
[toc] 一、準備工作 先來一段偽代碼,首先你能看懂麽? 繼續做以下的前期準備工作: 新建一個測試資料庫TestDB; 創建測試表table1和table2; 插入測試數據; 準備工作做完以後,table1和table2看起來應該像下麵這樣: 準備SQL邏輯查詢測試語句 Oracle SQL語句執 ...
目錄
一、準備工作
先來一段偽代碼,首先你能看懂麽?
SELECT DISTINCT <select_list>
FROM <left_table>
<join_type> JOIN <right_table>
ON <join_condition>
WHERE <where_condition>
GROUP BY <group_by_list>
HAVING <having_condition>
ORDER BY <order_by_condition>
LIMIT <limit_number>繼續做以下的前期準備工作:
新建一個測試資料庫TestDB;
create database TestDB;創建測試表table1和table2;
CREATE TABLE table1
(
customer_id VARCHAR(10) NOT NULL,
city VARCHAR(10) NOT NULL,
PRIMARY KEY(customer_id)
)ENGINE=INNODB DEFAULT CHARSET=UTF8;
CREATE TABLE table2
(
order_id INT NOT NULL auto_increment,
customer_id VARCHAR(10),
PRIMARY KEY(order_id)
)ENGINE=INNODB DEFAULT CHARSET=UTF8;插入測試數據;
INSERT INTO table1(customer_id,city) VALUES('163','hangzhou');
INSERT INTO table1(customer_id,city) VALUES('9you','shanghai');
INSERT INTO table1(customer_id,city) VALUES('tx','hangzhou');
INSERT INTO table1(customer_id,city) VALUES('baidu','hangzhou');
INSERT INTO table2(customer_id) VALUES('163');
INSERT INTO table2(customer_id) VALUES('163');
INSERT INTO table2(customer_id) VALUES('9you');
INSERT INTO table2(customer_id) VALUES('9you');
INSERT INTO table2(customer_id) VALUES('9you');
INSERT INTO table2(customer_id) VALUES('tx');
INSERT INTO table2(customer_id) VALUES(NULL);準備工作做完以後,table1和table2看起來應該像下麵這樣:
mysql> select * from table1;
+-------------+----------+
| customer_id | city |
+-------------+----------+
| 163 | hangzhou |
| 9you | shanghai |
| baidu | hangzhou |
| tx | hangzhou |
+-------------+----------+
4 rows in set (0.00 sec) mysql> select * from table2;
+----------+-------------+
| order_id | customer_id |
+----------+-------------+
| 1 | 163 |
| 2 | 163 |
| 3 | 9you |
| 4 | 9you |
| 5 | 9you |
| 6 | tx |
| 7 | NULL |
+----------+-------------+
7 rows in set (0.00 sec)準備SQL邏輯查詢測試語句
SELECT a.customer_id, COUNT(b.order_id) as total_orders
FROM table1 AS a
LEFT JOIN table2 AS b
ON a.customer_id = b.customer_id
WHERE a.city = 'hangzhou'
GROUP BY a.customer_id
HAVING count(b.order_id) < 2
ORDER BY total_orders DESC;使用上述SQL查詢語句來獲得來自杭州,並且訂單數少於2的客戶。
二、SQL邏輯查詢語句執行順序
還記得上面給出的那一長串的SQL邏輯查詢規則麽?那麼,到底哪個先執行,哪個後執行呢?現在,我先給出一個查詢語句的執行順序:
(7) SELECT /* 處理SELECT列表,產生 VT7 */
(8) DISTINCT <select_list> /* 將重覆的行從 VT7 中刪除,產品 VT8 */
(1) FROM <left_table> /* 對FROM子句中的表執行笛卡爾積(交叉聯接),生成虛擬表 VT1。 */
(3) <join_type> JOIN <right_table> /* 如果指定了OUTER JOIN(相對於CROSS JOIN或INNER JOIN),
保留表中未找到匹配的行將作為外部行添加到 VT2,生成 VT3。
如果FROM子句包含兩個以上的表,
則對上一個聯接生成的結果表和下一個表重覆執行步驟1到步驟3,
直到處理完所有的表位置。 */
(2) ON <join_condition>/* 對 VT1 應用 ON 篩選器,只有那些使為真才被插入到 VT2。 */
(4) WHERE <where_condition>/* 對 VT3 應用 WHERE 篩選器,只有使為true的行才插入VT4。 */
(5) GROUP BY <group_by_list> /* 按 GROUP BY子句中的列列表對 VT4 中的行進行分組,生成 VT5 */
(6) HAVING <having_condition> /* 對 VT5 應用 HAVING 篩選器,只有使為true的組插入到 VT6 */
(9) ORDER BY <order_by_condition> /* 將 VT8 中的行按 ORDER BY子句中的列列表順序,生成一個游標(VC10),
生成表TV11,並返回給調用者。 */
(10)LIMIT <limit_number>Oracle SQL語句執行順序
(8)SELECT (9)DISTINCT (11)<Top Num> <select list>
(1)FROM [left_table]
(3)<join_type> JOIN <right_table>
(2)ON <join_condition>
(4)WHERE <where_condition>
(5)GROUP BY <group_by_list>
(6)WITH <CUBE | RollUP>
(7)HAVING <having_condition>
(10)ORDER BY <order_by_list>以上每個步驟都會產生一個虛擬表,該虛擬表被用作下一個步驟的輸入。這些虛擬表對調用者(客戶端應用程式或者外部查詢)不可用。只有最後一步生成的表才會會給調用者。如果沒有在查詢中指定某一個子句,將跳過相應的步驟。
邏輯查詢處理階段簡介:
FROM:對 FROM 子句中的前兩個表執行笛卡爾積(Cartesian product)(交叉聯接),生成虛擬表VT1ON:對VT1應用ON篩選器。只有那些使<join_condition>為真的行才被插入VT2。
OUTER(JOIN):如 果指定了OUTER JOIN(相對於CROSS JOIN或(INNER JOIN),保留表(preserved table:左外部聯接把左表標記為保留表,右外部聯接把右表標記為保留表,完全外部聯接把兩個表都標記為保留表)中未找到匹配的行將作為外部行添加到 VT2,生成VT3.如果FROM子句包含兩個以上的表,則對上一個聯接生成的結果表和下一個表重覆執行步驟1到步驟3,直到處理完所有的表為止。WHERE:對VT3應用WHERE篩選器。只有使<where_condition>為true的行才被插入VT4.GROUP BY:按GROUP BY子句中的列列表對VT4中的行分組,生成VT5.CUBE|ROLLUP:把超組(Suppergroups)插入VT5,生成VT6.HAVING:對VT6應用HAVING篩選器。只有使<having_condition>為 true 的組才會被插入VT7.SELECT:處理SELECT列表,產生VT8.DISTINCT:將重覆的行從VT8中移除,產生VT9.ORDER BY:將VT9中的行按RDER BY子句中的列列表排序,生成游標(VC10).TOP:從VC10的開始處選擇指定數量或比例的行,生成表VT11,並返回調用者。
註:步驟10,按ORDER BY子句中的列列表排序上步返回的行,返回游標VC10.這一步是第一步也是唯一 一步可以使用SELECT列表中的列別名的步驟。這一步不同於其它步驟的 是,它不返回有效的表,而是返回一個游標。SQL是基於集合理論的。集合不會預先對它的行排序,它只是成員的邏輯集合,成員的順序無關緊要。對錶進行排序 的查詢可以返回一個對象,包含按特定物理順序組織的行。ANSI把這種對象稱為游標。理解這一步是正確理解SQL的基礎。
因為這一步不返回表(而是返回游標),使用了ORDER BY子句的查詢不能用作表表達式。表表達式包括:視圖、內聯表值函數、子查詢、派生表和共用表達式。它的結果必須返回給期望得到物理記錄的客戶端應用程式。例如,下麵的派生表查詢無效,並產生一個錯誤:
select *
from(select orderid,customerid from orders order by orderid) as d下麵的視圖也會產生錯誤
create view my_view
as
select *
from orders
order by orderid在 SQL 中,表表達式中不允許使用帶有 ORDER BY 子句的查詢,而在T—SQL中卻有一個例外(應用TOP選項)。
所以要記住,不要為表中的行假設任何特定的順序。換句話說,除非你確定要有序行,否則不要指定 ORDER BY 子句。排序是需要成本的,SQL Server需要執行有序索引掃描或使用排序運行符。
以上就是一條sql的執行過程,同時我們在書寫查詢sql的時候應當遵守以下順序。
SELECT XXX FROM XXX WHERE XXX GROUP BY XXX HAVING XXX ORDER BY XXX LIMIT XXX;上面標出了各條查詢規則的執行先後順序,那麼各條查詢語句是如何執行的呢?
(1)執行FROM語句
在這些 SQL 語句的執行過程中,都會產生一個虛擬表,用來保存 SQL 語句的執行結果(這是重點),我現在就來跟蹤這個虛擬表的變化,得到最終的查詢結果的過程,來分析整個 SQL 邏輯查詢的執行順序和過程。
第一步,執行FROM語句。我們首先需要知道最開始從哪個表開始的,這就是FROM告訴我們的。現在有了 <left_table> 和 <right_table> 兩個表,我們到底從哪個表開始,還是從兩個表進行某種聯繫以後再開始呢?它們之間如何產生聯繫呢?——笛卡爾積
關於什麼是笛卡爾積,請自行 Google 補腦。經過 FROM 語句對兩個表執行笛卡爾積,會得到一個虛擬表,暫且叫VT1(vitual table 1),內容如下:
+-------------+----------+----------+-------------+
| customer_id | city | order_id | customer_id |
+-------------+----------+----------+-------------+
| 163 | hangzhou | 1 | 163 |
| 9you | shanghai | 1 | 163 |
| baidu | hangzhou | 1 | 163 |
| tx | hangzhou | 1 | 163 |
| 163 | hangzhou | 2 | 163 |
| 9you | shanghai | 2 | 163 |
| baidu | hangzhou | 2 | 163 |
| tx | hangzhou | 2 | 163 |
| 163 | hangzhou | 3 | 9you |
| 9you | shanghai | 3 | 9you |
| baidu | hangzhou | 3 | 9you |
| tx | hangzhou | 3 | 9you |
| 163 | hangzhou | 4 | 9you |
| 9you | shanghai | 4 | 9you |
| baidu | hangzhou | 4 | 9you |
| tx | hangzhou | 4 | 9you |
| 163 | hangzhou | 5 | 9you |
| 9you | shanghai | 5 | 9you |
| baidu | hangzhou | 5 | 9you |
| tx | hangzhou | 5 | 9you |
| 163 | hangzhou | 6 | tx |
| 9you | shanghai | 6 | tx |
| baidu | hangzhou | 6 | tx |
| tx | hangzhou | 6 | tx |
| 163 | hangzhou | 7 | NULL |
| 9you | shanghai | 7 | NULL |
| baidu | hangzhou | 7 | NULL |
| tx | hangzhou | 7 | NULL |
+-------------+----------+----------+-------------+總共有28(table1的記錄條數 * table2的記錄條數)條記錄。這就是VT1的結果,接下來的操作就在VT1的基礎上進行。
(2)執行ON過濾
執行完笛卡爾積以後,接著就進行ON a.customer_id = b.customer_id條件過濾,根據ON中指定的條件,去掉那些不符合條件的數據,得到VT2表,內容如下:
+-------------+----------+----------+-------------+
| customer_id | city | order_id | customer_id |
+-------------+----------+----------+-------------+
| 163 | hangzhou | 1 | 163 |
| 163 | hangzhou | 2 | 163 |
| 9you | shanghai | 3 | 9you |
| 9you | shanghai | 4 | 9you |
| 9you | shanghai | 5 | 9you |
| tx | hangzhou | 6 | tx |
+-------------+----------+----------+-------------+VT2就是經過ON條件篩選以後得到的有用數據,而接下來的操作將在VT2的基礎上繼續進行。
(3) JOIN 添加外部行
這一步只有在連接類型為OUTER JOIN時才發生,如LEFT OUTER JOIN、RIGHT OUTER JOIN和FULL OUTER JOIN。在大多數的時候,我們都是會省略掉OUTER關鍵字的,但OUTER表示的就是外部行的概念。
下麵從網上找到一張很形象的關於‘SQL JOINS'的解釋圖
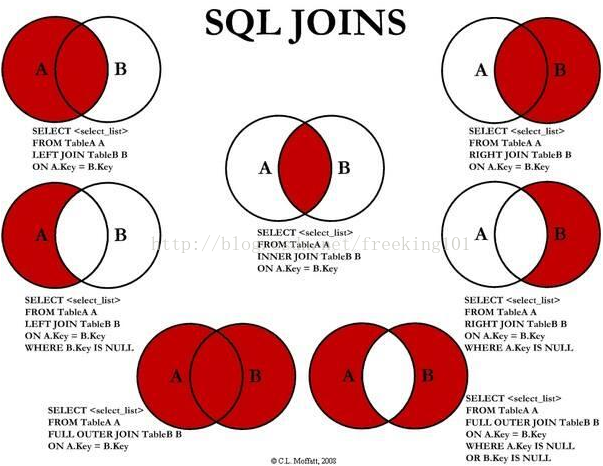
LEFT OUTER JOIN把左表記為保留表,得到的結果為:
+-------------+----------+----------+-------------+
| customer_id | city | order_id | customer_id |
+-------------+----------+----------+-------------+
| 163 | hangzhou | 1 | 163 |
| 163 | hangzhou | 2 | 163 |
| 9you | shanghai | 3 | 9you |
| 9you | shanghai | 4 | 9you |
| 9you | shanghai | 5 | 9you |
| tx | hangzhou | 6 | tx |
| baidu | hangzhou | NULL | NULL |
+-------------+----------+----------+-------------+RIGHT OUTER JOIN把右表記為保留表,得到的結果為:
+-------------+----------+----------+-------------+
| customer_id | city | order_id | customer_id |
+-------------+----------+----------+-------------+
| 163 | hangzhou | 1 | 163 |
| 163 | hangzhou | 2 | 163 |
| 9you | shanghai | 3 | 9you |
| 9you | shanghai | 4 | 9you |
| 9you | shanghai | 5 | 9you |
| tx | hangzhou | 6 | tx |
| NULL | NULL | 7 | NULL |
+-------------+----------+----------+-------------+FULL OUTER JOIN把左右表都作為保留表,得到的結果為:
+-------------+----------+----------+-------------+
| customer_id | city | order_id | customer_id |
+-------------+----------+----------+-------------+
| 163 | hangzhou | 1 | 163 |
| 163 | hangzhou | 2 | 163 |
| 9you | shanghai | 3 | 9you |
| 9you | shanghai | 4 | 9you |
| 9you | shanghai | 5 | 9you |
| tx | hangzhou | 6 | tx |
| baidu | hangzhou | NULL | NULL |
| NULL | NULL | 7 | NULL |
+-------------+----------+----------+-------------+添加外部行的工作就是在VT2表的基礎上添加保留表中被過濾條件過濾掉的數據,非保留表中的數據被賦予NULL值,最後生成虛擬表VT3。
由於我在準備的測試SQL查詢邏輯語句中使用的是LEFT JOIN,過濾掉了以下這條數據:
| baidu | hangzhou | NULL | NULL |現在就把這條數據添加到VT2表中,得到的VT3表如下:
+-------------+----------+----------+-------------+
| customer_id | city | order_id | customer_id |
+-------------+----------+----------+-------------+
| 163 | hangzhou | 1 | 163 |
| 163 | hangzhou | 2 | 163 |
| 9you | shanghai | 3 | 9you |
| 9you | shanghai | 4 | 9you |
| 9you | shanghai | 5 | 9you |
| tx | hangzhou | 6 | tx |
| baidu | hangzhou | NULL | NULL |
+-------------+----------+----------+-------------+接下來的操作都會在該VT3表上進行。
(4)執行WHERE過濾
對添加外部行得到的VT3進行WHERE過濾,只有符合
+-------------+----------+----------+-------------+
| customer_id | city | order_id | customer_id |
+-------------+----------+----------+-------------+
| 163 | hangzhou | 1 | 163 |
| 163 | hangzhou | 2 | 163 |
| tx | hangzhou | 6 | tx |
| baidu | hangzhou | NULL | NULL |
+-------------+----------+----------+-------------+但是在使用WHERE子句時,需要註意以下兩點:
由於數據還沒有分組,因此現在還不能在WHERE過濾器中使用where_condition=MIN(col)這類對分組統計的過濾;
由於還沒有進行列的選取操作,因此在SELECT中使用列的別名也是不被允許的,
如:SELECT city as c FROM t WHERE c='shanghai';是不允許出現的。
(5) 執行 GROUP BY 分組
GROU BY子句主要是對使用WHERE子句得到的虛擬表進行分組操作。我們執行測試語句中的GROUP BY a.customer_id,就會得到以下內容:
+-------------+----------+----------+-------------+
| customer_id | city | order_id | customer_id |
+-------------+----------+----------+-------------+
| 163 | hangzhou | 1 | 163 |
| baidu | hangzhou | NULL | NULL |
| tx | hangzhou | 6 | tx |
+-------------+----------+----------+-------------+得到的內容會存入虛擬表VT5中,此時,我們就得到了一個VT5虛擬表,接下來的操作都會在該表上完成。
(6) 執行HAVING過濾
HAVING子句主要和GROUP BY子句配合使用,對分組得到的VT5虛擬表進行條件過濾。當我執行測試語句中的HAVING count(b.order_id) < 2時,將得到以下內容:
+-------------+----------+----------+-------------+
| customer_id | city | order_id | customer_id |
+-------------+----------+----------+-------------+
| baidu | hangzhou | NULL | NULL |
| tx | hangzhou | 6 | tx |
+-------------+----------+----------+-------------+這就是虛擬表VT6。
(7) SELECT列表
現在才會執行到SELECT子句,不要以為SELECT子句被寫在第一行,就是第一個被執行的。
我們執行測試語句中的SELECT a.customer_id, COUNT(b.order_id) as total_orders,從虛擬表VT6中選擇出我們需要的內容。我們將得到以下內容:
+-------------+--------------+
| customer_id | total_orders |
+-------------+--------------+
| baidu | 0 |
| tx | 1 |
+-------------+--------------+不,還沒有完,這隻是虛擬表VT7。
(8)執行 DISTINCT 子句
如果在查詢中指定了DISTINCT子句,則會創建一張記憶體臨時表(如果記憶體放不下,就需要存放在硬碟了)。這張臨時表的表結構和上一步產生的虛擬表 VT7 是一樣的,不同的是對進行DISTINCT操作的列增加了一個唯一索引,以此來除重覆數據。
由於我的測試SQL語句中並沒有使用 DISTINCT,所以,在該查詢中,這一步不會生成一個虛擬表。
(9)執行 ORDER BY 子句
對虛擬表中的內容按照指定的列進行排序,然後返回一個新的虛擬表,我們執行測試SQL語句中的ORDER BY total_orders DESC,就會得到以下內容:
+-------------+--------------+
| customer_id | total_orders |
+-------------+--------------+
| tx | 1 |
| baidu | 0 |
+-------------+--------------+可以看到這是對 total_orders 列進行降序排列的。上述結果會存儲在VT8中。
(10) 執行 LIMIT 子句
LIMIT子句從上一步得到的VT8虛擬表中選出從指定位置開始的指定行數據。對於沒有應用ORDER BY的LIMIT子句,得到的結果同樣是無序的,所以,很多時候,我們都會看到LIMIT子句會和ORDER BY子句一起使用。
MySQL資料庫的LIMIT支持如下形式的選擇:
LIMIT n, m
表示從第n條記錄開始選擇m條記錄。而很多開發人員喜歡使用該語句來解決分頁問題。對於小數據,使用LIMIT子句沒有任何問題,當數據量非常大的時候,使用LIMIT n, m是非常低效的。因為LIMIT的機制是每次都是從頭開始掃描,如果需要從第60萬行開始,讀取3條數據,就需要先掃描定位到60萬行,然後再進行讀取,而掃描的過程是一個非常低效的過程。所以,對於大數據處理時,是非常有必要在應用層建立一定的緩存機制(貌似現在的大數據處理,都有緩存哦)。各位,請期待我的緩存方面的文章哦。
至此SQL的解析之旅就結束了,上圖總結一下:
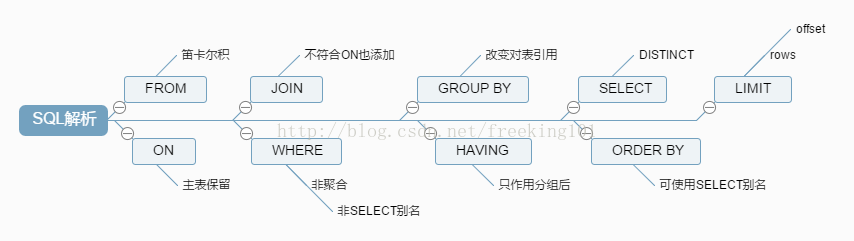
三、SQL書寫習慣
瞭解了 SQL 執行順序,那麼我們就接下來進一步養成日常 sql好習慣,也就是在實現功能同時有考慮性能的思想,資料庫是能進行集合運算的工具,我們應該儘量的利用這個工具,所謂集合運算實際就是批量運算,就是儘量減少在客戶端進行大數據量的迴圈操作,而用SQL語句或者存儲過程代替。
1.只返回需要的數據
返回數據到客戶端至少需要資料庫提取數據、網路傳輸數據、客戶端接收數據以及客戶端處理數據等環節。
如果返回不需要的數據,就會增加伺服器、網路和客戶端的無效勞動,其害處是顯而易見的,避免這類事件需要註意:
(1)橫向來看:
不要寫SELECT * 的語句,而是選擇你需要的欄位。
當在SQL語句中連接多個表時, 請使用表的別名並把別名首碼於每個Column上。這樣一來,就可以減少解析的時間並減少那些由Column歧義引起的語法錯誤。
如有表table1(ID,col1)和table2 (ID,col2)
Select A.ID, A.col1, B.col2
-- Select A.ID, col1, col2 –不要這麼寫,不利於將來程式擴展
from table1 A inner join table2 B on A.ID=B.ID Where …(2) 縱向來看
合理寫 WHERE 子句,不要寫沒有 WHERE 的 SQL 語句。SELECT TOP N * --沒有WHERE條件的用此替代
儘量少做重覆的工作。控制同一語句的多次執行,特別是一些基礎數據的多次執行是很多程式員很少註意的。
減少多次的數據轉換,也許需要數據轉換是設計的問題,但是減少次數是程式員可以做到的。
杜絕不必要的子查詢和連接表,子查詢在執行計劃一般解釋成外連接,多餘的連接錶帶來額外的開銷。
合併對同一表同一條件的多次 UPDATE,比如:
UPDATE EMPLOYEE SET FNAME='HAIWER'
WHERE EMP_ID=' VPA30890F' UPDATE EMPLOYEE SET LNAME='YANG'
WHERE EMP_ID=' VPA30890F'
-- 這兩個語句應該合併成以下一個語句
UPDATE EMPLOYEE SET FNAME='HAIWER',LNAME='YANG' WHERE EMP_ID=' VPA30890F'
UPDATE操作不要拆成DELETE操作+INSERT操作的形式,雖然功能相同,但是性能差別是很大的。2.註意 臨時表 和 表變數 的用法
在複雜系統中,臨時表和表變數很難避免,關於臨時表和表變數的用法,需要註意:
如果語句很複雜,連接太多,可以考慮用臨時表和表變數分步完成。
如果需要多次用到一個大表的同一部分數據,考慮用臨時表和表變數暫存這部分數據。
如果需要綜合多個表的數據,形成一個結果,可以考慮用臨時表和表變數分步彙總這多個表的數據。
其他情況下,應該控制臨時表和表變數的使用。
關於臨時表和表變數的選擇,很多說法是表變數在記憶體,速度快,應該首選表變數,
但是在實際使用中發現,主要考慮需要放在臨時表的數據量,在數據量較多的情況下,臨時表的速度反而更快。執行時間段與預計執行時間(多長)。
關於臨時表產生使用SELECT INTO 和 CREATE TABLE + INSERT INTO 的選擇。
一般情況下,SELECT INTO會比CREATE TABLE + INSERT INTO的方法快很多,
但是SELECT INTO會鎖定TEMPDB的系統表SYSOBJECTS、SYSINDEXES、SYSCOLUMNS,
在多用戶併發環境下,容易阻塞其他進程,
所以我的建議是,在併發系統中,儘量使用CREATE TABLE + INSERT INTO,而大數據量的單個語句使用中,使用SELECT INTO。
3.子查詢的用法
子查詢是一個 SELECT 查詢,它嵌套在 SELECT、INSERT、UPDATE、DELETE語句或其它子查詢中。
任何允許使用表達式的地方都可以使用子查詢,子查詢可以使我們的編程靈活多樣,可以用來實現一些特殊的功能。
但是在性能上,往往一個不合適的子查詢用法會形成一個性能瓶頸。
如果子查詢的條件中使用了其外層的表的欄位,這種子查詢就叫作相關子查詢。
相關子查詢可以用IN、NOT IN、EXISTS、NOT EXISTS引入。
關於相關子查詢,應該註意:
1. NOT IN、NOT EXISTS的相關子查詢可以改用LEFT JOIN代替寫法。
比如:
SELECT PUB_NAME FROM PUBLISHERS WHERE PUB_ID NOT IN (SELECT PUB_ID FROM TITLES WHERE TYPE = 'BUSINESS')
可以改寫成:
SELECT A.PUB_NAME FROM PUBLISHERS A LEFT JOIN TITLES B ON B.TYPE = 'BUSINESS' AND A.PUB_ID=B. PUB_ID WHERE B.PUB_ID IS NULL
又比如:
SELECT TITLE FROM TITLES
WHERE NOT EXISTS
(SELECT TITLE_ID FROM SALES
WHERE TITLE_ID = TITLES.TITLE_ID)
可以改寫成:
SELECT TITLE
FROM TITLES LEFT JOIN SALES
ON SALES.TITLE_ID = TITLES.TITLE_ID
WHERE SALES.TITLE_ID IS NULL
2. 如果保證子查詢沒有重覆 ,IN、EXISTS的相關子查詢可以用INNER JOIN 代替。
比如:
SELECT PUB_NAME
FROM PUBLISHERS
WHERE PUB_ID IN
(SELECT PUB_ID
FROM TITLES
WHERE TYPE = 'BUSINESS')
可以改寫成:
SELECT A.PUB_NAME --SELECT DISTINCT A.PUB_NAME
FROM PUBLISHERS A INNER JOIN TITLES B
ON B.TYPE = 'BUSINESS' AND
A.PUB_ID=B. PUB_ID
3. IN的相關子查詢用EXISTS代替
比如
SELECT PUB_NAME FROM PUBLISHERS
WHERE PUB_ID IN
(SELECT PUB_ID FROM TITLES WHERE TYPE = 'BUSINESS')
可以用下麵語句代替:
SELECT PUB_NAME FROM PUBLISHERS WHERE EXISTS
(SELECT 1 FROM TITLES WHERE TYPE = 'BUSINESS' AND
PUB_ID= PUBLISHERS.PUB_ID)
4. 不要用COUNT(*)的子查詢判斷是否存在記錄,最好用LEFT JOIN或者EXISTS
比如有人寫這樣的語句:
SELECT JOB_DESC FROM JOBS
WHERE (SELECT COUNT(*) FROM EMPLOYEE WHERE JOB_ID=JOBS.JOB_ID)=0
應該寫成:
SELECT JOBS.JOB_DESC FROM JOBS LEFT JOIN EMPLOYEE
ON EMPLOYEE.JOB_ID=JOBS.JOB_ID
WHERE EMPLOYEE.EMP_ID IS NULL
還有
SELECT JOB_DESC FROM JOBS
WHERE (SELECT COUNT(*) FROM EMPLOYEE WHERE JOB_ID=JOBS.JOB_ID)<>0
應該寫成:
SELECT JOB_DESC FROM JOBS
WHERE EXISTS (SELECT 1 FROM EMPLOYEE WHERE JOB_ID=JOBS.JOB_ID)4.儘量使用索引
建立索引後,並不是每個查詢都會使用索引,在使用索引的情況下,索引的使用效率也會有很大的差別。只要我們在查詢語句中沒有強制指定索引,索引的選擇和使用方法是SQLSERVER的優化器自動作的選擇,而它選擇的根據是查詢語句的條件以及相關表的統計信息,這就要求我們在寫SQL語句的時候儘量使得優化器可以使用索引。為了使得優化器能高效使用索引,寫語句的時候應該註意:
不要對索引欄位進行運算,而要想辦法做變換
SELECT ID FROM T WHERE NUM/2=100
應改為:
SELECT ID FROM T WHERE NUM=100*2
SELECT ID FROM T WHERE NUM/2=NUM1
如果NUM有索引應改為:
SELECT ID FROM T WHERE NUM=NUM1*2
如果NUM1有索引則不應該改。
發現過這樣的語句:
SELECT 年,月,金額 FROM 結餘表 WHERE 100*年+月=2010*100+10
應該改為:
SELECT 年,月,金額 FROM 結餘表 WHERE 年=2010 AND月=10不要對索引欄位進行格式轉換
日期欄位的例子:
WHERE CONVERT(VARCHAR(10), 日期欄位,120)='2010-07-15'
應該改為
WHERE日期欄位〉='2010-07-15' AND 日期欄位<'2010-07-16'
ISNULL轉換的例子:
WHERE ISNULL(欄位,'')<>''應改為:WHERE欄位<>''
WHERE ISNULL(欄位,'')=''不應修改
WHERE ISNULL(欄位,'F') ='T'應改為: WHERE欄位='T'
WHERE ISNULL(欄位,'F')<>'T'不應修改不要對索引欄位使用函數
WHERE LEFT(NAME, 3)='ABC' 或者WHERE SUBSTRING(NAME,1, 3)='ABC'
應改為: WHERE NAME LIKE 'ABC%'
日期查詢的例子:
WHERE DATEDIFF(DAY, 日期,'2010-06-30')=0
應改為:WHERE 日期>='2010-06-30' AND 日期 <'2010-07-01'
WHERE DATEDIFF(DAY, 日期,'2010-06-30')>0
應改為:WHERE 日期 <'2010-06-30'
WHERE DATEDIFF(DAY, 日期,'2010-06-30')>=0
應改為:WHERE 日期 <'2010-07-01'
WHERE DATEDIFF(DAY, 日期,'2010-06-30')<0
應改為:WHERE 日期>='2010-07-01'
WHERE DATEDIFF(DAY, 日期,'2010-06-30')<=0
應改為:WHERE 日期>='2010-06-30'不要對索引欄位進行多欄位連接
比如:
WHERE FAME+ '. '+LNAME='HAIWEI.YANG'
應改為:
WHERE FNAME='HAIWEI' AND LNAME='YANG'5.多表連接的連接條件
多表連接的連接條件對索引的選擇有著重要的意義,所以我們在寫連接條件的時候需要特別註意。
多表連接的時候,連接條件必須寫全,寧可重覆,不要缺漏。
連接條件儘量使用聚集索引
註意ON、WHERE和HAVING部分條件的區別
ON是最先執行,WHERE次之,HAVING最後。因為ON是先把不符合條件的記錄過濾後才進行統計,它就可以減少中間運算要處理的數據,按理說應該速度是最快的,
WHERE也應該比 HAVING快點的,因為它過濾數據後才進行SUM,在兩個表聯接時才用ON的,所以在一個表的時候,就剩下WHERE跟HAVING比較了
6.考慮聯接優先順序
INNER JOIN LEFT JOIN (註:RIGHT JOIN 用 LEFT JOIN 替代) CROSS JOIN
其它註意和瞭解的地方有
在IN後面值的列表中,將出現最頻繁的值放在最前面,出現得最少的放在最後面,減少判斷的次數
註意UNION和UNION ALL的區別。--允許重覆數據用UNION ALL好
註意使用DISTINCT,在沒有必要時不要用
7.TRUNCATE TABLE 與 DELETE 區別
相同點:
1.truncate和不帶where子句的delete、以及drop都會刪除表內的數據。
2.drop、truncate都是DDL語句(數據定義語言),執行後會自動提交。不同點:
1. truncate 和 delete 只刪除數據不刪除表的結構(定義)
drop 語句將刪除表的結構被依賴的約束(constrain)、觸發器(trigger)、索引(index);依賴於該表的存儲過程/函數將保留,但是變為 invalid 狀態。
2. delete 語句是資料庫操作語言(dml),這個操作會放到 rollback segement 中,事務提交之後才生效;如果有相應的 trigger,執行的時候將被觸發。
truncate、drop 是資料庫定義語言(ddl),操作立即生效,原數據不放到 rollback segment 中,不能回滾,操作不觸發 trigger。
3.delete 語句不影響表所占用的 extent,高水線(high watermark)保持原位置不動
drop 語句將表所占用的空間全部釋放。
truncate 語句預設情況下見空間釋放到 minextents個 extent,除非使用reuse storage;truncate 會將高水線複位(回到最開始)。
4.速度,一般來說: drop> truncate > delete
5.安全性:小心使用 drop 和 truncate,尤其沒有備份的時候.否則哭都來不及
使用上,想刪除部分數據行用 delete,註意帶上where子句. 回滾段要足夠大.
想刪除表,當然用 drop
想保留表而將所有數據刪除,如果和事務無關,用truncate即可。如果和事務有關,或者想觸發trigger,還是用delete。
如果是整理表內部的碎片,可以用truncate跟上reuse stroage,再重新導入/插入數據。
6.delete是DML語句,不會自動提交。drop/truncate都是DDL語句,執行後會自動提交。
7、TRUNCATE TABLE 在功能上與不帶 WHERE 子句的 DELETE
語句相同:二者均刪除表中的全部行。但 TRUNCATE TABLE 比 DELETE 速度快,且使用的系統和事務日誌資源少。
DELETE 語句每次刪除一行,併在事務日誌中為所刪除的每行記錄一項。
TRUNCATE TABLE 通過釋放存儲表數據所用的數據頁來刪除數據,並且只在事務日誌中記錄頁的釋放。
8、TRUNCATE TABLE 刪除表中的所有行,但表結構及其列、約束、索引等保持不變。新行標識所用的計數值重置為該列的種子。如果想保留標識計數值,請改用 DELETE。如果要刪除表定義及其數據,請使用 DROP TABLE 語句。
9、對於由 FOREIGN KEY 約束引用的表,不能使用 TRUNCATE TABLE,而應使用不帶 WHERE 子句的 DELETE 語句。由於 TRUNCATE TABLE 不記錄在日誌中,所以它不能激活觸發器。
10、TRUNCATE TABLE 不能用於參與了索引視圖的表。 
