
前幾篇文章已經從整體提供了診斷資料庫的各個方面問題的基本思路...也許對你很有用,也許你覺得離自己太遠。那麼今天我們從語句的一些優化寫法及一些簡單優化方法做一個介紹。這對於很多開發人員來說還是很有用的!為了方便閱讀給出前文鏈接: SQL SERVER全面優化 Expert for SQL Serve ...
前幾篇文章已經從整體提供了診斷資料庫的各個方面問題的基本思路...也許對你很有用,也許你覺得離自己太遠。那麼今天我們從語句的一些優化寫法及一些簡單優化方法做一個介紹。這對於很多開發人員來說還是很有用的!為了方便閱讀給出前文鏈接:
SQL SERVER全面優化-------Expert for SQL Server 診斷系列
首先還是貼出我的座駕

好的語句就像這輛車,跑的又快又帥氣!今天這裡介紹一些技巧讓你可以改裝一下自己的車!
網上確實有好多好多好多好多SQL 語句優化的文章,什麼 優化大全 ,100個優化註意 ,確實整理了好多好多。那麼為什麼我也要湊熱鬧寫一篇呢? 好吧我也不知道!
--------------博客地址---------------------------------------------------------------------------------------
Expert 診斷優化系列 http://www.cnblogs.com/double-K/
廢話不多說,直接開整-----------------------------------------------------------------------------------------
-
重中之重---語句執行順序
在QQ群和人聊天的時候突然有位群友說:我才知道原來語句走索引是按照select 的欄位篩選的! 振振有詞,非常肯定!另一個群友反問update呢 ? 看起來很小白的問題,但確實讓我很震驚!所以我們先看看語句的執行順序
如果我沒記錯這是《SQL SERVER 2005技術內幕--查詢》這本書的開篇第一章第一節。書的作者也要讓讀者首先瞭解語句是怎麼樣那的一個執行順序,因為不知道順序何談寫個好語句?
查詢的邏輯執行順序:
(1) FROM < left_table>
(3) < join_type> JOIN < right_table> (2) ON < join_condition>
(4) WHERE < where_condition>
(5) GROUP BY < group_by_list>
(6) WITH {cube | rollup}
(7) HAVING < having_condition>
(8) SELECT (9) DISTINCT (11) < top_specification> < select_list>
(10) ORDER BY < order_by_list>
標準的SQL 的解析順序為:
(1).FROM 子句 組裝來自不同數據源的數據
(2).WHERE 子句 基於指定的條件對記錄進行篩選
(3).GROUP BY 子句 將數據劃分為多個分組
(4).使用聚合函數進行計算
(5).使用HAVING子句篩選分組
(6).計算所有的表達式
(7).使用ORDER BY對結果集進行排序
執行順序:
1.FROM:對FROM子句中前兩個表執行笛卡爾積生成虛擬表vt1
2.ON:對vt1表應用ON篩選器只有滿足< join_condition> 為真的行才被插入vt2
3.OUTER(join):如果指定了 OUTER JOIN保留表(preserved table)中未找到的行將行作為外部行添加到vt2 生成t3如果from包含兩個以上表則對上一個聯結生成的結果表和下一個表重覆執行步驟和步驟直接結束
4.WHERE:對vt3應用 WHERE 篩選器只有使< where_condition> 為true的行才被插入vt4
5.GROUP BY:按GROUP BY子句中的列列表對vt4中的行分組生成vt5
6.CUBE|ROLLUP:把超組(supergroups)插入vt6 生成vt6
7.HAVING:對vt6應用HAVING篩選器只有使< having_condition> 為true的組才插入vt7
8.SELECT:處理select列表產生vt8
9.DISTINCT:將重覆的行從vt8中去除產生vt9
10.ORDER BY:將vt9的行按order by子句中的列列表排序生成一個游標vc10
11.TOP:從vc10的開始處選擇指定數量或比例的行生成vt11 並返回調用者
我們瞭解了sqlserver執行順序,請以前不知道的看官們,反覆試驗反覆記憶!那麼我們就接下來進一步養成日常sql好習慣,也就是在實現功能的同時又考慮性能的思想!
-
設計思路
具體寫法的優化請不要著急,那都是小兒科!
設計思路說的有點大了,下麵介紹幾個最常見的設計問題!
迴圈改批量
迴圈單條操作,請改成批量操作,如果沒辦法修改,請儘量想辦法修改!這算是最常見的吧:
- 應用代碼端一記 for 迴圈再噁心點的每次打開關閉連接,跑個幾分鐘,數量大點幾小時。請把你的每次for迴圈出來的結果放在一個datatable,list啥的,不要找到一條就往資料庫寫一條!
- 資料庫中的游標也是差不多的道理,如果有可能不用游標迴圈一條一條處理,請儘量不要使用。如果自己認為必須用,也請問問別人是否可以有其他方式做批量!
- 如果沒法避免一條一條的寫入,那麼在處理前顯示開啟一個事務 begin tran 在處理完成後 commit 這樣也要比不開顯示事務會快很多!
上個小例子:
create table test_0607 (a int,b nvarchar(100)) declare @i int set @i = 1 while @i < 10000 begin insert into test_0607 select @i,'0607無顯示整體事務' set @i = @i + 1 end
drop table test_0607 create table test_0607 (a int,b nvarchar(100)) ---加上事務 begin tran declare @i int set @i = 1 while @i < 10000 begin insert into test_0607 select @i,'0607 顯示整體事務' set @i = @i + 1 end ----結束事務,提交 commit
結果 : 8秒和0.8秒的區別,不用多少啥了吧! 凡事有利有弊,這種顯示開啟大事務要保證的整體的過程不會執行特別長的時間,如果執行的操作特別多而且時間長就是災難了!


降低語句複雜性
前文語句優化三板斧中已經介紹過,降低語句複雜性是常見的優化方式。這裡在說一下,導致語句特別複雜一般有兩個原因:
- 程式邏輯本身就很複雜,需要很多表連接,又要排序又要聚合,時不時來幾個子查詢,外加幾個函數。
- 由於業務有很大的共性,所以創建出很多視圖,甚至視圖嵌套很多層視圖,最後外層又要關聯單個模塊的特殊性表。
對於第一種情況,代碼看起來就很長很複雜,看起來很牛逼的代碼其實在高手看來都是很LOW的。而對於第二種,看起來代碼很簡潔,但經過SQL優化器的二次編譯,其實和第一種並無區別。這兩種的解決辦法都是降低複雜性,把一些能拆分出來的儘量拆分出來放入臨時表或者表變數中,比如先把條件篩選性較強的幾張表關聯,然後把結果放入臨時表,在用臨時表和其他表關聯。可以理解成我有10張表關聯,我先拿5張表出來關聯,然後把結果放入臨時表,再跟另外5張表關聯。這樣這個查詢的複雜度由10張表的聯合變成 5+6,這樣降低了複雜語句複雜度。
複雜視圖也是如此,在視圖和外層關聯前,放入臨時表,再跟外層關聯。
子查詢也是如此,可以分離出來成為臨時表的子查詢,先分離出來。
對於表值函數,其實也是有內聯和表值之分:
---方式1:內聯 CREATE FUNCTION [dbo].[tvf_inline_Test]() RETURNS TABLE AS RETURN SELECT ProductID FROM Sales.SalesOrderHeader soh INNER JOIN Sales.SalesOrderDetail sod ON soh.SalesOrderID = sod.SalesOrderID ---此寫法可以結合外層查詢二次編譯(也就是可以利用外層的關聯條件及WHERE 條件) ---方式2:表值 CREATE FUNCTION [dbo].[tvf_multi_Test]() RETURNS @SaleDetail TABLE ( ProductId INT ) AS BEGIN INSERT INTO @SaleDetail SELECT ProductID FROM Sales.SalesOrderHeader soh INNER JOIN Sales.SalesOrderDetail sod ON soh.SalesOrderID = sod.SalesOrderID RETURN END ---此寫法不能應用外層條件篩選,如果數據量大會對性能產生影響。
高能預警:這裡說的是適當使用臨時表,我遇到的很多開發人員一般都有這樣一個過程。開始巨複雜的語句,知道使用臨時表以後,每個步驟很小的操作都要用臨時表。這會給你的TempDB造成很大的壓力!
詳細請參見 : Expert 診斷優化系列------------------給TempDB 降溫
避免重覆讀取
曾經遇到過很多這樣的程式,類似對商品有多種分析,而每種分析要做一些不同的處理,但是他們都會讀取同一份基礎數據商品和商品明細等。很多程式都是按照每種分析作為一個單獨的存儲過程去處理,那麼也就是說有20種處理他們創建了20個存儲過程,並且每個存儲過程的第一步,就是先讀取基礎數據--商品和明細等等。不巧的是商品和商品明細有巨大的數據量,雖然做了分表(按照月份,每個表大概2QW數據),但是每個存儲過程要讀取一年的數據,大概是2QW * 12 ,這麼龐大的數據巨量,查詢後被放入一張temp表,20個存儲過程順序執行,也就是說這份基礎數據每天晚上會被查詢20次! 基本上這個處理占據了系統夜間維護的所有時間,有時甚至會跑不完影響白天正常業務!
也許你看完描述就會笑,誰會把處理設計成這個樣子?這不開玩笑麽?沒錯,解決這個問題其實超簡單,把20個存儲過程合成一個。讓基礎數據的查詢只查詢一次,放入臨時表,創建出下麵邏輯處理需要的索引,在用這個臨時表分別做下麵所有的處理。這樣一個夜間需要跑6小時以上的處理被縮短成40分鐘!(當然說的有點誇張,裡面還有些其他的優化,√)
這裡就提到一個使用臨時表比較重要的問題,那就是類似上面的大量數據寫入臨時表,一定要用 先create 再 insert 的方式,不要直接使用 select into 臨時表的方式,否則就是災難了!
-
論索引的重要性
老生常談的話題了,我想所有公司招人的時候都會問到這樣的面試題: 什麼是索引,索引有哪些類,有何不同?等等....
索引是啥?什麼是聚集索引?什麼是非聚集索引?什麼是主鍵查找?什麼是主鍵掃描?什麼是索引查找?什麼是書簽查找?有啥區別? 這裡都不介紹,請自行百度!
很多開發人員意識不到索引到底對語句,甚至對系統有對重要。關於索引對系統的重要性請關註後續文章。
如何建立索引
最為簡單粗暴的方式,當你寫完一條語句的時候,打開執行計劃,執行一下按照優化器的提示創建索引,具體請參見 :
Expert 診斷優化系列------------------語句調優三板斧
高能預警:這裡需要你的條件可以用索引!比如 你的語句中 索引列不能帶函數,不能參與計算如 where productID/2 = @a ,不能有隱式轉換等!
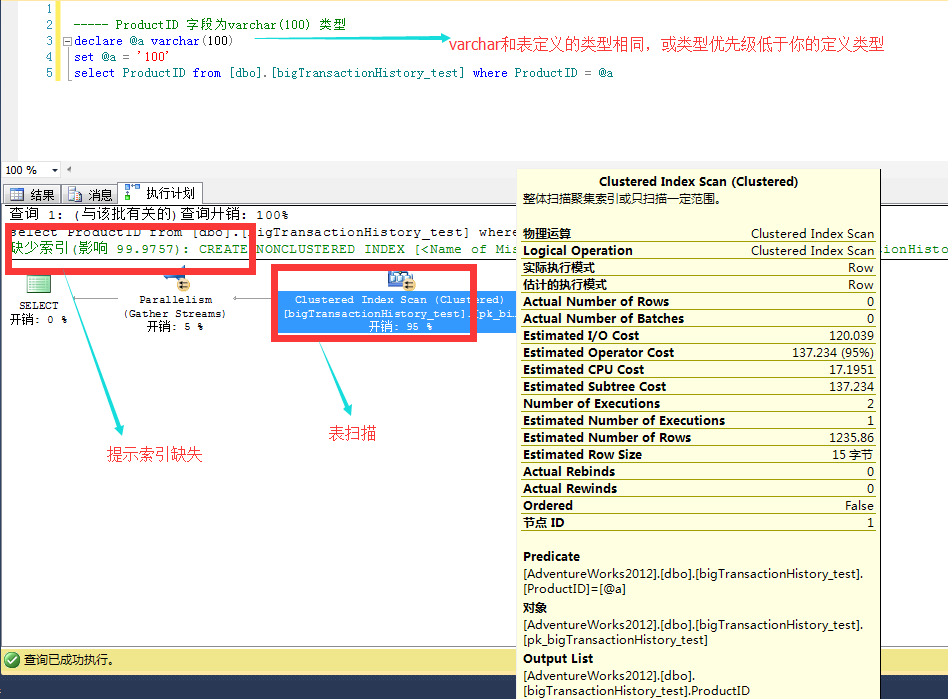

建立索引後,同樣並不是每個查詢都會使用索引,在使用索引的情況下,索引的使用效率也會有很大的差別。如上面的確實索引我們添加上以後再查詢!


索引查找(seek),一般為最優(但查找也要看查找的篩選性),儘量吧where 條件中的欄位建成一個組合索引,並且包含要查詢select 中的欄位。這裡就不繼續深入了。
看懂執行計劃創建
如何看懂執行計劃這就是一個可以寫幾百頁書的話題了,但是看懂執行計劃是做優化的重中之重了!以後的文章中會詳細講解。
通過執行計劃可以看出語句的主要消耗到底在哪裡,另外配合set statistics io on 等分析讀次數,也是優化的關鍵,創建或優化索引頁是主要從這裡出發。
-
語句常規習慣
只返回需要的數據
返回數據到客戶端至少需要資料庫提取數據、網路傳輸數據、客戶端接收數據以及客戶端處理數據等環節,如果返回不需要的數據,就會增加伺服器、網路和客戶端的無效勞動,其害處是顯而易見的,避免這類事件需要註意:
橫向來看:
- 不要寫SELECT * 的語句,而是選擇你需要的欄位。
- 當在SQL語句中連接多個表時, 請使用表的別名並把別名首碼於每個Column上.這樣一來,就可以減少解析的時間並減少那些由Column歧義引起的語法錯誤。 參見: 細心很重要---猜猜這個SQL執行的什麼意思
縱向來看:
- where 條件要儘量的多且保證高篩選性。
- 業務中很常見要返回大批量數據到前端,但是這些數據真的都是必要的麽?前端是否可以加一些預設條件呢?
減少不必要的操作
寫語句之前,理清你的思路!
- 杜絕不必要的表連接,多一個錶鏈接代表多很大部分開銷。
- 減少不必要的條件判斷,很多時候前臺傳入為空值得時候 後臺語句被寫成XX=XX OR XX IS NULL OR XX LIKE OR ...OR ...OR 等。這是比較經典的問題了,請加入判斷在拼入最後的條件!
- 你的語句需要去重覆麽? distinct 、union等操作
- LEFT JOIN 和 inner join的區別,是否真的需要left join,否則選用inner join 來減少不必要的數據返回。
- order by 你的語句是否需要排序?排序是否可以通過索引來降低性能消耗? 我見過竟然插入數據頁帶著order by的 !
儘量早的篩選
- 最經典的例子就是where 和 having的區別,看過語句執行順序你應該已經明白了。能寫在where 中不要放在having中。
- 使用臨時表降低語句複雜性,要降低臨時表的數據量,也就是要把有條件的表儘量關聯並做成臨時表。
- 前面提到的隱式轉換,索引欄位使用計算或函數,也會導致數據不能儘早篩選。
常用的寫法誤區(以下都是網上片面結論)
所有別讓提到的方法到底有無效
- or 要用union all 代替 (or是很常規的一種寫法,情況分很多種,一個表的兩個條件用 a.a =X or a.b = X ,一個表兩個欄位用 a.a =X or a.b = x,兩個不同表欄位用 a.a = X or b.a = X 這是網上說的union all代替的)
- 避免使用 in、not in (數據量小的時候不會有問題,如果數據量大可能影響性能,數據量大處理方式先把in 中的數據放入臨時表)
- 事務操作過程要儘量小,能拆分的事務要拆分開來。(前文中提到的例子,有些情況迴圈寫入下,顯示開啟一個大事務會有很大幫助)
- 使用with(nolock)查詢語句不會阻塞 (一般情況下是這樣,但是如果有架構修改或快照發佈等使用with(nolock)也會阻塞)
- 用exists 代替 in (情況也很複雜不能一概而論)
--------------博客地址---------------------------------------------------------------------------------------
Expert 診斷優化系列 http://www.cnblogs.com/double-K/
-----------------------------------------------------------------------------------------------------
總結 : 就寫到這裡吧,說道語句優化,有太多太多的註意,這些需要明白原理,能看懂執行計劃,並且不斷積累。
單單的幾篇優化大全是幫助是微乎其微的,另外要動手實踐,明白為什麼這樣寫會好!
-------------------------------------------------------------------------------------------------
今天的思緒有些亂...因為今天是一個特殊的日子,不是因為高考,是因為《魔獸》,這個讓我玩了八年的游戲,滿滿的青春熱血。帶著滿滿的回憶,就在今晚讓我們high起來!

提到魔獸激動了補上個人學習道路上,幾本推薦書籍已經上傳網盤。
下載鏈接 :http://pan.baidu.com/s/1kUDrPyf
----------------------------------------------------------------------------------------------------
註:此文章為原創,歡迎轉載,請在文章頁面明顯位置給出此文鏈接!
若您覺得這篇文章還不錯請點擊下右下角的推薦,非常感謝!
為了方便閱讀給出系列文章的導讀鏈接:


