
本篇博客是Redis系列的第3篇,主要講解下Redis的2種持久化機制:RDB和AOF。 本系列的前2篇可以點擊以下鏈接查看: "Redis系列(一):Redis簡介及環境安裝" 。 "Redis系列(二):Redis的5種數據結構及其常用命令" 1. 為什麼需要持久化? 因為Redis是記憶體資料庫 ...
本篇博客是Redis系列的第3篇,主要講解下Redis的2種持久化機制:RDB和AOF。
本系列的前2篇可以點擊以下鏈接查看:
1. 為什麼需要持久化?
因為Redis是記憶體資料庫,它將自己的數據存儲在記憶體裡面,一旦Redis伺服器進程退出或者運行Redis伺服器的電腦停機,Redis伺服器中的數據就會丟失。
為了避免數據丟失,所以Redis提供了持久化機制,將存儲在記憶體中的數據保存到磁碟中,用於在Redis伺服器進程退出或者運行Redis伺服器的電腦停機導致數據丟失時,快速的恢復之前Redis存儲在記憶體中的數據。
Redis提供了2種持久化方式,分別為:
- RDB持久化
- AOF持久化
接下來,我們一一詳解。
2. RDB持久化
RDB持久化是將某個時間點上Redis中的數據保存到一個RDB文件中,如下所示:
基於RDB持久化的上述性質,所以RDB持久化也叫做快照持久化。
該文件是一個經過壓縮的二進位文件,通過該文件可以還原生成RDB文件時Redis中的數據,如下所示:
2.1 創建RDB文件
Redis提供了2個命令來創建RDB文件,一個是SAVE,另一個是BGSAVE。
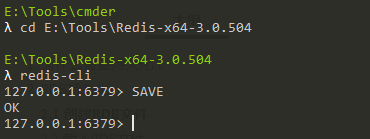
SAVE命令會阻塞Redis伺服器進程,直到RDB文件創建完畢為止,在伺服器進程阻塞期間,伺服器不能處理任何命令請求,如下所示:
BGSAVE命令會派生出一個子進程,然後由子進程負責創建RDB文件,伺服器進程(父進程)繼續處理命令請求,如下所示:

以上描述也是這2個命令的區別,這裡是重點,面試經常會問到。
因為BGSAVE命令可以在不阻塞伺服器進程的情況下執行,所以推薦使用BGSAVE命令。
我們可以手動執行該命令,如上面截圖所示,但還是推薦設置下Redis伺服器配置文件的save選項,讓伺服器每隔一段時間自動執行一次BGSAVE命令。
我們可以通過save選項設置多個保存條件,只要其中任意一個條件被滿足,伺服器就會執行BGSAVE命令。
save選項設置的預設條件如下所示:
save 900 1
save 300 10
save 60 10000
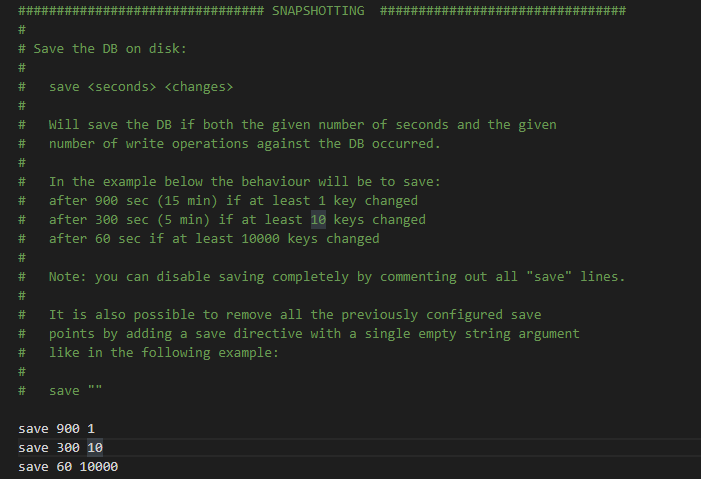
預設的配置條件表示,只要滿足以下3個條件中的任意1個,BGSAVE命令就會被執行:
- 伺服器在900s(即15分鐘)之內,對資料庫進行了至少1次修改
- 伺服器在300s(即5分鐘)之內,對資料庫進行了至少10次修改
- 伺服器在60s(即1分鐘)之內,對資料庫進行了至少10000次修改
當滿足條件執行BGSAVE命令時,輸出日誌如下圖所示:

生成的RDB文件會根據Redis配置文件中的名稱和路徑來保存,相關的2個配置如下所示:
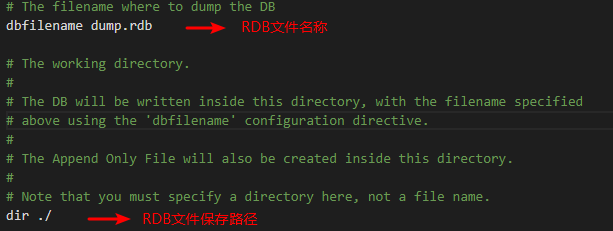
最終生成的RDB文件如下所示(截圖為本機Windows環境,Linux環境下路徑會稍有不同):

2.2 載入RDB文件
首先,我們要明確的是,載入RDB文件的目的是為了在Redis伺服器進程重新啟動之後還原之前存儲在Redis中的數據。
然後,Redis載入RDB文件並沒有專門的命令,而是在Redis伺服器啟動時自動執行的。
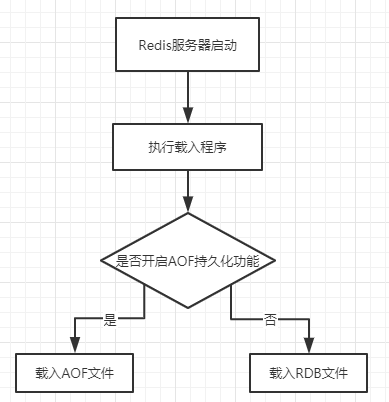
而且,Redis伺服器啟動時是否會載入RDB文件還取決於伺服器是否啟用了AOF持久化功能,具體判斷邏輯為:
- 只有在AOF持久化功能處於關閉狀態時,伺服器才會使用RDB文件來還原數據。
- 如果伺服器開啟了AOF持久化功能,那麼伺服器會優先使用AOF文件來還原數據。
以上判斷邏輯如下圖所示:
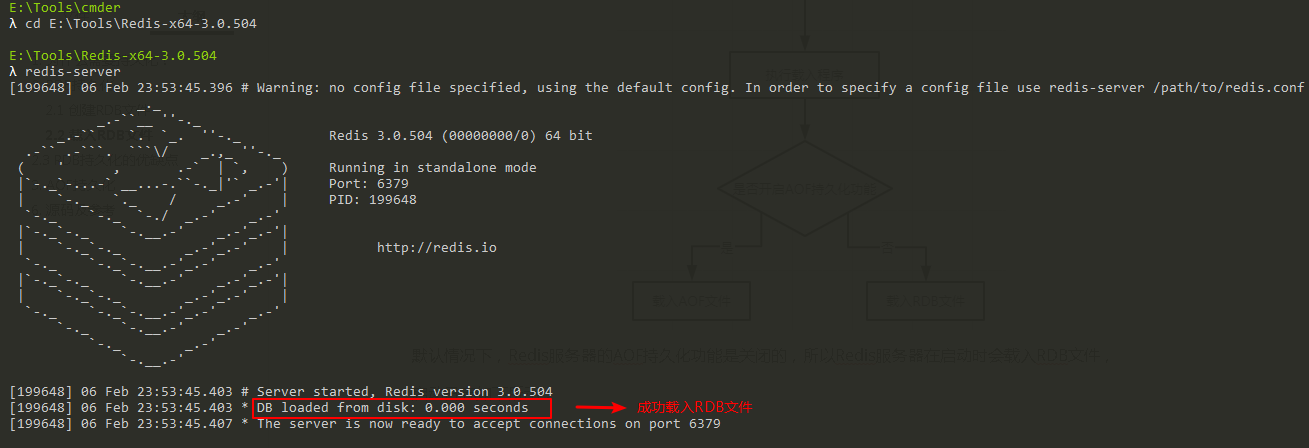
預設情況下,Redis伺服器的AOF持久化功能是關閉的,所以Redis伺服器在啟動時會載入RDB文件,
啟動日誌如下所示:
2.3 伺服器狀態
創建和載入RDB文件,可能存在的伺服器狀態有以下3種:
- 當執行SAVE命令時,Redis伺服器會被阻塞,此時客戶端發送的所有命令請求都會被阻塞,只有在伺服器執行完SAVE命令,重新開始接受命令請求之後,客戶端發送的命令請求才會被處理。
- 當執行BGSAVE命令時,Redis伺服器不會被阻塞,Redis伺服器仍然可以繼續處理客戶端發送的命令請求。
- 伺服器在載入RDB文件期間,會一直處於阻塞狀態,直到RDB文件載入成功。
3. AOF持久化
AOF持久化是通過保存Redis伺服器所執行的寫命令來記錄資料庫數據的,如下圖所示:

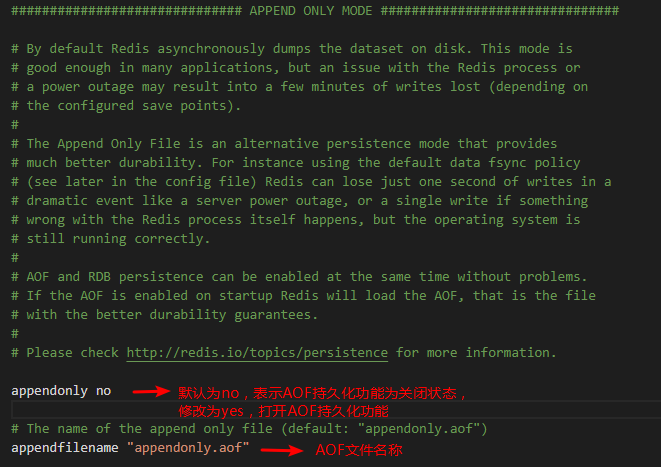
預設情況下,AOF持久化功能是關閉的,如果想要打開,可以修改下圖所示的配置:
舉個例子,假設Redis中還沒有存儲任何數據,我們執行瞭如下所示的命令:
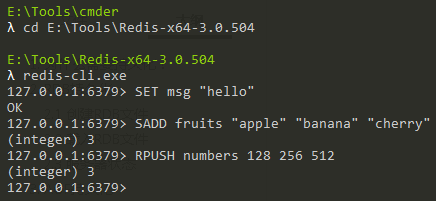
然後我們會發現Redis伺服器生成了1個名為appendonly.aof的文件,打開該文件,我們可以看到上面執行的3個寫命令都存儲在該文件中:
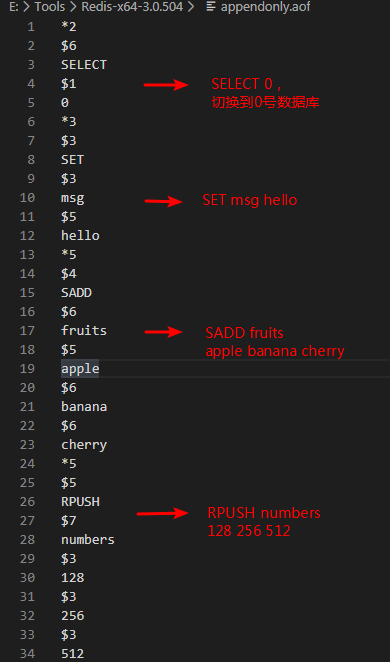
3.1 AOF持久化的實現
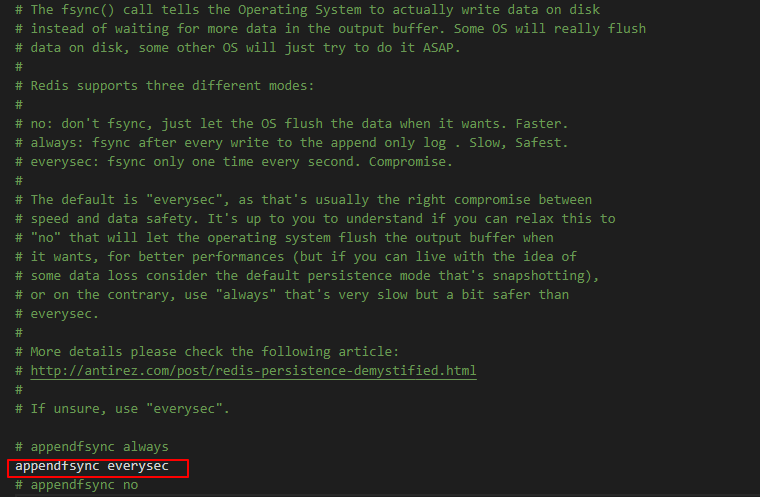
當AOF持久化功能處於打開狀態時,Redis伺服器在執行完一個寫命令之後,會以協議格式(如上面截圖中AOF文件里保存寫命令的格式)將被執行的寫命令追加到伺服器狀態的AOF緩衝區的末尾,然後Redis伺服器會根據配置文件中appendfsync選項的值來決定何時將AOF緩衝區中的內容寫入和同步到AOF文件裡面。
appendfsync選項有以下3個值:
always
從安全性來說,always是最安全的(丟失數據最少),因為即使出現故障停機,資料庫也只會丟失一個事件迴圈中所產生的命令數據。
從效率來說,always的效率最慢,因為伺服器在每個事件迴圈都要將AOF緩衝區中的所有內容寫入到AOF文件,並且同步AOF文件。
everysec
從安全性來說,everysec模式下,即使出現故障停機,資料庫只會丟失一秒鐘的命令數據。
從效率來說,everysec模式足夠快,因為伺服器在每個事件迴圈都要將AOF緩衝區中的所有內容寫入到AOF文件,並且每隔一秒就要在子線程中對AOF文件進行同步。
no
從安全性來說,no模式下,如果出現故障停機,資料庫會丟失上次同步AOF文件之後的所有寫命令數據,具有不確定性,因為伺服器在每個事件迴圈都要將AOF緩衝區中的所有內容寫入到AOF文件,至於何時對AOF文件進行同步,則由操作系統控制。
從效率來說,no模式和everysec模式的效率差不多。
appendfsync選項的預設值是everysec,也推薦使用這個值,因為既保證了效率又保證了安全性。
3.2 載入AOF文件
因為AOF文件包含了重建資料庫所需的所有寫命令,所以Redis伺服器只要讀入並重新執行一遍AOF文件裡面保存的寫命令,就可以還原Redis伺服器關閉之前的數據。
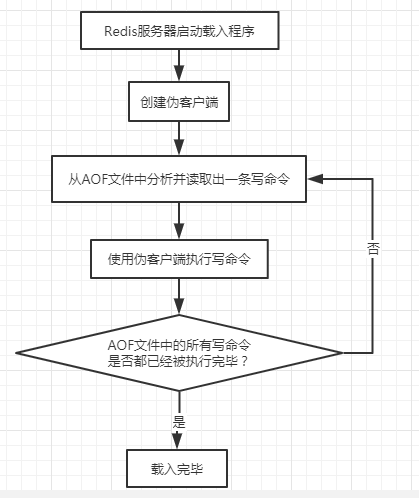
Redis讀取AOF文件並還原資料庫的詳細步驟如下:
創建一個不帶網路連接的偽客戶端
因為Redis的命令只能在客戶端上下文中執行,而載入AOF文件時所使用的命令直接來源於AOF文件而不是網路連接,所以伺服器使用了一個沒有網路連接的偽客戶端來執行AOF文件保存的寫命令。
偽客戶端執行命令的效果和帶網路連接的客戶端執行命令的效果完全一樣。
從AOF文件中分析並讀取出一條寫命令。
使用偽客戶端執行被讀取出的寫命令。
一直執行步驟2和步驟3,直到AOF文件中的所有寫命令都被執行完畢。
以上步驟如下圖所示:
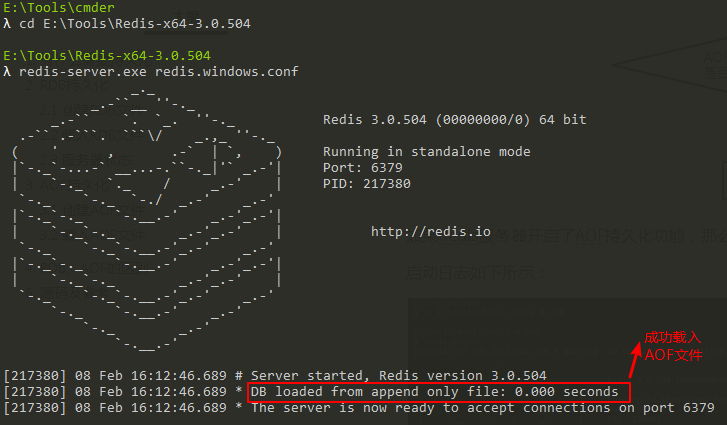
如果Redis伺服器開啟了AOF持久化功能,那麼Redis伺服器在啟動時會載入AOF文件,
啟動日誌如下所示:
3.3 AOF重寫
因為AOF持久化是通過保存被執行的寫命令來記錄資料庫數據的,所以隨著Redis伺服器運行時間的增加,AOF文件中的內容會越來越多,文件的體積會越來越大,如果不做控制,會有以下2點壞處:
- 過多的占用伺服器磁碟空間,可能會對Redis伺服器甚至整個宿主電腦造成影響。
- AOF文件的體積越大,使用AOF文件來進行資料庫還原所需的時間就越多。
舉個例子,在客戶端執行如下命令:
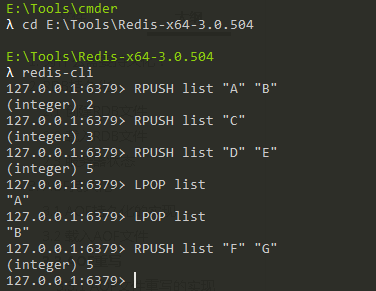
為了記錄這個list鍵的狀態,AOF文件就需要保存上面執行的6條命令。
為瞭解決AO文件體積越來越大的問題,Redis提供了AOF文件重寫功能,即Redis伺服器會創建一個新的AOF文件來替代現有的AOF文件,新舊兩個AOF文件所保存的資料庫數據相同,但新AOF文件不會包含任何浪費空間的冗餘命令,所以新AOF文件的體積通常會比舊AOF文件的體積要小很多。
3.3.1 AOF重寫的實現原理
AOF文件重寫並不需要對現有的AOF文件進行任何讀取、分析或者寫入操作,而是通過讀取伺服器當前的資料庫數據來實現的。
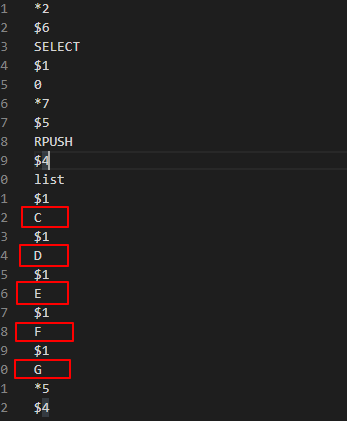
仍然以上面的list鍵為例,舊的AOF文件保存了6條命令來記錄list鍵的狀態,但list鍵的結果是“C” "D" "E" "F" "G"這樣的數據,所以AOF文件重寫時,可以用一條RPUSH list “C” "D" "E" "F" "G"命令來代替之前的六條命令,這樣就可以將保存list鍵所需的命令從六條減少為一條了。
按照上面的原理,如果Redis伺服器存儲的鍵值對足夠多,AOF文件重寫生成的新AOF文件就會減少很多很多的冗餘命令,進而大大減小了AOF文件的體積。
綜上所述,AOF文件重寫功能的實現原理為:
首先從資料庫中讀取鍵現在的值,然後用一條命令去記錄鍵值對,代替之前記錄這個鍵值對的多條命令。
3.3.2 AOF後臺重寫
因為AOF文件重寫會進行大量的文件寫入操作,所以執行這個操作的線程將被長時間阻塞。
因為Redis伺服器使用單個線程來處理命令請求,所以如果由伺服器進程直接執行這個操作,那麼在重寫AOF文件期間,伺服器將無法處理客戶端發送過來的命令請求。
為了避免上述問題,Redis將AOF文件重寫功能放到子進程里執行,這樣做有以下2個好處:
- 子進程進行AOF文件重寫期間,伺服器進程(父進程)可以繼續處理命令請求。
- 子進程帶有伺服器進程的數據副本,使用子進程而不是線程,可以在避免使用鎖的情況下,保證數據的安全性。
AOF後臺重寫的步驟如下所示:
伺服器進程創建子進程,子進程開始AOF文件重寫
從創建子進程開始,伺服器進程執行的所有寫命令不僅要寫入AOF緩衝區,還要寫入AOF重寫緩衝區
寫入AOF緩衝區的目的是為了同步到原有的AOF文件。
寫入AOF重寫緩衝區的目的是因為子進程在進行AOF文件重寫期間,伺服器進程還在繼續處理命令請求,
而新的命令可能會對現有的資料庫進行修改,從而使得伺服器當前的資料庫數據和重寫後的AOF文件所
保存的資料庫數據不一致。
子進程完成AOF重寫工作,向父進程發送一個信號,父進程在接收到該信號後,會執行以下操作:
1.將AOF重寫緩衝區中的所有內容寫入到新AOF文件中,這樣就保證了新AOF文件所保存的資料庫數據和伺服器當前的資料庫數據是一致的。
2.對新的AOF文件進行改名,原子地覆蓋現有的AOF文件,完成新舊兩個AOF文件的替換。
Redis提供了BGREWRITEAOF命令來執行以上步驟,如下圖所示:

執行完成後,打開appendonly.aof文件,發現保存list鍵的命令從六條變為了一條:
除了手動執行BGREWRITEAOF命令外,Redis還提供了2個配置項用來自動執行BGREWRITEAOF命令:
auto-aof-rewrite-percentage 100
auto-aof-rewrite-min-size 64mb
該配置表示,當AOF文件的體積大於64MB,並且AOF文件的體積比上一次重寫之後的體積大了至少一倍(100%),Redis將自動執行BGREWRITEAOF命令。
4. RDB持久化、AOF持久化的區別
通過上面的講解,我們會發現Redis提供的2種持久化方法是有區別的,可以總結為以下4點:
- 實現方式
- 文件體積
- 安全性
- 優先順序
接下來一一講解。
4.1 實現方式
RDB持久化是通過將某個時間點Redis伺服器存儲的數據保存到RDB文件中來實現持久化的。
AOF持久化是通過將Redis伺服器執行的所有寫命令保存到AOF文件中來實現持久化的。
4.2 文件體積
由上述實現方式可知,RDB持久化記錄的是結果,AOF持久化記錄的是過程,所以AOF持久化生成的AOF文件會有體積越來越大的問題,Redis提供了AOF重寫功能來減小AOF文件體積。
4.3 安全性
AOF持久化的安全性要比RDB持久化的安全性高,即如果發生機器故障,AOF持久化要比RDB持久化丟失的數據要少。
因為RDB持久化會丟失上次RDB持久化後寫入的數據,而AOF持久化最多丟失1s之內寫入的數據(使用預設everysec配置的話)。
4.4 優先順序
由於上述的安全性問題,如果Redis伺服器開啟了AOF持久化功能,Redis伺服器在啟動時會使用AOF文件來還原數據,如果Redis伺服器沒有開啟AOF持久化功能,Redis伺服器在啟動時會使用RDB文件來還原數據,所以AOF文件的優先順序比RDB文件的優先順序高。
5. 源碼及參考
Josiah L. Carlson 《Reids實戰》
黃健巨集 《Redis設計與實現》

