
大家好,今天給大家介紹一款輕量、快速、穩定可編排的組件式規則引擎框架LiteFlow。 一、LiteFlow的介紹 LiteFlow官方網站和代碼倉庫地址 官方網站:https://yomahub.com/liteflow Gitee托管倉庫:https://gitee.com/dromara/li ...
大家好,今天給大家介紹一款輕量、快速、穩定可編排的組件式規則引擎框架LiteFlow。
一、LiteFlow的介紹
LiteFlow官方網站和代碼倉庫地址
官方網站:https://yomahub.com/liteflow
Gitee托管倉庫:https://gitee.com/dromara/liteFlow
Github托管倉庫:https://github.com/dromara/liteflow
前言
在每個公司的系統中,總有一些擁有複雜業務邏輯的系統,這些系統承載著核心業務邏輯,幾乎每個需求都和這些核心業務有關,這些核心業務業務邏輯冗長,涉及內部邏輯運算,緩存操作,持久化操作,外部資源調取,內部其他系統RPC調用等等。時間一長,項目幾經易手,維護的成本就會越來越高。各種硬代碼判斷,分支條件越來越多。代碼的抽象,復用率也越來越低,各個模塊之間的耦合度很高。一小段邏輯的變動,會影響到其他模塊,需要進行完整回歸測試來驗證。如要靈活改變業務流程的順序,則要進行代碼大改動進行抽象,重新寫方法。實時熱變更業務流程,幾乎很難實現。
LiteFlow框架的作用
LiteFlow就是為解耦複雜邏輯而生,如果你要對複雜業務邏輯進行新寫或者重構,用LiteFlow最合適不過。它是一個輕量,快速的組件式流程引擎框架,組件編排,幫助解耦業務代碼,讓每一個業務片段都是一個組件,並支持熱載入規則配置,實現即時修改。
使用LiteFlow,你需要去把複雜的業務邏輯按代碼片段拆分成一個個小組件,並定義一個規則流程配置。這樣,所有的組件,就能按照你的規則配置去進行複雜的流轉。
LiteFlow的設計原則
LiteFlow是基於工作台模式進行設計的,何謂工作台模式?
n個工人按照一定順序圍著一張工作台,按順序各自生產零件,生產的零件最終能組裝成一個機器,每個工人只需要完成自己手中零件的生產,而無需知道其他工人生產的內容。每一個工人生產所需要的資源都從工作臺上拿取,如果工作臺上有生產所必須的資源,則就進行生產,若是沒有,就等到有這個資源。每個工人所做好的零件,也都放在工作臺上。
這個模式有幾個好處:
- 每個工人無需和其他工人進行溝通。工人只需要關心自己的工作內容和工作臺上的資源。這樣就做到了每個工人之間的解耦和無差異性。
- 即便是工人之間調換位置,工人的工作內容和關心的資源沒有任何變化。這樣就保證了每個工人的穩定性。
- 如果是指派某個工人去其他的工作台,工人的工作內容和需要的資源依舊沒有任何變化,這樣就做到了工人的可復用性。
- 因為每個工人不需要和其他工人溝通,所以可以在生產任務進行時進行實時工位更改:替換,插入,撤掉一些工人,這樣生產任務也能實時地被更改。這樣就保證了整個生產任務的靈活性。
這個模式映射到LiteFlow框架里,工人就是組件,工人坐的順序就是流程配置,工作台就是上下文,資源就是參數,最終組裝的這個機器就是這個業務。正因為有這些特性,所以LiteFlow能做到統一解耦的組件和靈活的裝配。
二、LiteFlow的使用
1)非Spring環境下
引入pom依賴
<dependency>
<groupId>com.yomahub</groupId>
<artifactId>liteflow-core</artifactId>
<version>2.6.13</version>
</dependency>第一步構建自己的業務Node,也就是繼承NodeComponent,重寫process方法,業務執行的過程中,會調用process來執行節點的業務。
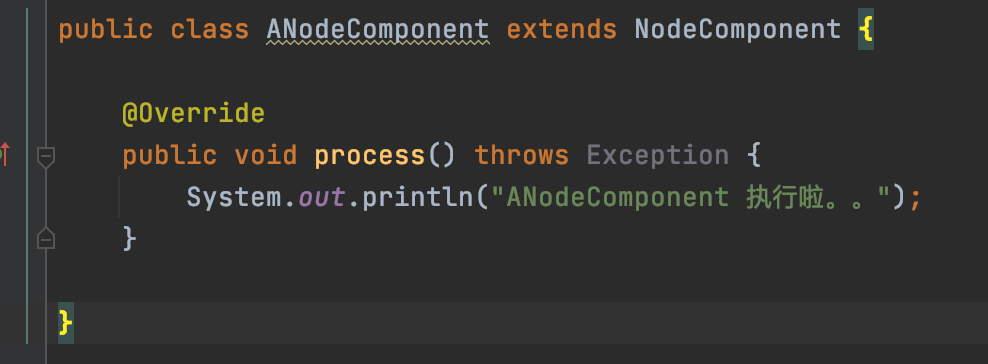
我這裡寫了三個
然後編寫xml文件,直接放在resources底下
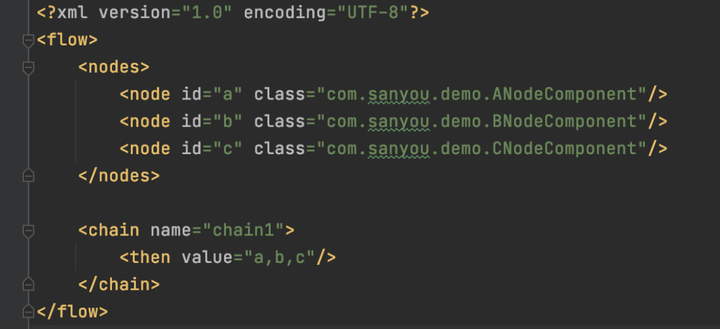
<nodes/>配置了每個業務的節點,這裡配置了我們寫的那幾個,<chain/>標簽代表了每一個業務的執行流程,配置了<when/>和<then/>標簽,然後value標簽設置了上面配置的<node/>的id,至於為什麼這麼配置,後面會解析。
然後執行這個demo
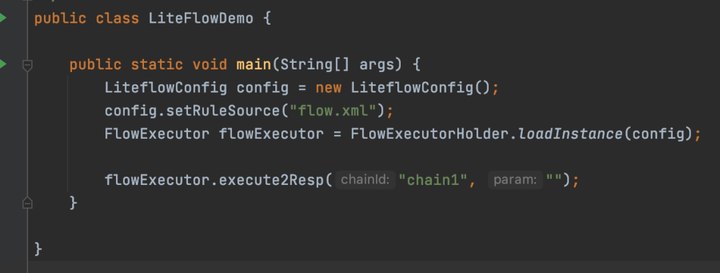
構建了一個LiteflowConfig,傳入xml的路徑,然後構建FlowExecutor,最後調用FlowExecutor的execute2Resp,傳入需要執行的業務流程名字 chain1 ,就是xml中配置的,執行業務流程。
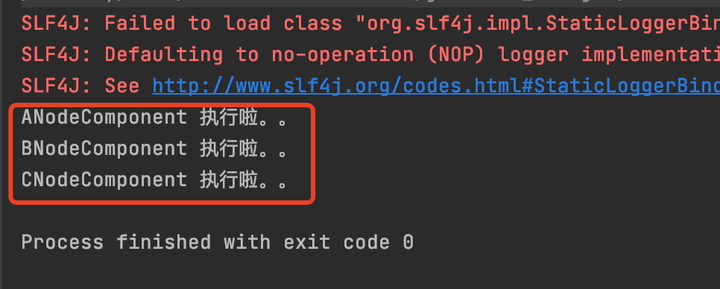
結果
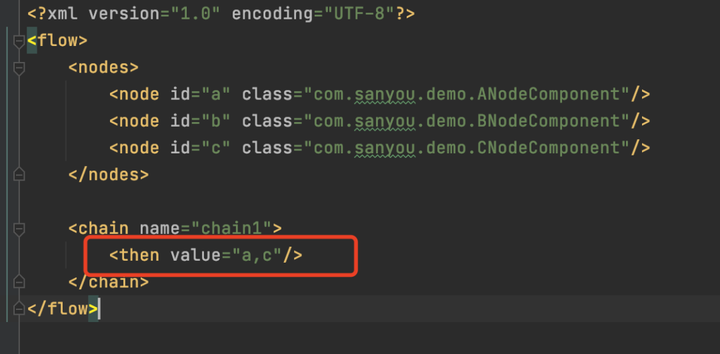
如果業務變動,現在不需要執行B流程了,那麼直接修改規則文件就行了,如圖。
運行結果
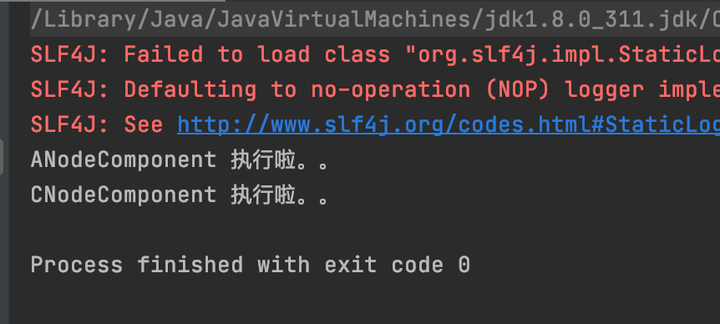
這裡發現B就沒執行了。
2)SpringBoot環境下
引入pom依賴
<dependency>
<groupId>com.yomahub</groupId>
<artifactId>liteflow-spring-boot-starter</artifactId>
<version>2.6.13</version>
</dependency>構建自己的業務Node,只不過在Spring的環境底下,可以不需要在xml配置<node/>標簽,直接使用@LiteflowComponent註解即可

xml中沒有聲明<node/>標簽
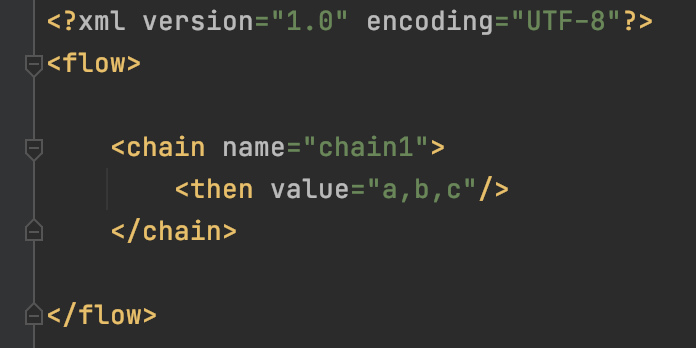
application.properties中配置xml文件的路徑
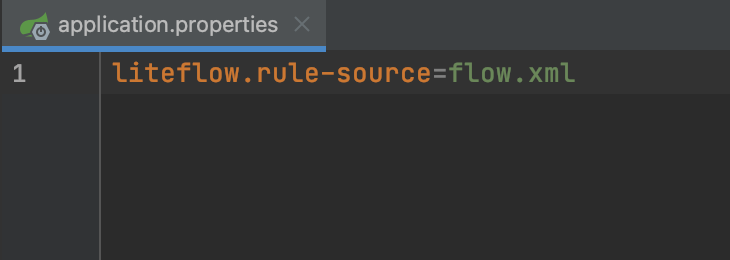
測試代碼
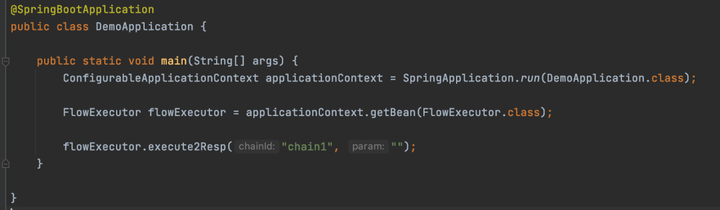
執行結果
跟非spring的環境結果一致。
如果有想要獲取demo的小伙伴在微信公眾號 三友的java日記 後臺回覆 LiteFlow 即可獲取。
通過上面的例子我們可以看出,其實每個業務節點之間是沒有耦合的,用戶只需要按照一定的業務規則配置節點的執行順序,LiteFlow就能實現業務的執行。
三、LiteFlow核心組件講解
講解核心組件的時候如果有什麼不是太明白的,可以繼續往下看,後面會有源碼解析。
下圖為LiteFlow整體架構圖
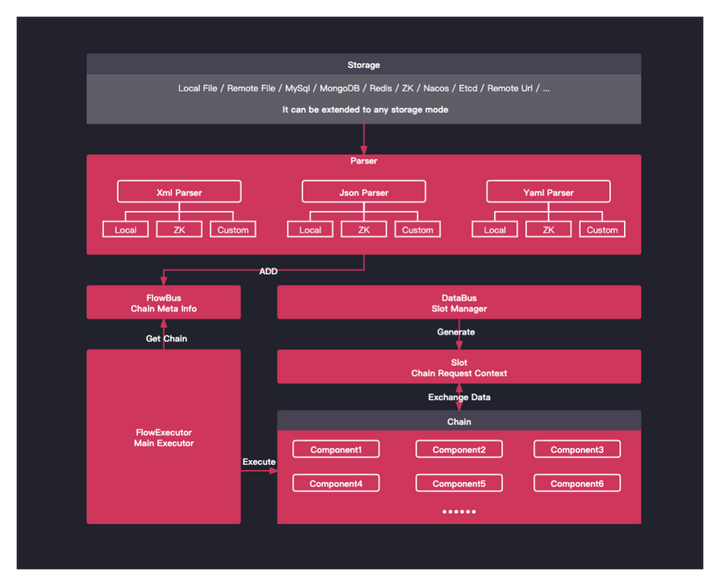
1)Parser
這個組件的作用就是用來解析流程配置的規則,也就是將你配置的規則文件解析成Java代碼來運行。支持的文件格式有xml、json、yaml,其實不論是什麼格式,只是形式的不同,用戶可根據自身配置的習慣來選擇規則文件的格式。
同時,規則文件的存儲目前官方支持基於zk或者本地文件的形式,同時也支持自定義的形式。
對於xml來說,Parser會將<node/>標簽解析成Node對象,將<chain/>解析成Chain對象,將<chain/>內部的比如<when/>、<then/>等標簽都會解析成Condition對象。
如下圖所示。
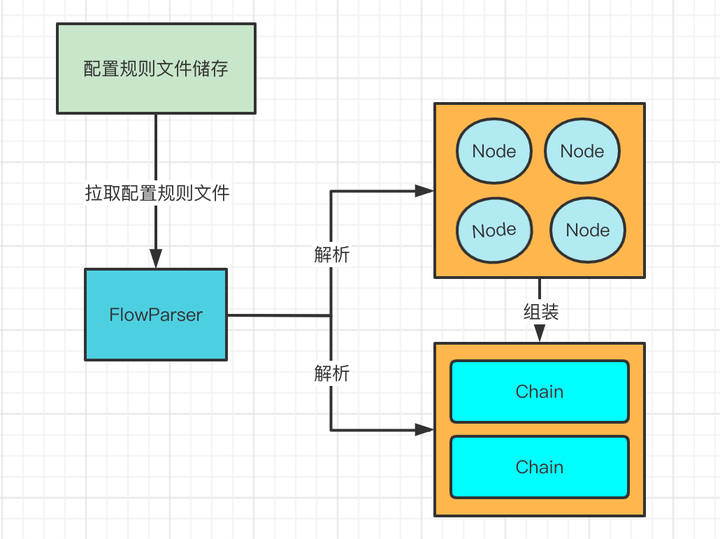
- Node其實就是代表了你具體業務執行的節點,就是真正的業務是在Node中執行的
- Condition可以理解為一種條件,比如前置條件,後置條件,裡面一個Condition可以包含許多需要執行的Node
- Chain可以理解成整個業務執行的流程,按照一定的順序來執行Condition中的Node也就是業務節點
Condition和Node的關係
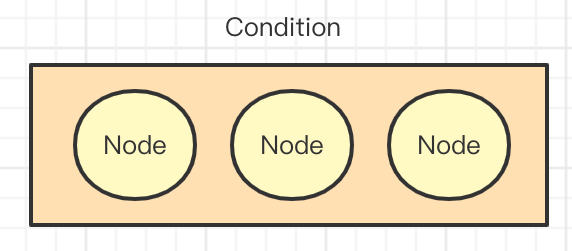
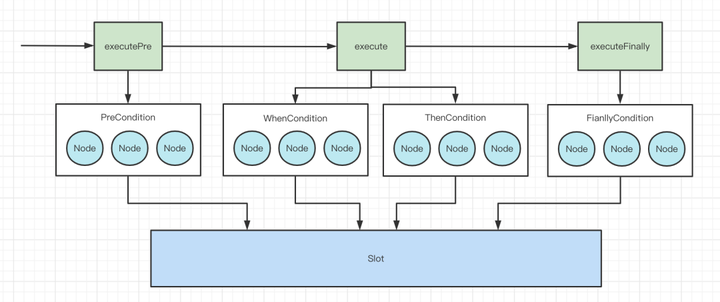
Condition分為以下幾種
- PreCondition:在整個業務執行前執行,就是前置的作用
- ThenCondition:內部的Node是串列執行的
- WhenCondition:內部的Node是並行執行的
- FinallyCondition:當前面的Condition中的Node都執行完成之後,就會執行這個Condition中的Node節點
Chain和Condition的關係
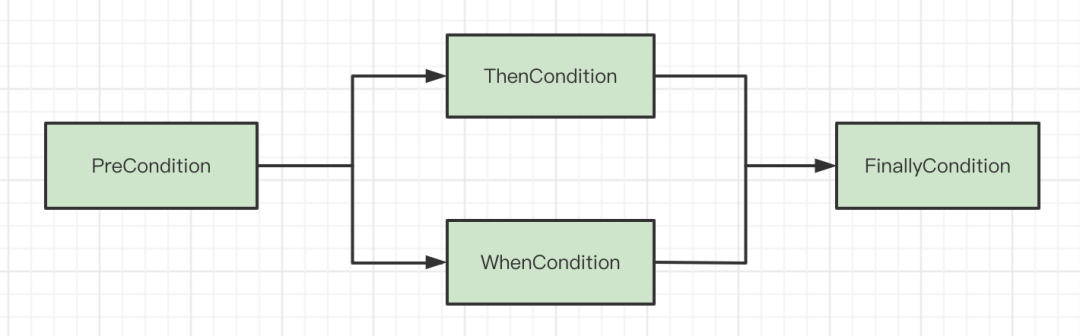
Chain內部其實就是封裝了一堆Condition,Chain的執行就是指從不同的Condition中拿出裡面的Node來執行,首先會拿出來PreCondition中的Node節點來執行,執行完之後會執行ThenCondition和WhenCondition中的Node節點,最後執行完之後才會執行FinallyCondition中的Node節點。
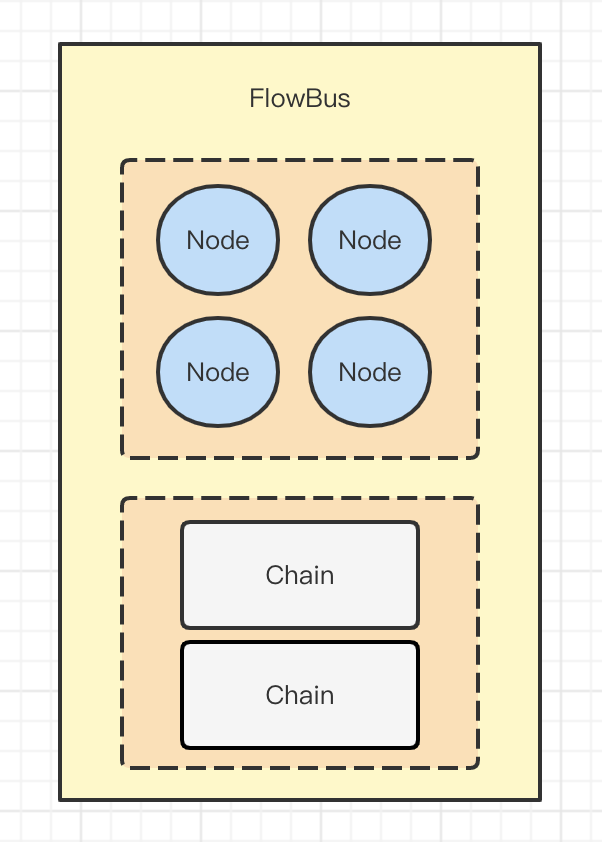
2)FlowBus
這個組件主要是用來存儲上一步驟解析出來的Node和Chain的
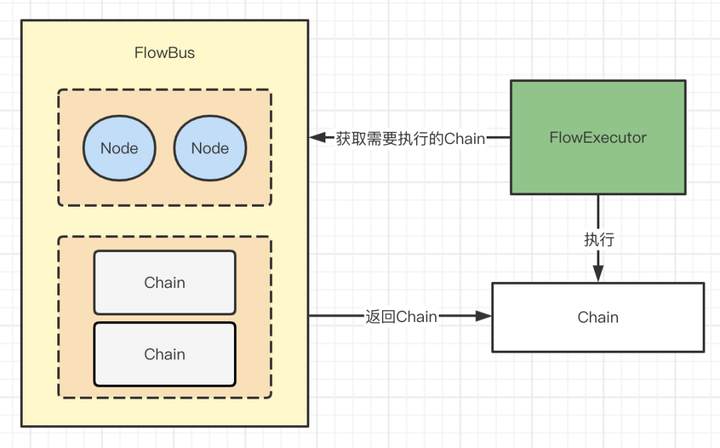
3)FlowExecutor
這個其實是用來執行上面解析出來的業務流程,從FlowBus找到需要執行的業務流程Chain,然後執行Chain,也就是按照Condition的順序來分別執行每個Condition的Node,也就是業務節點。
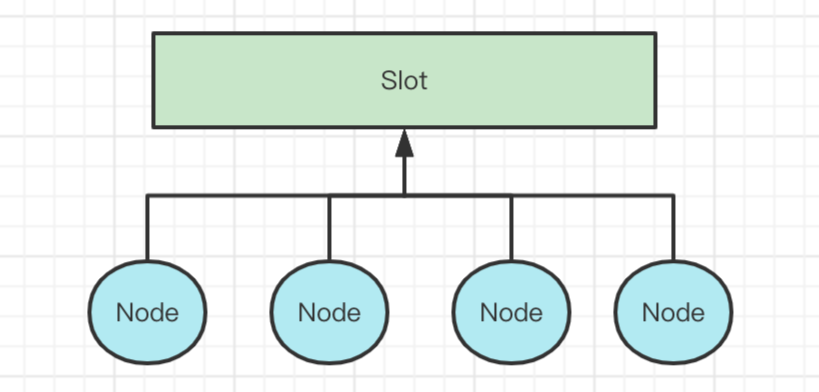
4)Slot
Slot可以理解為業務的上下文,在一個業務流程中,這個Slot是共用的。
Slot有個預設的實現DefaultSlot,DefaultSlot雖然可以用,但是在實際業務中,用這個會存在大量的弱類型,存取數據的時候都要進行強轉,頗為不方便。所以官方建議自己去實現自己的Slot,可以繼承AbsSlot。
5)DataBus
用來管理Slot的,從這裡面可以獲取當前業務流程執行的Slot。
四、LiteFlow源碼探究
說完核心的組件,接下來就來剖析一下源碼,來看一看LiteFlow到底是如何實現規則編排的。
1)FlowExecutor的構造流程
我們這裡就以非Spring環境的例子來說,因為在SpringBoot環境底下,FlowExecutor是由Spring創建的,但是創建的過程跟非Spring的例子是一樣的。
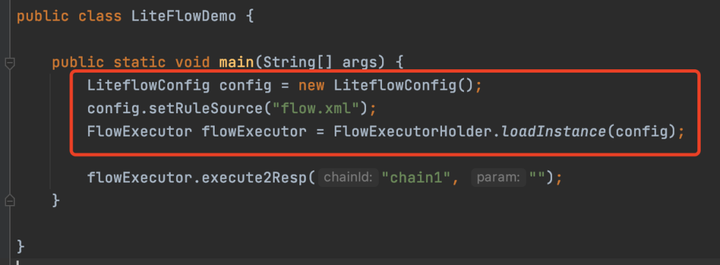
這裡在構建FlowExecutor,傳入了一個規則的路徑flow.xml,也就是ruleSource屬性值。
進入loadInstance這個方法,其實就是直接new了一個FlowExecutor。
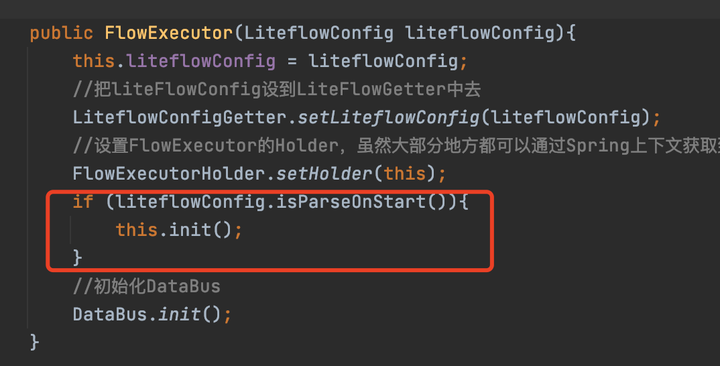
進入FlowExecutor構造方法,前面就是簡單的賦值操作。然後調用liteflowConfig.isParseOnStart(),這個方法預設是返回true的,接下來會調用init方法,也就是在啟動時,就去解析規則文件,保證運行時的效率。
接下來進入init方法。
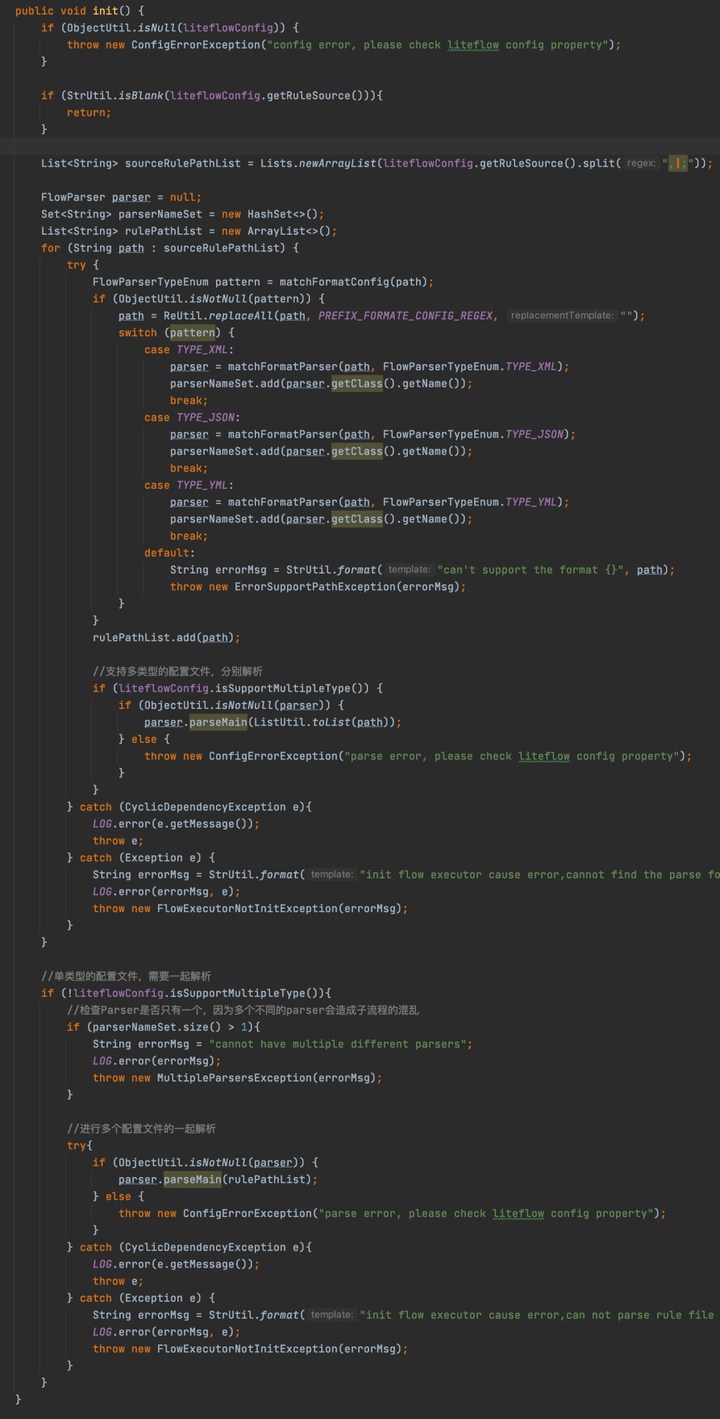
init方法非常長,來一步一步解析
前面就是校驗,不用care
List<String> sourceRulePathList = Lists.newArrayList(liteflowConfig.getRuleSource().split(",|;"));這行代碼的意思就是將我們傳入的規則文件路徑進行分割成多個路徑,從這可以看出支持配置多個規則的文件。對我們這個demo來說其實就是只有一個,那就是flow.xml。
分割完之後,就會遍歷每個路徑,然後判斷文件的格式,比如xml、json、yaml,然後根據文件格式找到對應的FlowParser。
隨後根據liteflowConfig.isSupportMultipleType()判斷是不是支持多類型的,什麼叫多類型,就是指規則文件配置了多個並且文件的格式不同,如果支持的話,需要每個規則文件單獨去解析,如果不支持,那就說明文件的格式一定是相同的,相同可以在最後統一解析,解析是通過調用FlowParser的parseMain來解析的。
剖析完之後整個init方法就會結束,然後繼續調用DataBus的init方法,其實就是初始化DataBus。
到這其實構建FlowExecutor就完成了,從上面我們得出一個結論,那就是在構造FlowExecutor的時候會通過FlowParser的parseMain來處理對應規則文件的路徑,所以接下來我們分析一下這個FlowParser是如何解析xml的,並且解析了之後幹了什麼。
2)FlowParser規則解析流程
接下來我們進入FlowParser來看看一個是如何解析規則的。
以本文的例子為例,因為是配置本地的xml文件,找到的FlowParser的實現是LocalXmlFlowParser。

接下會調用parseMain方法,parseMain的方法的實現很簡單,首先根據PathContentParserHolder拿到一個PathContentParser來解析路徑,對上面案例來說,就是flow.xml路徑,拿到路徑對應文件的內容,其實就是拿到了flow.xml內容。然後調用父類的parse方法來解析xml的內容,所以parse方法才是解析xml的核心方法。
這裡有個細節說一下,PathContentParserHolder其實內部使用了Java的SPI機制來載入PathContentParser的實現,然後解析路徑,拿到內容,在Spring環境中預設基於Spring的實現的優先順序高點,但是不論是怎麼實現,作用都是一樣的,那就是拿到路徑對應的xml文件的內容,這裡就不繼續研究PathContentParser是如何載入文件的源碼了。
其實不光是PathContentParser,LiteFlow內部使用了很多SPI機制,但是基本上整合Spring的實現的優先順序都高於框架本身的實現。
接下來我們就來看一下LocalXmlFlowParser父類中的parse方法的實現。
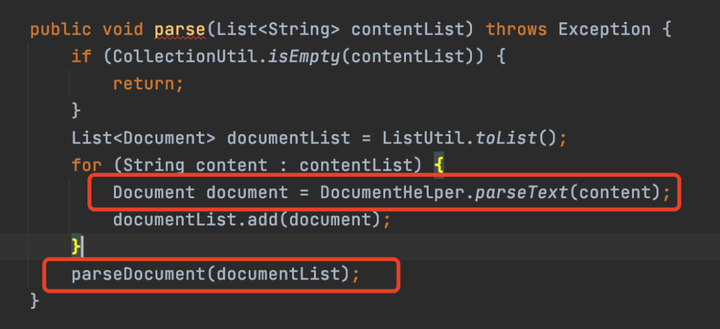
首先遍歷每個文件中的內容,然後轉成Document,Document其實是dom4j的包,其實就是將xml轉成Java對象,這樣可以通過Java中的方法來獲取xml中每個標簽的數據。
將文件都轉換成Document之後,調用parseDocument方法。
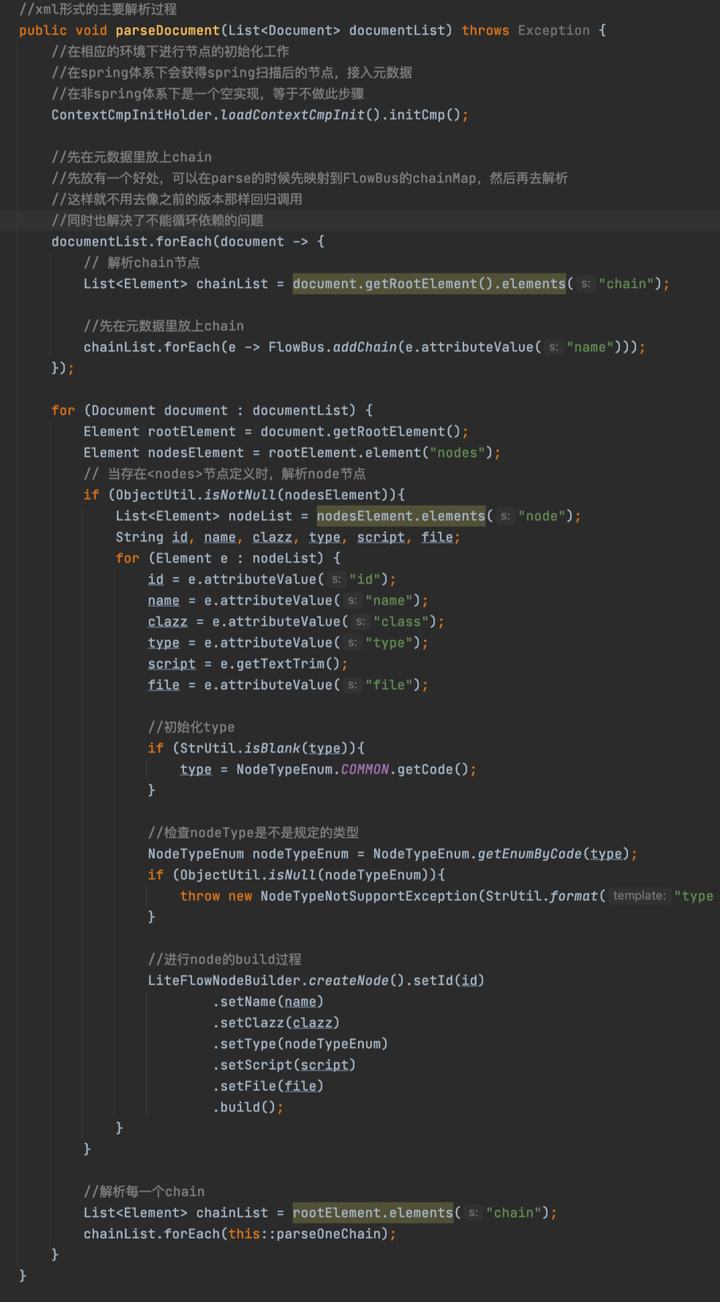
首先調用了ContextCmpInitHolder.loadContextCmpInit().initCmp() ,這行代碼也是通過SPI機制來載入ContextCmpInit,調用initCmp方法。框架本身對於initCmp的實現是空實現,但是在Spring環境中,主要是用來整合Spring中的Node節點的,將Node節點添加到FlowBus中,這也是為什麼在Spring環境中的那個案例中不需要在xml文件中配置<nodes/>的原因,因為LiteFlow會自動識別這些Node節點的Spring Bean。至於怎麼整合Spring的,有興趣的同學可以看一下ComponentScanner類的實現,主要在Bean初始化之後進行判斷的,這裡畫一張圖來總結一下initCmp方法的作用。
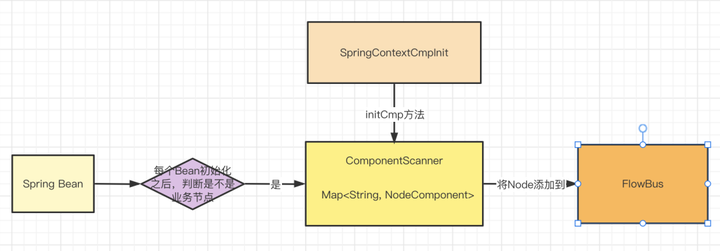
至於為什麼需要先將Spring中的Node節點添加到FlowBus,其實很簡單,主要是因為構建Chain是需要Node,需要保證構建Chain之前,Spring中的Node節點都已經添加到了FlowBus中。
接下來就會繼續遍歷每個Document,也就是每個xml,然後拿到解析<nodes></nodes>中的每個<node></node>標簽,拿出每個node標簽中的屬性,通過LiteFlowNodeBuilder構建Node,然後放入到FlowBus中,至於如何放入到FlowBus中,可以看一下LiteFlowNodeBuilder的build方法的實現。
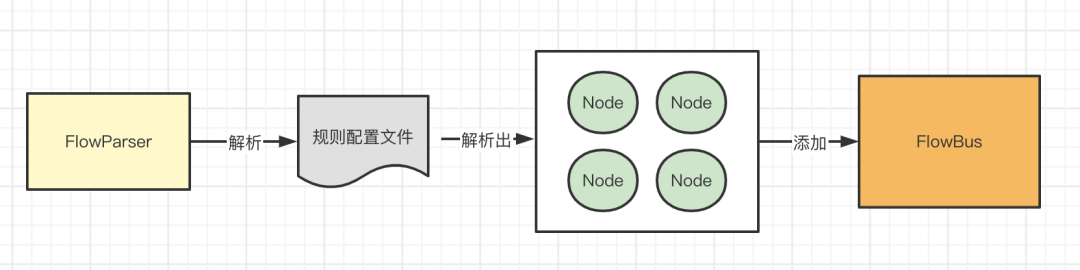
解析完Node之後,接下來就是解析<chain/>標簽,拿到每一個<chain/>標簽對應的Element之後,調用parseOneChain來解析<chain/>標簽的內容。
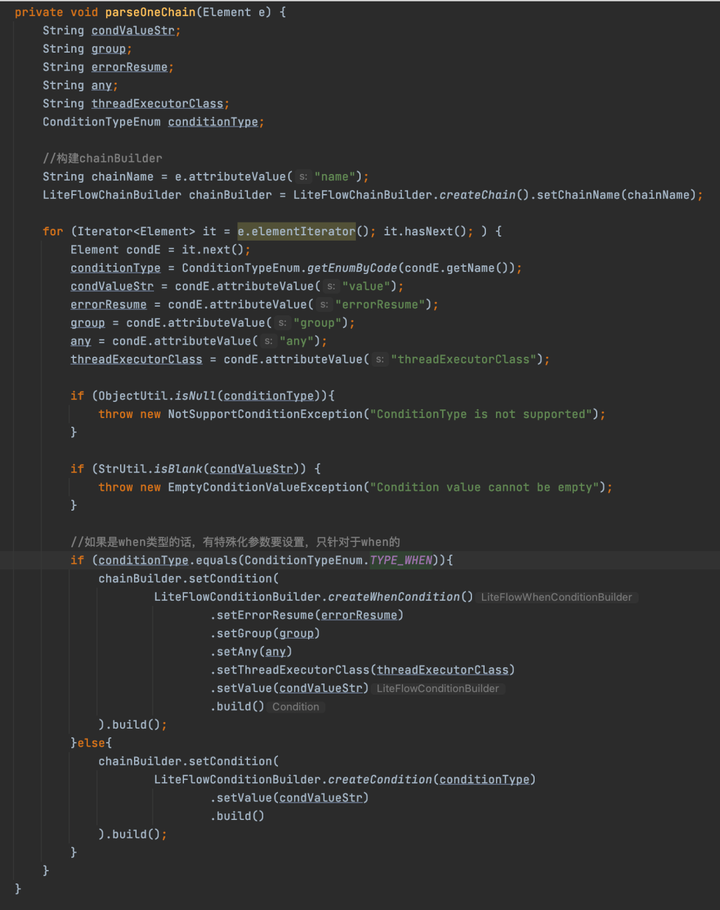
parseOneChain方法,先拿到<chain/>底下所有的標簽,然後判斷標簽類型,標簽的類型主要有四種類型:then、when、pre、finally,然後拿到每個標簽的值,構建對應的Condition,就是上文提到的ThenCondition、WhenCondition、PreCondition、FinallyCondition,然後加入到Chain中,至於如何將Node設置到Condition中,主要是通過LiteFlowConditionBuilder的setValue方法來實現的,setValue這個方式設置的值是條件標簽的value屬性值,然後解析value屬性值,然後從FlowBus中clone一個新的Node,加入到Condition中,至於為什麼需要clone一下新的Node,因為同一個業務節點,可能在不同的執行鏈中,為了保證不同業務中的同一個業務節點不相互干擾,所以得重新clone一個新的Node對象。
構建好Condition之後,都設置到了對應的Chain中,最後將Chain添加到FlowBus中。
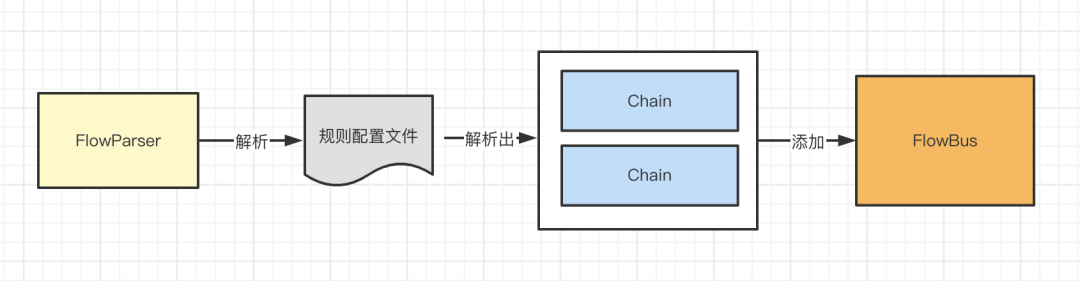
到這裡,其實整個xml就解析完了,FlowParser的最主要的作用就是解析xml,根據配置構建Node、Condition和Chain對象,有了這些基礎的組件之後,後面才能運行業務流程。其實從這裡也可以看出是如何流程編排的,其實就是根據配置,將一個個Node添加到Condition中,Condition再添加到Chain中,這樣相同的業務節點,可能分佈在不同的Chain中,這樣就實現了業務代碼的復用和流程的編排。
3)Chain的執行流程
剖析完FlowParser的作用,也就是Node和Chain的構造流程之後,接下來看一下Chain是如何執行的。
流程執行是通過FlowExecutor來執行的,FlowExecutor執行的方法很多,我們以上面demo調用的execute2Resp為例,最終會走到如下圖的重載方法。
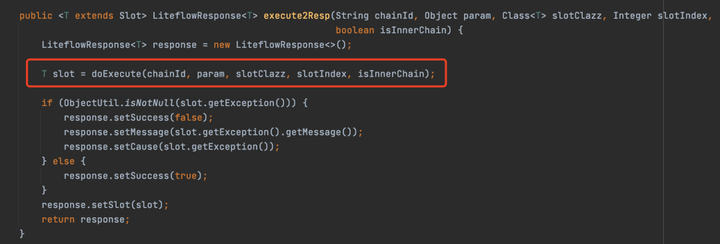
execute2Resp方法就會調用doExecute方法的實現,然後拿到Slot,封裝成一個LiteflowResponse返回回去,所以從這裡可以看出,doExecute是核心方法。
接下來看看doExecute方法的實現。
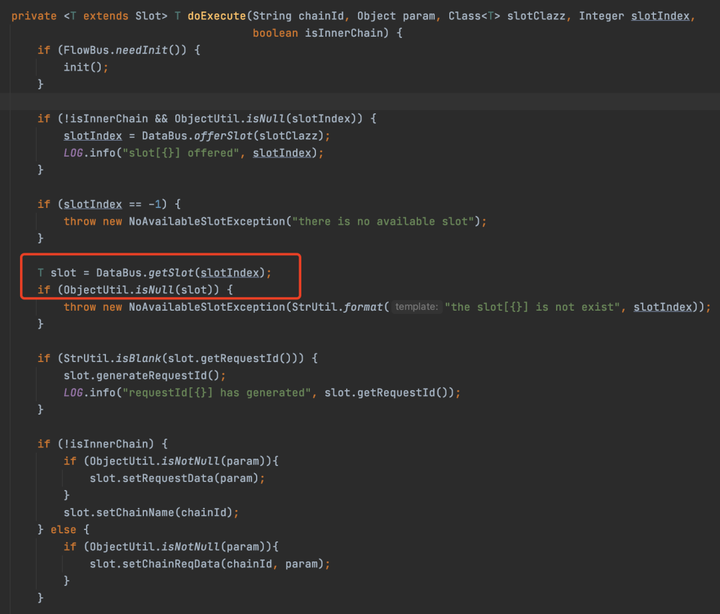
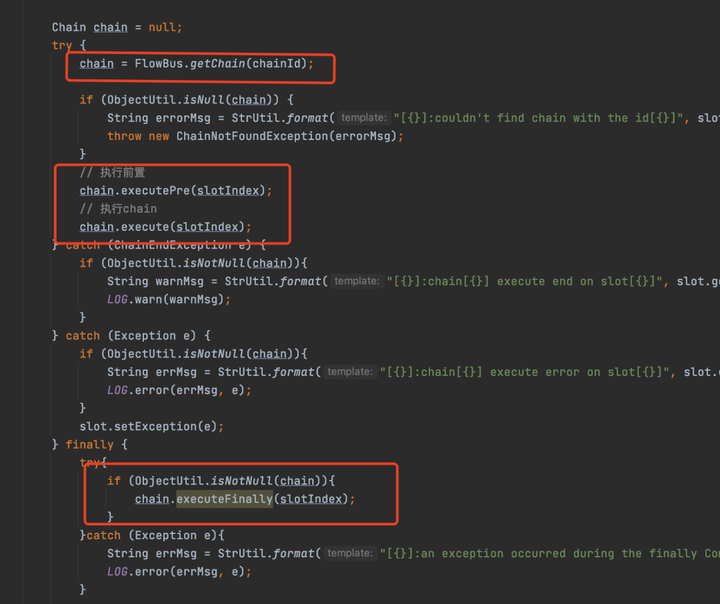
doExecute方法比較長,我截了兩張圖
首先從DataBus中獲取一個Slot,也就是當前業務執行的上下文。之後從FlowBus中獲取需要執行的Chain,最後分別調用了Chain的executePre、execute、executeFinally方法,其實不用看也知道這些方法幹了什麼,其實就是調用不同的Condition中Node方法。
executePre和executeFinally方法
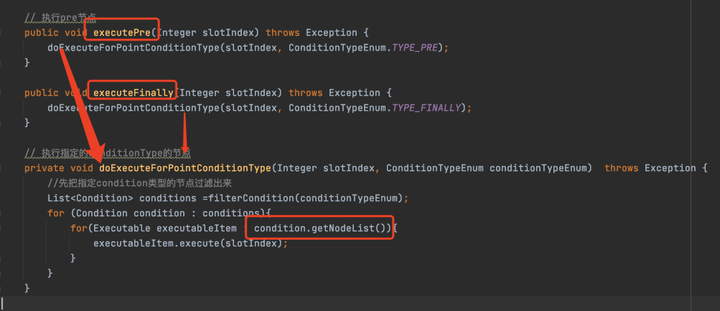
這兩個方法最後調用的是同一個方法,就是分別找到PreCondition和FinallyCondition,取出裡面的Node節點,執行excute方法。
這裡有重點說明一下,其實在Condition中存的不是直接的Node,而是Executable,Executable的有兩個實現,一個就是我們所說的Node,還有一個就是我們一直說的Chain,為了方便大家理解,我一直說的是Node,其實這裡的Executable是有可能為Chain的,取決於規則的配置。當是一個Chain的時候,其實就是一個嵌套的子流程,也就是在一個流程中嵌套另一個流程的意思,大家註意一下就行了,其實不論怎麼嵌套,流程執行到最後一定是Node,因為如果是Chain,那麼還會繼續執行,不會停止,只有最後一個流程的Executable都是Node的時候流程才能執行完。
executePre和executeFinally方法說完之後,看一看execute方法的實現。

execute方法主要是判斷Condition的類型,然後判斷是ThenCondition還是WhenCondition,ThenCondition的話其實也就是拿出Node直接執行,如果是WhenCondition的話,其實就是並行執行每個Node節點。這也是ThenCondition和WhenCondition的主要區別。
畫圖總結一下Chain的執行流程
4)Node的執行流程
從上面我們可以看出,Chain的執行其實最終都是交給Node來執行的,只不過是不同階段調用不同的Node而已,其實最終也就是會調用Node的execute方法,所以我們就來著重看一下Node的execute方法。
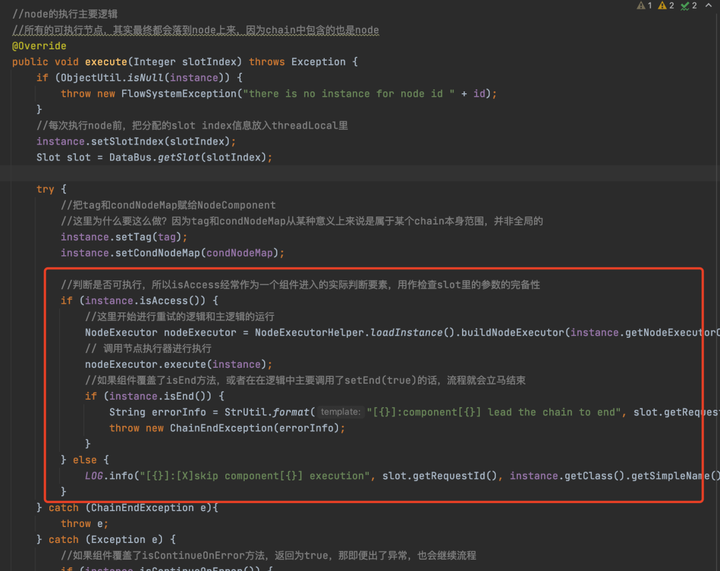
instance就是NodeComponent對象,也就是我們自定義實現的節點對象,好家伙,終於要執行到業務了。有人可能好奇NodeComponent是如何設置到Node對象中的,其實就是在往FlowBus添加Node的時候設置的,不清楚的小伙伴可以翻一下那塊相關的源碼,在解析xml那塊我有說過。
先調用NodeComponent的isAccess方法來判斷業務要不要執行,預設是true,你可以重寫這個方法,自己根據其它節點執行的情況來判斷當前業務的節點要不要執行,因為Slot是公共的,每個業務節點的執行結果可以放在Slot中。
隨後通過這個方法獲取了NodeExecutor,NodeExecutor可以通過execute方法來執行NodeComponent的,也就是來執行業務的,NodeExecutor預設是使用DefaultNodeExecutor子類的,當然你也可以自定義NodeExecutor來執行NodeComponent
NodeExecutor nodeExecutor = NodeExecutorHelper.loadInstance().buildNodeExecutor(instance.getNodeExecutorClass());DefaultNodeExecutor的execute方法也是直接調用父類NodeExecutor的execute方法,接下來我們來看一下NodeExecutor的execute方法。
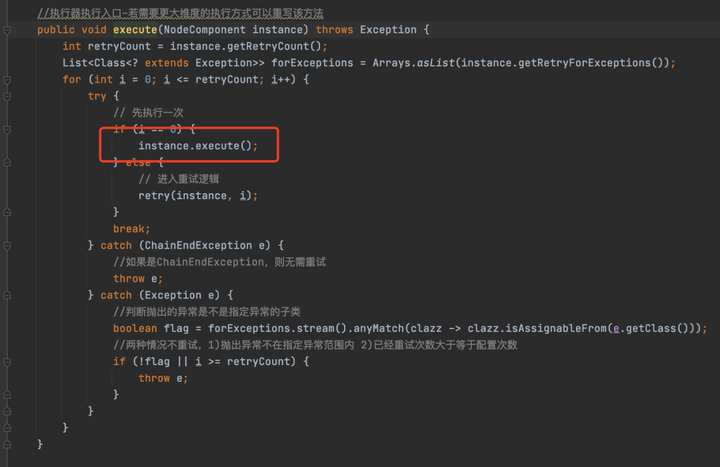
從這個方法的實現我們可以看出,LiteFlow對於業務的執行是支持重試功能的,但是不論怎麼重試,最終一定調用的是NodeComponent的execute方法。
進入NodeComponent的execute方法
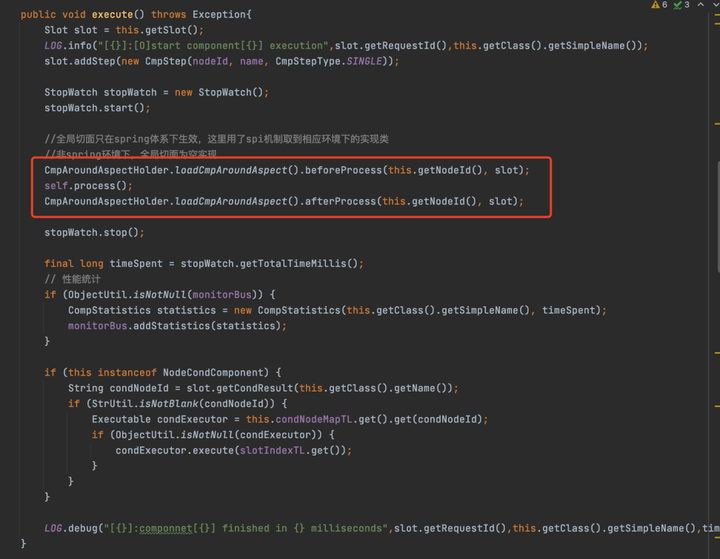
紅框圈出來的,就是核心代碼,self是一個變數,指的是當前這個NodeComponent對象,所以就直接調用當前這個NodeComponent的process方法,也就是用來執行業務的方法。
在執行NodeComponent的process方法前後其實有回調的,也就是可以實現攔截的效果,在Spring環境中會生效。
至於這裡為什麼要使用self變數而不是直接使用this,其實源碼也有註釋,簡單點說就是如果process方法被動態代理了,那麼直接使用this的話,動態代理會不生效,所以為了防止動態代理不生效,就單獨使用了self變數來引用自己。至於為什麼不生效,這是屬於Spring的範疇了,這裡就不過多贅述了。
其實到這裡,一個Node就執行完成了,Node的執行其實就是在執行NodeComponent,而NodeComponent其實最終是交給NodeExecutor來執行的。
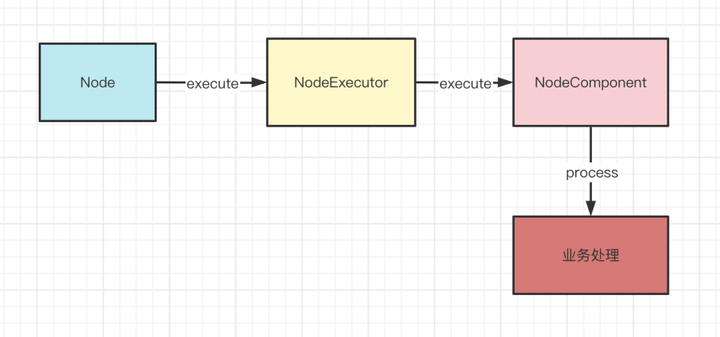
每個Condition中的Node執行完之後,就將Slot返回,這樣就能在調用方就能通過Slot拿到整個流程的執行結果了。
到這裡,其實核心流程源碼剖析就完成了,總的來說就是將規則配置文件翻譯成代碼,生成Node和Chain,然後通過調用Chain來執行業務流程,最終其實就是執行我們實現的NodeComponent的process方法。
最終畫一張圖來總結整個核心源碼。
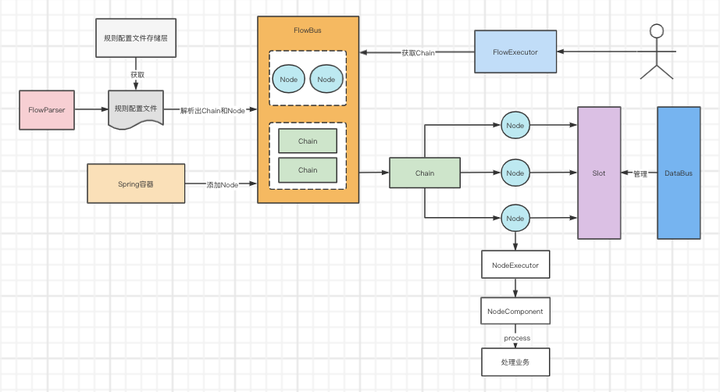
圖中我省略了Condition的示意圖,因為Condition其實最終也是執行Node的。
以上就是本篇文章的全部內容,如果你有什麼不懂或者想要交流的地方,可以關註我的個人的微信公眾號 三友的java日記 聯繫我,我們下篇文章再見。
如果覺得這篇文章對你有所幫助,還請幫忙點贊、在看、轉發給更多的人,碼字不易,非常感謝!
往期熱門文章推薦
- 7000字+24張圖帶你徹底弄懂線程池
- 【SpringCloud原理】OpenFeign原來是這麼基於Ribbon來實現負載均衡的
- 【SpringCloud原理】Ribbon核心組件以及運行原理源碼剖析
- 【SpringCloud原理】OpenFeign之FeignClient動態代理生成原理
- 為什麼Java有了synchronized之後還造了Lock鎖這個輪子?
- synchronized真的很重麽?
- 一文帶你看懂Java中的Lock鎖底層AQS到底是如何實現的


