
Hadoop HDFS負載均衡 轉載請註明出處: "http://www.cnblogs.com/BYRans/" <br/ Hadoop HDFSHadoop 分散式文件系統(Hadoop Distributed File System),簡稱 HDFS,被設計成適合運行在通用硬體上的分散式...
Hadoop HDFS負載均衡
轉載請註明出處:http://www.cnblogs.com/BYRans/
Hadoop HDFS
Hadoop 分散式文件系統(Hadoop Distributed File System),簡稱 HDFS,被設計成適合運行在通用硬體上的分散式文件系統。它和現有的分散式文件系統有很多的共同點。HDFS 是一個高容錯性的文件系統,提供高吞吐量的數據訪問,非常適合大規模數據集上的應用。
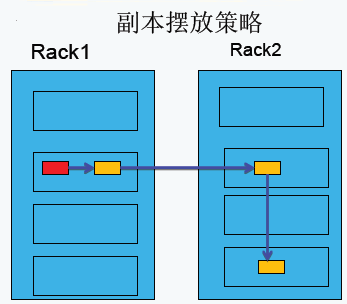
HDFS副本擺放策略
第一副本:放置在上傳文件的DataNode上;如果是集群外提交,則隨機挑選一臺磁碟不太慢、CPU不太忙的節點上;
第二副本:放置在於第一個副本不同的機架的節點上;
第三副本:與第二個副本相同機架的不同節點上;
如果還有更多的副本:隨機放在節點中;
需要註意的是:
- HDFS中存儲的文件的副本數由上傳文件時設置的副本數決定。無論以後怎麼更改系統副本繫數,這個文件的副本數都不會改變;
- 在上傳文件時優先使用啟動命令中指定的副本數,如果啟動命令中沒有指定則使用hdfs-site.xml中dfs.replication設置的預設值;
HDFS負載均衡
Hadoop的HDFS集群非常容易出現機器與機器之間磁碟利用率不平衡的情況,例如:當集群內新增、刪除節點,或者某個節點機器內硬碟存儲達到飽和值。當數據不平衡時,Map任務可能會分配到沒有存儲數據的機器,這將導致網路帶寬的消耗,也無法很好的進行本地計算。
當HDFS負載不均衡時,需要對HDFS進行數據的負載均衡調整,即對各節點機器上數據的存儲分佈進行調整。從而,讓數據均勻的分佈在各個DataNode上,均衡IO性能,防止熱點的發生。進行數據的負載均衡調整,必須要滿足如下原則:
- 數據平衡不能導致數據塊減少,數據塊備份丟失
- 管理員可以中止數據平衡進程
- 每次移動的數據量以及占用的網路資源,必須是可控的
- 數據均衡過程,不能影響namenode的正常工作
Hadoop HDFS數據負載均衡原理
數據均衡過程的核心是一個數據均衡演算法,該數據均衡演算法將不斷迭代數據均衡邏輯,直至集群內數據均衡為止。該數據均衡演算法每次迭代的邏輯如下:
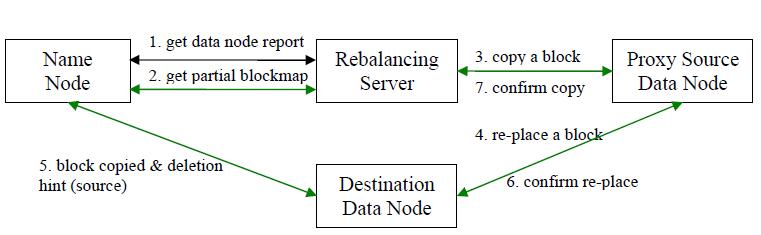
步驟分析如下:
- 數據均衡服務(Rebalancing Server)首先要求 NameNode 生成 DataNode 數據分佈分析報告,獲取每個DataNode磁碟使用情況
- Rebalancing Server彙總需要移動的數據分佈情況,計算具體數據塊遷移路線圖。數據塊遷移路線圖,確保網路內最短路徑
- 開始數據塊遷移任務,Proxy Source Data Node複製一塊需要移動數據塊
- 將複製的數據塊複製到目標DataNode上
- 刪除原始數據塊
- 目標DataNode向Proxy Source Data Node確認該數據塊遷移完成
- Proxy Source Data Node向Rebalancing Server確認本次數據塊遷移完成。然後繼續執行這個過程,直至集群達到數據均衡標準
DataNode分組
在第2步中,HDFS會把當前的DataNode節點,根據閾值的設定情況劃分到Over、Above、Below、Under四個組中。在移動數據塊的時候,Over組、Above組中的塊向Below組、Under組移動。四個組定義如下:
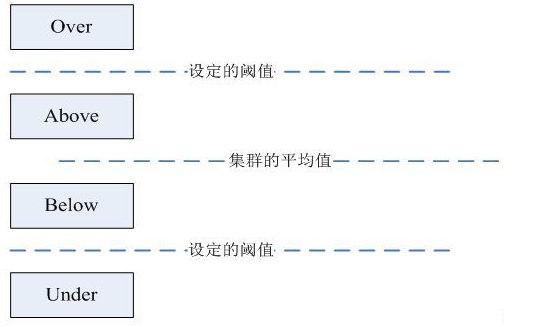
- Over組:此組中的DataNode的均滿足
DataNode_usedSpace_percent > Cluster_usedSpace_percent + threshold
- Above組:此組中的DataNode的均滿足
Cluster_usedSpace_percent + threshold > DataNode_ usedSpace _percent > Cluster_usedSpace_percent
- Below組:此組中的DataNode的均滿足
Cluster_usedSpace_percent > DataNode_ usedSpace_percent > Cluster_ usedSpace_percent – threshold
- Under組:此組中的DataNode的均滿足
Cluster_usedSpace_percent – threshold > DataNode_usedSpace_percent
Hadoop HDFS 數據自動平衡腳本使用方法
在Hadoop中,包含一個start-balancer.sh腳本,通過運行這個工具,啟動HDFS數據均衡服務。該工具可以做到熱插拔,即無須重啟電腦和 Hadoop 服務。\(Hadoop_Home/bin 目錄下的 start-balancer.sh 腳本就是該任務的啟動腳本。 啟動命令為:`\)Hadoop_home/bin/start-balancer.sh –threshold
影響Balancer的幾個參數:
- -threshold
- 預設設置:10,參數取值範圍:0-100
- 參數含義:判斷集群是否平衡的閾值。理論上,該參數設置的越小,整個集群就越平衡
- dfs.balance.bandwidthPerSec
- 預設設置:1048576(1M/S)
- 參數含義:Balancer運行時允許占用的帶寬
示例如下:
#啟動數據均衡,預設閾值為 10%
$Hadoop_home/bin/start-balancer.sh
#啟動數據均衡,閾值 5%
bin/start-balancer.sh –threshold 5
#停止數據均衡
$Hadoop_home/bin/stop-balancer.sh在hdfs-site.xml文件中可以設置數據均衡占用的網路帶寬限制
<property>
<name>dfs.balance.bandwidthPerSec</name>
<value>1048576</value>
<description> Specifies the maximum bandwidth that each datanode can utilize for the balancing purpose in term of the number of bytes per second. </description>
</property>

