
在數據分析過程中,一般提取資料庫裡面的數據時候,拿著表格數據反覆思索,希望能夠根據自己所想立馬生成一張數據可視化的圖表來更直觀的呈現數據。 但想要進行數據可視化的時候,往往需要調用很多的庫與函數,還需要數據轉換以及大量的代碼處理編寫。這都是十分繁瑣的工作,確實只為了數據可視化我們不需要實現數據可視化 ...
在數據分析過程中,一般提取資料庫裡面的數據時候,拿著表格數據反覆思索,希望能夠根據自己所想立馬生成一張數據可視化的圖表來更直觀的呈現數據。

但想要進行數據可視化的時候,往往需要調用很多的庫與函數,還需要數據轉換以及大量的代碼處理編寫。這都是十分繁瑣的工作,確實只為了數據可視化我們不需要實現數據可視化的工程編程,這都是數據分析師以及擁有專業的報表工具來做的事情,日常分析的話我們根據自己的需求直接進行快速出圖即可,而Pandas正好就帶有這個功能,當然還是依賴matplotlib庫的,只不過將代碼壓縮更容易實現。下麵就讓我們來瞭解一下如何快速出圖。
一、基礎繪圖:plot
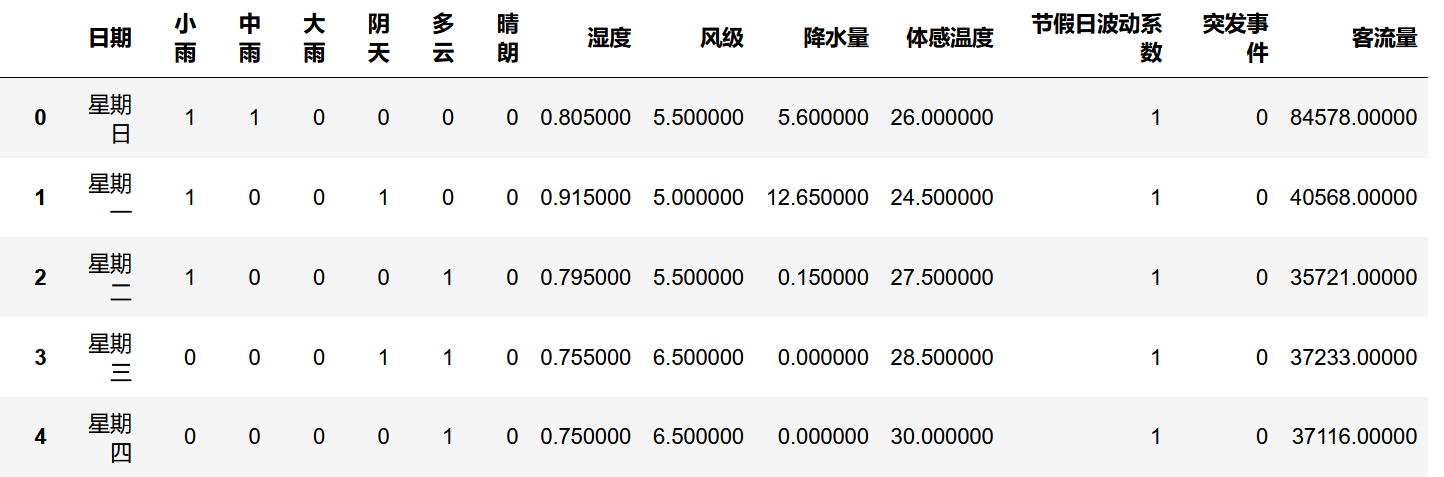
Series和DataFrame上的plot方法只是plt.plot()的簡單包裝,這裡我們用一段實際數據來進行可視化展示:
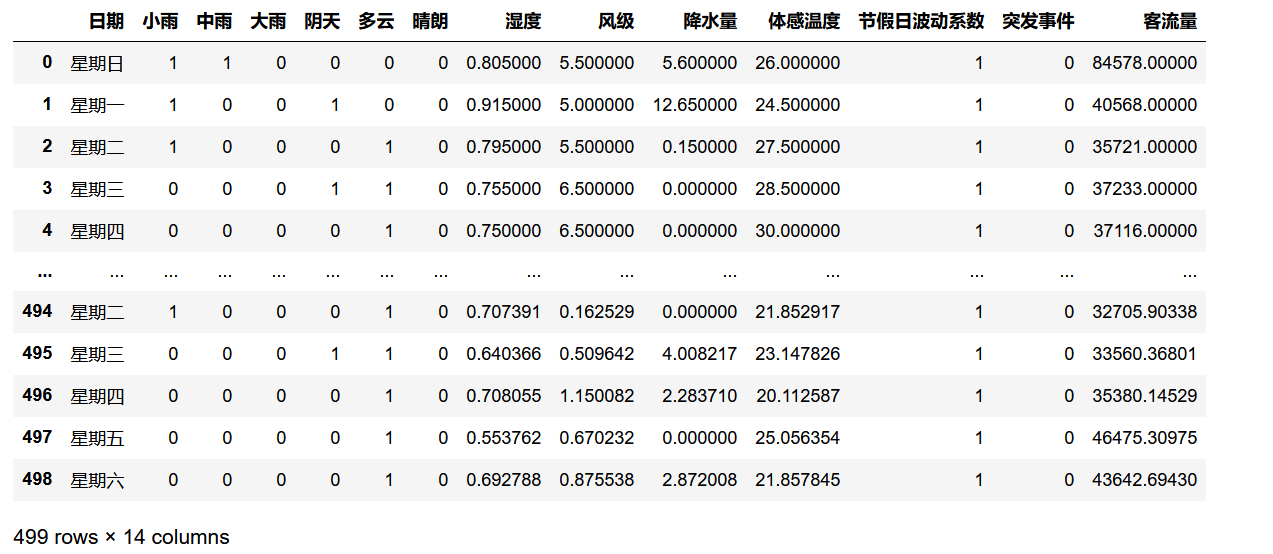
這是一段真實地鐵通行量特征數據,我們用此數據進行展示:
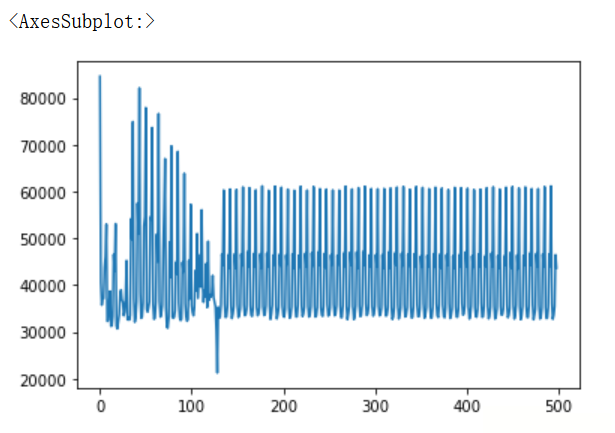
df_flow['客流量'].plot() # 小伙伴們在學習Python的過程中,有時候不知道怎麼學,從哪裡開始學。掌握了一些基本的知識或者做了一些案例後,不知道下一步怎麼走,不知道如何去學習更加高深的知識。 # 那麼對於這些大兄弟們,我準備了大量的免費視頻教程,PDF電子書籍,以及源代碼! # 我都放在這個裙了 279199867 大家自取即可~
如果索引由日期組成,則調用gcf().autofmt_xdate()方法可以很好地格式化x軸。

在DataFrame上,plot()可以方便地用標簽繪製所有列:
df_flow_mark[['濕度','風級','降水量']].plot()

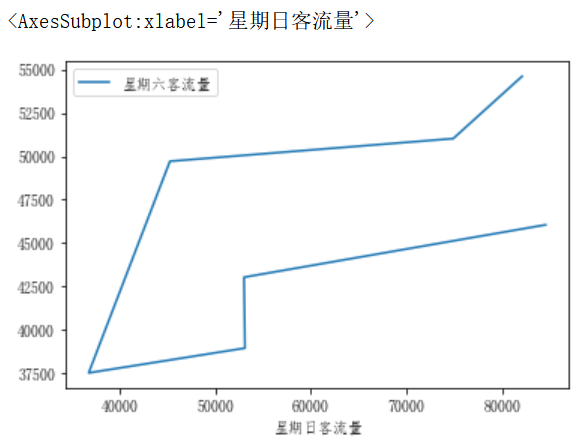
可以使用plot()中的x和y關鍵字繪製一列與另一列的對比,比如我們想要使用星期六的客流量和星期日的客流量作對比:
df_flow_7=df_flow[df_flow['日期']=='星期日'].iloc[:7,:] df_flow_7.rename(columns={'客流量':'星期日客流量'},inplace=True) df_flow_6=df_flow[df_flow['日期']=='星期六'].iloc[:7,:] df_flow_6.rename(columns={'客流量':'星期六客流量'},inplace=True) df_compare=pd.concat([columns_convert_df(df_flow_7['星期日客流量']),columns_convert_df(df_flow_6['星期六客流量'])],axis=1) df_compare.plot(x='星期日客流量',y='星期六客流量')
二、底圖板塊
根據Pandas包裝後的kind關鍵字我們梳理一下底圖種類:
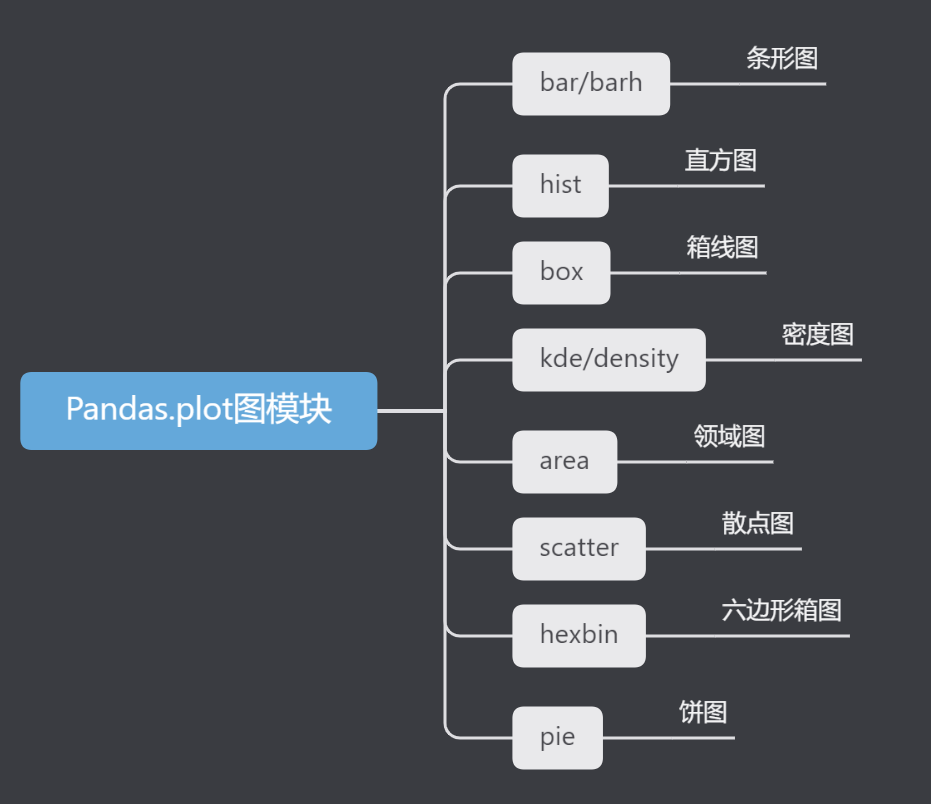
也可以使用DataFrame.plot方法創建這些其他繪圖而不是提供kind關鍵字參數。這使得更容易發現繪圖方法及其使用的特定參數:
df.plot.area df.plot.barh df.plot.density df.plot.hist df.plot.line df.plot.scatter
df.plot.bar df.plot.box df.plot.hexbin df.plot.kde df.plot.pie
除了這些類型,還有DataFrame.hist()和DataFrame.boxplot()方法,它們使用單獨的介面。
最後,pandas中有幾個繪圖功能。以Series或DataFrame作為參數的繪圖。其中包括:
-
Scatter Matrix
-
Andrews Curves
-
Parallel Coordinates
-
Lag Plot
-
Autocorrelation Plot
-
Bootstrap Plot
-
RadViz
分別是:
- 散射矩陣
- 安德魯斯曲線
- 平行坐標
- 滯後圖
- 自相關圖
- 引導圖
- 拉德維茲圖
繪圖也可以用錯誤條或表格進行裝飾。
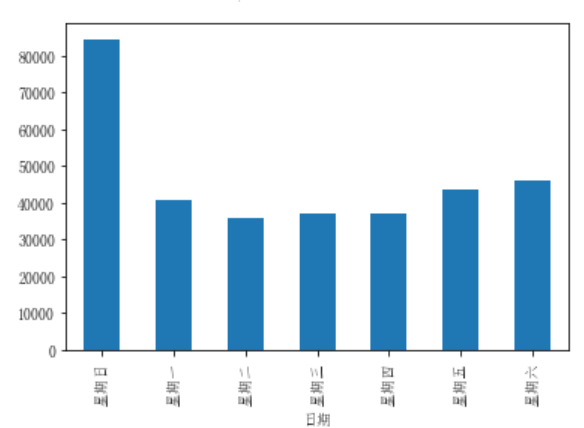
1、條形圖
df_flow_mark['客流量'].plot(kind='bar') df_flow_mark['客流量'].plot.bar()
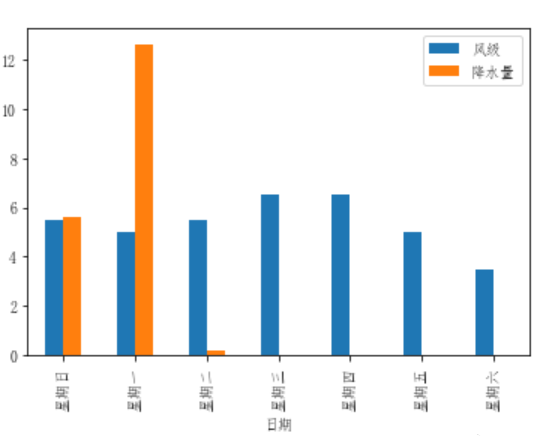
多個標簽圖表也可以一齊繪出:
df_flow_mark[['風級','降水量']].plot.bar()
要生成堆疊條形圖,傳遞stacked=True:
df_flow_mark[['風級','降水量']].plot.bar(stacked=True)

長久看這個maatplotlib的預設地圖有點疲勞了,我這裡換個主題,還是一樣的效果不礙事。
要獲得水平條形圖可以使用barh方法:
df_flow_mark[['風級','降水量']].plot.barh(stacked=True)

2、直方圖
可以使用DataFrame.plo.hist()和Series.plot.hist()方法繪製直方圖.
df4 = pd.DataFrame( { "a": np.random.randn(1000) + 1, "b": np.random.randn(1000), "c": np.random.randn(1000) - 1, }, columns=["a", "b", "c"], ) plt.figure(); df4.plot.hist(alpha=0.5)

直方圖可以使用stacked=True進行疊加。可以使用bins關鍵字更改bin大小。
df4.plot.hist(stacked=True, bins=20);

可以傳遞matplotlib hist支持的其他關鍵字。例如,水平和累積直方圖可以通過orientation='horizontal’和cumulative=True繪製。

有關詳細信息,可以參閱hist方法和matplotlib hist文檔。
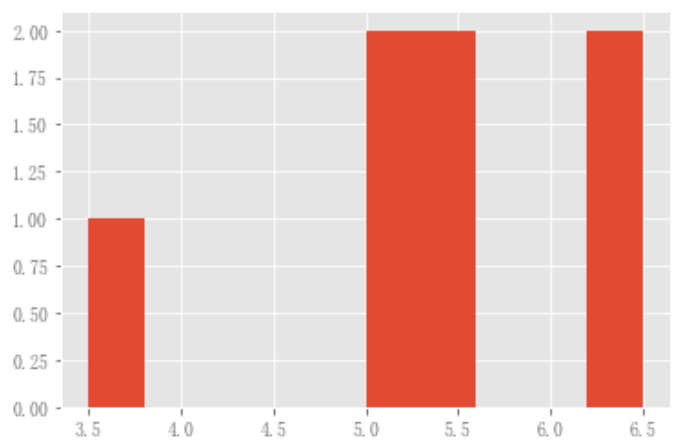
現有介面DataFrame.hist,但仍然可以使用hist繪製直方圖
plt.figure(); df_flow_mark['風級'].hist();
DataFrame.hist()可以在多個子地塊上繪製列的直方圖:
plt.figure(); df_flow_mark[['風級','降水量']].diff().hist(color="k", alpha=0.5, bins=50);
可以指定by關鍵字來繪製分組直方圖:
data = pd.Series(np.random.randn(1000))
data.hist(by=np.random.randint(0, 4, 1000), figsize=(6, 4));
此外,還可以在DataFrame.plot.hist()中指定by關鍵字:
data = pd.DataFrame( { "a": np.random.choice(["x", "y", "z"], 1000), "b": np.random.choice(["e", "f", "g"], 1000), "c": np.random.randn(1000), "d": np.random.randn(1000) - 1 } ) data.plot.hist(by=["a", "b"], figsize=(10, 5));
三、箱線圖
調用
- Series.plot.box()
- DataFrame.plot.box()
- DataFrame.boxplot()
可以繪製箱線圖可視化每個列中的值分佈。
df_flow_mark[['風級','降水量']].plot.box()

可以通過傳遞color關鍵字對Boxplot進行著色。你可以傳遞一個字典dict,key關鍵字為boxes、whiskers,medians,caps。如果dict中缺少一些鍵,則會為相應的使用預設顏色。此外,箱線圖還有sym關鍵字來指定傳單樣式。
color = { "boxes": "DarkGreen", "whiskers": "DarkOrange", "medians": "DarkBlue", "caps": "Gray", } df_flow_mark[['風級','降水量']].plot.box(color=color, sym="r+")

創建一個數據集展示更加明顯:
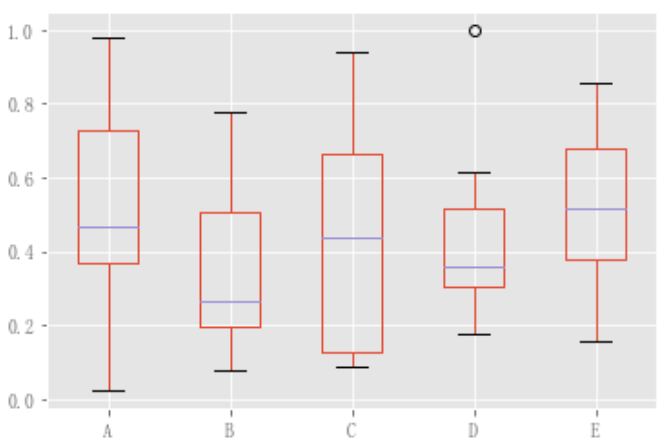
df = pd.DataFrame(np.random.rand(10, 5), columns=["A", "B", "C", "D", "E"]) color = { "boxes": "DarkGreen", "whiskers": "DarkOrange", "medians": "DarkBlue", "caps": "Gray", } df.plot.box(color=color, sym="r+")

此外,還可以傳遞matplotlib箱線圖支持的其他關鍵字。例如,可以通過vert=False和positions關鍵字繪製水平和自定義定位箱線圖。
df.plot.box(vert=False, positions=[1, 4, 5, 6, 8])
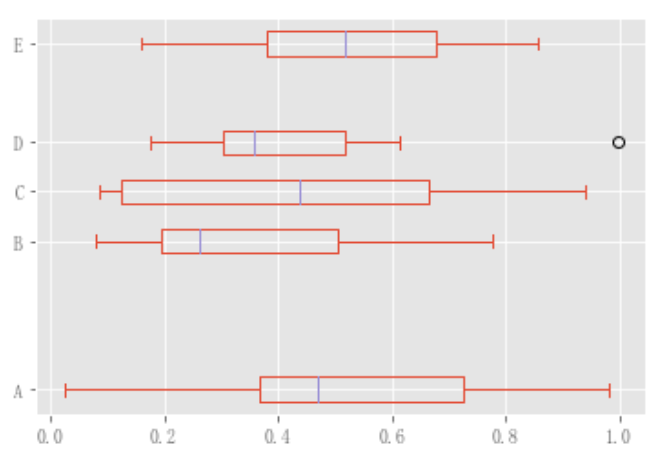
現有介面仍然可以使用DataFrame.boxplot:
df.boxplot()
可以使用by關鍵字參數創建分層箱線圖來創建分組。
例如
df = pd.DataFrame(np.random.rand(10, 2), columns=["Col1", "Col2"]) df["X"] = pd.Series(["A", "A", "A", "A", "A", "B", "B", "B", "B", "B"]) plt.figure(); bp = df.boxplot(by="X")

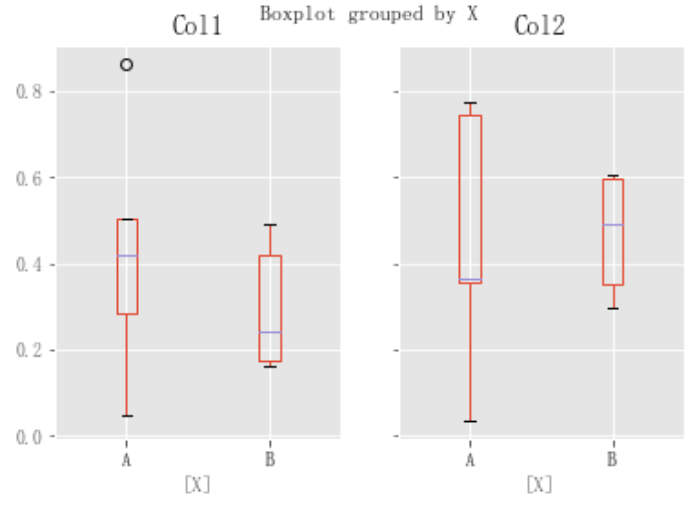
還可以傳遞要列印的列子集,以及按多個列分組:
df = pd.DataFrame(np.random.rand(10, 3), columns=["Col1", "Col2", "Col3"]) df["X"] = pd.Series(["A", "A", "A", "A", "A", "B", "B", "B", "B", "B"]) df["Y"] = pd.Series(["A", "B", "A", "B", "A", "B", "A", "B", "A", "B"]) plt.figure(); bp = df.boxplot(column=["Col1", "Col2"], by=["X", "Y"])

用DataFrame.plot.box()也是一樣的:
df = pd.DataFrame(np.random.rand(10, 3), columns=["Col1", "Col2", "Col3"]) df["X"] = pd.Series(["A", "A", "A", "A", "A", "B", "B", "B", "B", "B"]) plt.figure() bp = df.plot.box(columns=["Col1", "Col2"], by="X")
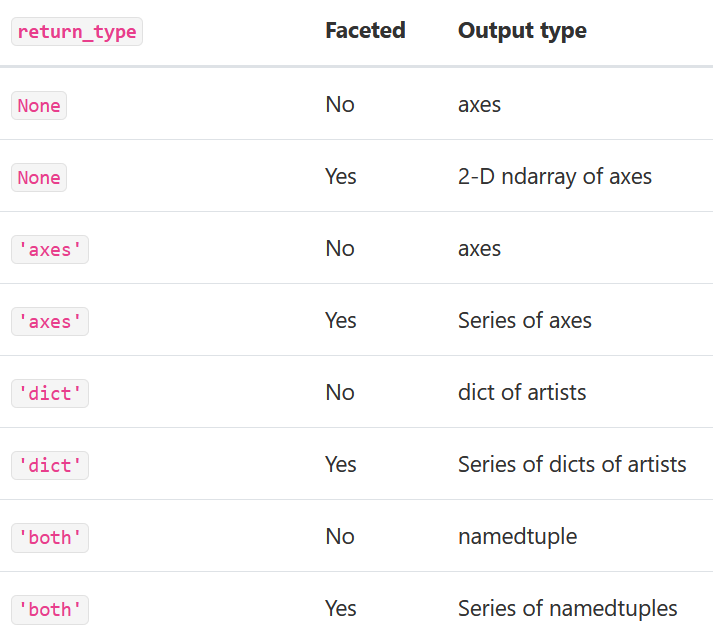
在箱線圖中,返回類型可以由return_type,關鍵字控制。有效選項是{“axes”、“dict”、“both”、“None}。鑲嵌面,由DataFrame.boxplot創建by關鍵字的箱線圖也會影響輸出類型:
np.random.seed(1234) df_box = pd.DataFrame(np.random.randn(50, 2)) df_box["g"] = np.random.choice(["A", "B"], size=50) df_box.loc[df_box["g"] == "B", 1] += 3 bp = df_box.boxplot(by="g")

上面的子地塊首先由數字列分割,然後由g列的值分割。下麵的子地塊首先由g值分割,然後由數字列分割。
bp = df_box.groupby("g").boxplot()

四、面積填充圖
可以使用Series.plot.area()和DataFrame.plot.area()創建面積圖。預設情況下,面積圖是堆疊的。要生成堆疊面積圖,每列必須全部為正值或全部為負值。
當輸入數據包含NaN時,它將自動由0填充。如果要使用不同的值進行刪除或填充,調用plot之前可以使用DataFrame.dropna()或DataFrame.fillna()。
代碼如下(示例):
df = pd.DataFrame(np.random.rand(10, 4), columns=["a", "b", "c", "d"]) df.plot.area();

要生成未堆疊的繪圖,請傳遞stacked=False。Alpha值設置為0.5。
df.plot.area(stacked=False);
五、散點圖
可以使用DataFrame.plot.scatter()方法繪製散點圖,散點圖需要x軸和y軸的數字列。這些可以由x和y關鍵字指定。
df_flow_mark.plot.scatter(x='日期',y='客流量')

要在單個軸上繪製多個列組,可以重覆指定目標軸的列印方法。建議指定顏色(color)和標簽(label)關鍵字以區分每個組。
df = pd.DataFrame(np.random.rand(50, 4), columns=["a", "b", "c", "d"]) df["species"] = pd.Categorical( ["setosa"] * 20 + ["versicolor"] * 20 + ["virginica"] * 10 ) ax = df.plot.scatter(x="a", y="b", color="DarkBlue", label="Group 1") df.plot.scatter(x="c", y="d", color="DarkGreen", label="Group 2", ax=ax);
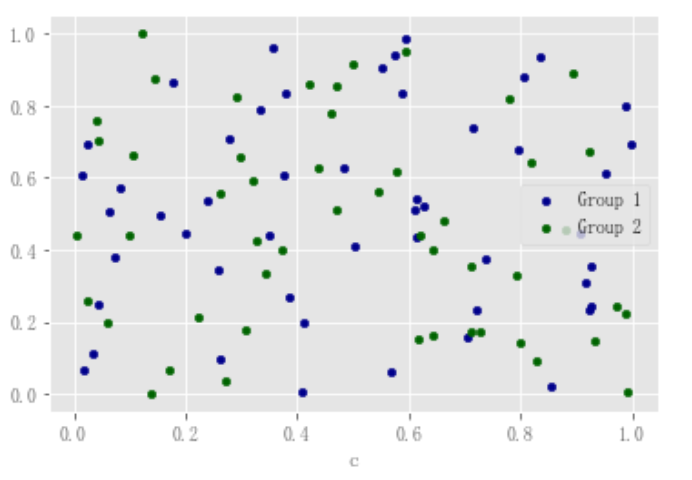
關鍵字c可以作為列的名稱,為每個點提供顏色:
df.plot.scatter(x="a", y="b", c="c", s=50);

如果將分類列傳遞給c,則將生成一個離散的顏色條:
df.plot.scatter(x="a", y="b", c="species", cmap="viridis", s=50);

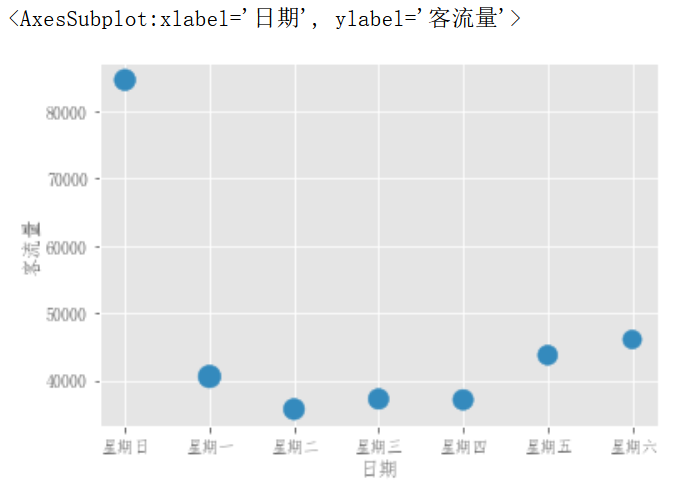
可以傳遞matplotlib.scatter支持的其他關鍵字。下麵的示例顯示了一個氣泡圖,它使用DataFrame的一列作為氣泡大小。
df_flow_mark.plot.scatter(x='日期',y='客流量',s=df_flow_mark['濕度']*200)
六、最後
最後給大家分享一套Python視頻:Python實戰100例
今天的分享就到這裡結束遼~
大家下次再見!



