
原創聲明 本文作者:黃小斜 轉載請務必在文章開頭註明出處和作者。 什麼是消息隊列 “RabbitMQ?”“Kafka?”“RocketMQ?”...在日常學習與開發過程中,我們常常聽到消息隊列這個關鍵詞,可能你是熟練使用消息隊列的老手,又或者你是不懂消息隊列的新手,不論你了不瞭解消息隊列,本文都將帶 ...
原創聲明
本文作者:黃小斜
轉載請務必在文章開頭註明出處和作者。
什麼是消息隊列
“RabbitMQ?”“Kafka?”“RocketMQ?”...在日常學習與開發過程中,我們常常聽到消息隊列這個關鍵詞,可能你是熟練使用消息隊列的老手,又或者你是不懂消息隊列的新手,不論你了不瞭解消息隊列,本文都將帶你搞懂消息隊列的一些基本理論。如果你是老手,你可能從本文學到你之前不曾註意的一些關於消息隊列的重要概念,如果你是新手,相信本文將是你打開消息隊列大門的一板磚。
根據百度百科的說法,“消息隊列”是在消息的傳輸過程中保存消息的容器。消息隊列管理器在將消息從它的源中繼到它的目標時充當中間人。隊列的主要目的是提供路由並保證消息的傳遞;如果發送消息時接收者不可用,消息隊列會保留消息,直到可以成功地傳遞它。`
為什麼要使用消息隊列
我覺得使用消息隊列主要有兩點好處:
1.通過非同步處理提高系統性能(削峰、減少響應所需時間);
2.降低系統耦合性。如果在面試的時候你被面試官問到這個問題的話,一般情況是你在你的簡歷上涉及到消息隊列這方面的內容,這個時候推薦你結合你自己的項目來回答。
《大型網站技術架構》第四章和第七章均有提到消息隊列對應用性能及擴展性的提升。
在我平時的日常工作中,用到消息隊列的場景可不少,比如,我有一個定時任務需要在A應用每天7點開始調度,那麼定時任務系統如何告訴這個A應用呢,一種辦法是直接調用A應用的RPC服務,但是,定時任務系統不可能去記錄那麼多應用的RPC服務,所以如果換成消息,就大大降低了複雜度。
還有一種常見使用消息隊列的場景,那就是把一些不需要及時處理的RPC調用改成消息,比如最典型的電商下單,一定是實時性要求很高的,但是,有一些消息會在用戶下單後進行非同步的發送,比如用戶對商品的評價,用戶的退款請求,這些請求不需要被實時地進行處理,完全可以非同步化處理,這個時候使用消息隊列就是再好不過的選擇了,消息隊列會幫你存儲這些待處理的消息,並且等應用負載較低的時候再分發給應用處理,或者是等待應用主動向消息隊列獲取消息。
常用的消息隊列
我們可以把消息隊列比作是一個存放消息的容器,當我們需要使用消息的時候可以取出消息供自己使用。消息隊列是分散式系統中重要的組件,使用消息隊列主要是為了通過非同步處理提高系統性能和削峰、降低系統耦合性。目前使用較多的消息隊列有ActiveMQ,RabbitMQ,Kafka,RocketMQ。
當然,在我們公司內部用的大多都是自研的消息隊列產品,一方面是因為需要適配金融級分散式場景,另一方面自研的中間件有專門的的團隊維護,出了什麼問題才能及時處理和修複。
下麵我們就一起來看看這些開源的消息隊列是怎麼設計的,各有什麼優缺點呢。
RabbitMQ
RabbitMQ 2007年發佈,是一個在AMQP(高級消息隊列協議)基礎上完成的,可復用的企業消息系統,是當前最主流的消息中間件之一。
主要特性:
- 可靠性: 提供了多種技術可以讓你在性能和可靠性之間進行權衡。這些技術包括持久性機制、投遞確認、發佈者證實和高可用性機制;
- 靈活的路由: 消息在到達隊列前是通過交換機進行路由的。RabbitMQ為典型的路由邏輯提供了多種內置交換機類型。如果你有更複雜的路由需求,可以將這些交換機組合起來使用,你甚至可以實現自己的交換機類型,並且當做RabbitMQ的插件來使用;
- 消息集群:在相同區域網中的多個RabbitMQ伺服器可以聚合在一起,作為一個獨立的邏輯代理來使用;
- 隊列高可用:隊列可以在集群中的機器上進行鏡像,以確保在硬體問題下還保證消息安全;
- 多種協議的支持:支持多種消息隊列協議;
- 伺服器端用Erlang語言編寫,支持只要是你能想到的所有編程語言;
- 管理界面: RabbitMQ有一個易用的用戶界面,使得用戶可以監控和管理消息Broker的許多方面;
- 跟蹤機制:如果消息異常,RabbitMQ提供消息跟蹤機制,使用者可以找出發生了什麼;
- 插件機制:提供了許多插件,來從多方面進行擴展,也可以編寫自己的插件;
優點:
- 由於erlang語言的特性,mq 性能較好,高併發;
- 健壯、穩定、易用、跨平臺、支持多種語言、文檔齊全;
- 有消息確認機制和持久化機制,可靠性高;
- 高度可定製的路由;
- 管理界面較豐富,在互聯網公司也有較大規模的應用;
- 社區活躍度高;
缺點:
- 儘管結合erlang語言本身的併發優勢,性能較好,但是不利於做二次開發和維護;
- 實現了代理架構,意味著消息在發送到客戶端之前可以在中央節點上排隊。此特性使得RabbitMQ易於使用和部署,但是使得其運行速度較慢,因為中央節點增加了延遲,消息封裝後也比較大;
- 需要學習比較複雜的介面和協議,學習和維護成本較高;
ActiveMQ
ActiveMQ是由Apache出品,ActiveMQ 是一個完全支持JMS1.1和J2EE 1.4規範的 JMS Provider實現。它非常快速,支持多種語言的客戶端和協議,而且可以非常容易的嵌入到企業的應用環境中,並有許多高級功能。
主要特性:
- 服從JMS 規範:JMS 規範提供了良好的標準和保證,包括:同步或非同步的消息分發,一次和僅一次的消息分發,消息接收和訂閱等等。遵從 JMS 規範的好處在於,不論使用什麼 JMS 實現提供者,這些基礎特性都是可用的;
- 連接性:ActiveMQ 提供了廣泛的連接選項,支持的協議有:HTTP/S,IP 多播,SSL,STOMP,TCP,UDP,XMPP等等。對眾多協議的支持讓 ActiveMQ 擁有了很好的靈活性。
- 支持的協議種類多:OpenWire、STOMP、REST、XMPP、AMQP ;
- 持久化插件和安全插件:ActiveMQ 提供了多種持久化選擇。而且,ActiveMQ 的安全性也可以完全依據用戶需求進行自定義鑒權和授權;
- 支持的客戶端語言種類多:除了 Java 之外,還有:C/C++,.NET,Perl,PHP,Python,Ruby;
- 代理集群:多個 ActiveMQ 代理可以組成一個集群來提供服務;
- 異常簡單的管理:ActiveMQ 是以開發者思維被設計的。所以,它並不需要專門的管理員,因為它提供了簡單又使用的管理特性。有很多中方法可以監控 ActiveMQ 不同層面的數據,包括使用在 JConsole 或者 ActiveMQ 的Web Console 中使用 JMX,通過處理 JMX 的告警消息,通過使用命令行腳本,甚至可以通過監控各種類型的日誌。
優點:
- 跨平臺(JAVA編寫與平臺無關有,ActiveMQ幾乎可以運行在任何的JVM上)
- 可以用JDBC:可以將數據持久化到資料庫。雖然使用JDBC會降低ActiveMQ的性能,但是資料庫一直都是開發人員最熟悉的存儲介質。將消息存到資料庫,看得見摸得著。而且公司有專門的DBA去對資料庫進行調優,主從分離;
- 支持JMS :支持JMS的統一介面;
- 支持自動重連;
- 有安全機制:支持基於shiro,jaas等多種安全配置機制,可以對Queue/Topic進行認證和授權。
- 監控完善:擁有完善的監控,包括Web Console,JMX,Shell命令行,Jolokia的REST API;
- 界面友善:提供的Web Console可以滿足大部分情況,還有很多第三方的組件可以使用,如hawtio;
缺點:
- 區活躍度不及RabbitMQ高;
- 根據其他用戶反饋,會出莫名其妙的問題,會丟失消息;
- 目前重心放到activemq6.0產品-apollo,對5.x的維護較少;
- 不適合用於上千個隊列的應用場景;
RocketMQ
RocketMQ出自 阿裡公司的開源產品,用 Java 語言實現,在設計時參考了 Kafka,並做出了自己的一些改進,消息可靠性上比 Kafka 更好。RocketMQ在阿裡集團被廣泛應用在訂單,交易,充值,流計算,消息推送,日誌流式處理,binglog分發等場景。
主要特性:
- 是一個隊列模型的消息中間件,具有高性能、高可靠、高實時、分散式特點;
- Producer、Consumer、隊列都可以分散式;
- Producer向一些隊列輪流發送消息,隊列集合稱為Topic,Consumer如果做廣播消費,則一個consumer實例消費這個Topic對應的所有隊列,如果做集群消費,則多個Consumer實例平均消費這個topic對應的隊列集合;
- 能夠保證嚴格的消息順序;
- 提供豐富的消息拉取模式;
- 高效的訂閱者水平擴展能力;
- 實時的消息訂閱機制;
- 億級消息堆積能力;
- 較少的依賴;
優點:
- 單機支持 1 萬以上持久化隊列
- RocketMQ 的所有消息都是持久化的,先寫入系統 PAGECACHE,然後刷盤,可以保證記憶體與磁碟都有一份數據,
訪問時,直接從記憶體讀取。
- 模型簡單,介面易用(JMS 的介面很多場合併不太實用);
- 性能非常好,可以大量堆積消息在broker中;
- 支持多種消費,包括集群消費、廣播消費等。
- 各個環節分散式擴展設計,主從HA;
- 開發度較活躍,版本更新很快。
缺點:
支持的客戶端語言不多,目前是java及c++,其中c++不成熟;
RocketMQ社區關註度及成熟度也不及前兩者;
沒有web管理界面,提供了一個CLI(命令行界面)管理工具帶來查詢、管理和診斷各種問題;
沒有在 mq 核心中去實現JMS等介面;
Kafka
Apache Kafka是一個分散式消息發佈訂閱系統。它最初由LinkedIn公司基於獨特的設計實現為一個分散式的提交日誌系統( a distributed commit log),,之後成為Apache項目的一部分。Kafka系統快速、可擴展並且可持久化。它的分區特性,可複製和可容錯都是其不錯的特性。
主要特性:
- 快速持久化,可以在O(1)的系統開銷下進行消息持久化;
- 高吞吐,在一臺普通的伺服器上既可以達到10W/s的吞吐速率;
- .完全的分散式系統,Broker、Producer、Consumer都原生自動支持分散式,自動實現負載均衡;
- 支持同步和非同步複製兩種HA;
- 支持數據批量發送和拉取;
- zero-copy:減少IO操作步驟;
- 數據遷移、擴容對用戶透明;
- 無需停機即可擴展機器;
- 其他特性:嚴格的消息順序、豐富的消息拉取模型、高效訂閱者水平擴展、實時的消息訂閱、億級的消息堆積能力、定期刪除機制;
優點:
- 客戶端語言豐富,支持java、.net、php、ruby、python、go等多種語言;
- 性能卓越,單機寫入TPS約在百萬條/秒,消息大小10個位元組;
- 提供完全分散式架構, 並有replica機制, 擁有較高的可用性和可靠性, 理論上支持消息無限堆積;
- 支持批量操作;
- 消費者採用Pull方式獲取消息, 消息有序, 通過控制能夠保證所有消息被消費且僅被消費一次;
- 有優秀的第三方Kafka Web管理界面Kafka-Manager;
- 在日誌領域比較成熟,被多家公司和多個開源項目使用;
缺點:
- Kafka單機超過64個隊列/分區,Load會發生明顯的飆高現象,隊列越多,load越高,發送消息響應時間變長
- 使用短輪詢方式,實時性取決於輪詢間隔時間;
- 消費失敗不支持重試;
- 支持消息順序,但是一臺代理宕機後,就會產生消息亂序;
- 社區更新較慢;
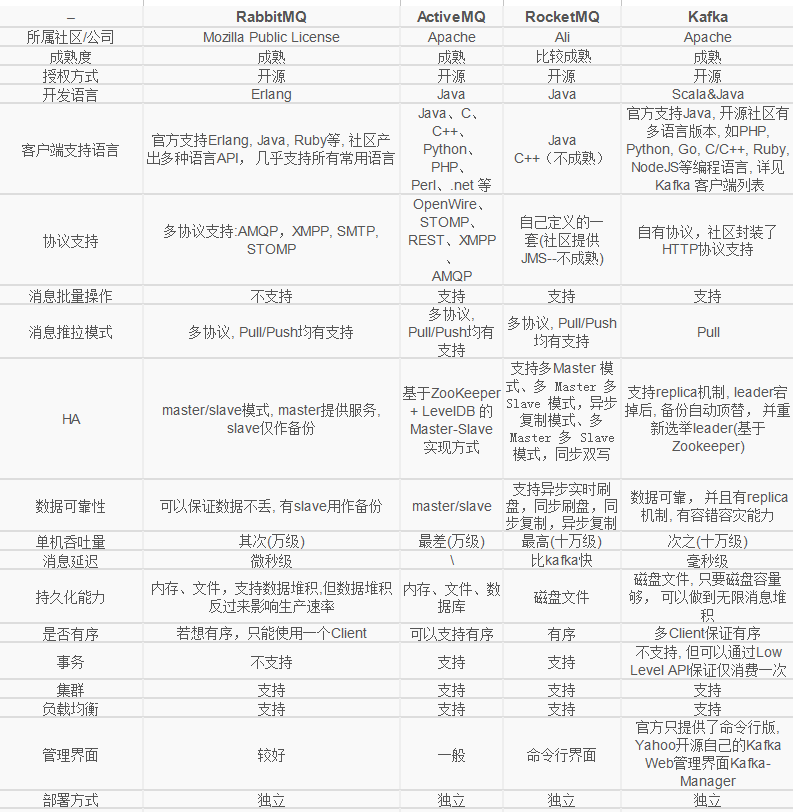
消息隊列的pull和push
這麼多的消息隊列,有一個區別很重要,那就是模式,到底是pull好還是push好,下麵就讓我們來一探究竟吧
Push
Push即服務端主動發送數據給客戶端。在服務端收到消息之後立即推送給客戶端。
Push模型最大的好處就是實時性。因為服務端可以做到只要有消息就立即推送,所以消息的消費沒有“額外”的延遲。
但是Push模式在消息中間件的場景中會面臨以下一些問題:
- 在Broker端需要維護Consumer的狀態,不利於Broker去支持大量的Consumer的場景
- Consumer的消費速度是不一致的,由Broker進行推送難以處理不同的Consumer的狀況
- Broker難以處理Consumer無法消費消息的情況(Broker無法確定Consumer的故障是短暫的還是永久的)
- 大量的推送消息會加重Consumer的負載或者衝垮Consumer
Pull模式可以很好的應對以上的這些場景。
Pull
Pull模式由Consumer主動從Broker獲取消息。
這樣帶來了一些好處:
- Broker不再需要維護Consumer的狀態(每一次pull都包含了其實偏移量等必要的信息)
- 狀態維護在Consumer,所以Consumer可以很容易的根據自身的負載等狀態來決定從Broker獲取消息的頻率
Pull模式還有一個好處是可以聚合消息。
因為Broker無法預測寫一條消息產生的時間,所以在收到消息之後只能立即推送給Consumer,所以無法對消息聚合後再推送給Consumer。 而Pull模式由Consumer主動來獲取消息,每一次Pull時都儘可能多的獲取已近在Broker上的消息。
但是,和Push模式正好相反,Pull就面臨了實時性的問題。
因為由Consumer主動來Pull消息,所以實時性和Pull的周期相關,這裡就產生了“額外”延遲。如果為了降低延遲來提升Pull的執行頻率,可能在沒有消息的時候產生大量的Pull請求(消息中間件是完全解耦的,Broker和Consumer無法預測下一條消息在什麼時候產生);如果頻率低了,那延遲自然就大了。
另外,Pull模式狀態維護在Consumer,所以多個Consumer之間需要相互協調,這裡就需要引入ZK或者自己實現NameServer之類的服務來完成Consumer之間的協調。
有沒有一種方式,能結合Push和Pull的優勢,同時變各自的缺陷呢?答案是肯定的。
Long-Polling
使用long-polling模式,Consumer主動發起請求到Broker,正常情況下Broker響應消息給Consumer;在沒有消息或者其他一些特殊場景下,可以將請求阻塞在服務端延遲返回。
long-polling不是一種Push模式,而是Pull的一個變種。
那麼:
- 在Broker一直有可讀消息的情況下,long-polling就等價於執行間隔為0的pull模式(每次收到Pull結果就發起下一次Pull請求)。
- 在Broker沒有可讀消息的情況下,請求阻塞在了Broker,在產生下一條消息或者請求“超時之前”響應請求給Consumer。
以上兩點避免了多餘的Pull請求,同時也解決Pull請求的執行頻率導致的“額外”的延遲。
註意上面有一個概念:“超時之前”。每一個請求都有超時時間,Pull請求也是。“超時之前”的含義是在Consumer的“Pull”請求超時之前。
基於long-polling的模型,Broker需要保證在請求超時之前返回一個結果給Consumer,無論這個結果是讀取到了消息或者沒有可讀消息。
因為Consumer和Broker之間的時間是有偏差的,且請求從Consumer發送到Broker也是需要時間的,所以如果一個請求的超時時間是5秒,而這個請求在Broker端阻塞了5秒才返回,那麼Consumer在收到Broker響應之前就會判定請求超時。所以Broker需要保證在Consumer判定請求超時之前返回一個結果。
通常的做法時在Broker端可以阻塞請求的時間總是小於long-polling請求的超時時間。比如long-polling請求的超時時間為30秒,那麼Broker在收到請求後最遲在25s之後一定會返回一個結果。中間5s的差值來應對Broker和Consumer的始終存在偏差和網路存在延遲的情況。 (可見Long-Polling模式的前提是Broker和Consumer之間的時間偏差沒有“很大”)
Long-Polling還存在什麼問題嗎,還能改進嗎?
Dynamic Push/Pull
“在Broker一直有可讀消息的情況下,long-polling就等價於執行間隔為0的pull模式(每次收到Pull結果就發起下一次Pull請求)。”
這是上面long-polling在服務端一直有可消費消息的處理情況。在這個情況下,一條消息如果在long-polling請求返回時到達服務端,那麼它被Consumer消費到的延遲是:
假設Broker和Consumer之間的一次網路開銷時間為R毫秒,
那麼這條消息需要經歷3R才能到達Consumer
第一個R:消息已經到達Broker,但是long-polling請求已經讀完數據準備返回Consumer,從Broker到Consumer消耗了R
第二個R:Consumer收到了Broker的響應,發起下一次long-polling,這個請求到達Broker需要一個R
的時間
第三個R:Broker收到請求讀取了這條數據,那麼返回到Consumer需要一個R的時間
所以總共需要3R(不考慮讀取的開銷,只考慮網路開銷)
另外,在這種情況下Broker和Consumer之間一直在進行請求和響應(long-polling變成了間隔為0的pull)。
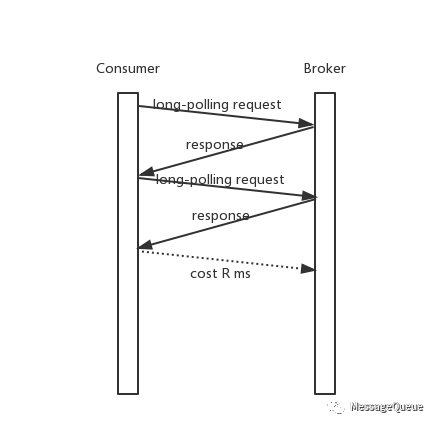
考慮這樣一種方式,它有long-polling的優勢,同時能減少在有消息可讀的情況下由Broker主動push消息給Consumer,減少不必要的請求。
參考文章
http://www.luyixian.cn/news_show_261068.aspx
https://blog.51cto.com/caczjz/2141194?source=dra
https://www.jianshu.com/p/251b76643d47
https://www.jianshu.com/p/36a7775b04ec

