
生成全局唯一 ID 全局唯一 ID 需要滿足以下要求: 唯一性:在分散式環境中,要全局唯一 高可用:在高併發情況下保證可用性 高性能:在高併發情況下生成 ID 的速度必須要快,不能花費太長時間 遞增性:要確保整體遞增的,以便於資料庫創建索引 安全性:ID 的規律性不能太明顯,以免信息泄露 從上面的要 ...
深度解析 Raft 分散式一致性協議
本文參考轉載至:
淺談 Raft 分散式一致性協議|圖解 Raft - 白澤來了 - 博客園 (cnblogs.com)深度解析 Raft 分散式一致性協議 - 掘金 (juejin.cn)
raft-zh_cn/raft-zh_cn.md at master · maemual/raft-zh_cn (github.com)
本篇文章將模擬一個KV數據讀寫服務,從提供單一節點讀寫服務,到結合分散式一致性協議(Raft)後,逐步擴展為一個分散式的,滿足一致性讀寫需求的讀寫服務的過程。
其中將配合引入Raft協議的種種概念:選主、一致性、共識、安全等,通篇閱讀之後,將幫助你深刻理解什麼是分散式一致性協議。
一. 單機Key-Value數據讀寫服務

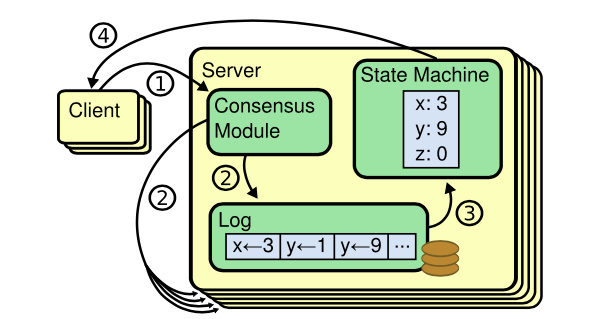
DB Engine這裡可以簡單看成對數據的狀態進行存儲(比如B+樹型的組織形式),負責存儲Key-Value的內容 ,並假設這個Key-Value服務將提供如下介面:
- Get(key) —> value
- Put([key, value])
思考此時Key-Value服務的可靠性:
- 容錯:單個數據存儲節點,不具備容錯能力。
- 高可用:服務部署在單節點上,節點宕機將無法提供服務。
思考此時Key-Value服務的正確性:
- 單進程,所有操作順序執行,可以保證已經存儲的數據是正確的
數據規模不斷增加,我們需要擴大這個Key-Value服務的規模,將其構建成一個分散式的系統
二. 一致性與共識演算法
2.1 從複製開始
既然一個節點會掛,那麼我們就多準備一個節點!
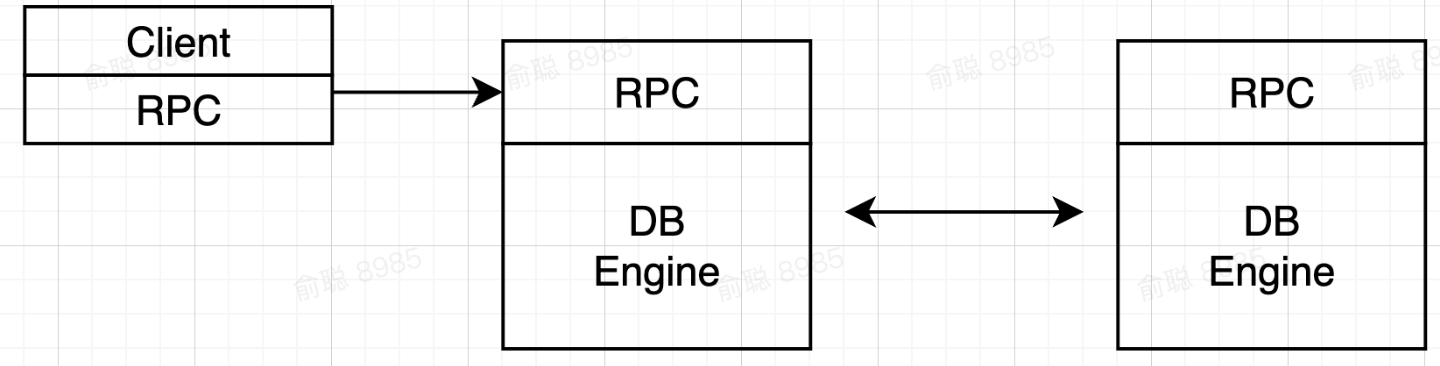
我們這裡只考慮主副本負責接收數據,而從副本只負責同步接收主副本數據的模式,如果主從都開放數據接收能力,將要考慮更多高可用和數據一致性的問題。
2.2 如何複製
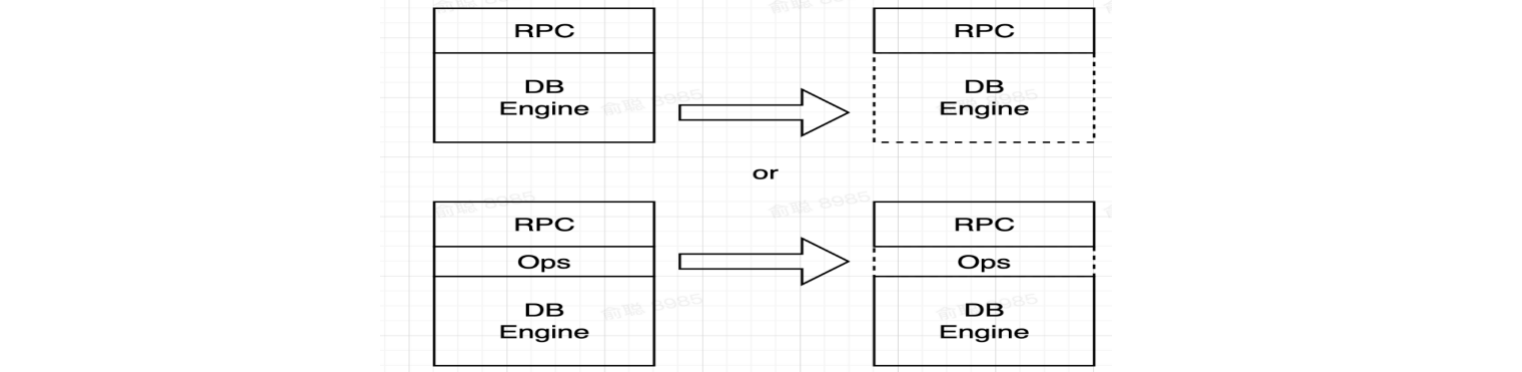
- 主副本定期拷貝全量數據到從副本(代價太高)
- 主副本拷貝操作日誌到從副本:如果你瞭解 MySQL 的主從同步,你就會想起它也是通過從副本監聽主副本當中的
binlog操作日誌變化,進行集群數據同步的,因此這種方式也是更主流的選擇。
2.3 寫流程
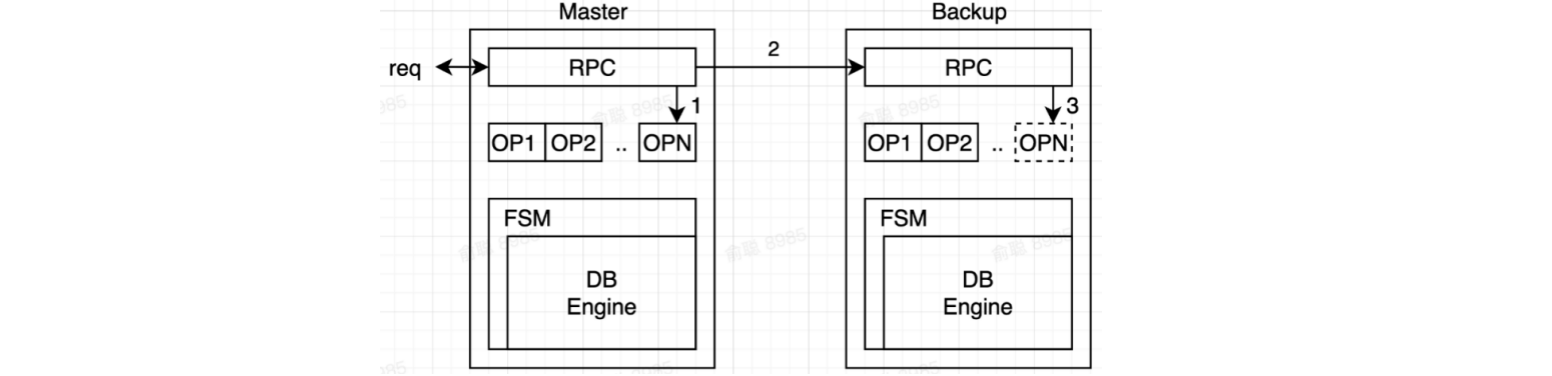
- 主副本把所有的操作打包成
Log- 所有的
Log寫入都是持久化的,保存在磁碟上
- 所有的
- 應用包裝成狀態機(也就是DB Engine部分),只接收
Log作為Input - 主副本確認
Log已經成功寫入到從副本機器上,當狀態機apply後,返回客戶端(關於寫入之後,請求返回客戶端的時機,是可以由應用控制的,可以是Log寫入從副本之後,就從主副本機器返回,也可以等Log完成落盤之後,再返回)
2.4 讀流程
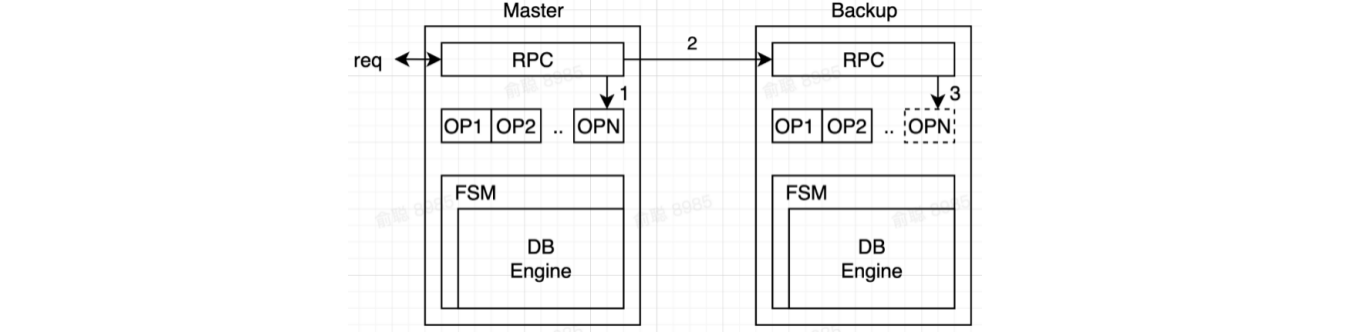
-
方案一:直接讀狀態機(這裡指的是DB),要求上一步寫操作進入狀態機後再返回client(數據已落盤)
-
方案二:寫操作複製
Log完成後直接返回,讀操作Block等待所有pending log進入狀態機 -
如果不遵循上述兩種方案:可能存在剛剛寫入的值讀不到的情況(在Log中)
2.5 什麼是一致性
對於我們的KV服務,要像操作一臺機器一樣,對用戶來說在寫入成功後,就應該能讀到最近寫入的值,而不關心具體底層是如何分散式實現。
一致性是一種模型(或語義),約定一個分散式系統如何向外界提供服務,KV服務中常見的一致性模型有以下兩種:
- 最終一致性:讀取可能暫時讀不到但是總會讀到
- 線性一致性:最嚴格,線性時間執行(寫完KV確保就能讀到),是最理想中的狀態
2.6 複製協議-當失效發生
上述用到的添加了一個從副本節點的方式,我們暫且將其稱為山寨版分散式一致性協議——複製協議(因為它依賴於主從副本間的複製操作)
那麼當主副本失效時,以這個複製協議為基礎的KV服務的運行情況如何呢:
-
容錯能力:沒有容錯能力,因為主副本停了,KV服務就停了
-
高可用:或許有,取決於我們發現主副本宕機後多快將從副本切換為主副本(手動切換)
-
正確性:正確,因為操作只從一臺機器發起,可以控制所有操作返回前都已經複製到另一臺機器了
衍生出的一些的問題:
- 如何保證主副本是真的失效了,切換的過程中如果主副本又開始接收
client請求,則會出現Log覆蓋寫的情況 - 如果增加到3個乃至更多的節點,每次PUT數據的請求都等待其他節點操作落盤性能較差
- 能否允許少數節點掛了的情況下,仍然可以保持服務能工作(具備容錯能力)
2.7 共識演算法
什麼是共識:一個值一旦確定,所有人都認同
共識協議不等於一致性:
- 應用層面不同的一致性,都可以用共識演算法來實現
- 比如可以故意返回舊的值(共識演算法只是一個彼此的約定,只要數據存儲與獲取符合需求,達成共識即可)
- 簡單的複製協議也可以提供線性一致性(雖然不容錯)
一般討論共識協議時提到的一致性,都指線性一致性
- 因為弱一致性往往可以使用相對簡單的複製演算法實現
三. 一致性協議案例:Raft
3.1 Raft 協議是什麼
在分散式系統中,為了消除單點提高系統可用性,通常會使用副本來進行容錯,但這會帶來另一個問題,即如何保證多個副本之間的一致性?
所謂的強一致性(線性一致性)並不是指集群中所有節點在任一時刻的狀態必須完全一致,而是指一個目標,即讓一個分散式系統看起來只有一個數據副本,並且讀寫操作都是原子的,這樣應用層就可以忽略系統底層多個數據副本間的同步問題。也就是說,我們可以將一個強一致性分散式系統當成一個整體,一旦某個客戶端成功的執行了寫操作,那麼所有客戶端都一定能讀出剛剛寫入的值。即使發生網路分區故障,或者少部分節點發生異常,整個集群依然能夠像單機一樣提供服務。
共識演算法(Consensus Algorithm)就是用來做這個事情的,它保證即使在小部分(≤ (N-1)/2)節點故障的情況下,系統仍然能正常對外提供服務。共識演算法通常基於狀態複製機(Replicated State Machine)模型,也就是所有節點從同一個 state 出發,經過同樣的操作 log,最終達到一致的 state。
共識演算法是構建強一致性分散式系統的基石,Paxos 是共識演算法的代表,而 Raft 則是其作者在博士期間研究 Paxos 時提出的一個變種,主要優點是容易理解、易於實現,甚至關鍵的部分都在論文中給出了偽代碼實現。
3.2 誰在使用 Raft
採用 Raft 的系統最著名的當屬 etcd 了,可以認為 etcd 的核心就是 Raft 演算法的實現。作為一個分散式 kv 系統,etcd 使用 Raft 在多節點間進行數據同步,每個節點都擁有全量的狀態機數據。我們在學習了 Raft 以後將會深刻理解為什麼 etcd 不適合大數據量的存儲(for the most critical data)、為什麼集群節點數不是越多越好、為什麼集群適合部署奇數個節點等問題。
作為一個微服務基礎設施,consul 底層使用 Raft 來保證 consul server 之間的數據一致性。在閱讀完第六章後,我們會理解為什麼 consul 提供了 default、consistent、stale 三種一致性模式(Consistency Modes)、它們各自適用的場景,以及 consul 底層是如何通過改變 Raft 讀模型來支撐這些不同的一致性模式的。
TiKV 同樣在底層使用了 Raft 演算法。雖然都自稱是“分散式 kv 存儲”,但 TiKV 的使用場景與 etcd 存在區別。其目標是支持 100TB+ 的數據,類似 etcd 的單 Raft 集群肯定無法支撐這個數據量。因此 TiKV 底層使用 Multi Raft,將數據劃分為多個 region,每個 region 其實還是一個標準的 Raft 集群,對每個分區的數據實現了多副本高可用。
目前 Raft 在工業界已經開始大放異彩,對於其各類應用場景這裡不再贅述,感興趣的讀者可以參考 這裡,下方有列出各種語言的大量 Raft 實現。
3.3 Raft基本概念
Raft 使用 Quorum 機制來實現共識和容錯,我們將對 Raft 集群的操作稱為提案,每當發起一個提案,必須得到大多數(> N/2)節點的同意才能提交。
這裡的“提案”我們可以先狹義地理解為對集群的讀寫操作,“提交”理解為操作成功。
那麼當我們向 Raft 集群發起一系列讀寫操作時,集群內部究竟發生了什麼呢?我們先來概覽式地做一個整體瞭解,接下來再分章節詳細介紹每個部分。
首先,Raft 集群必須存在一個主節點(leader),我們作為客戶端向集群發起的所有操作都必須經由主節點處理。所以 Raft 核心演算法中的第一部分就是選主(Leader election)——沒有主節點集群就無法工作,先票選出一個主節點,再考慮其它事情。
其次,主節點需要承載什麼工作呢?它會負責接收客戶端發過來的操作請求,將操作包裝為日誌同步給其它節點,在保證大部分節點都同步了本次操作後,就可以安全地給客戶端回應響應了。這一部分工作在 Raft 核心演算法中叫日誌複製(Log replication)。
然後,因為主節點的責任是如此之大,所以節點們在選主的時候一定要謹慎,只有符合條件的節點才可以當選主節點。此外主節點在處理操作日誌的時候也一定要謹慎,為了保證集群對外展現的一致性,不可以覆蓋或刪除前任主節點已經處理成功的操作日誌。所謂的“謹慎處理”,其實就是在選主和提交日誌的時候進行一些限制,這一部分在 Raft 核心演算法中叫安全性(Safety)。
Raft 核心演算法其實就是由這三個子問題組成的:選主(Leader election)、日誌複製(Log replication)、安全性(Safety)。這三部分共同實現了 Raft 核心的共識和容錯機制。
除了核心演算法外,Raft 也提供了幾個工程實踐中必須面對問題的解決方案。
第一個是關於日誌無限增長的問題。Raft 將操作包裝成為了日誌,集群每個節點都維護了一個不斷增長的日誌序列,狀態機只有通過重放日誌序列來得到。但由於這個日誌序列可能會隨著時間流逝不斷增長,因此我們必須有一些辦法來避免無休止的磁碟占用和過久的日誌重放。這一部分叫日誌壓縮(Log compaction)。
第二個是關於集群成員變更的問題。一個 Raft 集群不太可能永遠是固定幾個節點,總有擴縮容的需求,或是節點宕機需要替換的時候。直接更換集群成員可能會導致嚴重的腦裂問題。Raft 給出了一種安全變更集群成員的方式。這一部分叫集群成員變更(Cluster membership change)。
此外,我們還會額外討論線性一致性的定義、為什麼 Raft 不能與線性一致劃等號、如何基於 Raft 實現線性一致,以及在如何保證線性一致的前提下進行讀性能優化。
以上便是理論篇內將會討論到的大部分內容的概要介紹,這裡我們對 Raft 已經有了一個巨集觀上的認識,知道了各個部分大概是什麼內容,以及它們之間的關係。
接下來我們將會詳細討論 Raft 演算法的每個部分。讓我們先從第一部分選主開始。
四. 選主
4.1 什麼是選主
選主(Leader election)就是在分散式系統內抉擇出一個主節點來負責一些特定的工作。在執行了選主過程後,集群中每個節點都會識別出一個特定的、唯一的節點作為 leader。
我們開發的系統如果遇到選主的需求,通常會直接基於 zookeeper 或 etcd 來做,把這部分的複雜性收斂到第三方系統。然而作為 etcd 基礎的 Raft 自身也存在“選主”的概念,這是兩個層面的事情:基於 etcd 的選主指的是利用第三方 etcd 讓集群對誰做主節點的決策達成一致,技術上來說利用的是 etcd 的一致性狀態機、lease 以及 watch 機制,這個事情也可以改用單節點的 MySQL/Redis 來做,只是無法獲得高可用性;而 Raft 本身的選主則指的是在 Raft 集群自身內部通過票選、心跳等機制來協調出一個大多數節點認可的主節點作為集群的 leader 去協調所有決策。
當你的系統利用 etcd 來寫入誰是主節點的時候,這個決策也在 etcd 內部被它自己集群選出的主節點處理並同步給其它節點。
4.2 Raft 為什麼要進行選主?
按照論文所述,原生的 Paxos 演算法使用了一種點對點(peer-to-peer)的方式,所有節點地位是平等的。在理想情況下,演算法的目的是制定一個決策,這對於簡化的模型比較有意義。但在工業界很少會有系統會使用這種方式,當有一系列的決策需要被制定的時候,先選出一個 leader 節點然後讓它去協調所有的決策,這樣演算法會更加簡單快速。
此外,和其它一致性演算法相比,Raft 賦予了 leader 節點更強的領導力,稱之為 Strong Leader。比如說日誌條目只能從 leader 節點發送給其它節點而不能反著來,這種方式簡化了日誌複製的邏輯,使 Raft 變得更加簡單易懂。
4.3 Raft 選主過程
Raft協議動畫:Raft 分散式共識演算法動畫演示 (kailing.pub)
4.3.1 節點角色
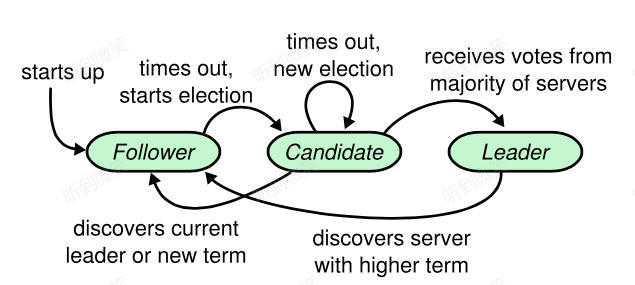
Raft 集群中每個節點都處於以下三種角色之一:
- Leader: 所有請求的處理者,接收客戶端發起的操作請求,寫入本地日誌後同步至集群其它節點。
- Follower: 請求的被動更新者,從 leader 接收更新請求,寫入本地文件。如果客戶端的操作請求發送給了 follower,會首先由 follower 重定向給 leader。
- Candidate: 如果 follower 在一定時間內沒有收到 leader 的心跳,則判斷 leader 可能已經故障,此時啟動 leader election 過程,本節點切換為 candidate 直到選主結束。
2.3.2 任期
每開始一次新的選舉,稱為一個任期(term),每個 term 都有一個嚴格遞增的整數與之關聯。
每當 candidate 觸發 leader election 時都會增加 term,如果一個 candidate 贏得選舉,他將在本 term 中擔任 leader 的角色。但並不是每個 term 都一定對應一個 leader,有時候某個 term 內會由於選舉超時導致選不出 leader,這時 candicate 會遞增 term 號並開始新一輪選舉。
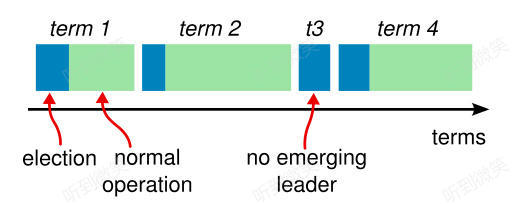
Term 更像是一個邏輯時鐘(logic clock)的作用,有了它,就可以發現哪些節點的狀態已經過期。每一個節點都保存一個 current term,在通信時帶上這個 term 號。
節點間通過 RPC 來通信,主要有兩類 RPC 請求:
- RequestVote RPCs: 用於 candidate 拉票選舉。
- AppendEntries RPCs: 用於 leader 向其它節點複製日誌以及同步心跳。
4.3.3 節點狀態轉換
我們知道集群每個節點的狀態都只能是 leader、follower 或 candidate,那麼節點什麼時候會處於哪種狀態呢?下圖展示了一個節點可能發生的狀態轉換:
4.3.3.1 Follower 狀態轉換過程
Raft 的選主基於一種心跳機制,集群中每個節點剛啟動時都是 follower 身份(Step: starts up),leader 會周期性的向所有節點發送心跳包來維持自己的權威,那麼首個 leader 是如何被選舉出來的呢?方法是如果一個 follower 在一段時間內沒有收到任何心跳,也就是選舉超時,那麼它就會主觀認為系統中沒有可用的 leader,併發起新的選舉(Step: times out, starts election)。
這裡有一個問題,即這個“選舉超時時間”該如何制定?如果所有節點在同一時刻啟動,經過同樣的超時時間後同時發起選舉,整個集群會變得低效不堪,極端情況下甚至會一直選不出一個主節點。Raft 巧妙的使用了一個隨機化的定時器,讓每個節點的“超時時間”在一定範圍內隨機生成,這樣就大大的降低了多個節點同時發起選舉的可能性。
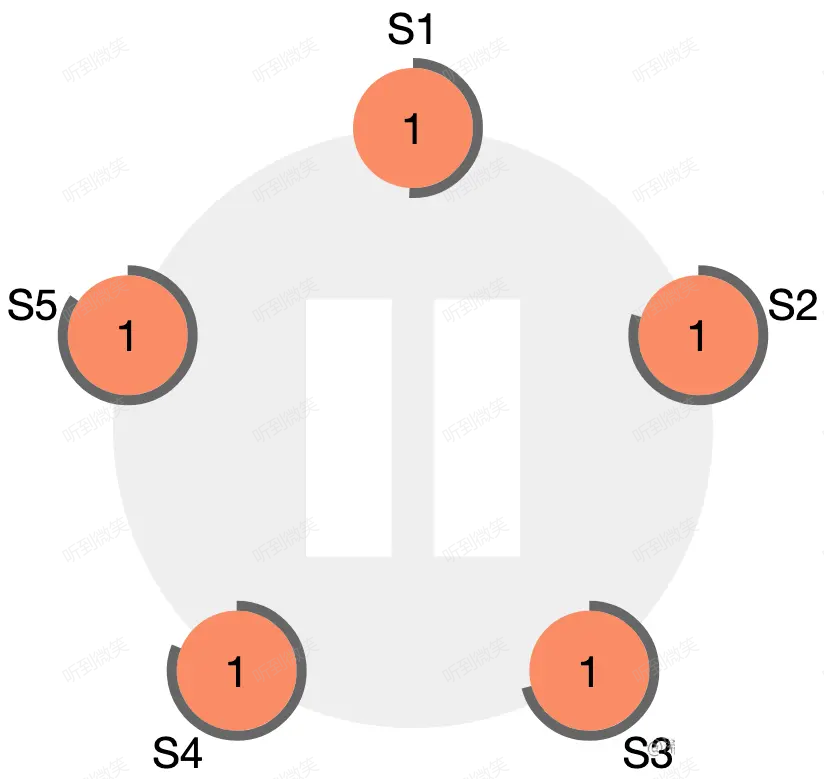
圖:一個五節點 Raft 集群的初始狀態,所有節點都是 follower 身份,term 為 1,且每個節點的選舉超時定時器不同
若 follower 想發起一次選舉,follower 需要先增加自己的當前 term,並將身份切換為 candidate。然後它會向集群其它節點發送“請給自己投票”的消息(RequestVote RPC)。
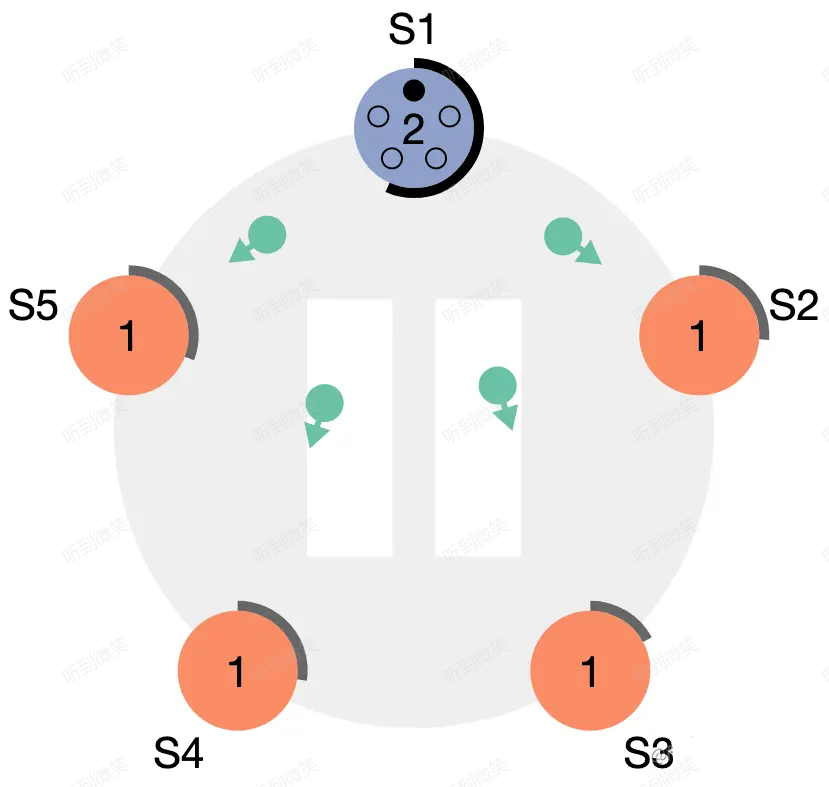
圖:S1 率先超時,變為 candidate,term + 1,並向其它節點發出拉票請求
4.3.3.2 Candicate 狀態轉換過程
Follower 切換為 candidate 並向集群其他節點發送“請給自己投票”的消息後,接下來會有三種可能的結果,也即上面節點狀態圖中 candidate 狀態向外伸出的三條線。
情況一:選舉成功(Step: receives votes from majority of servers)
當candicate從整個集群的大多數(N/2+1)節點獲得了針對同一 term 的選票時,它就贏得了這次選舉,立刻將自己的身份轉變為 leader 並開始向其它節點發送心跳來維持自己的權威。
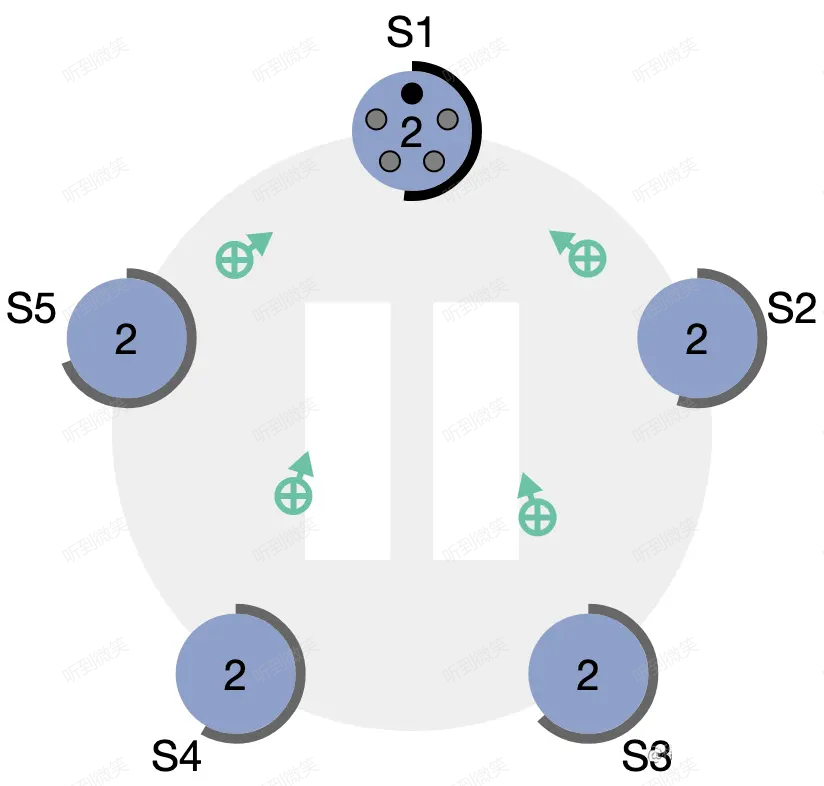
圖:“大部分”節點都給了 S1 選票
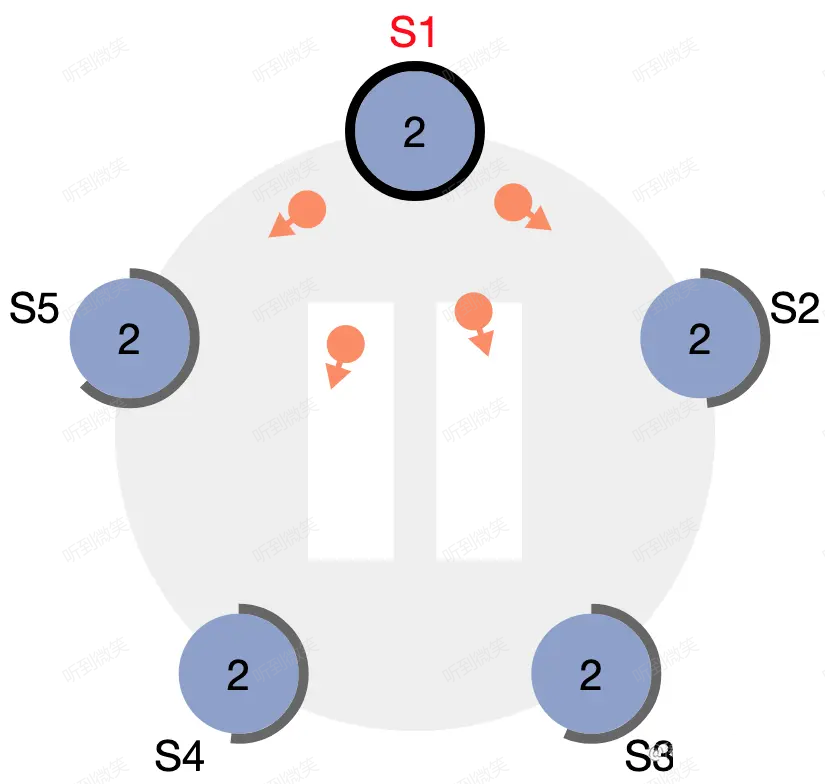
圖:S1 變為 leader,開始發送心跳維持權威
每個節點針對每個 term 只能投出一張票,並且按照先到先得的原則。這個規則確保只有一個 candidate 會成為 leader。
情況二:選舉失敗(Step: discovers current leader or new term)
Candidate 在等待投票回覆的時候,可能會突然收到其它自稱是 leader 的節點發送的心跳包,如果這個心跳包里攜帶的 term 不小於 candidate 當前的 term,那麼 candidate 會承認這個 leader,並將身份切回 follower。這說明其它節點已經成功贏得了選舉,我們只需立刻跟隨即可。但如果心跳包中的 term 比自己小,candidate 會拒絕這次請求並保持選舉狀態。
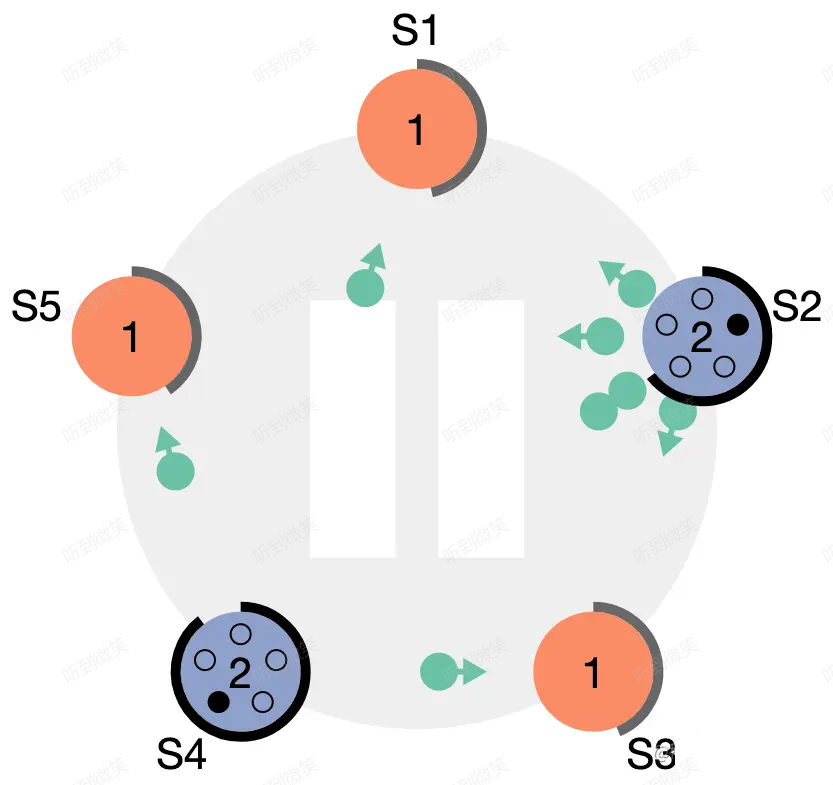
圖:S4、S2 依次開始選舉
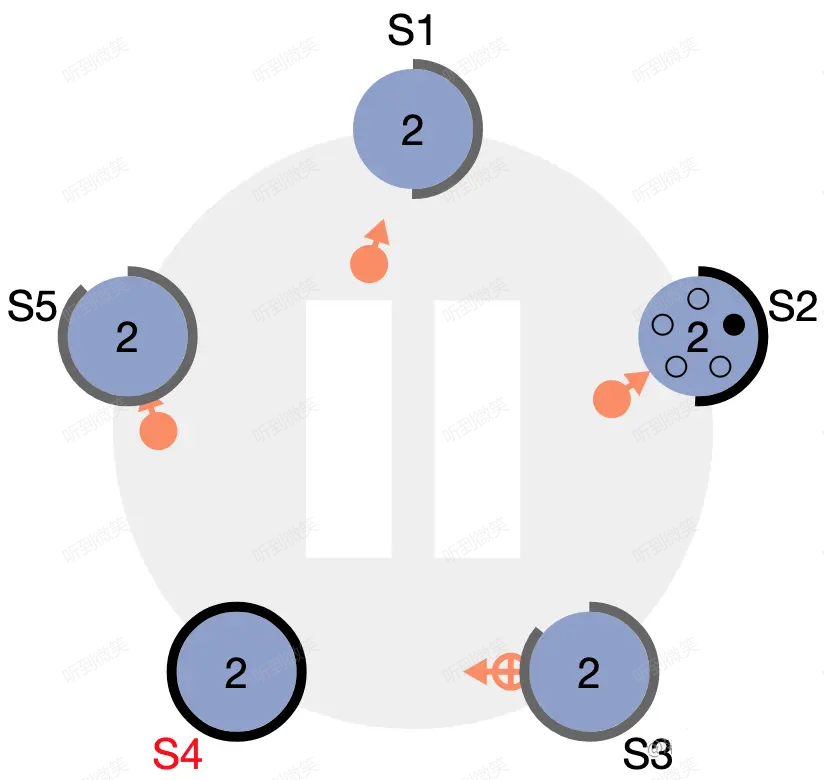
圖:S4 成為 leader,S2 在收到 S4 的心跳包後,由於 term 不小於自己當前的 term,因此會立刻切為 follower 跟隨 S4
情況三:選舉超時(Step: times out, new election)
第三種可能的結果是 candidate 既沒有贏也沒有輸。如果有多個 follower 同時成為 candidate,選票是可能被瓜分的,如果沒有任何一個 candidate 能得到大多數節點的支持,那麼每一個 candidate 都會超時。此時 candidate 需要增加自己的 term,然後發起新一輪選舉。如果這裡不做一些特殊處理,選票可能會一直被瓜分,導致選不出 leader 來。這裡的“特殊處理”指的就是前文所述的隨機化選舉超時時間。
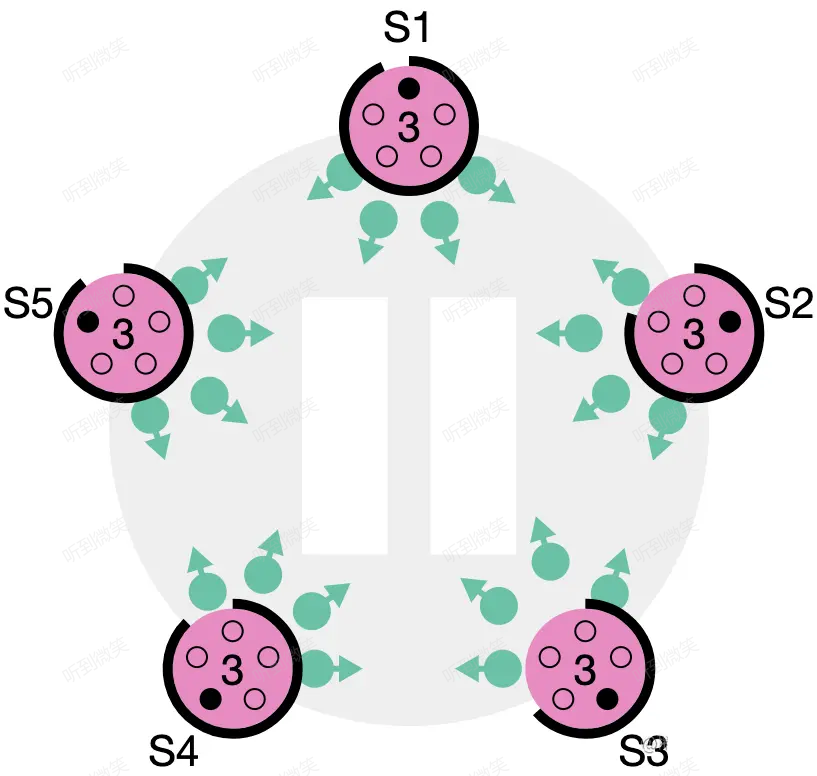
圖:S1 ~ S5 都在參與選舉
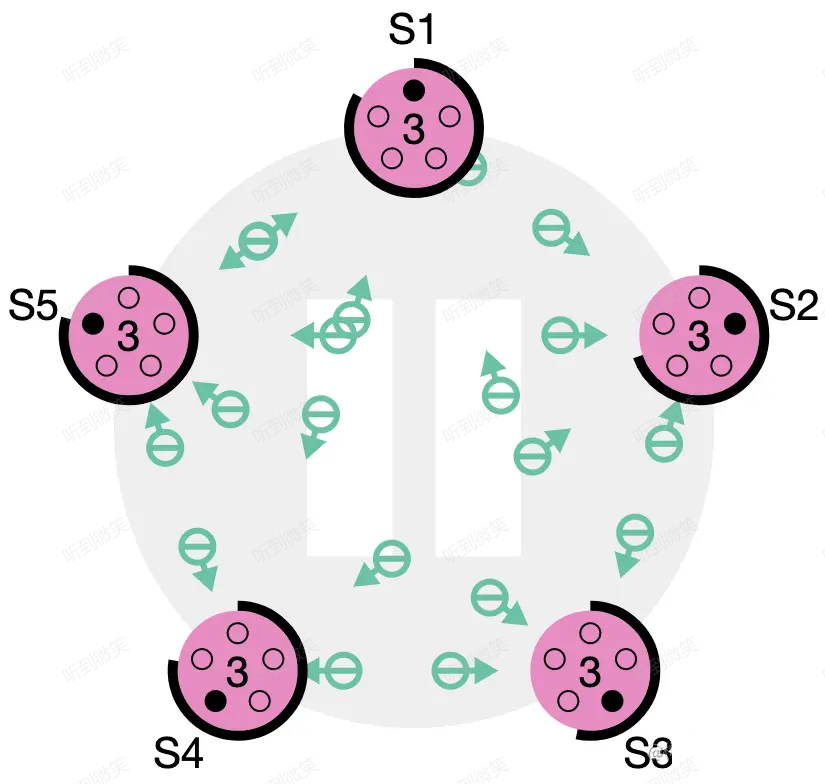
圖:沒有任何節點願意給他人投票
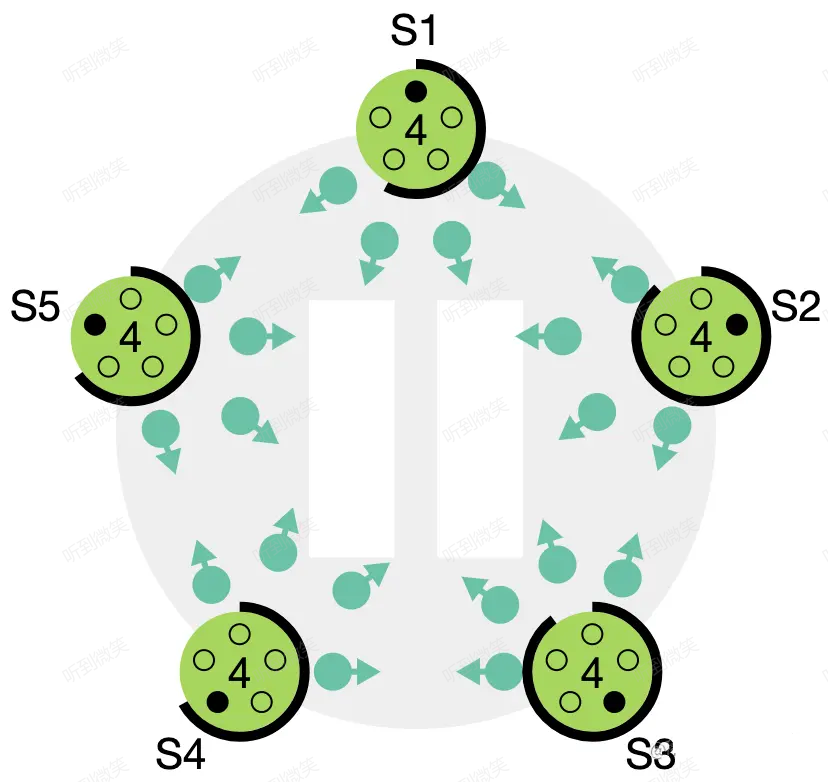
圖:如果沒有隨機化超時時間,所有節點將會繼續同時發起選舉……
以上便是 candidate 三種可能的選舉結果。
4.3.3.3 Leader 狀態轉換過程
節點狀態圖中的最後一條線是:discovers server with higher term。想象一個場景:當 leader 節點發生了宕機或網路斷連,此時其它 follower 會收不到 leader 心跳,首個觸發超時的節點會變為 candidate 並開始拉票(由於隨機化各個 follower 超時時間不同),由於該 candidate 的 term 大於原 leader 的 term,因此所有 follower 都會投票給它,這名 candidate 會變為新的 leader。一段時間後原 leader 恢復了,收到了來自新leader 的心跳包,發現心跳中的 term 大於自己的 term,此時該節點會立刻切換為 follower 並跟隨的新 leader。
上述流程的動畫模擬如下:
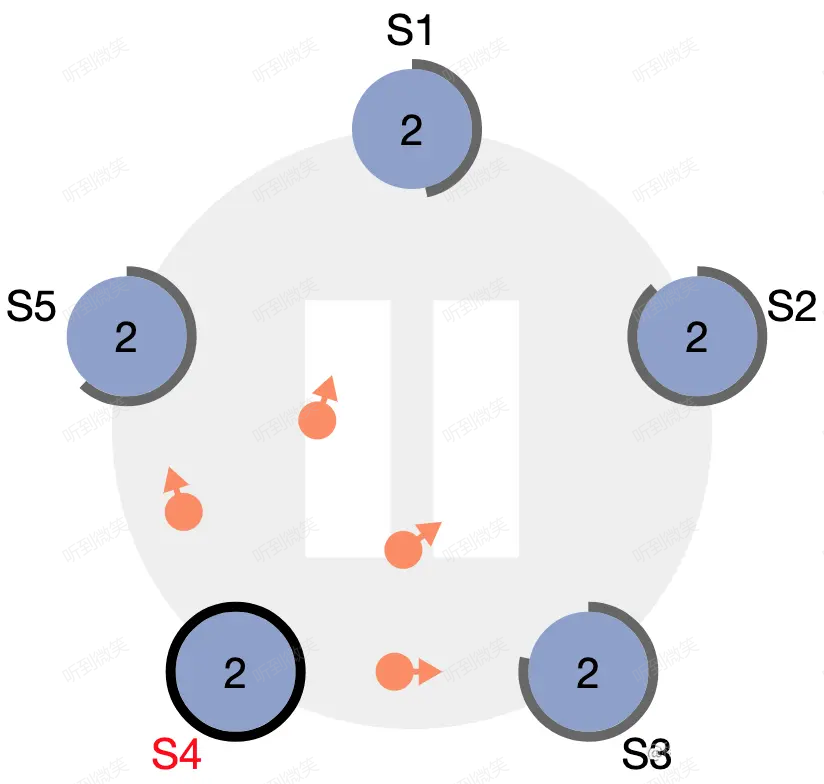
圖:S4 作為 term2 的 leader
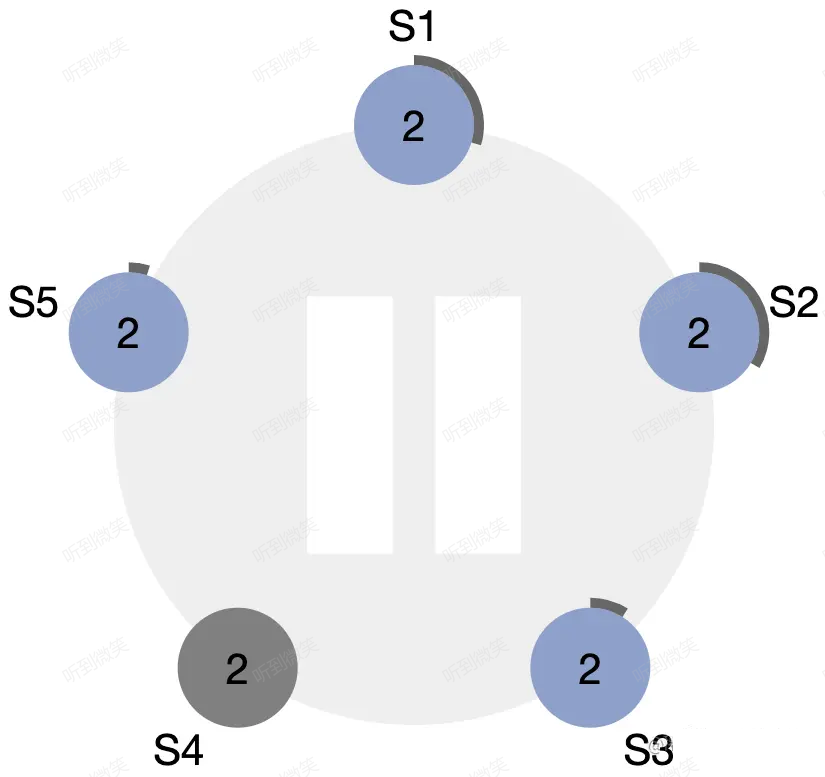
圖:S4 宕機,S5 即將率先超時
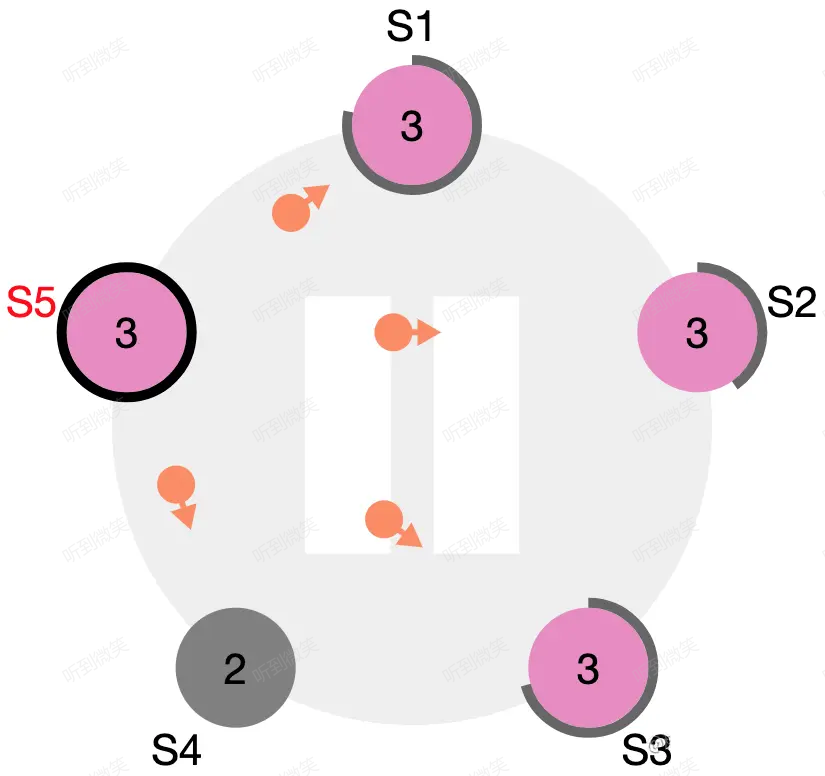
圖:S5 當選 term3 的 leader
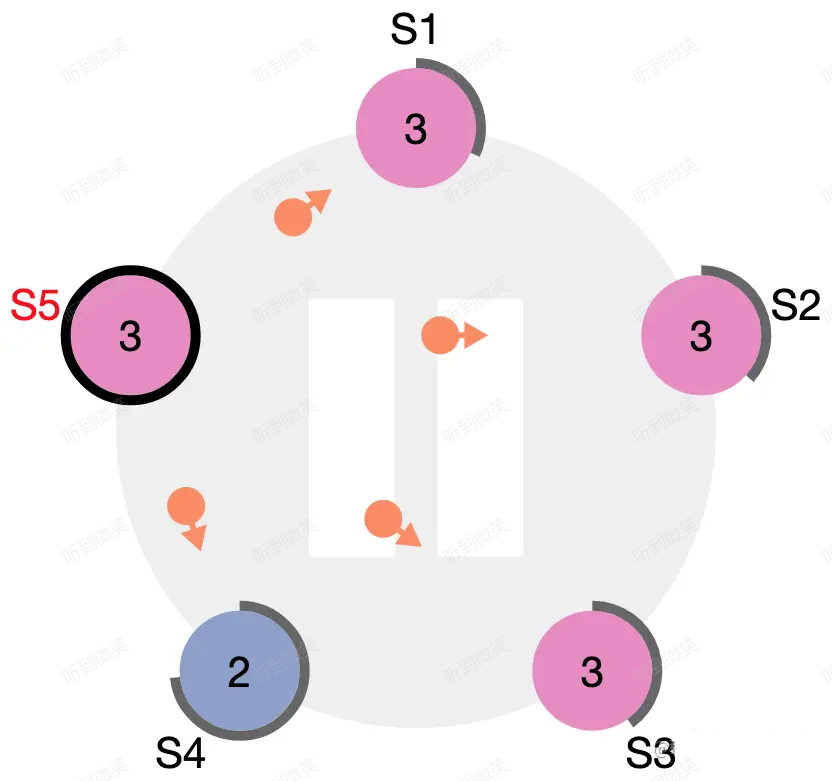
圖:S4 宕機恢復後收到了來自 S5 的 term3 心跳
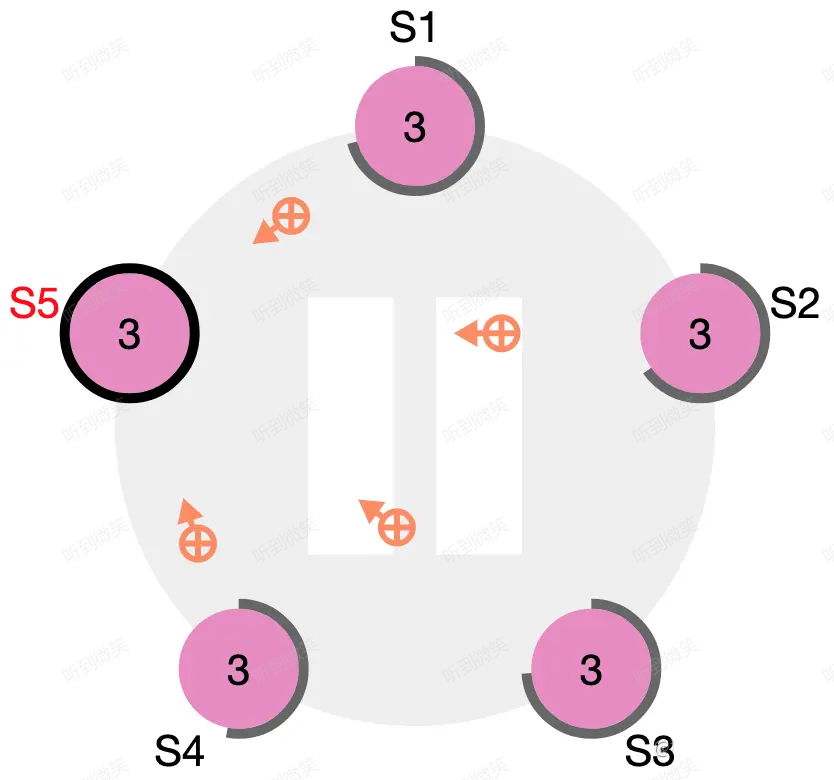
圖:S4 立刻變為 S5 的 follower
以上就是 Raft 的選主邏輯,但還有一些細節(譬如是否給該 candidate 投票還有一些其它條件)依賴演算法的其它部分基礎,我們會在後續“安全性”一章描述。
當票選出 leader 後,leader 也該承擔起相應的責任了,這個責任是什麼?就是下一章將介紹的“日誌複製”。
五. 日誌複製
5.1 什麼是日誌複製
在前文中我們講過:共識演算法通常基於狀態複製機(Replicated State Machine)模型,所有節點從同一個 state 出發,經過一系列同樣操作 log 的步驟,最終也必將達到一致的 state。也就是說,只要我們保證集群中所有節點的 log 一致,那麼經過一系列應用(apply)後最終得到的狀態機也就是一致的。
Raft 負責保證集群中所有節點 log 的一致性。
此外我們還提到過:Raft 賦予了 leader 節點更強的領導力(Strong Leader)。那麼 Raft 保證 log 一致的方式就很容易理解了,即所有 log 都必須交給 leader 節點處理,並由 leader 節點複製給其它節點。
這個過程,就叫做日誌複製(Log replication)。
5.2 Raft 日誌複製機制解析
5.2.1 整體流程解析
一旦 leader 被票選出來,它就承擔起領導整個集群的責任了,開始接收客戶端請求,並將操作包裝成日誌,並複製到其它節點上去。
整體流程如下:
- Leader 為客戶端提供服務,客戶端的每個請求都包含一條即將被狀態複製機執行的指令。
- Leader 把該指令作為一條新的日誌附加到自身的日誌集合,然後向其它節點發起附加條目請求(AppendEntries RPC),來要求它們將這條日誌附加到各自本地的日誌集合。
- 當這條日誌已經確保被安全的複製,即大多數(N/2+1)節點都已經複製後,leader 會將該日誌 apply 到它本地的狀態機中,然後把操作成功的結果返回給客戶端。
整個集群的日誌模型可以巨集觀表示為下圖(x ← 3 代表 x 賦值為 3):
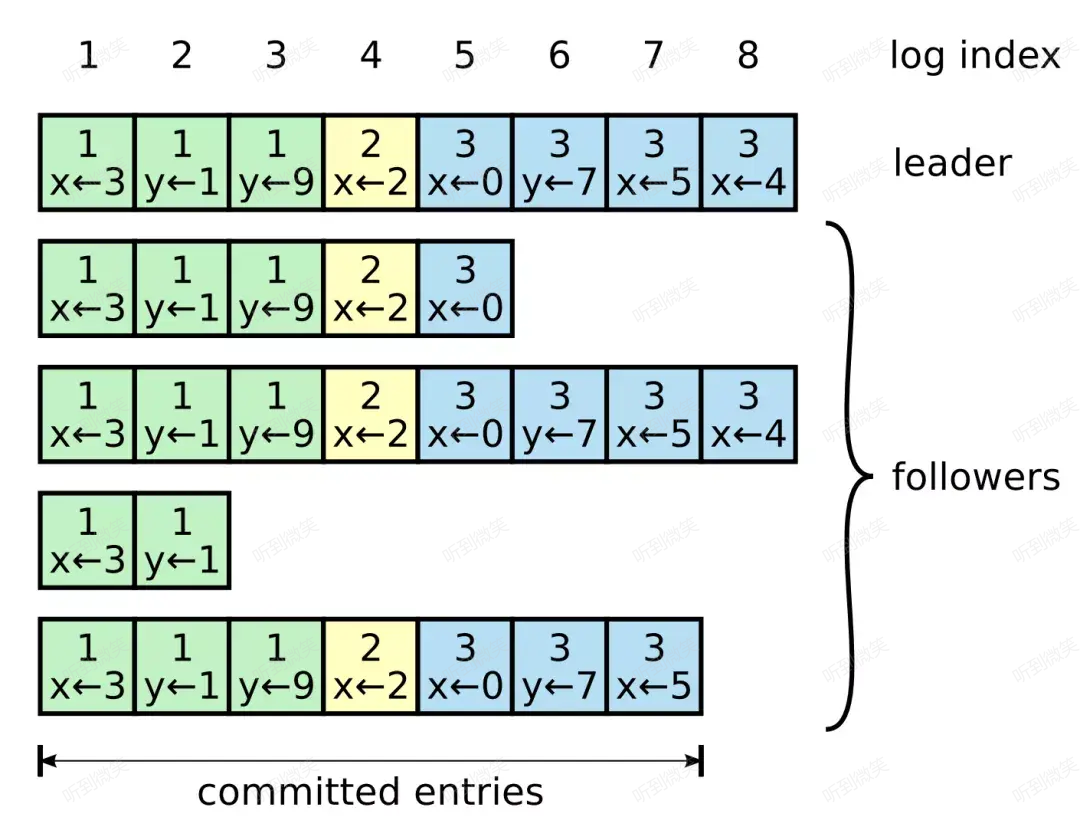
每條日誌除了存儲狀態機的操作指令外,還會擁有一個唯一的整數索引值(log index)來表明它在日誌集合中的位置。此外,每條日誌還會存儲一個 term 號(日誌條目方塊最上方的數字,相同顏色 term 號相同),該 term 表示 leader 收到這條指令時的當前任期,term 相同的 log 是由同一個 leader 在其任期內發送的。
當一條日誌被 leader 節點認為可以安全的 apply 到狀態機時,稱這條日誌是 committed(上圖中的 committed entries)。那麼什麼樣的日誌可以被 commit 呢?答案是:當 leader 得知這條日誌被集群過半的節點複製成功時。因此在上圖中我們可以看到 (term3, index7) 這條日誌以及之前的日誌都是 committed,儘管有兩個節點擁有的日誌並不完整。
Raft 保證所有 committed 日誌都已經被持久化,且“最終”一定會被狀態機apply。
註:這裡的“最終”用詞很微妙,它表明瞭一個特點:Raft 保證的只是集群內日誌的一致性,而我們真正期望的集群對外的狀態機一致性需要我們做一些額外工作,這一點在《線性一致性與讀性能優化》一章會著重介紹。
5.2.2 日誌複製流程圖解
我們通過 Raft 動畫 來模擬常規日誌複製這一過程:
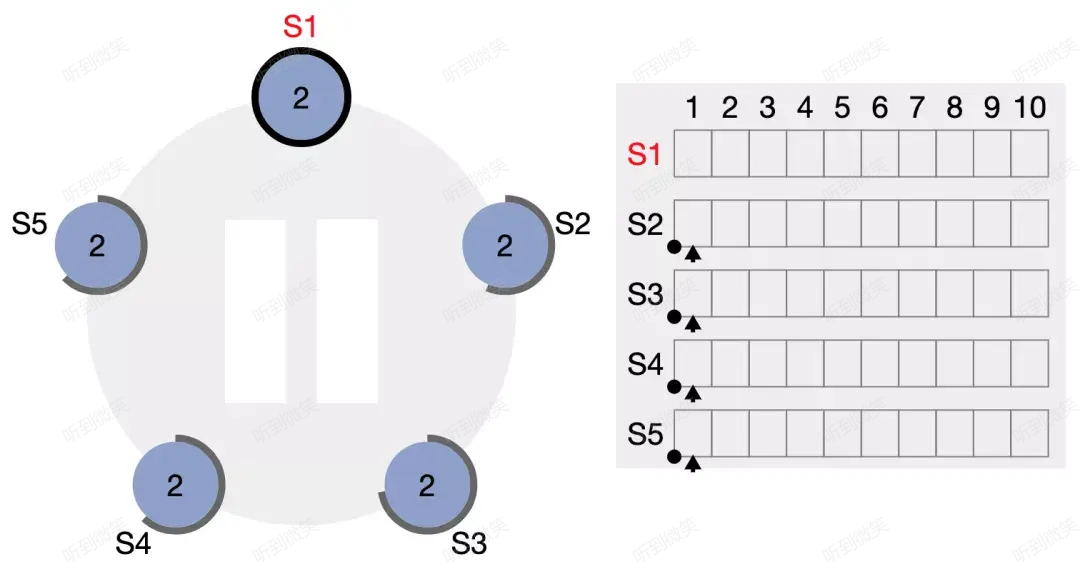
如上圖,S1 當選 leader,此時還沒有任何日誌。我們模擬客戶端向 S1 發起一個請求。
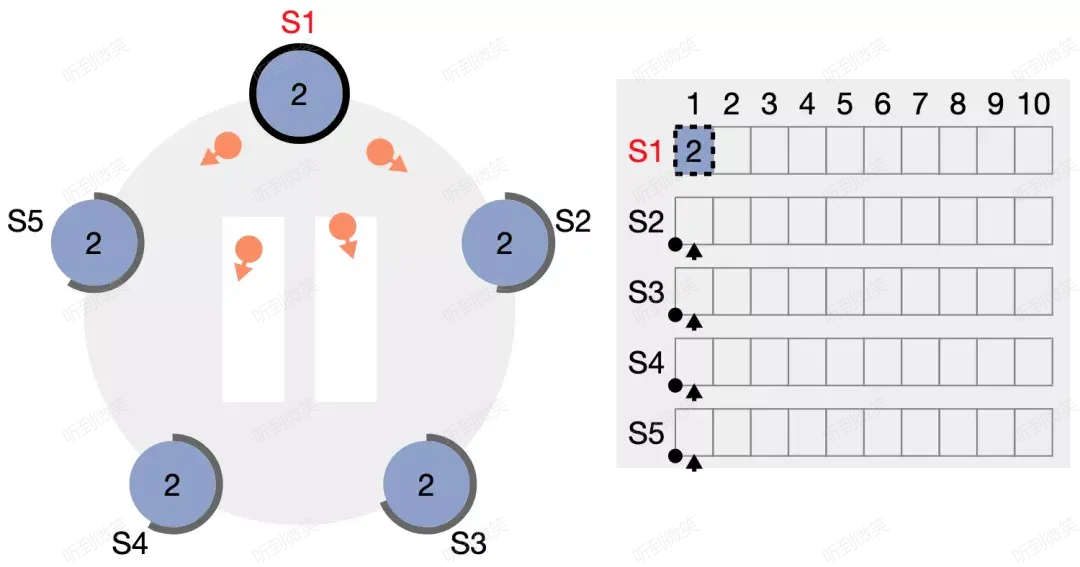
S1 收到客戶端請求後新增了一條日誌 (term2, index1),然後並行地向其它節點發起 AppendEntries RPC。
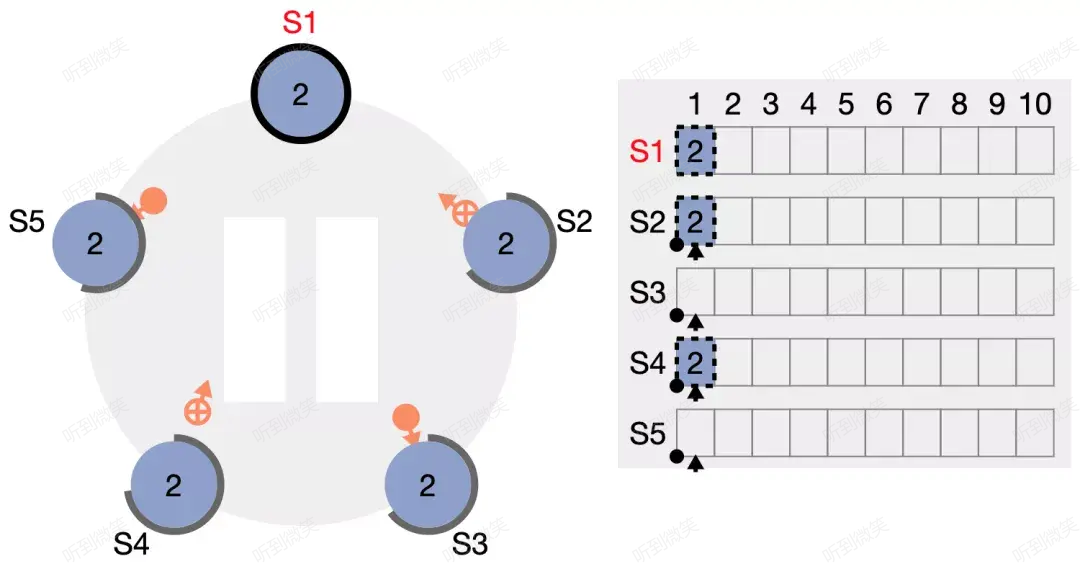
S2、S4 率先收到了請求,各自附加了該日誌,並向 S1 回應響應。
所有節點都附加了該日誌,但由於 leader 尚未收到任何響應,因此暫時還不清楚該日誌到底是否被成功複製。
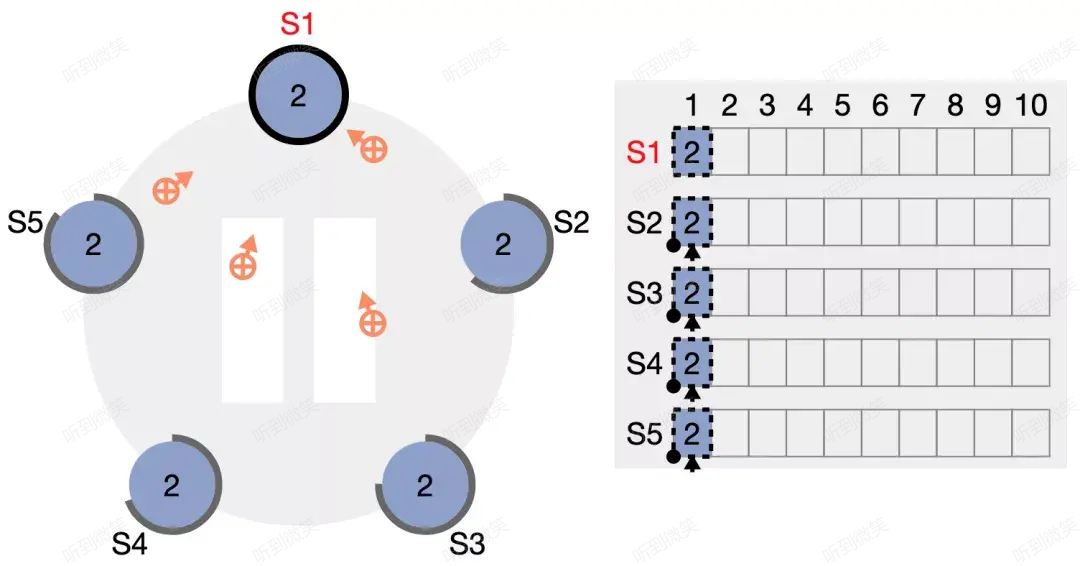
當 S1 收到2個節點的響應時,該日誌條目的邊框就已經變為實線,表示該日誌已經安全的複製,因為在5節點集群中,2個 follower 節點加上 leader 節點自身,副本數已經確保過半,此時 S1 將響應客戶端的請求。
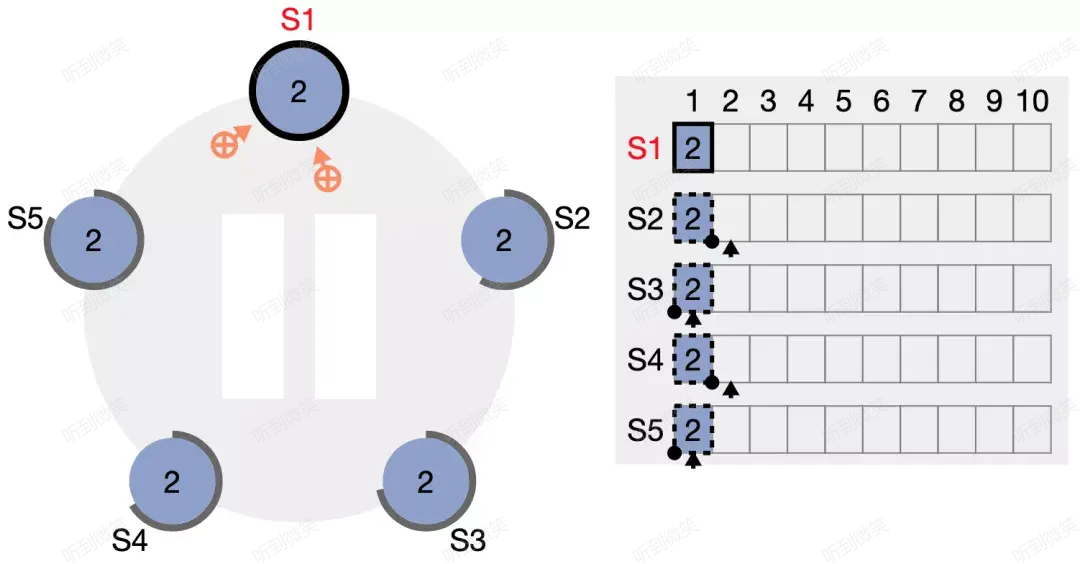
leader 後續會持續發送心跳包給 followers,心跳包中會攜帶當前已經安全複製(我們稱之為 committed)的日誌索引,此處為 (term2, index1)。
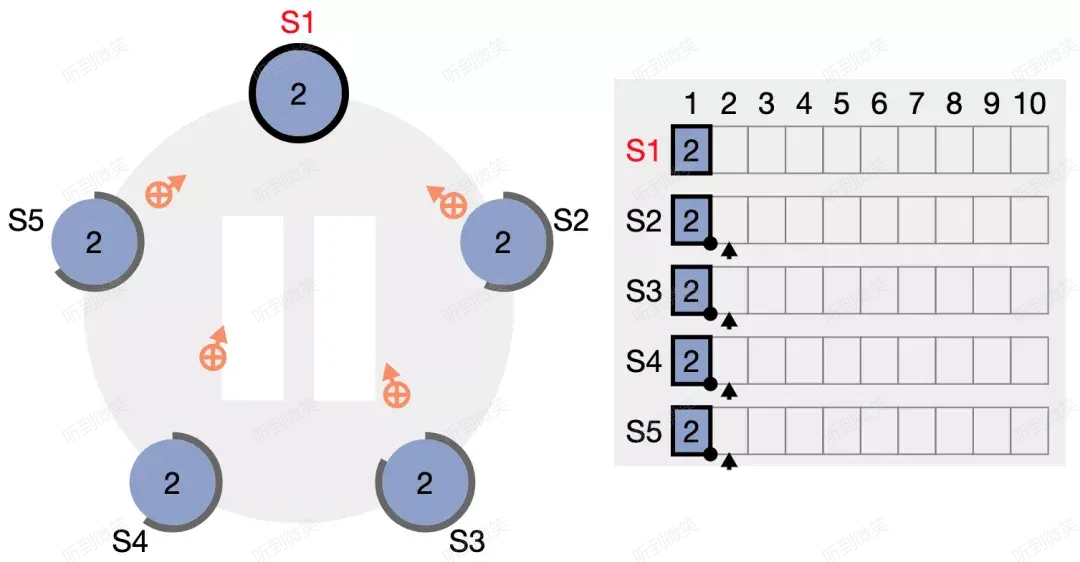
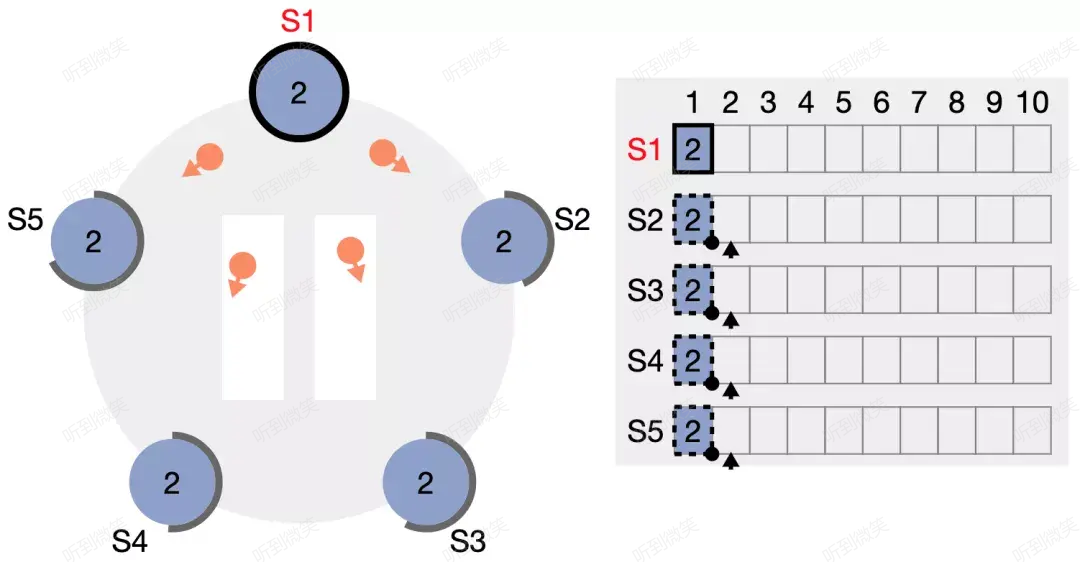
所有 follower 都通過心跳包得知 (term2, index1) 的 log 已經成功複製 (committed),因此所有節點中該日誌條目的邊框均變為實線。
5.2.3 對日誌一致性的保證
前邊我們使用了 (term2, index1) 這種方式來表示一條日誌條目,這裡為什麼要帶上 term,而不僅僅是使用 index?原因是 term 可以用來檢查不同節點間日誌是否存在不一致的情況,閱讀下一節後會更容易理解這句話。
Raft 保證:如果不同的節點日誌集合中的兩個日誌條目擁有相同的 term 和 index,那麼它們一定存儲了相同的指令。
為什麼可以作出這種保證?因為 Raft 要求 leader 在一個 term 內針對同一個 index 只能創建一條日誌,並且永遠不會修改它。
同時 Raft 也保證:如果不同的節點日誌集合中的兩個日誌條目擁有相同的 term 和 index,那麼它們之前的所有日誌條目也全部相同。
這是因為 leader 發出的 AppendEntries RPC 中會額外攜帶上一條日誌的 (term, index),如果 follower 在本地找不到相同的 (term, index) 日誌,則拒絕接收這次新的日誌。
所以,只要 follower 持續正常地接收來自 leader 的日誌,那麼就可以通過歸納法驗證上述結論。
5.2.4 可能出現的日誌不一致場景
在所有節點正常工作的時候,leader 和 follower的日誌總是保持一致,AppendEntries RPC 也永遠不會失敗。然而我們總要面對任意節點隨時可能宕機的風險,如何在這種情況下繼續保持集群日誌的一致性才是我們真正要解決的問題。
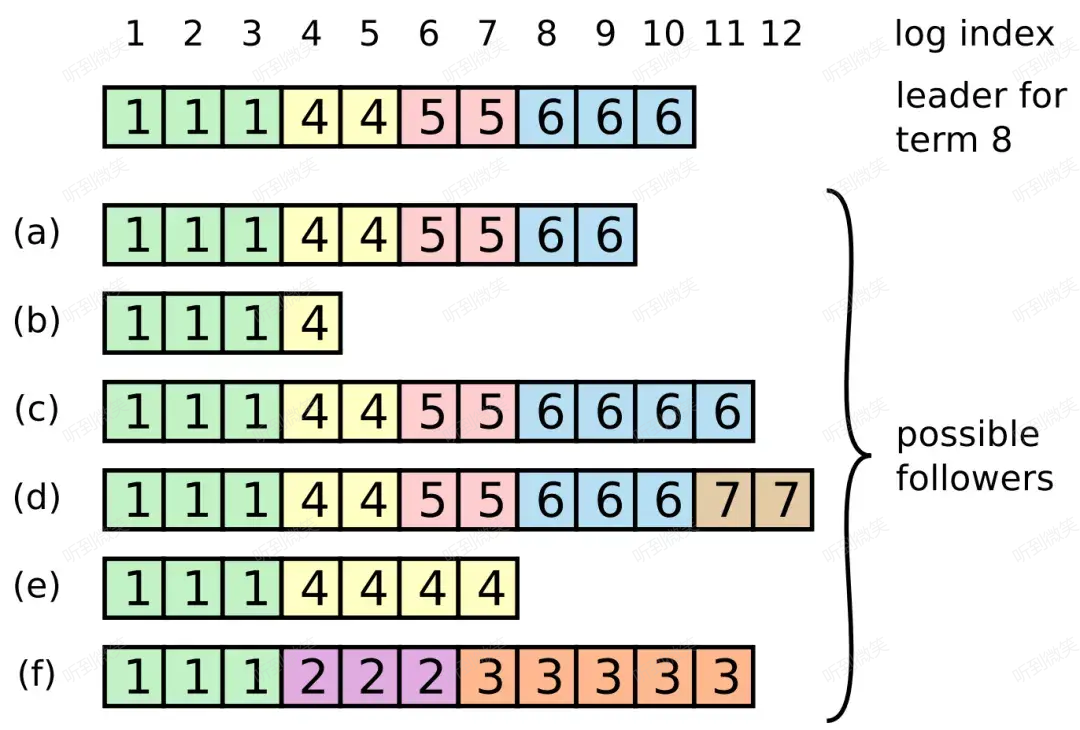
上圖展示了一個 term8 的 leader 剛上任時,集群中日誌可能存在的混亂情況。例如 follower 可能缺少一些日誌(a ~ b),可能多了一些未提交的日誌(c ~ d),也可能既缺少日誌又多了一些未提交日誌(e ~ f)。
註:Follower 不可能比 leader 多出一些已提交(committed)日誌,這一點是通過選舉上的限制來達成的,會在下一章《安全性》介紹。
我們先來嘗試復現上述 a ~ f 場景,最後再講 Raft 如何解決這種不一致問題。
場景a~b. Follower 日誌落後於 leader
這種場景其實很簡單,即 follower 宕機了一段時間,follower-a 從收到 (term6, index9) 後開始宕機,follower-b 從收到 (term4, index4) 後開始宕機。這裡不再贅述。
場景c. Follower 日誌比 leader 多 term6
當 term6 的 leader 正在將 (term6, index11) 向 follower 同步時,該 leader 發生了宕機,且此時只有 follower-c 收到了這條日誌的 AppendEntries RPC。然後經過一系列的選舉,term7 可能是選舉超時,也可能是 leader 剛上任就宕機了,最終 term8 的 leader 上任了,成就了我們看到的場景 c。
場景d. Follower 日誌比 leader 多 term7
當 term6 的 leader 將 (term6, index10) 成功 commit 後,發生了宕機。此時 term7 的 leader 走馬上任,連續同步了兩條日誌給 follower,然而還沒來得及 commit 就宕機了,隨後集群選出了 term8 的 leader。
場景e. Follower 日誌比 leader 少 term5 ~ 6,多 term4
當 term4 的 leader 將 (term4, index7) 同步給 follower,且將 (term4, index5) 及之前的日誌成功 commit 後,發生了宕機,緊接著 follower-e 也發生了宕機。這樣在 term5~7 內發生的日誌同步全都被 follower-e 錯過了。當 follower-e 恢復後,term8 的 leader 也剛好上任了。
場景f. Follower 日誌比 leader 少 term4 ~ 6,多 term2 ~ 3
當 term2 的 leader 同步了一些日誌(index4 ~ 6)給 follower 後,尚未來得及 commit 時發生了宕機,但它很快恢復過來了,又被選為了 term3 的 leader,它繼續同步了一些日誌(index7~11)給 follower,但同樣未來得及 commit 就又發生了宕機,緊接著 follower-f 也發生了宕機,當 follower-f 醒來時,集群已經前進到 term8 了。
5.2.5 如何處理日誌不一致
通過上述場景我們可以看到,真實世界的集群情況很複雜,那麼 Raft 是如何應對這麼多不一致場景的呢?其實方式很簡單暴力,想想 Strong Leader 這個詞。
Raft 強制要求 follower 必須複製 leader 的日誌集合來解決不一致問題。
也就是說,follower 節點上任何與 leader 不一致的日誌,都會被 leader 節點上的日誌所覆蓋。這並不會產生什麼問題,因為某些選舉上的限制,如果 follower 上的日誌與 leader 不一致,那麼該日誌在 follower 上一定是未提交的。未提交的日誌並不會應用到狀態機,也不會被外部的客戶端感知到。
要使得 follower 的日誌集合跟自己保持完全一致,leader 必須先找到二者間最後一次達成一致的地方。因為一旦這條日誌達成一致,在這之前的日誌一定也都一致(回憶下前文)。這個確認操作是在 AppendEntries RPC 的一致性檢查步驟完成的。
Leader 針對每個 follower 都維護一個 next index,表示下一條需要發送給該follower 的日誌索引。當一個 leader 剛剛上任時,它初始化所有 next index 值為自己最後一條日誌的 index+1。但凡某個 follower 的日誌跟 leader 不一致,那麼下次 AppendEntries RPC 的一致性檢查就會失敗。在被 follower 拒絕這次 Append Entries RPC 後,leader 會減少 next index 的值併進行重試。
最終一定會存在一個 next index 使得 leader 和 follower 在這之前的日誌都保持一致。極端情況下 next index 為1,表示 follower 沒有任何日誌與 leader 一致,leader 必須從第一條日誌開始同步。
針對每個 follower,一旦確定了 next index 的值,leader 便開始從該 index 同步日誌,follower 會刪除掉現存的不一致的日誌,保留 leader 最新同步過來的。
整個集群的日誌會在這個簡單的機制下自動趨於一致。此外要註意,leader 從來不會覆蓋或者刪除自己的日誌,而是強制 follower 與它保持一致。
這就要求集群票選出的 leader 一定要具備“日誌的正確性”,這也就關聯到了前文提到的:選舉上的限制。
下一章我們將對此詳細討論。
六. 安全性及正確性
前面的章節我們講述了 Raft 演算法是如何選主和複製日誌的,然而到目前為止我們描述的這套機制還不能保證每個節點的狀態機會嚴格按照相同的順序 apply 日誌。想象以下場景:
- Leader 將一些日誌複製到了大多數節點上,進行 commit 後發生了宕機。
- 某個 follower 並沒有被覆制到這些日誌,但它參與選舉並當選了下一任 leader。
- 新的 leader 又同步並 commit 了一些日誌,這些日誌覆蓋掉了其它節點上的上一任 committed 日誌。
- 各個節點的狀態機可能 apply 了不同的日誌序列,出現了不一致的情況。
因此我們需要對“選主+日誌複製”這套機制加上一些額外的限制,來保證狀態機的安全性,也就是 Raft 演算法的正確性。
6.1 對選舉的限制
我們再來分析下前文所述的 committed 日誌被覆蓋的場景,根本問題其實發生在第2步。Candidate 必須有足夠的資格才能當選集群 leader,否則它就會給集群帶來不可預料的錯誤。Candidate 是否具備這個資格可以在選舉時添加一個小小的條件來判斷,即:
每個 candidate 必須在 RequestVote RPC 中攜帶自己本地日誌的最新 (term, index),如果 follower 發現這個 candidate 的日誌還沒有自己的新,則拒絕投票給該 candidate。
Candidate 想要贏得選舉成為 leader,必須得到集群大多數節點的投票,那麼它的日誌就一定至少不落後於大多數節點。又因為一條日誌只有複製到了大多數節點才能被 commit,因此能贏得選舉的 candidate 一定擁有所有 committed 日誌。
因此前一篇文章我們才會斷定地說:Follower 不可能比 leader 多出一些 committed 日誌。
比較兩個 (term, index) 的邏輯非常簡單:如果 term 不同 term 更大的日誌更新,否則 index 大的日誌更新。
6.2 對提交的限制
除了對選舉增加一點限制外,我們還需對 commit 行為增加一點限制,來完成我們 Raft 演算法核心部分的最後一塊拼圖。
回憶下什麼是 commit:
當 leader 得知某條日誌被集群過半的節點複製成功時,就可以進行 commit,committed 日誌一定最終會被狀態機 apply。
所謂 commit 其實就是對日誌簡單進行一個標記,表明其可以被 apply 到狀態機,並針對相應的客戶端請求進行響應。
然而 leader 並不能在任何時候都隨意 commit 舊任期留下的日誌,即使它已經被覆制到了大多數節點。Raft 論文給出了一個經典場景:
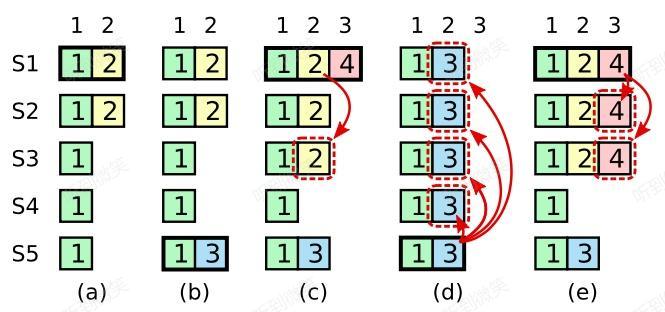
上圖從左到右按時間順序模擬了問題場景。
階段a:S1 是 leader,收到請求後將 (term2, index2) 只複製給了 S2,尚未複製給 S3 ~ S5。
階段b:S1 宕機,S5 當選 term3 的 leader(S3、S4、S5 三票),收到請求後保存了 (term3, index2),尚未複製給任何節點。
階段c:S5 宕機,S1 恢復,S1 重新當選 term4 的 leader,繼續將 (term2, index2) 複製給了 S3,已經滿足大多數節點,我們將其 commit。
階段d:S1 又宕機,S5 恢復,S5 重新當選 leader(S2、S3、S4 三票),將 (term3, inde2) 複製給了所有節點並 commit。註意,此時發生了致命錯誤,已經 committed 的 (term2, index2) 被 (term3, index2) 覆蓋了。
為了避免這種錯誤,我們需要添加一個額外的限制:
Leader 只允許 commit 包含當前 term 的日誌。
Raft論文:Raft 永遠不會通過計算副本數目的方式去提交一個之前任期內的日誌條目。只有領導人當前任期里的日誌條目通過計算副本數目可以被提交;一旦當前任期的日誌條目以這種方式被提交,那麼由於日誌匹配特性,之前的日誌條目也都會被間接的提交。在某些情況下,領導人可以安全的知道一個老的日誌條目是否已經被提交(例如,該條目是否存儲到所有伺服器上),但是 Raft 為了簡化問題使用一種更加保守的方法。
針對上述場景,問題發生在階段c,即使作為 term4 leader 的 S1 將 (term2, index2) 複製給了大多數節點,它也不能直接將其 commit,而是必須等待 term4 的日誌到來併成功複製後,一併進行 commit。
階段e:在添加了這個限制後,要麼 (term2, index2) 始終沒有被 commit,這樣 S5 在階段d將其覆蓋就是安全的;要麼 (term2, index2) 同 (term4, index3) 一起被 commit,這樣 S5 根本就無法當選 leader,因為大多數節點的日誌都比它新,也就不存在前邊的問題了。
以上便是對演算法增加的兩個小限制,它們對確保狀態機的安全性起到了至關重要的作用。
至此我們對 Raft 演算法的核心部分,已經介紹完畢。下一章我們會介紹兩個同樣描述於論文內的輔助技術:集群成員變更和日誌壓縮,它們都是在 Raft 工程實踐中必不可少的部分。
七. 集群成員變更與日誌壓縮
儘管我們已經通過前幾章瞭解了 Raft 演算法的核心部分,但相較於演算法理論來說,在工程實踐中仍有一些現實問題需要我們去面對。Raft 非常貼心的在論文中給出了兩個常見問題的解決方案,它們分別是:
- 集群成員變更:如何安全地改變集群的節點成員。
- 日誌壓縮:如何解決日誌集合無限制增長帶來的問題。
本文我們將分別講解這兩種技術。
7.1 集群成員變更
在前文的理論描述中我們都假設了集群成員是不變的,然而在實踐中有時會需要替換宕機機器或者改變複製級別(即增減節點)。一種最簡單暴力達成目的的方式就是:停止集群、改變成員、啟動集群。這種方式在執行時會導致集群整體不可用,此外還存在手工操作帶來的風險。
為了避免這樣的問題,Raft 論文中給出了一種無需停機的、自動化的改變集群成員的方式,其實本質上還是利用了 Raft 的核心演算法,將集群成員配置作為一個特殊日誌從 leader 節點同步到其它節點去。
7.1.1 直接切換集群成員配置
先說結論:所有將集群從舊配置直接完全切換到新配置的方案都是不安全的。
因此我們不能想當然的將新配置直接作為日誌同步給集群並 apply。因為我們不可能讓集群中的全部節點在“同一時刻”原子地切換其集群成員配置,所以在切換期間不同的節點看到的集群視圖可能存在不同,最終可能導致集群存在多個 leader。
為了理解上述結論,我們來看一個實際出現問題的場景,下圖對其進行了展現。
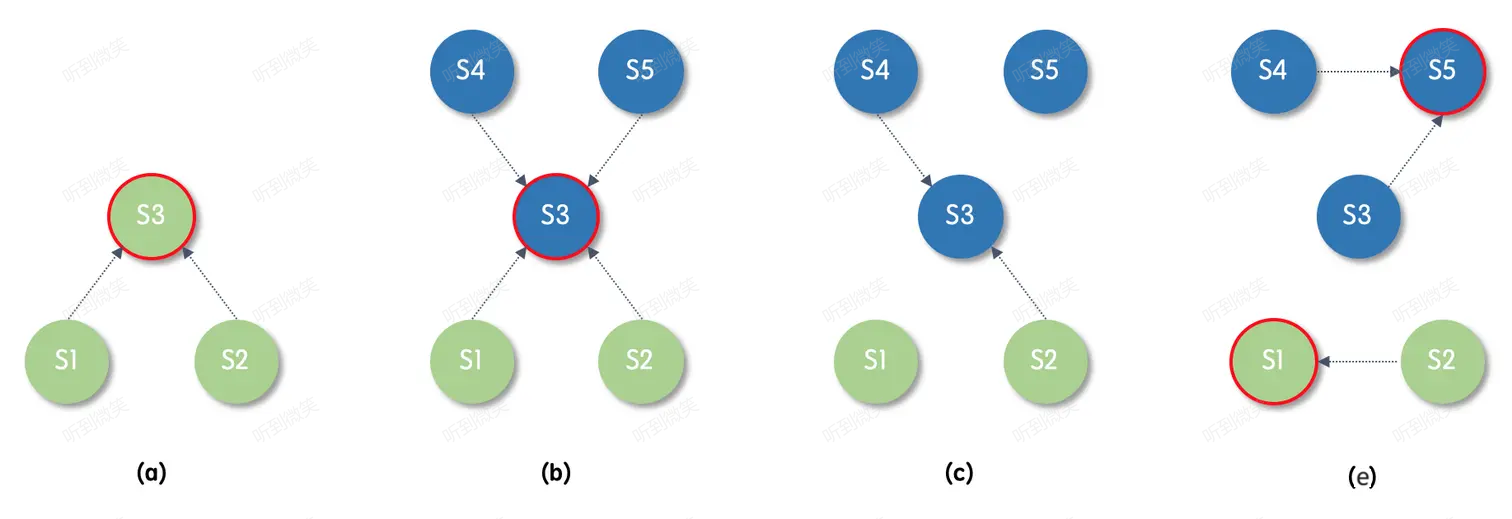
圖 7-1
階段a. 集群存在 S1 ~ S3 三個節點,我們將該成員配置表示為 C-old,綠色表示該節點當前視圖(成員配置)為 C-old,其中紅邊的 S3 為 leader。
階段b. 集群新增了 S4、S5 兩個節點,該變更從 leader 寫入,我們將 S1 ~ S5 的五節點新成員配置表示為 C-new,藍色表示該節點當前視圖為 C-new。
階段c. 假設 S3 短暫宕機觸發了 S1 與 S5 的超時選主。
階段d. S1 向 S2、S3 拉票,S5 向其它全部四個節點拉票。由於 S2 的日誌並沒有比 S1 更新,因此 S2 可能會將選票投給 S1,S1 兩票當選(因為 S1 認為集群只有三個節點)。而 S5 肯定會得到 S3、S4 的選票,因為 S1 感知不到 S4,沒有向它發送 RequestVote RPC,並且 S1 的日誌落後於 S3,S3 也一定不會投給 S1,結果 S5 三票當選。最終集群出現了多個主節點的致命錯誤,也就是所謂的腦裂。
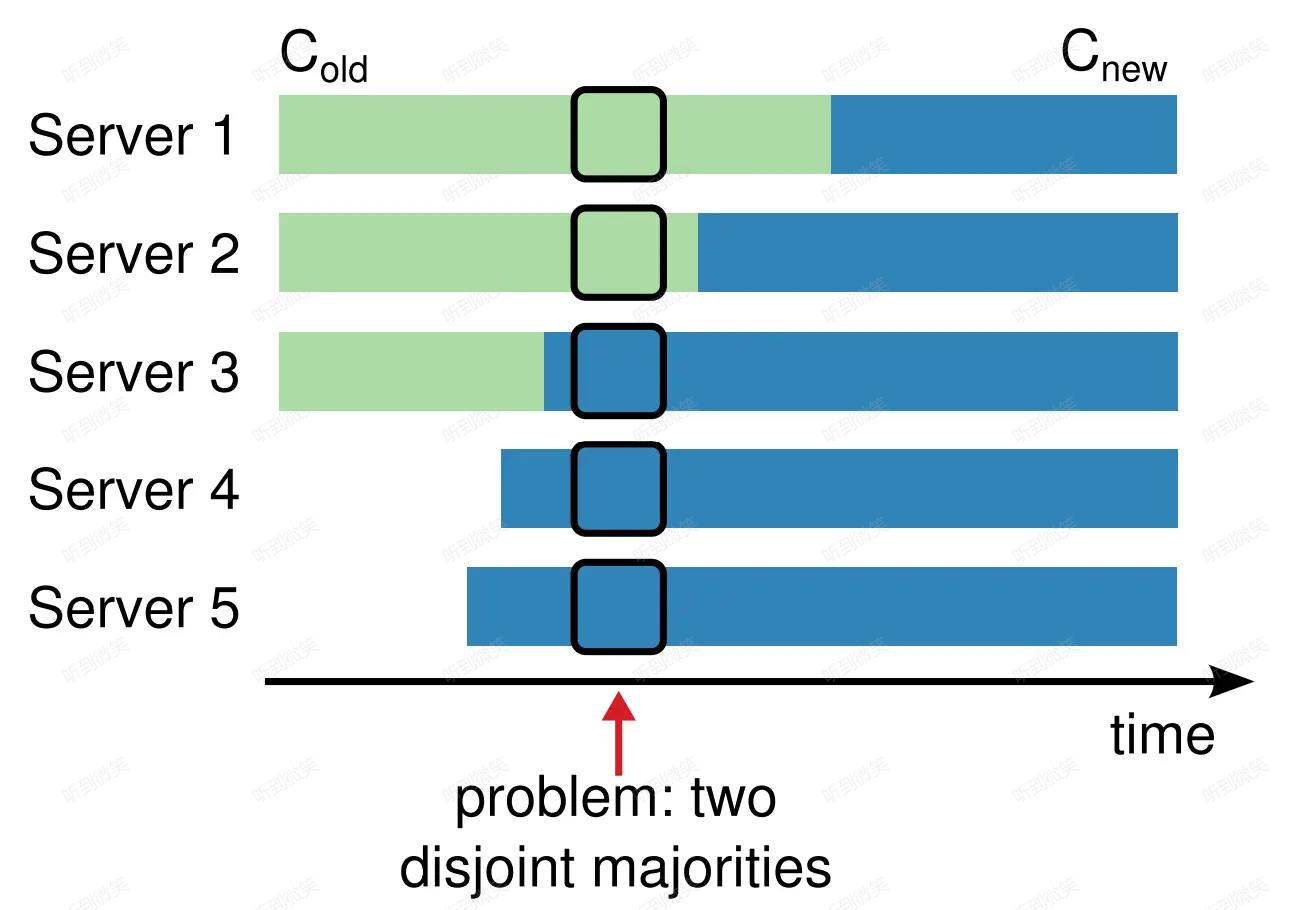
圖7-2
上圖來自論文,用不同的形式展現了和圖7-1相同的問題。顏色代表的含義與圖7-1是一致的,在 problem: two disjoint majorities 所指的時間點,集群可能會出現兩個 leader。
但是,多主問題並不是在任何新老節點同時選舉時都一定可能出現的,社區一些文章在舉多主的例子時可能存在錯誤,下麵是一個案例(筆者學習 Raft 協議也從這篇文章中受益匪淺,應該是作者行文時忽略了。文章很贊,建議大家參考學習):
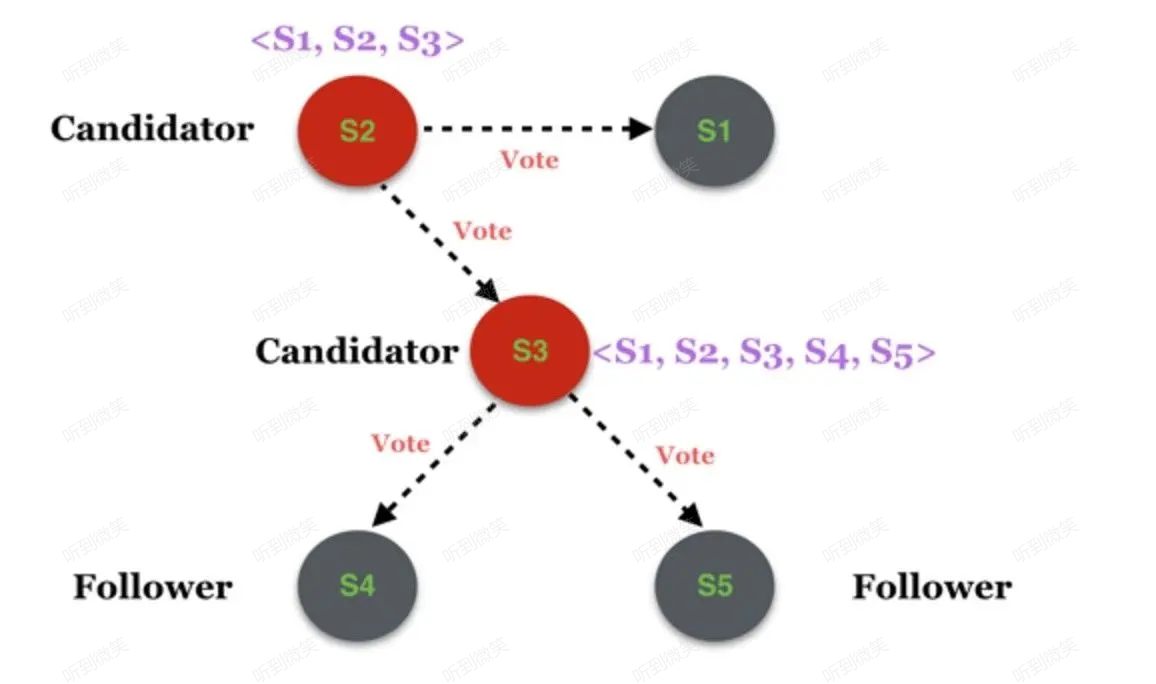
圖7-3
該假想場景類似圖7-1的階段d,模擬過程如下:
- S1 為集群原 leader,集群新增 S4、S5,該配置被推給了 S3,S2 尚未收到。
- 此時 S1 發生短暫宕機,S2、S3 分別觸發選主。
- 最終 S2 獲得了 S1 和自己的選票,S3 獲得了 S4、S5 和自己的選票,集群出現兩個 leader。
圖7-3過程看起來好像和圖7-1沒有什麼大的不同,只是參與選主的節點存在區別,然而事實是圖7-3的情況是不可能出現的。
註意:Raft 論文中傳遞集群變更信息也是通過日誌追加實現的,所以也受到選主的限制。很多讀者對選主限制中比較的日誌是否必須是 committed 產生疑惑,回看下在《安全性》一文中的描述:
每個 candidate 必須在 RequestVote RPC 中攜帶自己本地日誌的最新 (term, index),如果 follower 發現這個 candidate 的日誌還沒有自己的新,則拒絕投票給該 candidate。
這裡再幫大家明確下,論文里確實間接表明瞭,選主時比較的日誌是不要求 committed 的,只需比較本地的最新日誌就行!
回到圖7-3,不可能出現的原因在於,S1 作為原 leader 已經第一個保存了新配置的日誌,而 S2 尚未被同步這條日誌,根據上一章《安全性》我們講到的選主限制,S1 不可能將選票投給 S2,因此 S2 不可能成為 leader。
7.1.2 兩階段切換集群成員配置
Raft 使用一種兩階段方法平滑切換集群成員配置來避免遇到前一節描述的問題,具體流程如下:
階段一
- 客戶端將 C-new 發送給 leader,leader 將 C-old 與 C-new 取並集並立即apply,我們表示為 C-old,new。
- Leader 將 C-old,new 包裝為日誌同步給其它節點。
- Follower 收到 C-old,new 後立即 apply,當 C-old,new 的大多數節點(即 C-old 的大多數節點和 C-new 的大多數節點)都切換後,leader 將該日誌 commit。
階段二
- Leader 接著將 C-new 包裝為日誌同步給其它節點。
- Follower 收到 C-new 後立即 apply,如果此時發現自己不在 C-new 列表,則主動退出集群。
- Leader 確認 C-new 的大多數節點都切換成功後,給客戶端發送執行成功的響應。
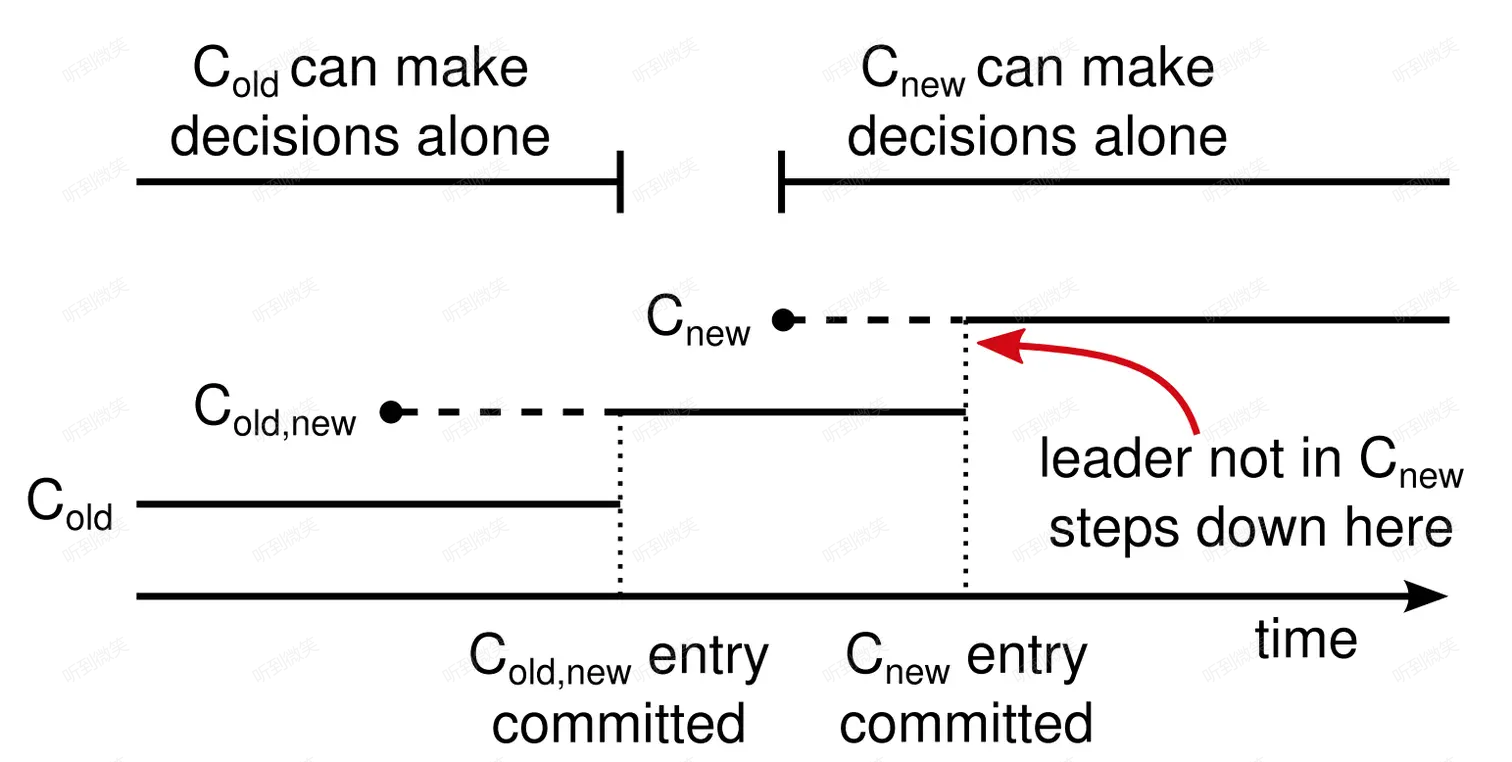
上圖展示了該流程的時間線。虛線表示已經創建但尚未 commit 的成員配置日誌,實線表示 committed 的成員配置日誌。
為什麼該方案可以保證不會出現多個 leader?我們來按流程逐階段分析。
階段1. C-old,new 尚未 commit
該階段所有節點的配置要麼是 C-old,要麼是 C-old,new,但無論是二者哪種,只要原 leader 發生宕機,新 leader 都必須得到大多數 C-old 集合內節點的投票。
以圖5-1場景為例,S5 在階段d根本沒有機會成為 leader,因為 C-old 中只有 S3 給它投票了,不滿足大多數。
階段2. C-old,new 已經 commit,C-new 尚未下發
該階段 C-old,new 已經 commit,可以確保已經被 C-old,new 的大多數節點(再次強調:C-old 的大多數節點和 C-new 的大多數節點)複製。
因此當 leader 宕機時,新選出的 leader 一定是已經擁有 C-old,new 的節點,不可能出現兩個 leader。
階段3. C-new 已經下發但尚未 commit
該階段集群中可能有三種節點 C-old、C-old,new、C-new,但由於已經經歷了階段2,因此 C-old 節點不可能再成為 leader。而無論是 C-old,new 還是 C-new 節點發起選舉,都需要經過大多數 C-new 節點的同意,因此也不可能出現兩個 leader。
階段4. C-new 已經 commit
該階段 C-new 已經被 commit,因此只有 C-new 節點可以得到大多數選票成為 leader。此時集群已經安全地完成了這輪變更,可以繼續開啟下一輪變更了。
以上便是對該兩階段方法可行性的分步驗證,Raft 論文將該方法稱之為共同一致(Joint Consensus)。
關於集群成員變更另一篇更詳細的論文還給出了其它方法,簡單來說就是論證一次只變更一個節點的的正確性,並給出解決可用性問題的優化方案。感興趣的同學可以參考:《Consensus: Bridging Theory and Practice》。
7.2 日誌壓縮
我們知道 Raft 核心演算法維護了日誌的一致性,通過 apply 日誌我們也就得到了一致的狀態機,客戶端的操作命令會被包裝成日誌交給 Raft 處理。然而在實際系統中,客戶端操作是連綿不斷的,但日誌卻不能無限增長,首先它會占用很高的存儲空間,其次每次系統重啟時都需要完整回放一遍所有日誌才能得到最新的狀態機。
因此 Raft 提供了一種機制去清除日誌里積累的陳舊信息,叫做日誌壓縮。
快照(Snapshot)是一種常用的、簡單的日誌壓縮方式,ZooKeeper、Chubby 等系統都在用。簡單來說,就是將某一時刻系統的狀態 dump 下來並落地存儲,這樣該時刻之前的所有日誌就都可以丟棄了。所以大家對“壓縮”一詞不要產生錯誤理解,我們並沒有辦法將狀態機快照“解壓縮”回日誌序列。
註意,在 Raft 中我們只能為 committed 日誌做 snapshot,因為只有 committed 日誌才是確保最終會應用到狀態機的。
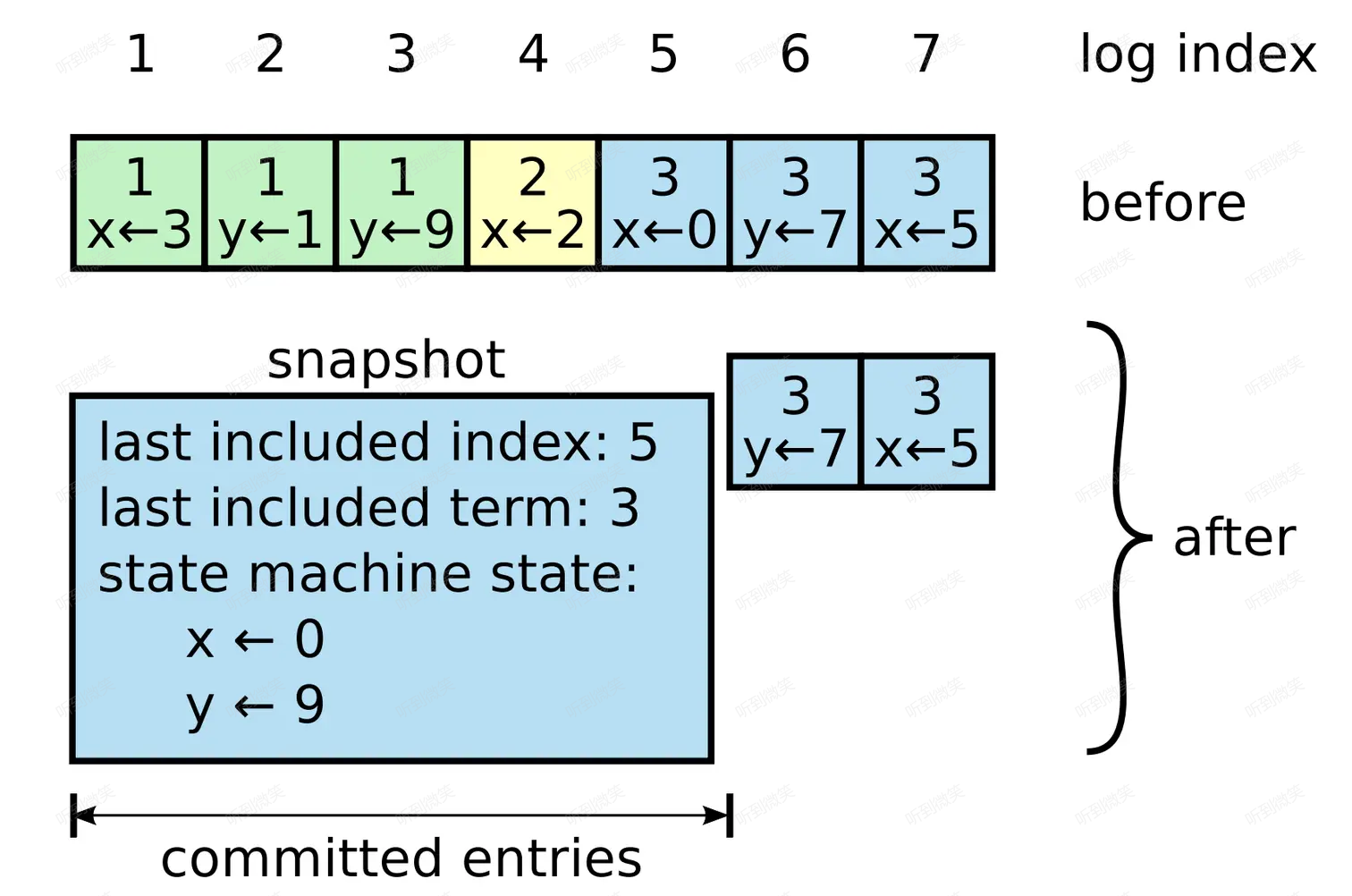
上圖展示了一個節點用快照替換了 (term1, index1) ~ (term3, index5) 的日誌。
快照一般包含以下內容:
- 日誌的元數據:最後一條被該快照 apply 的日誌 term 及 index
- 狀態機:前邊全部日誌 apply 後最終得到的狀態機
當 leader 需要給某個 follower 同步一些舊日誌,但這些日誌已經被 leader 做了快照並刪除掉了時,leader 就需要把該快照發送給 follower。
同樣,當集群中有新節點加入,或者某個節點宕機太久落後了太多日誌時,leader 也可以直接發送快照,大量節約日誌傳輸和回放時間。
同步快照使用一個新的 RPC 方法,叫做 InstallSnapshot RPC。
至此我們已經將 Raft 論文中的內容基本講解完畢了。《In Search of an Understandable Consensus Algorithm (Extended Version)》 畢竟只有18頁,更加側重於理論描述而非工程實踐。如果你想深入學習 Raft,或自己動手寫一個靠譜的 Raft 實現,《Consensus: Bridging Theory and Practice》 是你參考的不二之選。
接下來我們將額外討論一下關於線性一致性和 Raft 讀性能優化的內容。
八. 線性一致性與讀性能優化
8.1 什麼是線性一致性?
在該系列首篇《基本概念》中我們提到過:在分散式系統中,為了消除單點提高系統可用性,通常會使用副本來進行容錯,但這會帶來另一個問題,即如何保證多個副本之間的一致性。
什麼是一致性?所謂一致性有很多種模型,不同的模型都是用來評判一個併發系統正確與否的不同程度的標準。而我們今天要討論的是強一致性(Strong Consistency)模型,也就是線性一致性(Linearizability),我們經常聽到的 CAP 理論中的 C 指的就是它。
其實我們在第一篇就已經簡要描述過何為線性一致性:
所謂的強一致性(線性一致性)並不是指集群中所有節點在任一時刻的狀態必須完全一致,而是指一個目標,即讓一個分散式系統看起來只有一個數據副本,並且讀寫操作都是原子的,這樣應用層就可以忽略系統底層多個數據副本間的同步問題。也就是說,我們可以將一個強一致性分散式系統當成一個整體,一旦某個客戶端成功的執行了寫操作,那麼所有客戶端都一定能讀出剛剛寫入的值。即使發生網路分區故障,或者少部分節點發生異常,整個集群依然能夠像單機一樣提供服務。
“像單機一樣提供服務”從感官上描述了一個線性一致性系統應該具備的特性,那麼我們該如何判斷一個系統是否具備線性一致性呢?通俗來說就是不能讀到舊(stale)數據,但具體分為兩種情況:
- 對於調用時間存在重疊(併發)的請求,生效順序可以任意確定。
- 對於調用時間存在先後關係(偏序)的請求,後一個請求不能違背前一個請求確定的結果。
只要根據上述兩條規則即可判斷一個系統是否具備線性一致性。下麵我們來看一個非線性一致性系統的例子。
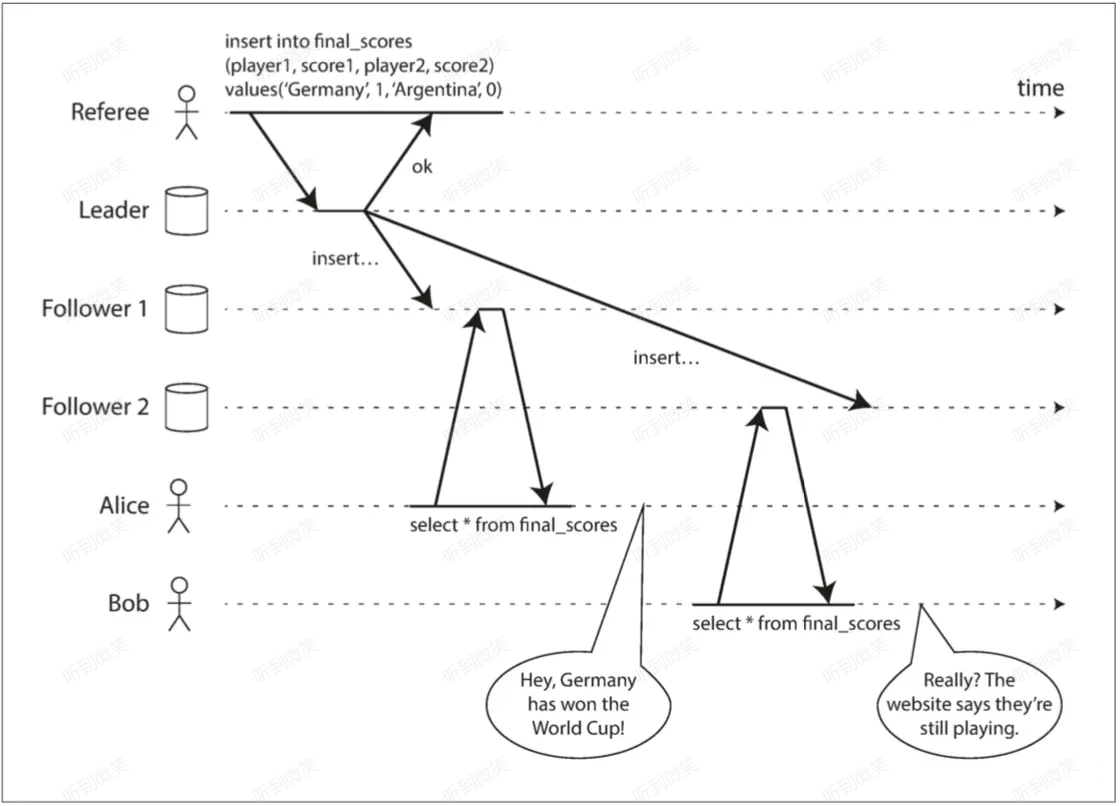
本節例圖均來自《Designing Data-Intensive Application》,作者 Martin Kleppmann
如上圖所示,裁判將世界盃的比賽結果寫入了主庫,Alice 和 Bob 所瀏覽的頁面分別從兩個不同的從庫讀取,但由於存在主從同步延遲,Follower 2 的本次同步延遲高於 Follower 1,最終導致 Bob 聽到了 Alice 的驚呼後刷新頁面看到的仍然是比賽進行中。
雖然線性一致性的基本思想很簡單,只是要求分散式系統看起來只有一個數據副本,但在實際中還是有很多需要關註的點,我們繼續看幾個例子。
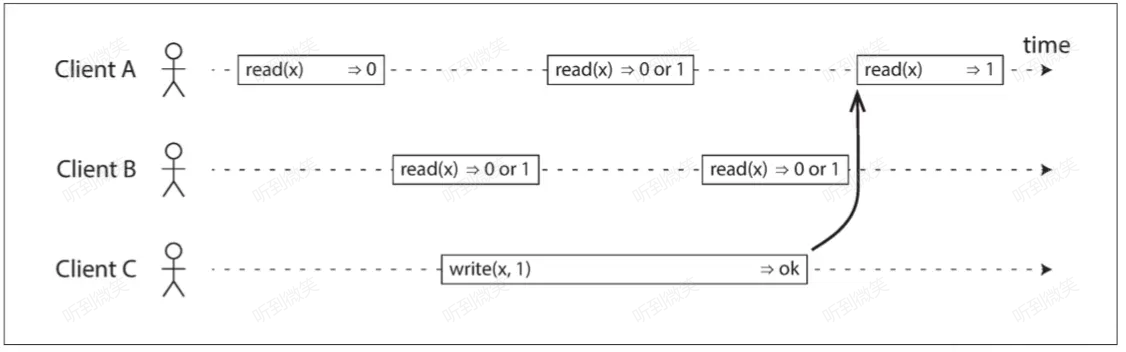
上圖從客戶端的外部視角展示了多個用戶同時請求讀寫一個系統的場景,每條柱形都是用戶發起的一個請求,左端是請求發起的時刻,右端是收到響應的時刻。由於網路延遲和系統處理時間並不固定,所以柱形長度並不相同。
x最初的值為0,Client C 在某個時間段將x寫為1。- Client A 第一個讀操作位於 Client C 的寫操作之前,因此必須讀到原始值
0。 - Client A 最後一個讀操作位於 Client C 的寫操作之後,如果系統是線性一致的,那麼必須讀到新值
1。 - 其它與寫操作重疊的所有讀操作,既可能返回
0,也可能返回1,因為我們並不清楚寫操作在哪個時間段內哪個精確的點生效,這種情況下讀寫是併發的。
僅僅是這樣的話,仍然不能說這個系統滿足線性一致。假設 Client B 的第一次讀取返回了 1,如果 Client A 的第二次讀取返回了 0,那麼這種場景並不破壞上述規則,但這個系統仍不滿足線性一致,因為客戶端在寫操作執行期間看到 x 的值在新舊之間來回翻轉,這並不符合我們期望的“看起來只有一個數據副本”的要求。
所以我們需要額外添加一個約束,如下圖所示:
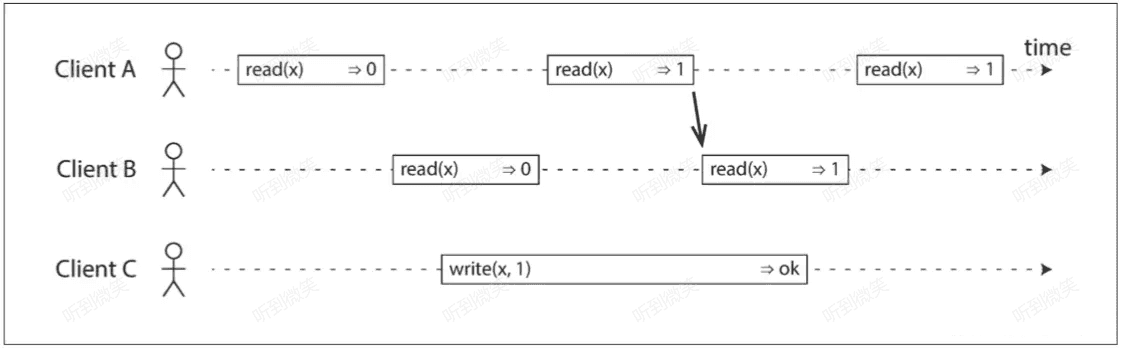
在任何一個客戶端的讀取返回新值後,所有客戶端的後續讀取也必須返回新值,這樣系統便滿足線性一致了。
我們最後來看一個更複雜的例子,繼續細化這個時序圖。
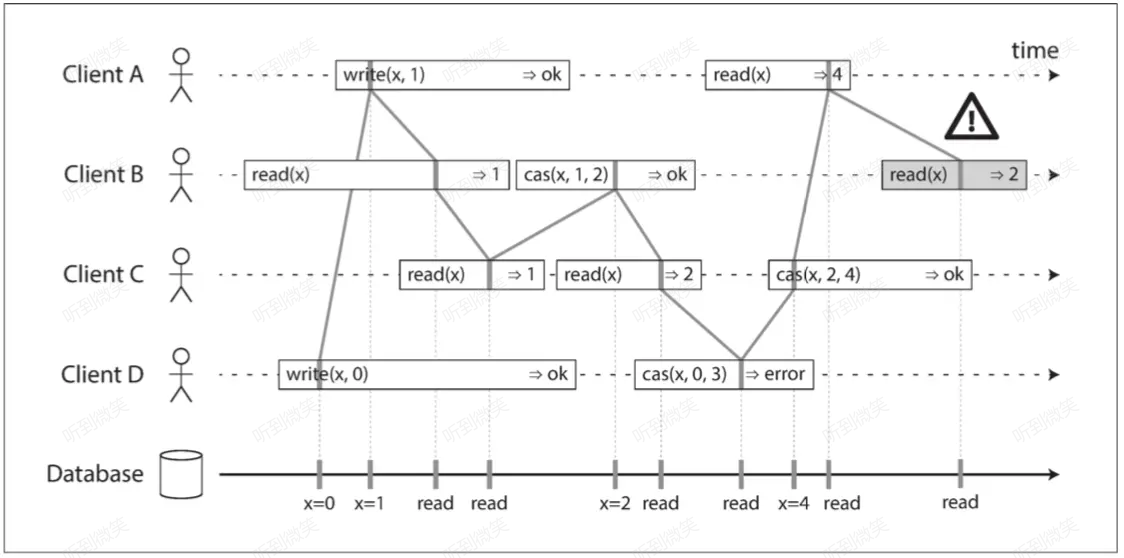
如上圖所示,每個讀寫操作在某個特定的時間點都是原子性的生效,我們在柱形中用豎線標記出生效的時間點,將這些標記按時間順序連接起來。那麼線性一致的要求就是:連線總是按照時間順序向右移動,而不會向左回退。所以這個連線結果必定是一個有效的寄存器讀寫序列:任何客戶端的每次讀取都必須返回該條目最近一次寫入的值。
線性一致性並非限定在分散式環境下,在單機單核系統中可以簡單理解為“寄存器”的特性。
Client B 的最後一次讀操作並不滿足線性一致,因為在連線向右移動的前提下,它讀到的值是錯誤的(因為Client A 已經讀到了由 Client C 寫入的 4)。此外這張圖裡還有一些值得指出的細節點,可以解開很多我們在使用線性一致系統時容易產生的誤解:
- Client B 的首個讀請求在 Client D 的首個寫請求和 Client A 的首個寫請求之前發起,但最終讀到的卻是最後由 Client A 寫成功之後的結果。
- Client A 尚未收到首個寫請求成功的響應時,Client B 就讀到了 Client A 寫入的值。
上述現象線上性一致的語義下都是合理的。
所以線性一致性(Linearizability)除了叫強一致性(Strong Consistency)外,還叫做原子一致性(Atomic Consistency)、立即一致性(Immediate Consistency)或外部一致性(External Consistency),這些名字看起來都是比較貼切的。
8.2 Raft 線性一致性讀
在瞭解了什麼是線性一致性之後,我們將其與 Raft 結合來探討。首先需要明確一個問題,使用了 Raft 的系統都是線性一致的嗎?不是的,Raft 只是提供了一個基礎,要實現整個系統的線性一致還需要做一些額外的工作。
假設我們期望基於 Raft 實現一個線性一致的分散式 kv 系統,讓我們從最朴素的方案開始,指出每種方案存在的問題,最終使整個系統滿足線性一致性。
8.2.1 寫主讀從缺陷分析
寫操作並不是我們關註的重點,如果你稍微看了一些理論部分就應該知道,所有寫操作都要作為提案從 leader 節點發起,當然所有的寫命令都應該簡單交給 leader 處理。真正關鍵的點在於讀操作的處理方式,這涉及到整個系統關於一致性方面的取捨。
在該方案中我們假設讀操作直接簡單地向 follower 發起,那麼由於 Raft 的 Quorum 機制(大部分節點成功即可),針對某個提案在某一時間段內,集群可能會有以下兩種狀態:
- 某次寫操作的日誌尚未被覆制到一少部分 follower,但 leader 已經將其 commit。
- 某次寫操作的日誌已經被同步到所有 follower,但 leader 將其 commit 後,心跳包尚未通知到一部分 follower。
以上每個場景客戶端都可能讀到過時的數據,整個系統顯然是不滿足線性一致的。
8.2.2 寫主讀主缺陷分析
在該方案中我們限定,所有的讀操作也必須經由 leader 節點處理,讀寫都經過 leader 難道還不能滿足線性一致?是的!! 並且該方案存在不止一個問題!!
問題一:狀態機落後於 committed log 導致臟讀
回想一下前文講過的,我們在解釋什麼是 commit 時提到


