
前言 在使用SpringBoot的時候經常需要對客戶端傳入的參數進行合法性的校驗,校驗的方法基本上都是使用SpringBoot提供的註解,有時候遇上註解不能滿足需求的時候還需要在業務邏輯上進行判斷。這樣根本就沒有實現解耦。 使用方法 項目maven引入 <dependency> <groupId>c ...
一個簡單的例子
先來看一個多線程的例子:
graph TB begin(a)-->線程1(x = 1, m = y) begin(x = 0, y = 0)-->線程2(y = 1, n = x)如圖所示,我們將變數x和y初始化為0,然後線上程1中執行:
x = 1, m = y;
同時線上程2中執行:
y = 1, n = x;
當兩個線程都執行結束以後,m和n的值分別是多少呢?
對於已經工作了n年、寫過無數次併發程式的的我們來說,這還不是小case嗎?讓我們來分析一下,大概有三種情況:
- 如果程式先執行了x = 1, m = y代碼段,後執行了y = 1, n = x代碼段,那麼結果是m = 0, n = 1;
- 如果程式先執行了y = 1, n = x代碼段,後執行了x = 1, m = y代碼段,那麼結果是m = 1, n = 0;
- 如果程式的執行順序先是 x = 1, y = 1, 後執行m = y, n = x, 那麼結果是m = 1, n = 1;
所以(m, n)的組合一共有3種情況,分別是(0, 1), (1, 0)和(1, 1)。
那有沒有可能程式執行結束後,(m, n)的值是(0, 0)呢?嗯...我們又仔細的回顧了一下自己的分析過程:在m和n被賦值的時候,x = 1和y = 1至少有一條語句被執行了...沒有問題,那應該就不會出現m和n都是0的情況。
詭異的輸出結果
不過人在江湖上混,還是要嚴謹一點。好在這代碼邏輯也不複雜,那就寫一段簡單的程式來驗證下吧:
#include <iostream>
#include <thread>
using namespace std;
int x = 0, y = 0, m = 0, n = 0;
int main()
{
while (1) {
x = y = 0;
thread t1([&]() { x = 1; m = y; });
thread t2([&]() { y = 1; n = x; });
t1.join(); t2.join();
if (m == 0 && n == 0) {
cout << " m == 0 && n == 0 ? impossible!\n";
}
}
return 0;
}
考慮到多線程的隨機性,就寫一個無限迴圈多跑一會吧,反正屏幕也不會有什麼輸出。我們信心滿滿的把程式跑了起來,但很快就發現有點不太對勁:
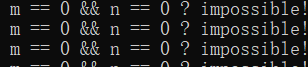
m和n居然真的同時為0了?不可能不可能...這難道是windows或者msvc的bug?那我們到linux上用g++編譯試一下,結果程式跑起來之後,又看到了熟悉的輸出:
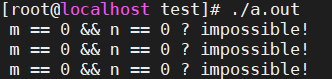
這...打臉未免來得也太快了吧!
你看到的執行順序不是真的執行順序
看來這不是bug,真的是有可能出現m和n都是0的情況。可是,到底是為什麼呢?恍惚之間,我們突然想起曾經似乎在哪看過這樣一個as-if規則:
The rule that allows any and all code transformations that do not change the observable behavior of the program.
也就是說,在不影響可觀測結果的前提下,編譯器是有可能對程式的代碼進行重排,以取得更好的執行效率的。比如像這樣的代碼:
int a, b;
void test()
{
a = b + 1;
b = 1;
}
編譯器是完全有可能重新排列成下麵的樣子的:
int a, b;
void test()
{
int c = b;
b = 1;
c += 1;
a = c;
}
這樣,程式在實際執行過程中對a的賦值就晚於對b的賦值之後了。不過,有了前車之鑒,我們還是先驗證一下在下結論吧。我們使用gcc的-S選項,生成彙編代碼(開啟-O2優化)來看一下,編譯器生成的指令到底是什麼樣子的:
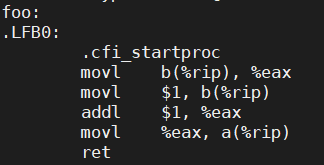
哈哈,果然如我們所料,對a的賦值被調整到對b的賦值後面了!那上面m和n同時為0也一定是因為編譯器重新排序我們的指令順序導致的!想到這裡,我們的底氣又漸漸回來了。那就生成彙編代碼看看吧:
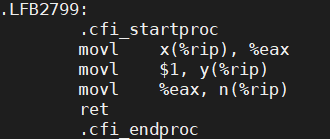
果然不出所料,因為我們在編譯的時候開了-O3優化,賦值的順序被重排了!代碼實際的執行順序大概是下麵這個樣子:
int t1 = y; x = 1; m = t1; //線程1
int t2 = x; y = 1; n = t2; //線程2
這就難怪會出現m = 0, n = 0這樣的結果了。分析到這裡,我們終於有點鬆了一口氣,這多年的編程經驗可不是白來的,總算是給出了一個合理的解釋。
那我們在編譯的時候把-O3優化選項去掉,儘量讓編譯器不要進行優化,保持原來的指令執行順序,應該就可以避免m和n同時為0的結果了吧?試試,保險起見,我們還是先看一看彙編代碼吧:

跟我們的預期一致,彙編代碼保持了原來的執行順序,這回肯定沒有問題了。那就把程式跑起來吧。然而...不一會兒,熟悉的列印又出現了...
這...到底是怎麼回事?!!!
你看到的執行順序還不是真正的執行順序
如果不是編譯器重排了我們的指令順序,那還會是什麼呢?難道是CPU?!
還真是。實際上,現代CPU為了提高執行效率,大多都採用了流水線技術。例如:一個執行過程可以被分為:取指(IF),解碼(ID),執行(EX),訪存(MEM),回寫(WB)等階段。這樣,當第一條指令在執行的時候,第二條指令可以進行解碼,第三條指令可以進行取指...於是CPU被充分利用了,指令的執行效率也大大提高。一個標準的5級流水線的工作過程如下表所示(實際的CPU流水線遠比這複雜得多):
| 序號/時鐘周期 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | ... |
|---|---|---|---|---|---|---|---|---|
| 1 | IF | ID | EX | MEM | WB | |||
| 2 | IF | ID | EX | MEM | WB | |||
| 3 | IF | ID | EX | MEM | WB | |||
| 4 | IF | ID | EX | MEM | WB | |||
| 5 | IF | ID | EX | MEM | ||||
| 6 | IF | ID | EX |
上面展示的指令流水線是完美的,然而實際情況往往沒有這麼理想。考慮這樣一種情況,假設第二條指令依賴於第一條指令的執行結果,而第一條指令恰巧又是一個比較耗時的操作,那麼整個流水線就停止了。即使第三條指令與前兩條指令完全無關,它也必須等到第一條指令執行完成,流水線繼續運轉時才能得已執行。這就浪費了CPU的執行帶寬。亂序執行(Out-Of-Order Execution)就是被用來解決這一問題的,它也是現代CPU提升執行效率的基礎技術之一。
簡單來說,亂序執行是指CPU提前分析待執行的指令,調整指令的執行順序,以期發揮更高流水線執行效率的一種技術。引入亂序執行技術以後,CPU執行指令過程大概是下麵這個樣子:
所以,上面的程式出現(m, n)結果為(0, 0)的情況,應該就是因為指令的執行順序被CPU重排了!
C++多線程記憶體模型
我們通常將讀取操作稱為load,存儲操作稱為store。對應的記憶體操作順序有以下幾種:
- load->load(讀讀)
- load->store(讀寫)
- store->load(寫讀)
- store->store(寫寫)
CPU在執行指令的時候,會根據情況對記憶體操作順序進行重新排列。也就是說,我們只要能夠讓CPU不要進行指令重排優化,那麼應該就不會出現(m, n)為(0, 0)的情況了。但具體要怎麼做呢?
實際上,在C++11之前,我們很難在語言層面做到這件事情。那時的C++甚至連線程都不支持,更別提什麼記憶體模型了。在C++98的年代,我們只能通過嵌入彙編的方式添加記憶體屏障來達到這樣的目的:
asm volatile("mfence" ::: "memory");
不過在現代C++中,要做這樣的事情就簡單多了。C++11引入了原子類型(atomic),同時規定了6種記憶體執行順序:
- memory_order_relaxed: 鬆散的,在保證原子性的前提下,允許進行任務的重新排序;
- memory_order_release: 代碼中這條語句前的所有讀寫操作, 不允許被重排到這個操作之後;
- memory_order_acquire: 代碼中這條語句後的所有讀寫操作,不允許被重排到這個操作之前;
- memory_order_consume: 代碼中這條語句後所有與這塊記憶體相關的讀寫操作,不允許被重排到這個操作之前;註意,這個類型已不建議被使用;
- memory_order_acq_rel: 對讀取和寫入施加acquire-release語義,無法被重排;
- memory_order_seq_cst: 順序一致性,如果是寫入就是release語義,如果是讀取是acquire語義,如果是讀取-寫入就是acquire-release語義;也是原子變數的預設語義。
所以,我們只需要將x和y的類型改為atmioc_int,就可以避免m和n同時為0的結果出現了。修改後的代碼如下:
#include <iostream>
#include <thread>
#include <atomic>
using namespace std;
atomic_int x(0);
atomic_int y(0);
int m = 0, n = 0;
int main()
{
while (1) {
x = y = 0;
thread t1([&]() { x = 1; m = y; });
thread t2([&]() { y = 1; n = x; });
t1.join(); t2.join();
if (m == 0 && n == 0) {
cout << " m == 0 && n == 0 ? impossible!\n";
}
}
return 0;
}
現在編譯運行一下,看看結果:

已經不會再出現"impossible"的列印了。我們再來看看生成的彙編代碼:

原來編譯器已經自動幫我們插入了記憶體屏障,這樣就再也不會出現(m, n)為(0, 0)的情況了。
全文完。

