
URI 規範和 W3C 規範衝突了,才會搞出這種讓人疑惑的烏龍事件 ...
「靈異」的空格
1.%20 還是 + ?
這個是個史詩級的大坑,我曾經被這個協議衝突坑了一天。
開始講解前先看個小測試,在瀏覽器里輸入 blank test( blank 和 test 間有個空格),我們看看瀏覽器如何處理的:

從動圖可以看出瀏覽器把空格解析為一個加號「+」。
是不是感覺有些奇怪?我們再做個測試,用瀏覽器提供的幾個函數試一下:
encodeURIComponent("blank test") // "blank%20test"
encodeURI("q=blank test") // "q=blank%20test"
new URLSearchParams("q=blank test").toString() // "q=blank+test"

代碼是不會說謊的,其實上面的結果都是正確的,encode 結果不一樣,是因為 URI 規範和 W3C 規範衝突了,才會搞出這種讓人疑惑的烏龍事件。
2.衝突的協議
我們首先看看 URI 中的保留字,這些保留字不參與編碼。保留字元一共有兩大類:
gen-delims: :/?#[]@sub-delims: !$&'()*+,;=
URI 的編碼規則也很簡單,先把非限定範圍的字元轉為 16 進位,然後前面加百分號。
空格這種不安全字元轉為十六進位就是 0x20,前面再加上百分號 % 就是 %20:
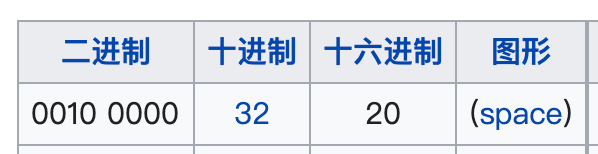
所以這時候再看 encodeURIComponent 和 encodeURI 的編碼結果,就是完全正確的。
既然空格轉為%20 是正確的,那轉為 + 是怎麼回事?這時候我們就要瞭解一下 HTML form 表單的歷史。
早期的網頁沒有 AJAX 的時候,提交數據都是通過 HTML 的 form 表單。form 表單的提交方法可以用 GET 也可以用 POST,大家可以在 MDN form 詞條上測試:

經過測試我們可以看出表單提交的內容中,空格都是轉為加號的,這種編碼類型就是 application/x-www-form-urlencoded,在 WHATWG 規範里是這樣定義的:

到這裡基本上就破案了,URLSearchParams 做 encode 的時候,就按這個規範來的。我找到了 URLSearchParams 的 Polyfill 代碼,裡面就做了 %20 到 + 的映射:
replace = {
'!': '%21',
"'": '%27',
'(': '%28',
')': '%29',
'~': '%7E',
'%20': '+', // <= 就是這個
'%00': '\x00'
}
規範里對這個編碼類型還有解釋說明:
The
application/x-www-form-urlencodedformat is in many ways an aberrant monstrosity, the result of many years of implementation accidents and compromises leading to a set of requirements necessary for interoperability, but in no way representing good design practices. In particular, readers are cautioned to pay close attention to the twisted details involving repeated (and in some cases nested) conversions between character encodings and byte sequences. Unfortunately the format is in widespread use due to the prevalence of HTML forms.這種編碼方式就不是個好的設計,不幸的是隨著 HTML form 表單的普及,這種格式已經推廣開了
其實上面一大段句話就是一個意思:這玩意兒設計的就是


