
scrapy爬蟲框架 簡介 通過實戰快速入門scrapy爬蟲框架 scrapy爬蟲框架入門簡介 下載scrapy pip install scrapy 創建項目 scrapy startproject spiderTest1 創建爬蟲 cd .\spiderTest1 scrapy genspide ...
scrapy爬蟲框架
目錄簡介
通過實戰快速入門scrapy爬蟲框架
scrapy爬蟲框架入門簡介
下載scrapy
pip install scrapy
創建項目
scrapy startproject spiderTest1
創建爬蟲
cd .\spiderTest1
scrapy genspider douban movie.douban.com
將項目拖入pycharm
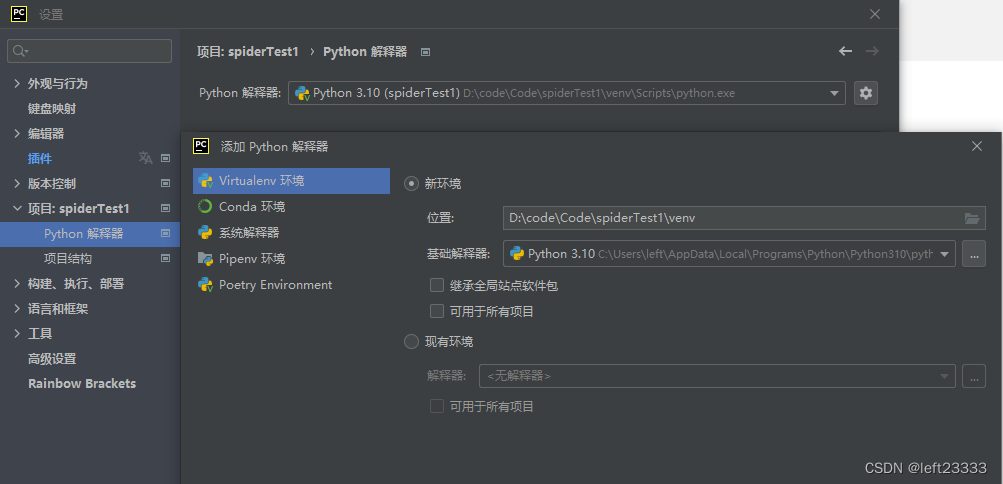
添加虛擬環境(python每一個項目都應當有專屬的虛擬環境)
設置->項目->python解釋器
不建議使用全局的python解釋器
點齒輪->點添加,將虛擬環境放在項目路徑下起名venv
項目目錄
在虛擬環境中,再次安裝scrapy 三方庫
設置settings.py文件
# 設置請求頭,偽裝成瀏覽器
USER_AGENT = 'Mozilla/5.0(Macintosh;intel Mac OS X 10_14_6)AppleWebKit/537.36(KHTML,like Gecko)Chrome/92.0.4515.159 Safari/537.36'
ROBOTSTXT_OBEY = True # 是否遵守爬蟲協議
CONCURRENT_REQUESTS = 2 # 設置併發
DOWNLOAD_DELAY = 2 # 下載延遲
RANDOMIZE_DOWNLOAD_DELAY = True #隨機延遲
# 當有多個管道,數字大的先執行,數字小的後執行
ITEM_PIPELINES = {
'spiderTest1.pipelines.ExcelPipeline': 300,
'spiderTest1.pipelines.AccessPipeline': 200,
}
運行爬蟲
scrapy crawl spiderName --nolog # --nolog不顯示日誌
scrapy crawl spiderName -o Nmae.csv # 保存為csv格式
python往excel寫數據,三方庫
pip install openpyxl
查看已經安裝了那些庫
pip list
pip freeze # 依賴清單
將依賴清單輸出requirements.txt保存
# >輸出重定向
pip freeze > requirements.txt
按依賴清單裝依賴項
pip install -r requirements.txt
網頁爬蟲代碼
douban.py
import scrapy
from scrapy import Selector, Request
from scrapy.http import HtmlResponse
from spiderTest1.items import movieItem
class DoubanSpider(scrapy.Spider):
name = 'douban'
allowed_domains = ['movie.douban.com']
start_urls = ['https://movie.douban.com/top250']
def start_requests(self):
for page in range(10):
# f格式化
yield Request(url=f'https://movie.douban.com/top250?start={page * 25}&filter=')
def parse(self, response: HtmlResponse, **kwargs):
sel = Selector(response)
list_items = sel.css('#content > div > div.article > ol > li')
for list_item in list_items:
movie_item = movieItem()
movie_item['title'] = list_item.css('span.title::text').extract_first()
movie_item['rank'] = list_item.css('span.rating_num::text').extract_first()
movie_item['subject'] = list_item.css('span.inq::text').extract_first()
yield movie_item
# 找到超鏈接爬取url
# hrefs_list = sel.css('div.paginator > a::attr(href)')
# for href in hrefs_list:
# url = response.urljoin(href.extract())
# yield Request(url=url)
在管道文件將資料庫寫入excel,資料庫等
piplines.py
import openpyxl
# import pymysql
import pyodbc
# 寫入access資料庫
class AccessPipeline:
def __init__(self):
# 鏈接資料庫
db_file = r"E:\left\Documents\spider.accdb" # 資料庫文件
self.conn = pyodbc.connect(
r"Driver={Microsoft access Driver (*.mdb, *.accdb)};DBQ=" + db_file + ";Uid=;Pwd=;charset='utf-8';")
# 創建游標
self.cursor = self.conn.cursor()
# 將數據放入容器進行批處理操作
self.data = []
def close_spider(self, spider):
self._write_to_db()
self.conn.close()
def _write_to_db(self):
sql = r"insert into tb_top_movie (title, rating, subject) values (%s, %s, %s)"
if len(self.data) > 0:
self.cursor.executemany(sql, self.data)
self.conn.commit()
# 清空原列表中的數據
self.data.clear()
# 回調函數 -->callback
def process_item(self, item, spider):
title = item.get('title', '')
rank = item.get('rank', '')
subject = item.get('subject', '')
# 單條數據插入,效率較低
# sql = "insert into [tb_top_movie] (title, rating, subject) values('"+title+"','"+rank+"','"+subject+"')"
# self.cursor.execute(sql)
# 批處理插入數據
self.data.append((title, rank, subject))
if len(self.data) == 50:
self._write_to_db()
return item
# 寫入Excel
class ExcelPipeline:
def __init__(self):
self.wb = openpyxl.Workbook() # 工作簿
self.ws = self.wb.active # 工資表
self.ws.title = 'Top250'
self.ws.append(('標題', '評分', '主題'))
def close_spider(self, spider):
self.wb.save('電影數據.xlsx')
# 回調函數 -->callback
def process_item(self, item, spider):
title = item.get('title', '')
rank = item.get('rank', '')
subject = item.get('subject', '')
self.ws.append((title, rank, subject))
return item
# 寫入mysql
# class DBPipeline:
# def __init__(self):
# # 鏈接資料庫
# self.conn = pymysql.connect(host='localhost', port=9555,
# user='left', passwd='123',
# database='spider', charset='utf8mb4')
# # 創建游標
# self.cursor = self.conn.cursor()
#
# def close_spider(self, spider):
# self.conn.commit()
# self.conn.close()
#
# # 回調函數 -->callback
# def process_item(self, item, spider):
# title = item.get('title', '')
# rank = item.get('rank', '')
# subject = item.get('subject', '')
# self.cursor.execute(
# 'insert into tb_top_movie (title, rating, subject) value(%s,%s,%s)',
# (title, rank, subject)
# )
# return item


