
前面三篇通過CPU、記憶體、磁碟三巨頭,講述瞭如何透過現在看本質,怎樣定位伺服器三巨頭反映出的問題。為了方便閱讀給出鏈接: Expert 診斷優化系列 你的CPU高麽? Expert 診斷優化系列 記憶體不夠用麽? Expert 診斷優化系列 冤枉磁碟了 通過三篇文章的基本介紹,可以看出系統的語句如果不 ...
前面三篇通過CPU、記憶體、磁碟三巨頭,講述瞭如何透過現在看本質,怎樣定位伺服器三巨頭反映出的問題。為了方便閱讀給出鏈接:
Expert 診斷優化系列------------------你的CPU高麽?
Expert 診斷優化系列------------------記憶體不夠用麽?
Expert 診斷優化系列------------------冤枉磁碟了
通過三篇文章的基本介紹,可以看出系統的語句如果不優化,可能會導致三巨頭都出現異常的表現。所以本篇開始介紹系統中的重頭戲--------------SQL語句!
-
開篇前的啰嗦
什麼是SQL 語句 ?

這就是SQL 語句! 帥氣吧!還有呢!

這也是SQL語句!
博主真能騙人,我讀書少也知道,這是“車、馬、炮”的 “車” ! 沒錯,此篇文章里會以“車”來代表你的SQL 語句,讓你知道怎樣讓你的“車”從16手報廢車改裝成------------------ |法拉利|
註:SQL語句優化的細節,一本書都寫不全,所以這裡只講述“改裝思想!”
- 改裝有順序------常開的愛車下手
你的系統中有成千上萬的語句,那麼優化語句從何入手呢 ? 當然是系統中運行最頻繁,最核心的語句了。廢話不多說,上例子:

這是一天的語句執行情況,裡面柱狀圖表示的是對應執行時間段內語句的次數,總體看起來長時間語句非常多。
下麵看一下具體的語句執行情況:

排位第一的語句執行次數38508次,是一個存儲過程(RPC:Completed 表示存儲過程結束,不知道這個的請看profiler的使用說明)。其中的一條語句(SP:StmtCompleted)也就是排在第二位的語句,存儲過程的執行時間大部分消耗這條子語句上!
這個例子可以看出業務系統中使用最頻繁,且遠遠高於其他處理的語句就是這個執行3W8Q多次的語句。
那麼看到這樣的數據,想做優化當然要從這條語句下手了!它就是你最常開的車了! 這個例子中只要解決了這條語句的性能問題,整個系統性能就可以有一個質的飛躍。
--------------------------------上面的情況,你很專一,只喜歡開一種車!----------------------------
這個例子中,你喜歡開的車就比較多了,也就是說需要你關註,並且優化的語句較多。(很多語句執行次數都很頻繁,也就是系統中使用到的頻繁功能較多)


系統優化需要循序漸進,從系統最頻繁的語句出發,逐個解決語句問題。
有人看到這會說,博主你有工具,能收集、能統計,我啥也沒有咋整?不要急後文腳本都會奉上!
- 改裝前的知識儲備
知識儲備很重要,語句的優化涉及的地方很多很多,要麼為什麼說可以寫本書呢?
- 你知道什麼是執行計劃麽?如何在語句執行的同時,看到執行計劃?
- 你知道索引有幾種?有什麼區別麽?
- 你知道有索引和沒索引,語句執行的區別麽?
- 你知道什麼是統計信息麽?
- 你知道什麼是臨時表,表變數,CTE?有什麼區別?
- 什麼是事務?什麼是隔離級別?
- 你知道什麼是邏輯讀,什麼是物理讀,什麼是預讀麽?怎麼查看你執行消耗的IO資源?
- 你知道什麼是等待?怎麼查看你運行的語句是否在等待?等待反應出的問題是什麼?
- 你瞭解SQL的鎖機制麽?
- 你瞭解TempDB麽?什麼樣的語句會使用TempDB?
- 編譯與重編譯?
- 查詢提示是乾什麼的?
- .....
- .....
- .....
- .....
- 常見的改裝方式
------------------------------------新手區-----------高手勿進-------------------------------------
是不是就沒法短時間內,掌握大部分語句的優化技巧呢? 這是可以的,簡單介紹一下語句簡單粗暴的調優方式:
開啟執行計劃,讓執行計劃告訴你,語句慢的原因

透過計劃,一眼看出索引

當語句執行後,執行計劃中會提示你這條運行的語句中是否缺少索引,右鍵綠色部分"缺少索引提示",點擊缺少索引詳細信息,生成對應的索引腳本,創在在資料庫中。
在次執行語句驗證是否有效,如果還繼續提示索引缺失,繼續按照此方法創建索引。
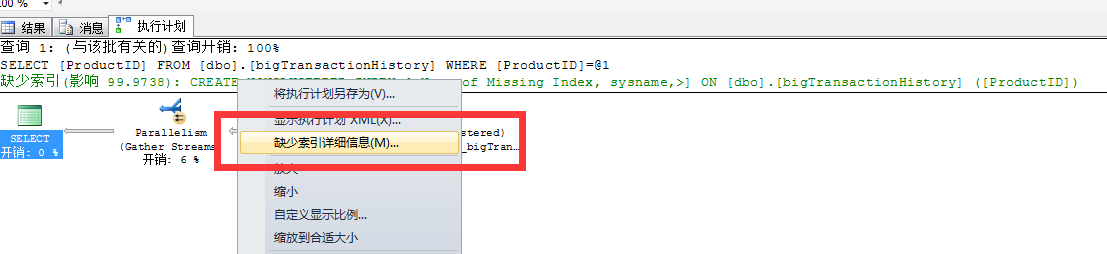
索引對於一個語句的影響很大,一個有效的索引可以縮短語句的執行時間,並且降低CPU、IO、記憶體等消耗。也就是說不但讓你的語句執行快,更降低了寶貴的系統資源消耗!
執行計劃中除了可以看出缺失的索引,也可以看出語句的主要消耗在哪。知道了主要消耗,我們也就可以針對這個消耗進行優化。如例子中94%的開銷在表的掃描上。當看到這個開銷很大並且是一個掃描的時候,第一反應要看掃描的表,有沒有篩選條件“where”條件,或 “關聯條件join" 如果有條件,那就看為什麼沒有先用條件過濾數據!是不是沒有索引? 是不是創建的索引不能用(隱式轉換?列上有函數?等等,具體為什麼不能使用索引,請自行百度)
高能提示:不要小看索引,感覺這都是小兒科。在我親身經歷的眾多客戶之中,大面積缺少索引的系統可以占到三層以上。或是軟體開發完,對資料庫就沒有建立索引,或是隨著系統的日積月累,數據量、功能也隨之增加,系統得不到一個及時的跟蹤優化導致。
降低語句的複雜度
講一個我自己的故事,我剛從業的時候對資料庫的優化瞭解不深,一度認為自己寫的SQL 好牛逼,因為現在給我,我真是看不懂。一個語句兩張A4紙都列印不下!各種子查詢,視圖嵌套,函數嵌套,UNION ALL等等等。
不能否認這種語句寫出來以後,有種小自豪感!因為別人根本看不懂,改也改不了!這種語句在對於SQL 的優化器來說就是災難,下麵簡單的說下優化器拿到一條語句怎麼樣作出執行計劃:
首先傳入一個語句,如果有視圖,則會把你視圖內的代碼和外層代碼經過二次編譯變成一個大語句(多層視圖都會編譯成一個),然後從表連接開始,優化器會根據統計信息,和一些預查詢(如執行所需要的欄位類型長度,數據量等)針對你的條件選用一個表作為驅動表,然後繼續和其他的表關聯,並選用關聯方式(hash、merge、nested loop)等,每次關聯順序和方式的都基於SQL的預估,也就是關聯的越多,最後的預估可能越不准確,進而導致選用一個比較差的計劃。為什麼有好的不選卻選出一個差的呢?因為優化器不會把你所有執行的可能都驗證一次,然後選擇一個最好的。這裡選出來的“最優”的只是一個相對值。
介紹的有點跑題了,下麵我們說一下降低語句複雜度的常用方式:最常用的就是臨時表,比如先把條件篩選性較強的幾張表關聯,然後把結果放入臨時表,在用臨時表和其他表關聯。可以理解成我有10張表關聯,我先拿5張表出來關聯,然後把結果放入臨時表,再跟另外5張表關聯。這樣這個查詢的複雜度由10張表的聯合變成 5+6,這樣降低了複雜語句複雜度。
複雜視圖也是如此,在視圖和外層關聯前,放入臨時表,再跟外層關聯。
子查詢也是如此,可以分離出來成為臨時表的子查詢,先分離出來。
情況很多種,最終目的就是降低語句複雜性,讓語句分多個步驟執行,這樣也可以讓優化器每次選出一個比較穩定的計劃(一個語句執行有時快有時慢,也很可能是語句的複雜性導致的)。
高能提示:部分系統核心處理的語句比較複雜,且已經很多年前留下的遺產了,經歷了一代又一代,我真心不敢碰。那麼恭喜你中獎了,好好分析下業務,通過臨時表拆分語句還是有可能的!
臨時表和表變數,最大的區別是表變數作為中間過程表不能插入太多數據,如果數據插入的多嚴重影響性能。
降低並行度,或使用並行提升性能
這個小標題好像有些矛盾!解釋一下降低並行度是因為現在的伺服器配置CPU數都很大64或更多的隨處可見,系統選用並行計劃時,使用過多的CPU 反而會使性能下降具體請參見:Expert 診斷優化系列------------------你的CPU高麽?
首先看一個等待: CXPACKET

CXPACKET 是最常見的等待之一,等待 並行計劃 CPU的調度,或線程上的資源等待,請參見
sys.dm_os_waiting_tasks 引發的疑問(上)
sys.dm_os_waiting_tasks 引發的疑問(中)
sys.dm_os_waiting_tasks 引發的疑問(下)
當你看見如圖的等待情況時,說明你系統中並行度需要調整了!請參見系列中的CPU篇,這裡不過多介紹。
另一種情況,語句可以通過並行來提升執行時間,這裡也不過多介紹,請參見SQL提示介紹-強制並行
使用一切方法降低讀次數
一個語句運行起來消耗的讀次數也少,說可以間接說明這個語句優化程度較高,讀取的頁數少也會降低記憶體和磁碟的壓力。
優化時可以開set statistics io on 來觀察語句的IO消耗情況。降低IO的主要方式就是添加索引和降低語句複雜度。
註:重點關註讀次數多的表!

這裡就不細說了!
- 不能忽視的硬體問題
前三篇一直在強調語句很影響伺服器資源。但不能忽略的一點就是,語句的運行好壞也很依賴於資源,硬體資源就好比路面環境。語句這車再好,路沒有那麼寬,也不平坦,再好的車也跑不起來。
反過來就算硬體足夠好,路夠寬也夠好,沒有好車也是跑不起來的!
--------------博客地址---------------------------------------------------------------------------------------
Expert 診斷優化系列 http://www.cnblogs.com/double-K/
-----------------------------------------------------------------------------------------------------
總結:語句運行的效率是系統的關鍵,而運行最頻繁的語句就是關鍵中的關鍵。找出系統運行頻率高且效率較差的語句進行優化,是優化思路中的核心。
80%的優化不需要你有高深的技術積累,程咬金的三板斧輪上去,也會掃倒一大片的。請參見 ”常見改裝“中的三種手段。
剩下20%的優化就需要對知識的不斷積累,在實際場景中獲得更好的知識提升。
硬體和語句相互依賴,都是最優的那自然是好,但是作為技術人員我們保證系統語句是最優的,也是一種責任的體現!
本文只是非常簡單的介紹常規優化的思路和方法,不足之處請諒解。後續文章中也會針對等待、執行計劃、tempDB等繼續細說系統的優化。
PS: 優化需要使用各種手段,反覆嘗試才能達到一個最好的效果,優化無止境。
-------------------------乾貨到了---------------------------------------------------------------------------
沒有自己的SQL工具怎麼找出執行頻繁的語句呢?
- profiler 對系統進行監控(不會的小伙伴,快去百度吧)
- DMV視圖 ,篩選條件請自行修改
with aa as ( SELECT --執行次數 QS.execution_count, --查詢語句 SUBSTRING(ST.text,(QS.statement_start_offset/2)+1, ((CASE QS.statement_end_offset WHEN -1 THEN DATALENGTH(st.text) ELSE QS.statement_end_offset END - QS.statement_start_offset)/2) + 1 ) AS statement_text, --執行文本 ST.text, --執行計劃 qs.last_elapsed_time, qs.min_elapsed_time, qs.max_elapsed_time, QS.total_worker_time, QS.last_worker_time, QS.max_worker_time, QS.min_worker_time FROM sys.dm_exec_query_stats QS --關鍵字 CROSS APPLY sys.dm_exec_sql_text(QS.sql_handle) ST WHERE QS.last_execution_time > '2016-02-14 00:00:00' and execution_count > 500 -- AND ST.text LIKE '%%' --ORDER BY --QS.execution_count DESC ) select text,max(execution_count) execution_count --,last_elapsed_time,min_elapsed_time,max_elapsed_time from aa where [text] not like '%sp_MSupd_%' and [text] not like '%sp_MSins_%' and [text] not like '%sp_MSdel_%' group by text order by 2 desc
怎麼查看自己系統缺失的索引?適合大批量創建索引
這裡的DMV信息只是記錄自上次SQL Server啟動以後的信息項,也就是說每次重啟之後這部分信息就丟失了,所以對於生產系統,建議確保運行了一段周期之後再進行查看。
在我們重新創建聚集索引的時候,SQL Server會預設的重新生成全部非聚集索引,如果表數據量特別大,這個過程會很漫長,如果不指定ONLINE的話,這個過程會是鎖定索引B-Teee的,這就意味著是阻塞的,業務就要停下來等待完成操作。
------------------缺失索引----------------------- SELECT migs.group_handle, mid.* FROM sys.dm_db_missing_index_group_stats AS migs INNER JOIN sys.dm_db_missing_index_groups AS mig ON (migs.group_handle = mig.index_group_handle) INNER JOIN sys.dm_db_missing_index_details AS mid ON (mig.index_handle = mid.index_handle) WHERE migs.group_handle = 2 ----------------------------------無用索引---------------------- SET TRANSACTION ISOLATION LEVEL READ UNCOMMITTED SELECT DB_NAME() AS DatbaseName , SCHEMA_NAME(O.Schema_ID) AS SchemaName , OBJECT_NAME(I.object_id) AS TableName , I.name AS IndexName INTO #TempNeverUsedIndexes FROM sys.indexes I INNER JOIN sys.objects O ON I.object_id = O.object_id WHERE 1=2 EXEC sp_MSForEachDB 'USE [?]; INSERT INTO #TempNeverUsedIndexes SELECT DB_NAME() AS DatbaseName , SCHEMA_NAME(O.Schema_ID) AS SchemaName , OBJECT_NAME(I.object_id) AS TableName , I.NAME AS IndexName FROM sys.indexes I INNER JOIN sys.objects O ON I.object_id = O.object_id LEFT OUTER JOIN sys.dm_db_index_usage_stats S ON S.object_id = I.object_id AND I.index_id = S.index_id AND DATABASE_ID = DB_ID() WHERE OBJECTPROPERTY(O.object_id,''IsMsShipped'') = 0 AND I.name IS NOT NULL AND S.object_id IS NULL' SELECT * FROM #TempNeverUsedIndexes ORDER BY DatbaseName, SchemaName, TableName, IndexName DROP TABLE #TempNeverUsedIndexes --------------------------經常被大量更新,但是卻基本不適用的索引項-------------------- SET TRANSACTION ISOLATION LEVEL READ UNCOMMITTED SELECT DB_NAME() AS DatabaseName , SCHEMA_NAME(o.Schema_ID) AS SchemaName , OBJECT_NAME(s.[object_id]) AS TableName , i.name AS IndexName , s.user_updates , s.system_seeks + s.system_scans + s.system_lookups AS [System usage] INTO #TempUnusedIndexes FROM sys.dm_db_index_usage_stats s INNER JOIN sys.indexes i ON s.[object_id] = i.[object_id] AND s.index_id = i.index_id INNER JOIN sys.objects o ON i.object_id = O.object_id WHERE 1=2 EXEC sp_MSForEachDB 'USE [?]; INSERT INTO #TempUnusedIndexes SELECT TOP 20 DB_NAME() AS DatabaseName , SCHEMA_NAME(o.Schema_ID) AS SchemaName , OBJECT_NAME(s.[object_id]) AS TableName , i.name AS IndexName , s.user_updates , s.system_seeks + s.system_scans + s.system_lookups AS [System usage] FROM sys.dm_db_index_usage_stats s INNER JOIN sys.indexes i ON s.[object_id] = i.[object_id] AND s.index_id = i.index_id INNER JOIN sys.objects o ON i.object_id = O.object_id WHERE s.database_id = DB_ID() AND OBJECTPROPERTY(s.[object_id], ''IsMsShipped'') = 0 AND s.user_seeks = 0 AND s.user_scans = 0 AND s.user_lookups = 0 AND i.name IS NOT NULL ORDER BY s.user_updates DESC' SELECT TOP 20 * FROM #TempUnusedIndexes ORDER BY [user_updates] DESC DROP TABLE #TempUnusedIndexes
----------------------------------------------------------------------------------------------------
註:此文章為原創,歡迎轉載,請在文章頁面明顯位置給出此文鏈接!
若您覺得這篇文章還不錯請點擊下右下角的推薦,非常感謝!
引用高大俠的一句話 :“拒絕SQL Server背鍋,從我做起!”

