
一、異常現象截圖 二、解決方式: 1、背景 早期的canal版本(<=1.0.24),在處理表結構的DDL變更時採用了一種簡單的策略,在記憶體里維護了一個當前資料庫內表結構的鏡像(通過desc table獲取)。 這樣的記憶體表結構鏡像的維護存在問題,如果當前在處理的binlog為歷史時間段T0,當前時 ...
一、異常現象截圖
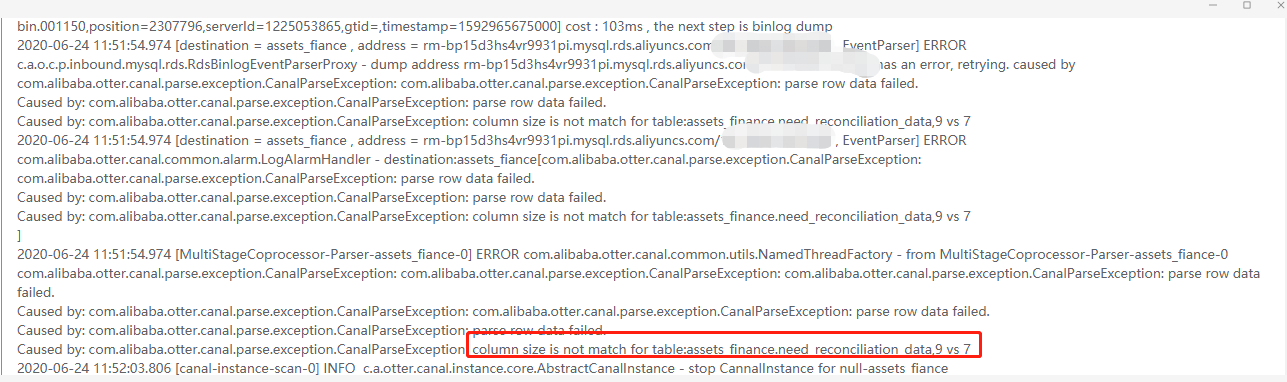
二、解決方式:
1、背景
早期的canal版本(<=1.0.24),在處理表結構的DDL變更時採用了一種簡單的策略,在記憶體里維護了一個當前資料庫內表結構的鏡像(通過desc table獲取)。
這樣的記憶體表結構鏡像的維護存在問題,如果當前在處理的binlog為歷史時間段T0,當前時間為T1,存在的一些異常分支情況:
- 假如在T0~T1的時間內,表結構A發生過增加列的DDL操作,那在處理T0時間段A表的binlog時,拿到的表結構為T1的鏡像,就會出現列不匹配的情況. 比如之前的異常: column size is not match for table: xx , 12 vs 13
- 假如在T0~T1發生了增加 C1列、刪除了C2列,此時拿到的列的總數還是和T0時保持一致,但是對應的列會錯位
- 假如在T0~T1發生了drop table的DDL,此時拿表結構時會出現無法找到表的異常,一直阻塞整個binlog處理,比如not found [xx] in db
補充一下MySQL binlog的一些技術背景:
本文作者:張永清,轉載請註明出處:https://www.cnblogs.com/laoqing/p/13187324.html
- MySQL的在記錄DML(INSERT/UPDATE/DELETE)的binlog時,會由一個當前表結構snapshot的TableMap binlog來描述,然後跟著一條DML的binlog
- TableMap對象里,會記錄一些基本信息:列的數量、列類型精度、後續DML binlog里的數據存儲格式等,但唯獨沒有記錄列名信息、列編碼、列類型,這也是大眾業務理解binlog的基本訴求(但MySQL binlog只做同構重放,可以不關註這些),所以canal要做的一件事就是補全對應的列信息.

ps. 針對複雜的一條update中包含多張表的更新時,大家可以觀察一下Table_map的特殊情況,留待有興趣的同學發揮
2、方案
扯了一堆的背景之後,再來看一下我們如何解決canal上一版本存在的表結構一致性的問題,這裡會把我們的思考過程都記錄出來,方便大家辯證的看一下方案.
思考一
解決這個問題,第一個最直接的思考:canal在訂閱binlog時,儘可能保持準實時,不做延遲回溯消費. 這樣的方式會有對應的優點和缺點:
- canal要做準實時解析,業務上可能有failover的需求,假如在業務處理離線時,原本canal基於記憶體ringBuffer的模型,會出現延遲解析,如果要解決這個問題,必須在canal store上支持了持久化存儲的能力,比如實現或者轉存到kafka/rocketmq等.
- canal準實時解析,如果遇到canal本身的failover,比如zookeeper掛、網路異常,出現分鐘級別以上的延遲,DDL變化的概率會比較高,此時就會陷入之前一樣的表結構一致性的問題
整個方案上,基本是想避開表結構的問題,在遇到一些容災場景下一定也會遇上,不是一個技術解決的方案,廢棄.
思考二
經過了第一輪辯證的思考,基本確定想通過迂迴的方式,簡單繞過一致性的問題不是正解,所以這次的思考主要就是如何正面解決一致性的問題. 基本思路:基於binlog中DDL的變化,來動態維護一份表結構,比如DDL中增加一個列,在本地表結構中也動態增加一列,解析binlog時都從本地表結構中獲取
實現方案:
- 本地表結構的維護,每個canal進程可以帶著一個二進位的MySQL版本,把收到的每條DDL,在本地MySQL中進行重放,從而維護一個本地的MySQL表結構
- 每個canal第一次訂閱或者回滾到指定位點,剛啟動時需要拉取一份表結構基線,存入本地表結構MySQL庫,然後在步驟1的方案上維護一個增量DDL.
整個方案上,可以絕大部分的解決DDL的問題,但也存在一些缺點:
- 每個canal進程,維護一個隔離的MySQL實例。不論是資源成本、運維成本上都有一些瑕疵,更像是一個工程的解決方案,不是一個開源+技術產品的解決方案
- 位點如果存在相對高頻的位點回溯,每次都需要重新做表結構基線,做表結構基線也會概率遇上表結構一致性問題
思考三
有了之前的兩次思考,思路基本明確了,在一次偶然的機會中和alibaba Druid的作者高鐵,交流中得到了一些靈感,是否可以基於Druid對DDL的支持能力,來構建一份動態的表結構.
大致思路:
- 首先準備一份表結構基線數據,每條建表語句傳入druid的SchemaRepository.console(),構建一份druid的初始表結構
- 之後在收到每條DDL變更時,把alter table add/drop column等,全部傳遞給druid,由druid識別ddl語句併在記憶體里執行具體的add/drop column的行為,維護一份最終的表結構
- 定時把druid的記憶體表結構,做一份checkpoint,之後的位點回溯,可以是checkpoint + 增量DDL重放的方式來快速構建任意時間點的表結構
最終方案示意圖

- C0為初始化的checkpoint,拿到所有滿足訂閱條件的表結構
- D1為binlog日誌流中的DDL,它會有時間戳T的標簽,用於記錄不同D1/D2之間的先後關係
- 定時產生一個checkpoint cm,並保存對應的checkpoint時間戳
- 用戶如果回溯位點到任意時間點Tx,對應的表結構就是 checkpoint + ddl增量的結合
介面設計:
public interface TableMetaTSDB { /** * 初始化 */ public boolean init(String destination); /** * 獲取當前的表結構 */ public TableMeta find(String schema, String table); /** * 添加ddl到時間表結構庫中 */ public boolean apply(BinlogPosition position, String schema, String ddl, String extra); /** * 回滾到指定位點的表結構 */ public boolean rollback(BinlogPosition position); /** * 生成快照內容 */ public Map<String/* schema */, String> snapshot(); }

- 依賴了alibaba druid的DDL SQL解析能力,維護一份MemoryTableMeta,實時記憶體表結構
- 依賴DAO持久化存儲的能力,記錄WAL結果(每條DDL) + checkpoint
持久化存儲的思考:
- 本地嵌入式實現(H2):提供最小化的依賴,完成時序表結構管理的能力。基於磁碟的模式,可以結合存儲計算分離的技術,canal failover之後只要在另一個計算節點上拉起,並載入雲盤上的DB數據,做到多機冷備。
- 中心管控存儲實現(MySQL): 一般結合於規模化的管控系統,允許將DDL數據錄入到中心MySQL進行統一運維。
canal中如何使用
- 打開conf/canal.properties,選擇持久化存儲的方案,預設為H2
canal.instance.tsdb.spring.xml=classpath:spring/tsdb/h2-tsdb.xml
#canal.instance.tsdb.spring.xml=classpath:spring/tsdb/mysql-tsdb.xml
- 打開instance下的instance.properties,修改對應的參數
| 參數名 | 預設值 | 描述 |
|---|---|---|
| canal.instance.tsdb.enable | true | 是否開啟時序表結構的能力 |
| canal.instance.tsdb.dir | ${canal.file.data.dir:../conf}/${canal.instance.destination:} | 預設存儲到conf/$instance |
| canal.instance.tsdb.url | jdbc:h2:${canal.instance.tsdb.dir}/h2;CACHE_SIZE=1000;MODE=MYSQL; | jdbc鏈接串 |
| canal.instance.tsdb.dbUsername | canal | jdbc用戶名,因為有自動創建表的能力,所以對該用戶需要有create table的許可權 |
| canal.instance.tsdb.dbPassword | canal | jdbc密碼 |
例子:
# table meta tsdb info
canal.instance.tsdb.enable=true
canal.instance.tsdb.dir=${canal.file.data.dir:../conf}/${canal.instance.destination:}
canal.instance.tsdb.url=jdbc:h2:${canal.instance.tsdb.dir}/h2;CACHE_SIZE=1000;MODE=MYSQL;
#canal.instance.tsdb.url=jdbc:mysql://127.0.0.1:3306/canal_tsdb
canal.instance.tsdb.dbUsername=canal
canal.instance.tsdb.dbPassword=canal三、最後
目前canal 1.0.26最新版已經預設開啟了時序表結構的能力,just have fun !


