
最近發現一個分頁查詢存儲過程中的的一個SQL語句,當聚集索引列的排序方式不同的時候,效率差別達到數十倍,讓我感到非常吃驚 由此引發出來分頁查詢的情況下對大表做Clustered Scan的時候, 不同情況下會選擇FORWARD 或者 BACKWARD差別,以及建立聚集索引時,選擇索引列的排序方式的一 ...
最近發現一個分頁查詢存儲過程中的的一個SQL語句,當聚集索引列的排序方式不同的時候,效率差別達到數十倍,讓我感到非常吃驚
由此引發出來分頁查詢的情況下對大表做Clustered Scan的時候,
不同情況下會選擇FORWARD 或者 BACKWARD差別,以及建立聚集索引時,選擇索引列的排序方式的一些思考
廢話不多,上代碼
先建立一張測試表,在Col1上建立聚集索引,寫入100W條數據
create table ClusteredIndexScanDirection ( Col1 int identity(1,1), Col2 varchar(50), Col3 varchar(50), Col4 Datetime ) create unique clustered index idx_Col1 on ClusteredIndexScanDirection(Col1 ASC) insert into ClusteredIndexScanDirection values (NEWID(),NEWID(),GETDATE()-RAND()*100) go 1000000
先直觀地看一下聚集索引掃描時候的FORWARD 和 BACKWARD
FORWARD
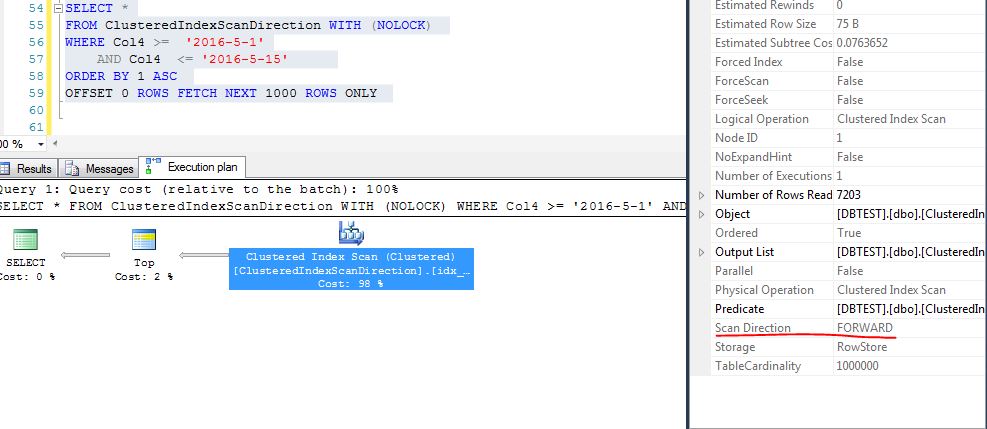
執行如下分頁查詢,當按照Col4符合2016-5-1和2016-5-15,並且Col1 正序排序的時候
從執行計劃看,Clustered Index Scan的Scan Direction的方式是BACKWARD
BACKWARD
執行如下分頁查詢,當按照Col4符合2016-5-1和2016-5-15,並且Col1 倒敘排序的時候
從執行計劃看,Clustered Index Scan的Scan Direction的方式是BACKWARD

那麼性能上有麽有差別?肯定有,如果沒有,本文也就沒有什麼意義了
如圖是上述兩種查詢方式在我本機的測試結果,同樣是前1000條數據,因為排序方式不同,其代價也是不同的
或許你認為邏輯讀,一個是100次,一個是97次,沒多大差別啊,當然這裡這是測試,在實際場景中,這個差別是非常非常大的

對FORWARD和BACKWARD有一個直觀的感受之後,來說說這兩者的區別
如果瞭解B樹索引結構的話,應該知道聚集索引是以類似於B樹結構的方式來組織的,既然是B樹結構,
那麼下麵這個圖就不難理解了,
在索引列按照某事方式排序的情況下,比如
create unique clustered index idx_Col1 on ClusteredIndexScanDirection(Col1 ASC)
或者是
create unique clustered index idx_Col1 on ClusteredIndexScanDirection(Col1 DESC)
下麵這張圖分別是FORWARD和BACKWARD兩種Scan direction的實現方式

FORWARD

BACKWARD
Sql Server究竟選中哪種方式,是FORWARD還是BACKWARD,是依賴於你的索引情況和查詢情況的
以我上面的查詢為例
如果是按照查詢結果正序排序的方式查詢
SELECT * FROM ClusteredIndexScanDirection WITH (NOLOCK) WHERE Col4 >= '2016-5-1' AND Col4 <= '2016-5-15' ORDER BY 1 ASC OFFSET 0 ROWS FETCH NEXT 1000 ROWS ONLY
也就是要求查詢結果的排序方式與聚集索引的排序方式一致,聚集索引是ASC的,Sql Server就會採用FORWARD的方式,
也即是從左到右的Scan方式,找到滿足1000條的數據後返回,查詢終止
如果是按照查詢結果的倒序排序的方式查詢
SELECT *
FROM ClusteredIndexScanDirection WITH (NOLOCK)
WHERE Col4 >= '2016-5-1'
AND Col4 <= '2016-5-15'
ORDER BY 1 DESC
OFFSET 0 ROWS FETCH NEXT 1000 ROWS ONLY
也就是要求查詢結果的排序方式與聚集索引的排序方式不一致,聚集索引是ASC的,Sql Server就會採用BACKWARD的方式,
也即是從右到左的Scan方式,找到滿足1000條的數據後返回,查詢終止
現在就存在一個問題,如果聚集索引是按照ASC正序排列的,也就是說在聚集索引排序一定的情況下,
聚集索引列和查詢條件(CreateDate)上的時候都是遞增的,也就是說,查詢目標數據分佈在B樹的右邊,
(當然這麼說不嚴謹,物理存儲中並沒有左右的概念,這些都是邏輯上的,並不是完全物理上的概念),
實際業務中,差不多的意思就是查詢最近N天的數據
如果查詢結果是按照聚集索引正序排序,
Sql Server 採用FORWARD的方式,也即從左至右,那麼這個查詢就要經歷B樹種從左到右很大一部分數據掃描之後,才能找到所需要的數據
如果查詢結果是按照聚集索引倒敘排序,
Sql Server 採用BACKWARD的方式,也即從右至左,那麼這個查詢直接從最右邊開始Scan,很快就能找到符合條件的1000條數據。
聚集索引是ASC或者DESC的方式,也會影響到這個查詢,這些概念都是相對的,當然實際場景中,索引情況和查詢條件可能更複雜,
可見,一個查詢的實現,是通過FORWARD還是BACKWARD,跟聚集索引的排序方式和查詢結果的排序方式,以及查詢條件都有關。
Sql Server 選擇FORWARD或者BACKWARD,本身都沒有錯,如果出現不同排序方式下性能差別非常大的時候,
就要註意到是不是,聚集索引的方式與查詢排序方式之間存在類似上述的問題。
不管是FORWARD或者BACKWARD,避免讓Scan整個表的大部分數據才找到符合條件的數據
當然實際情況也比例子中複雜很多,還是那句話,具體情況具體分析。
比如業務系統查詢數據時,排序方式是固定的(比如你網購的訂單信息,總是按照時間倒敘排列的),當然也不排除其他情況
這就要求我們在創建聚集索引的時候,要考慮到查詢的方式以及排序的方式,慎重地作出選擇。
總結:本文通過聚集索引Scan的兩種方式,FORWARD和BACKWARD,粗淺第分析了表上的聚集索引的排序對查詢時的影響,
我們在選擇聚集索引排序方式的時候,可以考慮到是不是因為FORWARD和BACKWARD的因素,以便進一步的排查確認。
補充:
好吧,算我沒說清楚,這裡是按照聚集索引排序,按照非索引欄位查詢,而不是直接按照聚集索引欄位查詢!!!
我的例子已經寫的很清楚了
如果聚集索引建立在一個欄位上,也即單欄位作為聚集索引,在非聚集索引欄位上查詢,暫不論這個欄位上有沒有索引
如果查詢結果的跟聚集索引的排序方式是相同的,那麼就是FORWARD
如果查詢結果的跟聚集索引的排序方式是相反的,那麼就是BACKWARD
不管是FORWARD還是BACKWARD,究竟要掃描多大範圍才能找到符合條件的數據,
取決於上面說的非聚集索引欄位列的數據分佈
豈能說“ 正序和倒序無差別”?
其實我更想表達的是,因為結果集的排序,會導致在做聚集索引Scan的時候選擇FORWARD或者BACKWARD
FORWARD還是BACKWARD會對查詢的效率有較大的影響,
實際應用中太複雜了,當然修改聚集索引的排序方式可以從一定程度上緩解這種問題,我當然測試過,不然也不會亂說
也有其他方法也可以實現,比如暴力地去修改聚集索引列,或者建立複合聚集索引,辦法也不僅限於此
如果還有不明白的,可以試試下麵這個腳本,可以直接在你機器上執行,看看最後兩個查詢的IO代價
當然這個例子也比較極端
create table ClusteredIndexScanDirection
(
Col1 int identity(1,1),
Col2 varchar(50),
Col3 varchar(50),
Col4 Datetime
)
create unique clustered index idx_Col1 on ClusteredIndexScanDirection(Col1 ASC)
DECLARE @date datetime,@i int=0
set @date=GETDATE()
while @i<1000000
begin
insert into ClusteredIndexScanDirection values (NEWID(),NEWID(),DATEADD(MI,@i,GETDATE()))
set @i=@i+1
end
set statistics io on
SELECT *
FROM ClusteredIndexScanDirection WITH (NOLOCK)
WHERE Col4 >= '2016-6-1'
AND Col4 <= '2016-6-15'
ORDER BY Col1 ASC
OFFSET 0 ROWS FETCH NEXT 1000 ROWS ONLY
SELECT *
FROM ClusteredIndexScanDirection WITH (NOLOCK)
WHERE Col4 >= '2016-6-1'
AND Col4 <= '2016-6-15'
ORDER BY Col1 DESC
OFFSET 0 ROWS FETCH NEXT 1000 ROWS ONLY


