一、排序演算法 1、冒泡排序(Bubble Sort) 定義:是一種簡單的排序演算法。它重覆地遍歷要排序的數列,一次比較兩個元素,如果他們的順序錯誤就把他們交換過來。遍曆數列的工作是重覆地進行直到沒有再需要交換,也就是說該數列已經排序完成。這個演算法的名字由來是因為越小的元素會經由交換慢慢“浮”到數列的頂 ...
一、排序演算法
1、冒泡排序(Bubble Sort)
定義:是一種簡單的排序演算法。它重覆地遍歷要排序的數列,一次比較兩個元素,如果他們的順序錯誤就把他們交換過來。遍曆數列的工作是重覆地進行直到沒有再需要交換,也就是說該數列已經排序完成。這個演算法的名字由來是因為越小的元素會經由交換慢慢“浮”到數列的頂端。
原理:
- 比較相鄰的元素。如果第一個比第二個大(升序),就交換他們兩個。
- 對每一對相鄰元素作同樣的工作,從開始第一對到結尾的最後一對。這步做完後,最後的元素會是最大的數。
- 針對所有的元素重覆以上的步驟,除了最後一個。
- 持續每次對越來越少的元素重覆上面的步驟,直到沒有任何一對數字需要比較。
list1 = [12, 54, 23, 56, 67, 45, 1] def bubbleSort(): '''冒泡排序''' for i in range(len(list1) - 1, 0, -1): for j in range(i): if list1[j] > list1[j + 1]: list1[j], list1[j + 1] = list1[j + 1], list1[j] print(list1) bubbleSort()
時間複雜度:
- 最優時間複雜度:O(n) (表示遍歷一次發現沒有任何可以交換的元素,排序結束。)
- 最壞時間複雜度:O(n2)
- 穩定性:穩定
效果圖:

2、選擇排序
定義:選擇排序(Selection sort)是一種簡單直觀的排序演算法。它的工作原理如下。首先在未排序序列中找到最小(大)元素,存放到排序序列的起始位置,然後,再從剩餘未排序元素中繼續尋找最小(大)元素,然後放到已排序序列的末尾。以此類推,直到所有元素均排序完畢。
list1 = [2, 6, 9, 5, 3, 1] def selection_sort(list1): n = len(list1) # 需要進行n-1次選擇操作 for i in range(n - 1): # 記錄最小位置 min_pos = i # 從i+1位置到末尾選擇出最小數據 for j in range(i + 1, n): if list1[j] < list1[min_pos]: min_pos = j # 如果選擇出的數據不在正確位置,進行交換 if min_pos != i: list1[i], list1[min_pos] = list1[min_pos], list1[i] print('----》', list1) selection_sort(list1)
時間複雜度:
- 最優時間複雜度:O(n2)
- 最壞時間複雜度:O(n2)
- 穩定性:不穩定(考慮升序每次選擇最大的情況)
效果圖:
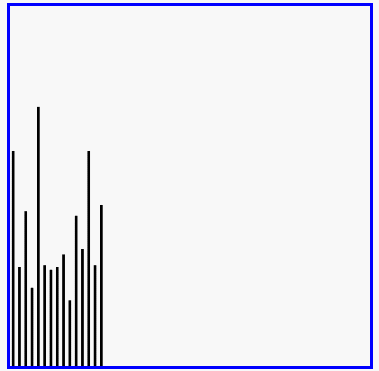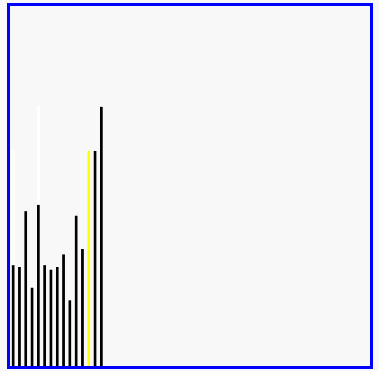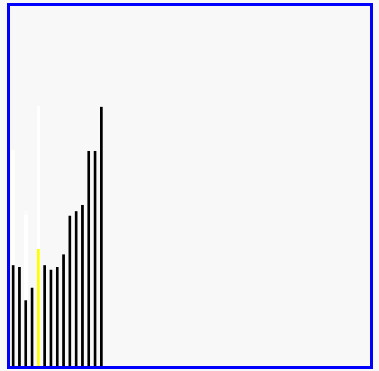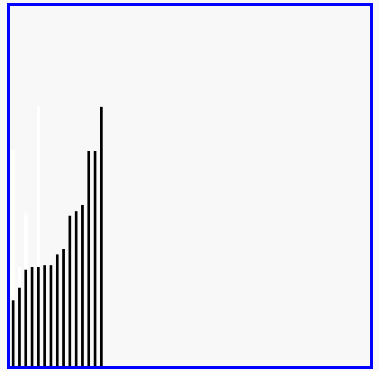
3、插入排序
定義:插入排序(英語:Insertion Sort)是一種簡單直觀的排序演算法。它的工作原理是通過構建有序序列,對於未排序數據,在已排序序列中從後向前掃描,找到相應位置並插入。插入排序在實現上,在從後向前掃描過程中,需要反覆把已排序元素逐步向後挪位,為最新元素提供插入空間。
list1 = [3, 2, 9, 5, 1, 0] def insert_sort(list1): '''插入排序''' # 從第二個位置,即下標為1的元素開始向前插入 for i in range(1, len(list1)): # 從第i個元素開始向前比較,如果小於前一個元素,交換位置 for j in range(i, 0, -1): if list1[j] < list1[j - 1]: list1[j], list1[j - 1] = list1[j - 1], list1[j] print(list1) insert_sort(list1)
時間複雜度:
- 最優時間複雜度:O(n) (升序排列,序列已經處於升序狀態)
- 最壞時間複雜度:O(n2)
- 穩定性:穩定
效果圖:
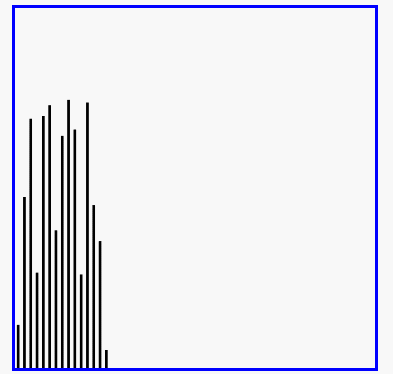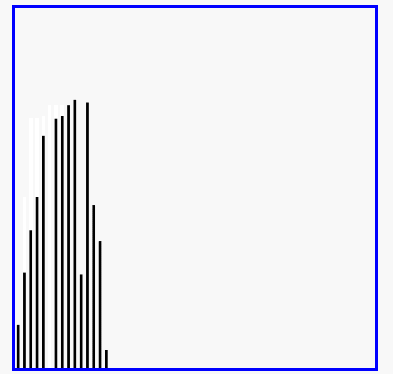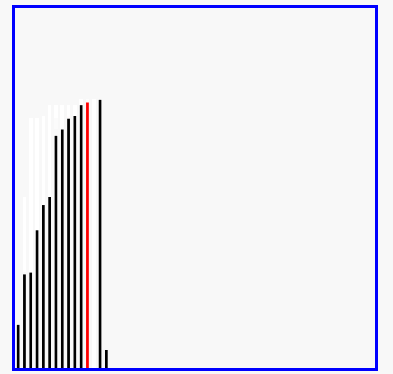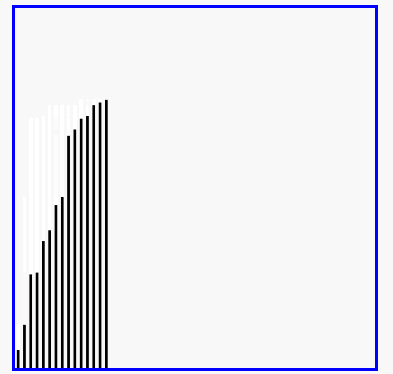
4、快速排序
定義:快速排序(英語:Quicksort),又稱劃分交換排序(partition-exchange sort),通過一趟排序將要排序的數據分割成獨立的兩部分,其中一部分的所有數據都比另外一部分的所有數據都要小,然後再按此方法對這兩部分數據分別進行快速排序,整個排序過程可以遞歸進行,以此達到整個數據變成有序序列。
步驟為:
- 從數列中挑出一個元素,稱為"基準"(pivot),
- 重新排序數列,所有元素比基準值小的擺放在基準前面,所有元素比基準值大的擺在基準的後面(相同的數可以到任一邊)。在這個分區結束之後,該基準就處於數列的中間位置。這個稱為分區(partition)操作。
- 遞歸地(recursive)把小於基準值元素的子數列和大於基準值元素的子數列排序。
遞歸的最底部情形,是數列的大小是零或一,也就是永遠都已經被排序好了。雖然一直遞歸下去,但是這個演算法總會結束,因為在每次的迭代(iteration)中,它至少會把一個元素擺到它最後的位置去。
list1 = [89, 56, 34, 16, 98, 110, 78, 90] def quik_sort(list1, start, end): '''快速排序''' # 遞歸退出的條件 if start >= end: return # 設定起始元素要尋找位置的基準標準 mid = list1[start] # low為序列左邊的由左向右移動的游標 low = start # high為序列左邊的由右向左移動的游標 high = end while low < high: # 若low與high未重合high指向的元素不比基準元素小,則high向左移動 while low < high and list1[high] >= mid: high -= 1 list1[low] = list1[high] # 若low與high未重合low指向的元素不比基準元素小,則low向左移動 while low < high and list1[low] < mid: low += 1 list1[high] = list1[low] # 退出迴圈後,low與high重合,此時所指位置為基準元素的正確位置 # 將基準元素放到該位置 list1[low] = mid # 左邊序列快速排序 遞歸 quik_sort(list1, start, low - 1) # 右邊序列快速排序 quik_sort(list1, low + 1, end) print(list1) quik_sort(list1, 0, len(list1) - 1)
時間複雜讀:
- 最優時間複雜度:O(nlogn)
- 最壞時間複雜度:O(n2)
- 穩定性:不穩定
演示:
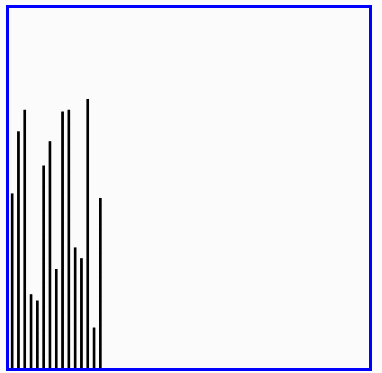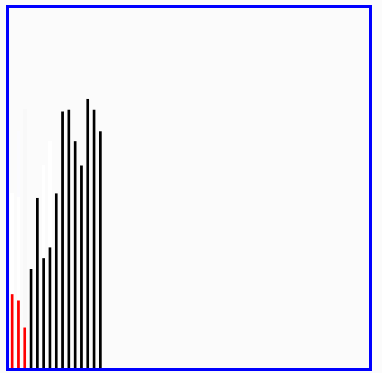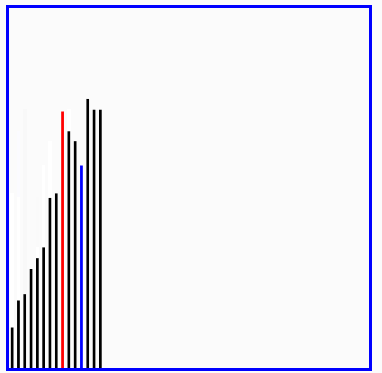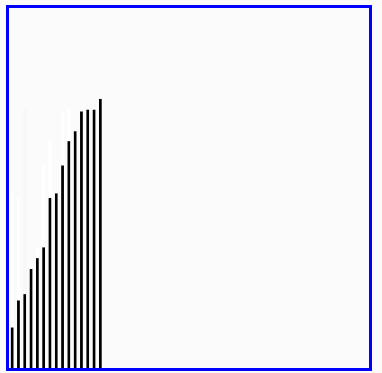
5、希爾排序
定義:希爾排序(Shell Sort)是插入排序的一種。也稱縮小增量排序,是直接插入排序演算法的一種更高效的改進版本。希爾排序是非穩定排序演算法。該方法因DL.Shell於1959年提出而得名。 希爾排序是把記錄按下標的一定增量分組,對每組使用直接插入排序演算法排序;隨著增量逐漸減少,每組包含的關鍵詞越來越多,當增量減至1時,整個文件恰被分成一組,演算法便終止。
基本思想:將數組列在一個表中並對列分別進行插入排序,重覆這過程,不過每次用更長的列(步長更長了,列數更少了)來進行。最後整個表就只有一列了。將數組轉換至表是為了更好地理解這演算法,演算法本身還是使用數組進行排序。
list1 = [23, 17, 77, 54, 12, 43, 65, 45] def shell_sort(list1): '''插入排序''' n = len(list1) # 初始化步長 gap = n // 2 while gap > 0: # 按步長進行插入排序 for i in range(gap, n): j = i while j >= gap and list1[j - gap] > list1[j]: list1[j - gap], list1[j] = list1[j], list1[j - gap] j -= gap gap = gap // 2 print(list1) shell_sort(list1)
時間複雜度:
- 最優時間複雜度:根據步長序列的不同而不同
- 最壞時間複雜度:O(n2)
- 穩定想:不穩定
演示:
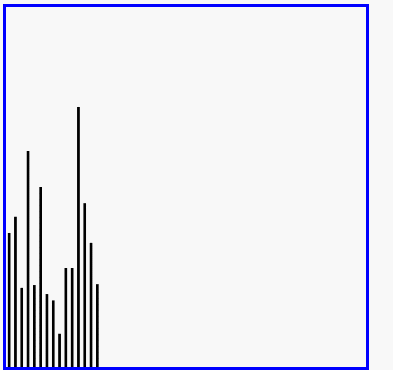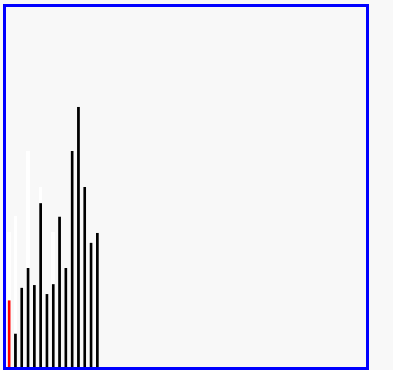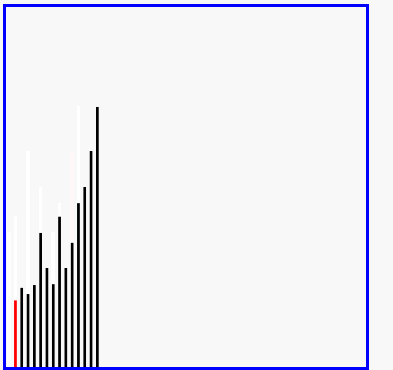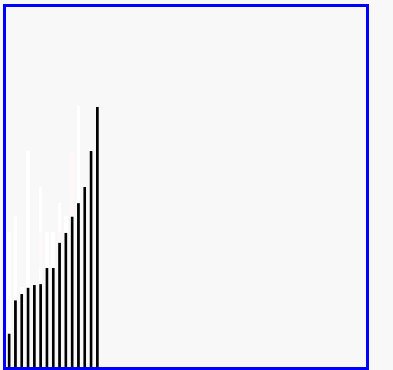
6、歸併排序
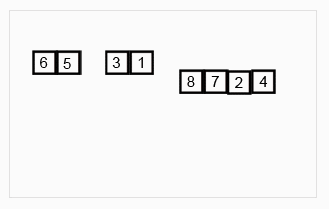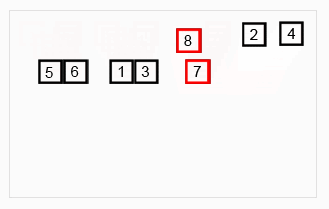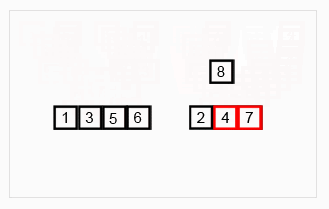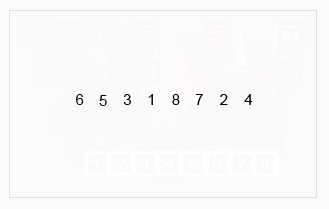
定義:歸併排序是採用分治法的一個非常典型的應用。歸併排序的思想就是先遞歸分解數組,再合併數組。
將數組分解最小之後,然後合併兩個有序數組,基本思路是比較兩個數組的最前面的數,誰小就先取誰,取了後相應的指針就往後移一位。然後再比較,直至一個數組為空,最後把另一個數組的剩餘部分複製過來即可。
原理:
def merge_sort(list1): '''歸併排序''' if len(list1) <= 1: return list1 # 二分分解 num = len(list1) // 2 left = merge_sort(list1[:num]) right = merge_sort(list1[num:]) print(left) print(right) # 進行合併 return merge(left, right) def merge(left, right): '''合併操作,將兩個有序數組left[] right[]合併成一個大的有序數組''' # left與right定義下標 l, r = 0, 0 result = [] while l < len(left) and r < len(right): if left[l] < right[r]: result.append(left[l]) l += 1 else: result.append(right[r]) r += 1 result += left[l:] result += right[r:] return result list1 = [12, 34, 21, 56, 43, 67] a = merge_sort(list1) print(a)
時間複雜度:
- 最優時間複雜度:O(nlogn)
- 最壞時間複雜度:O(nlogn)
- 穩定性:穩定
6種排序演算法比較: