
Spark Streaming對實時數據流進行分析處理,源源不斷的從數據源接收數據切割成一個個時間間隔進行處理; 流處理與批處理有明顯區別,批處理中的數據有明顯的邊界、數據規模已知;而流處理數據流並沒有邊界,也未知數據規模; ...
Spark Streaming對實時數據流進行分析處理,源源不斷的從數據源接收數據切割成一個個時間間隔進行處理;
流處理與批處理有明顯區別,批處理中的數據有明顯的邊界、數據規模已知;而流處理數據流並沒有邊界,也未知數據規模;
由於流處理的數據流特征,使之數據流具有不可預測性,而且數據處理的速率還與硬體、網路等資源有關,在這種情況下如不對源源不斷進來的數據流速率進行限制,那當Spark節點故障、網路故障或數據處理吞吐量下來時還有數據不斷流進來,那將有可能將出現OOM進而導致Spark Streaming程式崩潰;
在Spark Streaming中不同的數據源採用不同的限速策略,但無論是Socket數據源的限流策略還是Kafka數據源的限流策略其速率(rate)的計算都是使用PIDController演算法進行計算而得來;
下麵從源碼的角度分別介紹Socket數據源與Kafka數據源的限流處理。
速率限制的計算與更新
Spark Streaming的流處理其實是基於微批處理(MicroBatch)的,也就是說將數據流按某比較小的時間間隔將數據切割成為一段段微批數據進行處理;
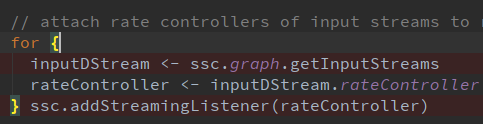
StreamingContext調用Start()啟動的時候會將速率控制器(rateController)添加到StreamingListener監聽器中;
當每批次處理完成時將觸發監聽器(RateController),使用該批處理的處理結束時間、處理延遲時間、調度延遲時間、記錄行數調用PIDRateEstimator傳入PID演算法中(PID Controller)計算出該批次的速率(rate)並更新速率限制(rateLimit)與發佈該限制速率;
override def onBatchCompleted(batchCompleted: StreamingListenerBatchCompleted) {
val elements = batchCompleted.batchInfo.streamIdToInputInfo
for {
processingEnd <- batchCompleted.batchInfo.processingEndTime
workDelay <- batchCompleted.batchInfo.processingDelay
waitDelay <- batchCompleted.batchInfo.schedulingDelay
elems <- elements.get(streamUID).map(_.numRecords)
} computeAndPublish(processingEnd, elems, workDelay, waitDelay)
}
private def computeAndPublish(time: Long, elems: Long, workDelay: Long, waitDelay: Long): Unit =
Future[Unit] {
val newRate = rateEstimator.compute(time, elems, workDelay, waitDelay)
newRate.foreach { s =>
rateLimit.set(s.toLong)
publish(getLatestRate())
}
}Socket數據源限流
批次的限制速率上面已經算出,這裡說的是接收Socket過來的數據時的數據限流;
SocketInputStream類receive方法接收到數據後將數據存入 BlockGenerator的Buffer中,在寫入Buffer前調用限流器 (RateLimiter)對寫入數據進行限流;
RateLimiter限流器使用了Google開源的 Guava中內置的RateLimiter限流器,該類只是對Guava限流器的簡單封裝;
在Spark Streaming中可通過使用兩個參數配置初始速率與最大速率spark.streaming.receiver.maxRate、spark.streaming.backpressure.initialRate;亦可配置PIDController演算法相關的四個參數值;
RateLimiter限流器是基於令牌桶的演算法基本原理比較簡單,以一個恆定的速率生成令牌放入令牌桶中,桶滿則停止,處理請求時需要從令牌桶中取出令牌,當桶中無令牌可取時阻塞等待,此演算法用於確保系統不被洪峰擊垮。
private lazy val rateLimiter = GuavaRateLimiter.create(getInitialRateLimit().toDouble)
/**
* Push a single data item into the buffer.
*/
def addData(data: Any): Unit = {
if (state == Active) {
//調用限流器等待
waitToPush()
synchronized {
if (state == Active) {
currentBuffer += data
} else {
throw new SparkException(
"Cannot add data as BlockGenerator has not been started or has been stopped")
}
}
} else {
throw new SparkException(
"Cannot add data as BlockGenerator has not been started or has been stopped")
}
}
def waitToPush() {
//限流器申請令牌
rateLimiter.acquire()
}Guava庫中RateLimiter限流器基本使用:
//創建限流器,每秒產生令牌數1
RateLimiter rateLimiter=RateLimiter.create(1);
for (int i = 0; i < 10; i++) {
//獲得一個令牌,未申請到令牌則阻塞等待
double waitTime = rateLimiter.acquire();
System.out.println(String.format("id:%d time:%d waitTime:%f",i,System.currentTimeMillis(),waitTime));
}Kafka數據源限流的實現
在Spark Streaming Kafka包拉取Kafka數據會進行如下動作:
1、取Kafka中最新偏移量、分區
2、通過rateController限制每個分區可拉取的最大消息數
3、在DirectKafkaInputDStream中創建KafkaRDD,在其中調用相關對象拉取數據
通過如上步驟也可用看出,只要限制了Kafka某個分區的偏移量(offset)範圍也就可限制從Kafka拉取的消息數量,從而達到限流的目的,Spark streaming kafka也是通過此實現的;
計算每個分區速率限制,有如下步驟:
1、通過seekToEnd獲取最新可用偏移量與當前偏移量對比獲得當前所有分區延遲偏移量
單個分區偏移量延遲=最新偏移量記錄-當前偏移量記錄
2、獲取配置項中每個分區最大速率
(spark.streaming.kafka.maxRatePerPartition),背壓率計算,計算每個分區背壓率計算公式為:
單個分區背壓率=單個分區偏移量延遲/所有分區總延遲*速率限制
速率限制(rateLimit):為通過PIDController動態計算得來
如有配置每個分區最大速率則取配置項最大速率與背壓率兩者中的最小值,未配置則取背壓率作為每個分區速率限制;
3、將批次間隔(batchDuration)*每個分區速率限制=每個分區最大消息數
4、取當前分區偏移量+分區最大消息數 與 最新偏移量兩者當中最小的,由此來控制拉取消息速率;
如當前偏移量+分區最大消息數 大於 最新偏移量則取 最新偏移量否則取 當前偏移量+分區最大消息數作為拉取Kafka數據的Offset範圍;
// 限制每個分區最大消息數
protected def clamp(
offsets: Map[TopicPartition, Long]): Map[TopicPartition, Long] = {
maxMessagesPerPartition(offsets).map { mmp =>
mmp.map { case (tp, messages) =>
val uo = offsets(tp)
tp -> Math.min(currentOffsets(tp) + messages, uo)
}
}.getOrElse(offsets)
} 不管是Kafka數據源還是Socket數據源Spark Streaming中都使用了PIDController演算法用於計算其速率限制值,兩者的差別也只是因為兩種數據源的獲取方式數據特征而決定的。Socket數據源使用了Guava RateLimiter、而Kafka數據源自己實現了基於Offsets的限流;
以上說介紹的框架版本為:Spark Streaming 版本為2.3.2與spark-streaming-kafka-0-10_2.11;
參考資料:
http://kafka.apache.org
http://spark.apache.org
文章首發地址:Solinx
https://mp.weixin.qq.com/s/yHStZgTAGBPoOMpj4e27Jg

