碼每個字元占用三個位元組 ]
如果編碼是uft8 則varchar(size) size = (65535-3) / 3 = 21844
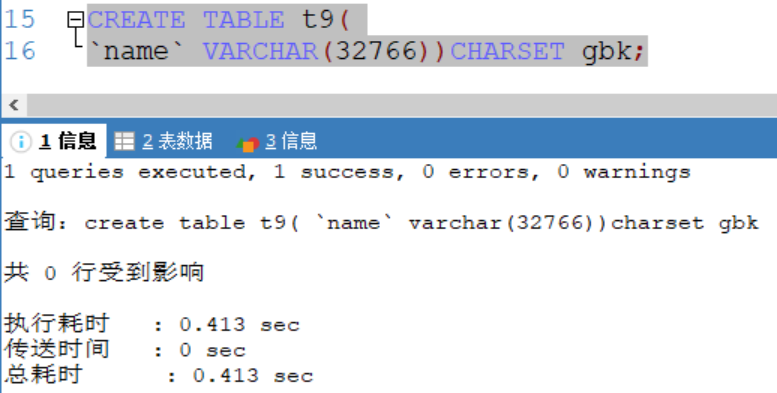
如果編碼是gbk 則varchar(size) size = (65535-3) / 2 = 32766
錯誤使用:(uft8)
成功插入:(uft8)
gbk字元集下:
-
字元串使用細節
-
細節1:
-
如 char(4) //這個4表示字元數(最大255),不是位元組數,不管是中文還是字母都是放四個,按字元計算
-
varchar(4) //這個4表示字元數,(這四個字元占用多少個位元組取決於你定義的編碼) 不管是字母還是中文都以定義好的表的編碼來存放數據
上面的例子不管是中文還是字母都是最多存放4個,是按照字元來存放的
-
-
細節2:
- char(4)是定長(固定的大小),就是說,即時你插入'aa',也會占用分配的4個字元
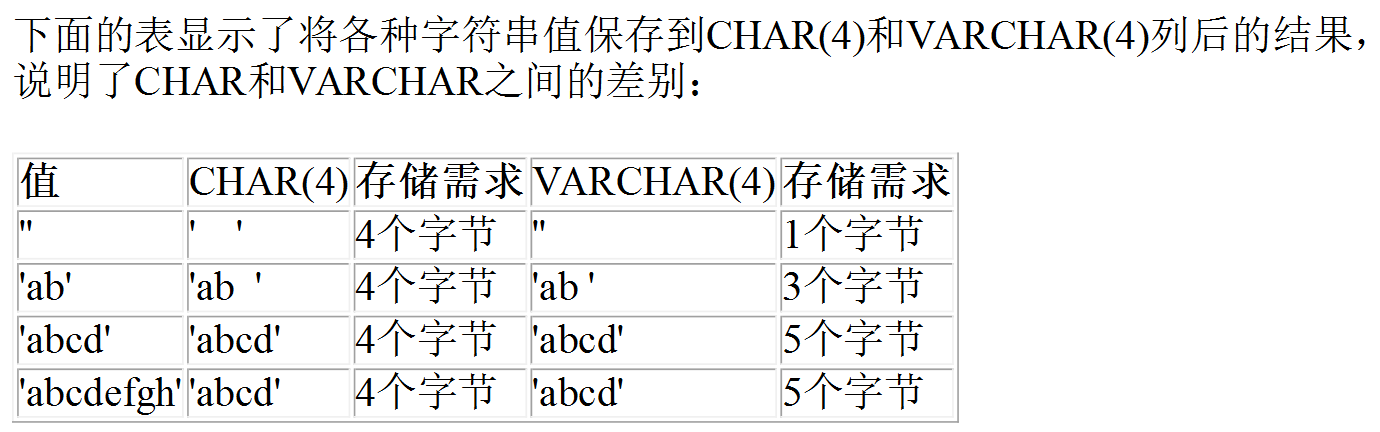
- varchar(4)是可變長,即如果你插入的是'aa',實際占用的空間大小並不是4個字元,而是按照實際占用空間來分配。VARCHAR值保存時只保存需要的字元數,另加一個位元組來記錄長度(如果列聲明的長度超過255,則使用兩個位元組) ,因此varchar的實際長度=實際的數據大小+(1-3個位元組)
-
細節3:使用的的時機
- 如果數據是定長,推薦使用char,比如md5的密碼,郵編,手機號,身份證號碼等
- 如果一個欄位的長度不定,就使用varchar,比如留言,文章
- 查詢速度 char > varchar
-
細節4:
- 在存放文本時,也可以使用text數據類型。可以將text列視為varchar列,註意text不能有預設值,大小 0~2^16位元組
- 如果希望存放更多字元,可以選擇mediumtext 0~2^24 或者 longtext 0~2^32
例子:
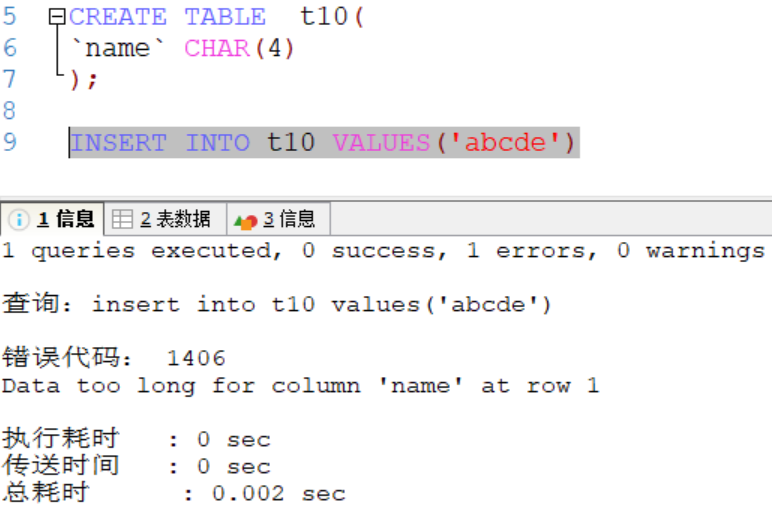
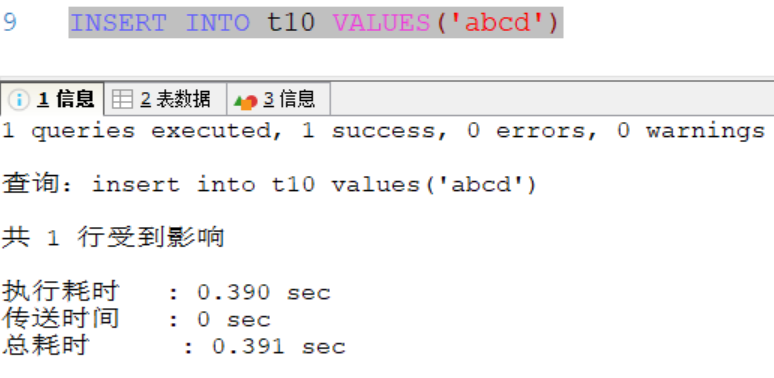
在下圖中,不管插入的是中文還是字母,每一個都按一個字元來算,因此'abcde'相當5個字元長度,插入失敗;varchar同理。
失敗:
成功:
例子2:關於text,mediumtext 和 longtext的使用
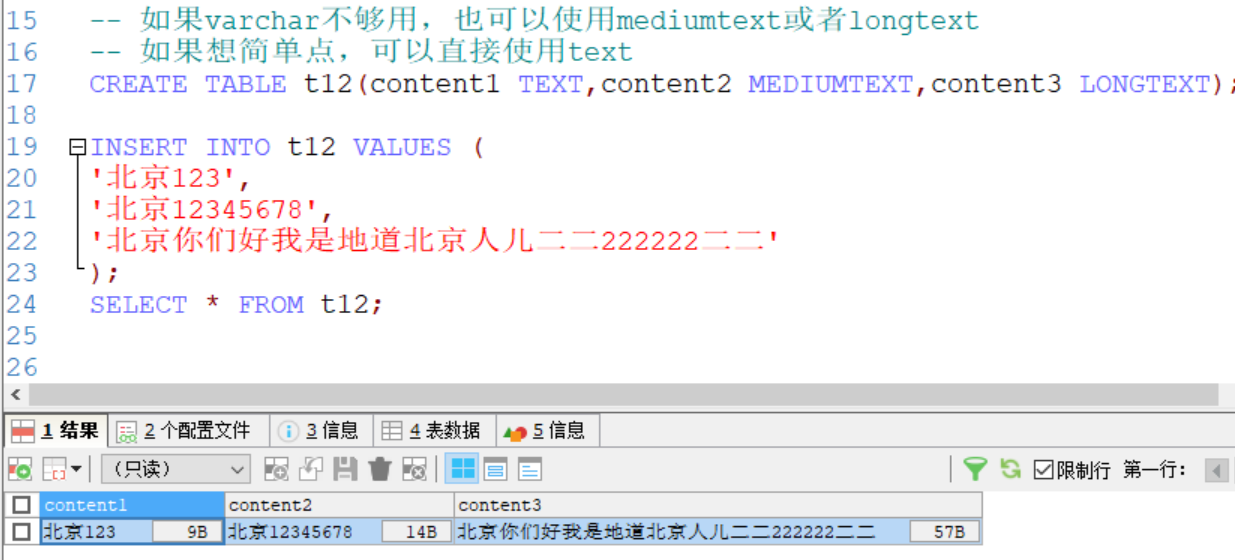
如上圖所示:在插入的數據後面顯示了實際使用的數值大小
content1有兩個中文=2*3=6bit,每個數字占用一個位元組,共計9bit
content2也有兩個中文=2*3=6bit,有八個數字,共計14bit
3.5列類型之日期類型
-
日期類型的細節說明
TimeStamp在Insert和Update時,會自動更新
例子:
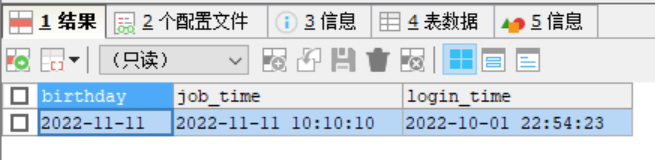
#演示時間相關的案例
#創建一張表,data ,datatime,timestamp
CREATE TABLE t13(
birthday DATE,-- 生日
job_time DATETIME,-- 記錄年月日 時分秒
login_time TIMESTAMP
NOT NULL DEFAULT CURRENT_TIMESTAMP
ON UPDATE CURRENT_TIMESTAMP);-- 登錄時間,如果希望login_time列自動更新,需要配置
INSERT INTO t13(birthday,job_time)
VALUES('2022-11-11','2022-11-11 10:10:10');
#如果我們更新了t13的某條記錄,login_time會自動地以當前時間來進行更新
SELECT * FROM t13;