
ethtool ethtool的使用 不帶選項,預設輸出協商速率、最大速率、連接狀態等信息 -i | --driver 列印驅動信息 --set-priv-flags 設置網卡的私有屬性,比如將link-down-on-close置為true後可以使用ifconfig down去關閉網卡連接 -a ...
ethtool
ethtool的使用
不帶選項,預設輸出協商速率、最大速率、連接狀態等信息
-i | --driver 列印驅動信息
--set-priv-flags 設置網卡的私有屬性,比如將link-down-on-close置為true後可以使用ifconfig down去關閉網卡連接
-a |--show-pause 查看乙太網是否啟用暫停幀(Pause Frame),暫停幀主要用於MAC層的流控。
-A |--pause DEVNAME 設置tx、rx和自動協商模式是否開啟暫停幀
-K 是否開啟TCP的offload機制
-m 獲取網卡的EEPROM信息
ethtool數據獲取流程
ethtool和內核的通信流程如下圖所示:
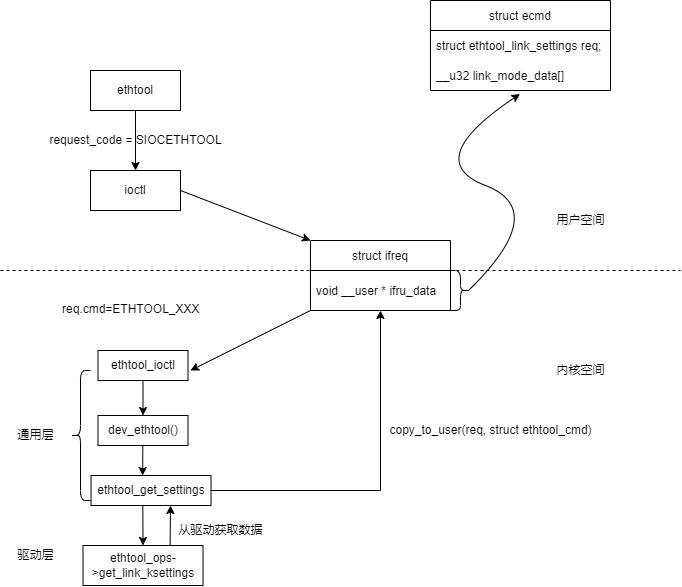
figure1 ethtool數據獲取流程圖
ethtool使用ioctl去操作網卡,需要指定ioctl的request code為SIOCETHTOOL。可以對網卡進行的操作都定義在ethtool.h中,常見的操作碼有
ETHTOOL_GLINKSETTINGS(獲取link狀態,協商速率)、ETHTOOL_GDRVINFO(獲取驅動信息)。用戶和內核使用struct ifreq交換通信數據,
在用戶態,ethtool的主要工作是
1、構造傳入內核的結構體,在源碼中使用了自定義的命令格式去封裝了和內核一致的結構體,比如struct ethtool_link_settings,這個結構體在ethtool源碼和內核的include/uapi/linux/ethtool.h中都存在一份。給struct ifreq的ifru_data賦值為struct ecmd
2、調用ioctl,把struct ifreq傳入內核
3、解析獲取的數據,構造命令輸出
在內核,ethtool的主要經過了通用層和驅動層,其中一些操作能夠在通用層完成,不能在通用層完成,就繼續把請求傳遞到驅動層。net_device中的ethtool_ops包含了所有能夠通過ethtool執行的操作,這個結構體在內核模塊插入的時候通過 SET_ETHTOOL_OPS 進行初始化。
//用戶態主要代碼
int ioctl(int fd, unsigned long request, ...);
struct {
struct ethtool_link_settings req;
__u32 link_mode_data[3 * ETHTOOL_LINK_MODE_MASK_MAX_KERNEL_NU32];
} ecmd;
struct ethtool_value {
__u32 cmd;
__u32 data;
};
//內核態主要代碼
struct ifreq {
void __user * ifru_data;
}
struct ethtool_ops {
int (*get_settings)(struct net_device *, struct ethtool_cmd *);
int (*set_settings)(struct net_device *, struct ethtool_cmd *);
void (*get_drvinfo)(struct net_device *, struct ethtool_drvinfo *);
int (*get_regs_len)(struct net_device *);
void (*get_regs)(struct net_device *, struct ethtool_regs *, void *);
void (*get_wol)(struct net_device *, struct ethtool_wolinfo *);
int (*set_wol)(struct net_device *, struct ethtool_wolinfo *);
u32 (*get_msglevel)(struct net_device *);
void (*set_msglevel)(struct net_device *, u32);
int (*nway_reset)(struct net_device *);
u32 (*get_link)(struct net_device *);
int (*get_eeprom_len)(struct net_device *);
int (*get_eeprom)(struct net_device *,
struct ethtool_eeprom *, u8 *);
int (*set_eeprom)(struct net_device *,
struct ethtool_eeprom *, u8 *);
int (*get_coalesce)(struct net_device *, struct ethtool_coalesce *);
int (*set_coalesce)(struct net_device *, struct ethtool_coalesce *);
void (*get_ringparam)(struct net_device *,
struct ethtool_ringparam *);
int (*set_ringparam)(struct net_device *,
struct ethtool_ringparam *);
void (*get_pauseparam)(struct net_device *,
struct ethtool_pauseparam*);
int (*set_pauseparam)(struct net_device *,
struct ethtool_pauseparam*);
void (*self_test)(struct net_device *, struct ethtool_test *, u64 *);
void (*get_strings)(struct net_device *, u32 stringset, u8 *);
int (*set_phys_id)(struct net_device *, enum ethtool_phys_id_state);
void (*get_ethtool_stats)(struct net_device *,
struct ethtool_stats *, u64 *);
int (*begin)(struct net_device *);
void (*complete)(struct net_device *);
u32 (*get_priv_flags)(struct net_device *);
int (*set_priv_flags)(struct net_device *, u32);
int (*get_sset_count)(struct net_device *, int);
int (*get_rxnfc)(struct net_device *,
struct ethtool_rxnfc *, u32 *rule_locs);
int (*set_rxnfc)(struct net_device *, struct ethtool_rxnfc *);
int (*flash_device)(struct net_device *, struct ethtool_flash *);
int (*reset)(struct net_device *, u32 *);
u32 (*get_rxfh_key_size)(struct net_device *);
u32 (*get_rxfh_indir_size)(struct net_device *);
int (*get_rxfh)(struct net_device *, u32 *indir, u8 *key,
u8 *hfunc);
int (*set_rxfh)(struct net_device *, const u32 *indir,
const u8 *key, const u8 hfunc);
int (*get_rxfh_context)(struct net_device *, u32 *indir, u8 *key,
u8 *hfunc, u32 rss_context);
int (*set_rxfh_context)(struct net_device *, const u32 *indir,
const u8 *key, const u8 hfunc,
u32 *rss_context, bool delete);
void (*get_channels)(struct net_device *, struct ethtool_channels *);
int (*set_channels)(struct net_device *, struct ethtool_channels *);
int (*get_dump_flag)(struct net_device *, struct ethtool_dump *);
int (*get_dump_data)(struct net_device *,
struct ethtool_dump *, void *);
int (*set_dump)(struct net_device *, struct ethtool_dump *);
int (*get_ts_info)(struct net_device *, struct ethtool_ts_info *);
int (*get_module_info)(struct net_device *,
struct ethtool_modinfo *);
int (*get_module_eeprom)(struct net_device *,
struct ethtool_eeprom *, u8 *);
int (*get_eee)(struct net_device *, struct ethtool_eee *);
int (*set_eee)(struct net_device *, struct ethtool_eee *);
int (*get_tunable)(struct net_device *,
const struct ethtool_tunable *, void *);
int (*set_tunable)(struct net_device *,
const struct ethtool_tunable *, const void *);
int (*get_per_queue_coalesce)(struct net_device *, u32,
struct ethtool_coalesce *);
int (*set_per_queue_coalesce)(struct net_device *, u32,
struct ethtool_coalesce *);
int (*get_link_ksettings)(struct net_device *,
struct ethtool_link_ksettings *);
int (*set_link_ksettings)(struct net_device *,
const struct ethtool_link_ksettings *);
int (*get_fecparam)(struct net_device *,
struct ethtool_fecparam *);
int (*set_fecparam)(struct net_device *,
struct ethtool_fecparam *);
void (*get_ethtool_phy_stats)(struct net_device *,
struct ethtool_stats *, u64 *);
};
數據收發流程
包傳輸流程
在網卡層面,數據的傳輸使用transmission(通信領域的專有名詞)表達。驅動的包傳輸過程,巨集觀上講就是把內核協議棧構造好的IP報文向下傳遞給驅動層,然後
再次封裝成乙太網幀並通過介質傳播出去的過程。封裝乙太網幀頭的過程通過dev_hard_header調用header_ops->create完成(在協議棧層),傳輸過程在驅動
中完成。
啟動傳輸的介面時net_device中的ndo_start_xmit(老版本是hard_start_xmit)。
netdev_tx_t (*ndo_start_xmit)(struct sk_buff *skb, struct net_device *dev);
這個介面需要由驅動程式進行實現,通用的實現邏輯是:
1、給skb->data填充padding
2、設置dev->trans_start
3、設備的私有數據引用skb
4、執行設備相關的發送邏輯(設置寄存器等)
sk_buff
struct sk_buff是整個內核網路數據交換、傳輸的核心數據結構。
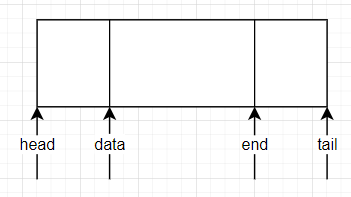
figure2 sk_buff結構圖
重要屬性
struct sk_buff {
//發送或者接收該BUFFER的設備
struct net_device *dev;
//操作buffer的指針
unsigned char *head;
unsigned char *data;
unsigned char *tail;
unsigned char *end;
//len是整個sk_buff的長度,等於tail-head;
//data_len是sk_buff存儲的有效數據的長度,等於end-data
unsigned int len;
unsigned int data_len;
};
重要方法
skb_put給buffer尾部增加數據
skb_push給buffer頭部增加數據
skb_pull刪除buffer頭部的數據
skb_reserve給buffer頭部預留len位元組的空間
unsigned char *skb_put(struct sk_buff *skb, int len);
unsigned char *skb_push(struct sk_buff *skb, int len);
unsigned char *skb_pull(struct sk_buff *skb, int len);
void skb_reserve(struct sk_buff *skb, int len);

figure3 sk_buff操作示意圖(參考[1])
流量控制
網卡的傳播隊列大小有限,當隊列達到上限的時候,驅動需要通知上層不要暫停發送新的數據包。這個工作由netif_stop_queue完成。
需要註意的是,如果在stop隊列之後,在之後的某個時間點(具體這個時間點怎麼確定是設備相關的)需要重啟傳播隊列。重啟隊列使用netif_wake_queue完成。netif_tx_disable 主要在ndo_start_xmit之外的場景使用,它可以保證在disable函
數生效之後,內核不會在別的CPU上再次調用ndo_start_xmit使得disable失效。
static inline void netif_stop_queue(struct net_device *dev);
static inline void netif_wake_queue(struct net_device *dev);
static inline void netif_tx_disable(struct net_device *dev)
數據包傳播超時
當系統流量比較大時,數據包的發送可能會超時,當數據包傳播超時的時候會調用net_device->ndo_tx_timeout函數。在ndo_tx_timeout函數中,一般會執行一下操作:
1、補全缺失的中斷
2、重啟傳播隊列:netif_wake_queue
包接收流程
驅動接收包的過程是從PHY接收數據然後構造成sk_buf傳遞給上層的過程。接收包的方式有中斷和NAPI兩種方式,NAPI 是 Linux 上採用的一種提高網路處理效率
的技術,它的核心概念就是不採用中斷的方式讀取數據,而代之以首先採用中斷喚醒數據接收的服務程式,然後 POLL 的方法來輪詢數據。
常規的中斷處理程式流程:
1、給設備加鎖
2、從寄存器獲取中斷狀態
3、判斷中斷類型,tx中斷還是rx中斷
4、釋放設備鎖和sk_buffer占用的資源
/*
* The typical interrupt entry point
*/
static void snull_regular_interrupt(int irq, void *dev_id, struct pt_regs *regs)
{
int statusword;
struct snull_priv *priv;
struct snull_packet *pkt = NULL;
struct net_device *dev = (struct net_device *)dev_id;
/* Lock the device */
priv = netdev_priv(dev);
spin_lock(&priv->lock);
/* retrieve statusword: real netdevices use I/O instructions */
statusword = priv->status;
priv->status = 0;
if (statusword & SNULL_RX_INTR) {
/* send it to snull_rx for handling */
pkt = priv->rx_queue;
if (pkt) {
priv->rx_queue = pkt->next;
snull_rx(dev, pkt);
}
}
if (statusword & SNULL_TX_INTR) {
/* a transmission is over: free the skb */
priv->stats.tx_packets++;
priv->stats.tx_bytes += priv->tx_packetlen;
dev_kfree_skb(priv->skb);
}
/* Unlock the device and we are done */
spin_unlock(&priv->lock);
if (pkt) snull_release_buffer(pkt); /* Do this outside the lock! */
return;
}
中斷處理函數
接受包的中斷處理
1、從接收隊列中獲取一個包
2、創建一個skb_buff,長度是datalen+2,2是給預留空間的
3、調用skb_reserve(2),給skb_buff中的data在頭部預留2兩個位元組。乙太網頭部是14位元組,保留兩個位元組就IP頭部的起始地址就剛好16位元組對齊。
對齊之後,可以減少CPU訪問硬體Cache的次數。
CPUs often take a performance hit when accessing unaligned memory locations. The actual performance hit varies, it can be small if the hardware
handles it or large if we have to take an exception and fix it in software. Since an ethernet header is 14 bytes network drivers often end up with the
IP header at an unaligned offset. The IP header can be aligned by shifting the start of the packet by 2 bytes. Drivers should do this with
skb_reserve(skb, NET_IP_ALIGN);
3、並將上一步獲取到的包拷貝到skb中
4、設置skb結構
(1)dev:表示該包是由那個設備接收的
(2)protocol: sk_buff的protocol欄位是一個 __be16 類型的變數,表示每一層所用的協議,並且每一層該欄位的值都不同。在驅動中使用幫助函數
eth_type_trans去給該欄位賦值。
skb->protocol = eth_type_trans(skb, dev);
(3)ip_summed:該欄位表示驅動接收的包是否經過校驗。可以取的值有:
CHECKSUM_HW : 表示包已經有硬體做過校驗,上層(網路層)可以跳過校驗。
CHECKSUM_NONE : 表示包沒有做過校驗,上層需要做校驗和
CHECKSUM_UNNECESSARY:表示不執行校驗,loopback設備執行這個選項
(4)更新統計數據,stats.rx_packets加1,stats.rx_bytes增加skb_buff中有效數據的長度
5、調用 netif_rx 通知內核已經接收了一個數據包並構造成了sk_buff,值得註意的是這是一個非同步的過程
void netif_rx(struct sk_buff *skb);
包傳播成功的中斷處理
在數據包成功從網卡傳播到介質上時,網卡會發送一個成功的中斷信號,對於這種中斷的處理比較簡單,主要的工作是
1、更新統計數據
2、釋放給sk_buff分配的空間
NAPI
NAPI是為了針對傳統中斷在處理大流量場景時,占用CPU太多導致的網路吞吐慢的問題,而提出的一種新的包接收模式。其核心思想是只使用中斷去通知CPU一個包接收階段的開始,一旦開始真正進行包傳輸就切換到輪詢(POLL)模式,輪詢在大流量(批處理)場景由於不涉及到中斷,具備較高的數據吞吐。
使用NAPI,我們需要在網卡驅動初始化的時候,初始化napi_struct結構。所有
/*
* Structure for NAPI scheduling similar to tasklet but with weighting
*/
struct napi_struct {
/* The poll_list must only be managed by the entity which
* changes the state of the NAPI_STATE_SCHED bit. This means
* whoever atomically sets that bit can add this napi_struct
* to the per-CPU poll_list, and whoever clears that bit
* can remove from the list right before clearing the bit.
*/
struct list_head poll_list;
unsigned long state;
int weight;
unsigned long gro_bitmask;
int (*poll)(struct napi_struct *, int);
#ifdef CONFIG_NETPOLL
int poll_owner;
#endif
struct net_device *dev;
struct gro_list gro_hash[GRO_HASH_BUCKETS];
struct sk_buff *skb;
struct hrtimer timer;
struct list_head dev_list;
struct hlist_node napi_hash_node;
unsigned int napi_id;
};
使用NAPI的中斷處理函數:
1、關閉中斷,停止接收新的中斷
2、使用napi_schedule調度poll函數執行
一個典型的poll函數的流程
1、獲取設備私有數據結構
struct snull_priv {
struct net_device_stats stats;
int status;
struct snull_packet *ppool;
struct snull_packet *rx_queue;
int rx_int_enabled;
int tx_packetlen;
u8 *tx_packetdata;
struct sk_buff *skb;
spinlock_t lock;
};
2、loop接收隊列,當接收的包超過系統的budget的時候退出迴圈
3、loop內邏輯
(1)從隊列中獲取包
(2)和常規中斷一致的流程
源碼
__be16 eth_type_trans(struct sk_buff *skb, struct net_device *dev)
{
unsigned short _service_access_point;
const unsigned short *sap;
const struct ethhdr *eth;
skb->dev = dev;
skb_reset_mac_header(skb);
eth = (struct ethhdr *)skb->data;
skb_pull_inline(skb, ETH_HLEN);
if (unlikely(is_multicast_ether_addr_64bits(eth->h_dest))) {
if (ether_addr_equal_64bits(eth->h_dest, dev->broadcast))
skb->pkt_type = PACKET_BROADCAST;
else
skb->pkt_type = PACKET_MULTICAST;
}
else if (unlikely(!ether_addr_equal_64bits(eth->h_dest,
dev->dev_addr)))
skb->pkt_type = PACKET_OTHERHOST;
/*
* Some variants of DSA tagging don't have an ethertype field
* at all, so we check here whether one of those tagging
* variants has been configured on the receiving interface,
* and if so, set skb->protocol without looking at the packet.
*/
if (unlikely(netdev_uses_dsa(dev)))
return htons(ETH_P_XDSA);
if (likely(eth_proto_is_802_3(eth->h_proto)))
return eth->h_proto;
/*
* This is a magic hack to spot IPX packets. Older Novell breaks
* the protocol design and runs IPX over 802.3 without an 802.2 LLC
* layer. We look for FFFF which isn't a used 802.2 SSAP/DSAP. This
* won't work for fault tolerant netware but does for the rest.
*/
sap = skb_header_pointer(skb, 0, sizeof(*sap), &_service_access_point);
if (sap && *sap == 0xFFFF)
return htons(ETH_P_802_3);
/*
* Real 802.2 LLC
*/
return htons(ETH_P_802_2);
}
void snull_rx(struct net_device *dev, struct snull_packet *pkt)
{
struct sk_buff *skb;
struct snull_priv *priv = netdev_priv(dev);
/*
* The packet has been retrieved from the transmission
* medium. Build an skb around it, so upper layers can handle it
*/
skb = dev_alloc_skb(pkt->datalen + 2);
skb_reserve(skb, 2); /* align IP on 16B boundary */
memcpy(skb_put(skb, pkt->datalen), pkt->data, pkt->datalen);
/* Write metadata, and then pass to the receive level */
skb->dev = dev;
skb->protocol = eth_type_trans(skb, dev);
skb->ip_summed = CHECKSUM_UNNECESSARY; /* don't check it */
priv->stats.rx_packets++;
priv->stats.rx_bytes += pkt->datalen;
(skb);
return;
}
參考
[1] 深入理解linux網路技術內幕
[2] LDD3
[3] https://sites.google.com/site/emmoblin/smp-yan-jiu/napi
[4] https://blog.51cto.com/u_15127616/3436261


