
B+樹索引的正確使用 索引並不是越多越好,索引創建越多,MySQL維護的代價越高,如果SQL未能完全使用到索引,創建索引的意義是不大的。 適用條件 表x,創建索引a,b,c。主鍵y。 全值匹配 select * from x where a = '' and b = '' and c = '' 當我 ...
B+樹索引的正確使用
索引並不是越多越好,索引創建越多,MySQL維護的代價越高,如果SQL未能完全使用到索引,創建索引的意義是不大的。
適用條件
表x,創建索引a,b,c。主鍵y。
全值匹配
select * from x where a = '' and b = '' and c = ''
當我們創建的索引abc,此時我們有a,b,c欄位的索引是可以匹配到的,不論你a,b,c欄位順序如何,優化器會自動優化為索引的順序。
匹配左邊的列
select * from x where a = '' and d = ''
我們在此情況可以用到a的索引,但是如果第一個為b或c欄位就不行。
匹配列首碼
select * from x where a like 'aaa%' and b like 'bbb%' # 不行'%aaa'或'%aaa%'
我們可以利用建立的索引找到a和b欄位,因為a索引和b索引按照首碼排序的。但是反過來不行
匹配範圍值
select * from x where a between 5 and 10;
因為是索引按照大小排序的,所以可以使用到索引。但是我們不用a直接用b是不能用到索引的。
精準匹配到某一列並範圍匹配到另外一列
select * from x where a = 'aaa' and b between 5 and 10;
當我們是這種情況會找到a,然後根據b的排序找到b的範圍值,是可以用到索引的。
用於排序
select * from x order by a,b,c; # 可以使用索引
select * from x order by b,a,c; # 不能使用索引
創建了a,b,c的索引可以根據a,b,c 排序,否則不能使用。
用於分組
select * from x group by a,b # 可以使用索引,順序不對可以,會自動優化,但是得從左邊開始
回表代價
二級索引最後的最後找到主鍵值需要拿著主鍵值去聚簇索引進行回表查詢。
我們創建索引時可以儘量避免回表的出現,儘量使用索引的欄位,否則回表會導致MySQL的性能下降。當然mysql對於大量數據需要回表的情況會直接優化成順序查找,省的大量回錶帶來的開銷。
這也是為什麼我們不要用select * 的原因,如果我們只需要索引欄位就select對應欄位即可。當所需欄位在索引中存在,會進行覆蓋索引作為結果返回,不需要回表查值。
select * from x where a = '' and b = '' and c = ''; # 如果資料庫中有其他欄位除了abc和主鍵y。
select a,b,c,y from x where a = '' and b = '' and c = ''; # 不需要回表直接覆蓋索引。
索引創建註意事項
- 不需要對查詢欄位創建索引,只需要對搜索、排序、分組的欄位進行即可。
- 列的基數儘量大,基礎小,即列的重覆值較少的列創建索引
- 索引列的類型能小儘量小,int能用tinyint就用。
- 索引字元串的首碼,如果只需要首碼創建索引,但是如果首碼重覆多可能會出現問題。
- 讓索引列在比較表達式中占獨立的一部分。where a * 2 > 6 是用不了索引的,where a > 6 /2 可以用索引。
- 主鍵插入順序,如果主鍵插入不按順序,是需要頁分裂等操作的,所以建議主鍵自增。
- 重覆索引。索引重覆只會更多的MySQL性能開銷,且毫無意義。
MySQL的數據目錄
數據存放目錄,與安裝目錄區分開
mysql> show variables like 'datadir';
+---------------+------------------------------------+
| Variable_name | Value |
+---------------+------------------------------------+
| datadir | D:\mysql\mysql-8.0.22-winx64\data\ |
+---------------+------------------------------------+
1 row in set, 1 warning (0.00 sec)
資料庫在文件中就是表現為存放目錄下的一個與資料庫同名的文件夾,系統資料庫會直接存放在數據存放目錄下。
表在文件系統中的表示
InnoDB存儲表數據
描述表結構的文件:表名.frm
描述表數據和索引的文件:表名.ibd
系統表空間:即數據存放目錄下的一個12M的文件,如果系統中資料庫數據多,會更大。即系統資料庫文件ibdata1文件。
獨立表空間:在數據存放目錄下資料庫名的子目錄裡面,表名.frm 和 表名.ibd 。不過現在8.0.22已經只有表名.ibd了。
MyISAM存儲表數據
描述表結構的文件:表名.frm
描述表數據的文件:表名.MYD
描述表索引的文件:表名.MYI
獨立表空間就是由這三個文件組成。
其他文件
伺服器進程文件、日誌文件、SSL和RSA證書和密鑰。
MySQL系統資料庫
- mysql
存放用戶賬號和許可權,一些存儲過程、事件定義信息、一些運行時日誌,幫助信息,時區信息。
- information_schema
維護伺服器有哪些表,哪些視圖,哪些觸發器,哪些列,哪些索引
- performance_schema
維護伺服器運行的狀態信息,對MySQL的監控
- sys
通過視圖的形式把前兩個表結合起來,讓程式員監控MySQL。
InnoDB 表空間
我們提到了行格式、頁這兩個概念。
行格式規定了每條數據,多條數據形成組,多個組存放在一個頁中。
如果我們需要管理頁的話,我們就需要區和段這個概念。
一個16KB的頁來說,連續64個頁就是一個區,也就是說一個區的大小為1MB。
連續256個區,就形成了一個組,一個組256MB。
區概念
對於每個表空間的第一個組來說,這個組第一個區前三個頁面是不一樣的。
- FSP_HDR類型的頁面。用來登記該組256個區的屬性,但是還會存儲表的基本屬性。
- IBUF_BITMAP類型的頁。存儲INSERT_BUFFER
- INODE類型的頁。存儲INODE entry。
其餘組的第一個區就是最先兩個頁面不一樣。
- XDES類型的頁面。用來登記該組256個區的屬性。
- IBUF_BITMAP類型的頁面
提問:為什麼要使用區來管理?
因為對於頁來說沒有固定的存儲地點,所以頁是隨意存儲的,但是如果數據量已經很大的情況下,我們插入了一個很小的主鍵值,會建立一個物理存儲位置在很後面的頁,但是頁會被插入到很前面,我們讀頁信息的時候,就會出現什麼情況呢?
就是我們需要IO讀取到最後,然後在回到當前繼續讀,是十分耗時的,也就是隨機IO,與順序IO性能差得多。
段概念
第一遍看到這個概念直接被搞蒙了。
InnoDB 中葉子節點存放的區和非葉子節點存放的區是分開的,這就是段的概念。一個為存放葉子節點區的段,和存放索引頁區的段。
所以捋一下。每個聚簇索引會有兩個段,一個段表示存放葉子頁的區,一個段表示存放非葉子頁的區。
那按照這樣的話,一個表開局就要2M的存儲空間,對於幾條數據的是不是太大了。
所以出現碎片頁的概念,一個區不屬於某個段,而是直接屬於表空間。它可以存儲各個段的頁,防止區的浪費。當一個段已經存儲了32個碎片區,剩下就會直接創建附屬的空閑區來存儲頁,而不是使用碎片頁。
所以區有如下狀態:
- 空閑區(FREE)、
- 有剩餘空間的碎片區(FREE_FRAG)、
- 滿的碎片區(FULL_FRAG)、
- 附屬於某個段的空閑區(FSEG)。
對於每個區來說都有一個XDES Entry的結構。
- Segment ID (8位元組):如果狀態為FSEG的話就是段的ID。否則沒有意義
- List Node(12位元組):用來存儲前一個和後一個區的地址
- State(4位元組):就是上述四種狀態。
- Page State Bitmap(16位元組): 描述當前64個頁,每個頁2比特,一比特表示是否空閑,還有一個比特沒什麼用。
尋找最近的有空間的或空閑區
當段中存儲的區小於32時,是會利用隸屬於表空間的碎片區進行存儲的。
流程:
- 新插入的頁尋找空閑區進行存儲,如何快速尋找到表空間的空閑碎片區呢?
- 表空間會維護一個FREE狀態的鏈表和FREE_FREG狀態的鏈表以及FULL_FRAG狀態的鏈表。
- 如果空閑的碎片區還存在就會找出鏈表中取出一個插入,如果滿了就改變其狀態將其放入FULL_FRAG的鏈表中。
- 如果沒有空閑的碎片區,就會從FREE中取出一個來將其轉變為空閑碎片區狀態放入FREE_FREG狀態的鏈表中。
當段中的碎片區存儲超過32時,就會申請隸屬於該段空間的區進行存儲。
流程和之前差不多,但是段空間也會維護三個鏈表FREE和FULL以及NOT_FULL雖然有點區別就是非碎片區的,不過是申請的專屬的區,所以流程是差不多的。
段的結構
前面我們不是提到了段並不是一個實際的存儲單元,只是區的引用。
所以需要有一個結構來定義段,就是INODE Entry 結構
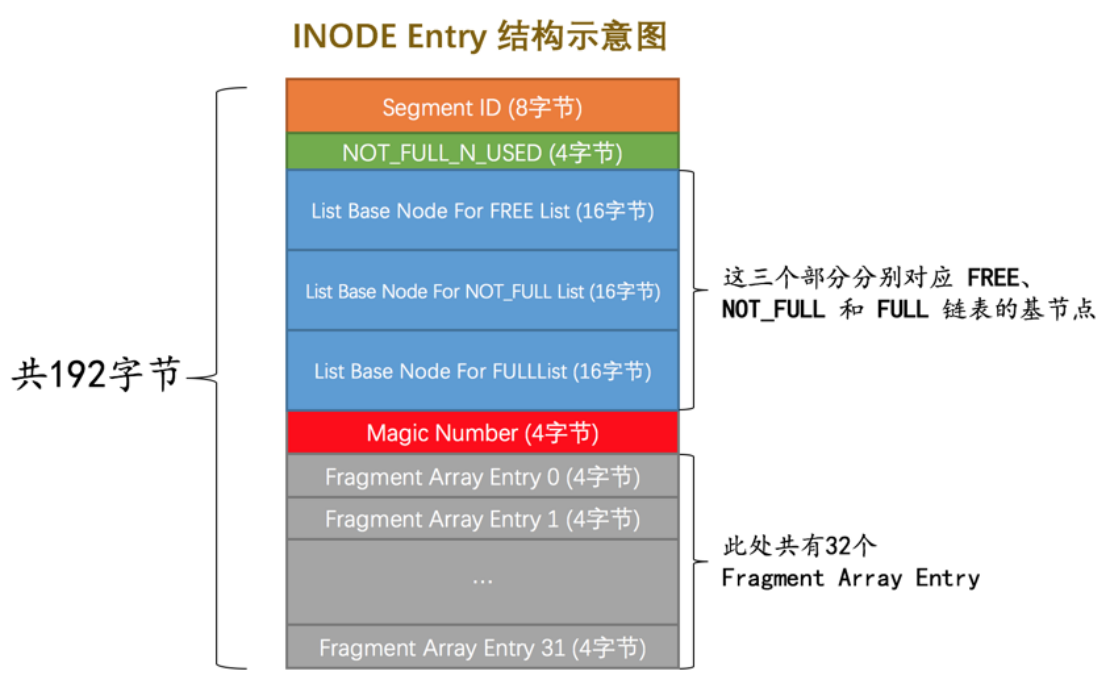
- Segment ID :就是段的唯一ID
- NOT_FULL_N_USED:表示已經使用的頁的個數,然後下次直接分配直接找到。
- 三個鏈表:很熟悉,就是表示空閑,沒滿,和滿了的隸屬於該段的區的鏈表。只會在碎片區分配滿32個的時候才會進行分配。
- Magic Number魔數
- 碎片區的引用剛好32個。
所以在段中,碎片區的引用是在最底下,而專屬區的引用是在鏈表中鏈著的。
所以你廢了嗎?
接下來我們可以講解一下INODE Entry放在哪裡呢,就需要介紹之前提到過的每個表空間的第一個區中固定的三個頁面,只介紹倆頁面
FSP_HDR頁面和XDES頁面
FSP_HDR類型的頁面,就是比其他的區的第一個XDES頁多了File Space Header就是記錄當前表空間的一些屬性,其他都是一樣的。

- File Header就是頭中的一些信息還有和File Trailer的校驗
- File Space Header

Space ID 表示表空間的ID
Size 表空間頁的大小
Free Limit 就是當前已經使用的頁到多少了,下次直接從這個地址開始分配頁面
FRAG_N_USED 表示碎片區已經使用的頁
接下來的for FREE List 和for FREE_FRAG List和for FULL_FRAG List 表示表空間維護的三個有關碎片區的鏈表
Next Unuser Segment ID 表示下一個未分配的段ID,方便分配一個新的段ID
for SEG_INODES_FULL 和 for SEG_INODES_FREE 表示已經放滿了INODE Entry 的INODE節點和空閑的INODE節點。(記住是存放INODE Entry也就是段結構的INODE節點)
INODE頁面
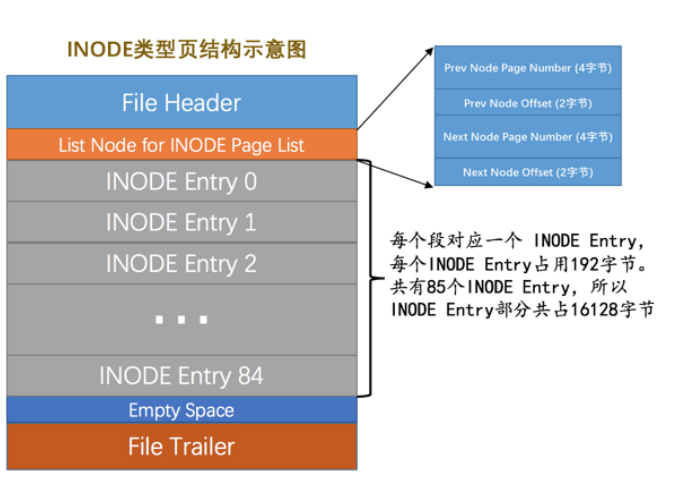
INODE類型結構就是為了存儲INODE Entry節點的,最多存儲85個段。
結構中List Node for INODE Page List 就是指向上一個INODE節點和下一個INODE節點。
我們就是在這個INODE中存儲段的INODE Entry節點的。
如果該頁存儲滿了,就會在上面提到的List Base Node for SEG_INODES_FREE 就是空閑INODE頁的基節點的鏈表引用,取出一個,空的話從碎片區中申請一個頁來存放。
所以我們知道了段是怎麼存儲的,存儲在哪裡。
同時呢,我們已經知道一個索引會有兩個段,一個葉子段,一個非葉子段。
我們怎麼找到索引的頁呢?
Segment Header結構
在這個結構之前,我們在數據頁是提到過兩個引用,但是沒有具體介紹
在頁結構的Page Header中有如下兩個結構

這兩個結構就是Segment Header這個結構

Space ID of the INODE Entry 就是INODE對應的表空間
Page Number of the INODE Entry 就是INODE對應的表空間下對應的頁號
Byte Offset of the INODE Entry 就是INODE對應的頁中對應段的偏移量。
我們就可以通過在索引的ROOT節點存儲一個這樣的結構,可以找到對應的段。包括葉子段和非葉子段,就是兩個這個結構,然後去表空間中找到這兩個段的地址即可。
系統表空間
介紹一個概念,數據字典即系統表空間中存放了一些固定的數據,以及資料庫中的表,表名,列,列屬於那個表等等基本信息。
還有一些已經用了的最大的表ID,最大的索引ID,最大的表空間ID,就是方便下次創建表啊索引啊這一些更方便一點,直接將值進行增加等操作進行賦值即可。
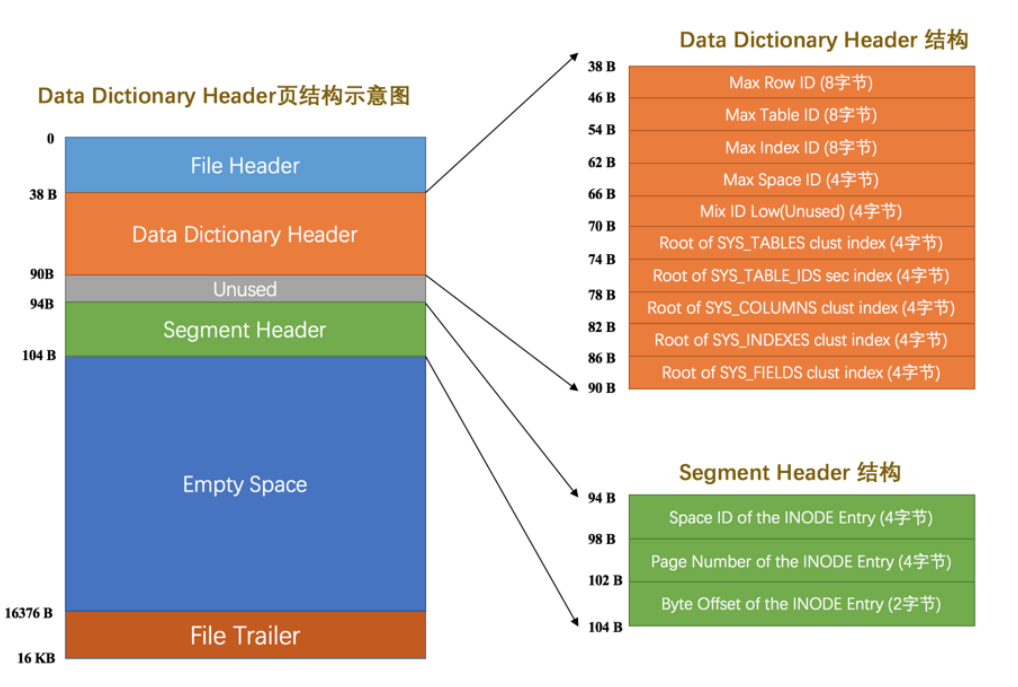
圖片出自:《MySQL是怎樣運行的:從根兒上理解MySQL》
對其進行總結概括,以及思路重新捋一遍。


