
本次遇到的問題描述,日誌採集同步時,當單條日誌(日誌文件中一行日誌)超過2M大小,數據無法採集同步到kafka,分析後,共踩到如下幾個坑。1、flume採集時,通過shell+EXEC(tail -F xxx.log 的方式) source來獲取日誌時,當單條日誌過大超過1M時,source端無法從 ...
本次遇到的問題描述,日誌採集同步時,當單條日誌(日誌文件中一行日誌)超過2M大小,數據無法採集同步到kafka,分析後,共踩到如下幾個坑。
1、flume採集時,通過shell+EXEC(tail -F xxx.log 的方式) source來獲取日誌時,當單條日誌過大超過1M時,source端無法從日誌中獲取到Event。
2、日誌超過1M後,flume的kafka sink 作為生產者發送給日誌給kafka失敗,kafka無法收到消息。
以下針對踩的這兩個坑做分析,flume 我使用的是1.9.0版本。 kafka使用的是2.11-2.0.0版本
問題一、flume採集時,通過shell+EXEC(tail -F xxx.log 的方式) source來獲取日誌時,當單條日誌過大超過1M時,source端無法從日誌中獲取到Event。flume的配置如下:
......
agent.sources = seqGenSrc
......
# For each one of the sources, the type is defined
agent.sources.seqGenSrc.type = exec
#agent.sources.seqGenSrc.command = tail -F /opt/logs/test.log|grep businessCollection|awk -F '- {' '{print "{"$2}'
agent.sources.seqGenSrc.command = tail -F /opt/logs/test.log|grep businessCollection
agent.sources.seqGenSrc.shell = /bin/bash -c
agent.sources.seqGenSrc.batchSize = 1
agent.sources.seqGenSrc.batchTimeout = 90000
......
原因:採用shell+EXEC方式的時候,flume的源碼中使用的是如下的方式來獲取日誌
private Process process = null; //使用這種方式來執行命令。 process = Runtime.getRuntime().exec(commandArgs); //讀取日誌 reader = new BufferedReader( new InputStreamReader(process.getInputStream(), charset));
在一行日誌超過1M後,這個代碼就假死了,一直宕住,導致無法獲取到數據。
針對這個問題處理方式:
方式一:修改源碼的實現方式。(1.9.0的源碼 對應的是源碼中的flume-ng-core 項目中的org.apache.flume.source.ExecSource.java 這個類)
//process的採用如下方式獲和執行命令,就改一行代碼。增加.redirectErrorStream(true)後,輸入流就都可以獲取到,哪怕超過1M process = new ProcessBuilder(commandArgs).redirectErrorStream(true).start();
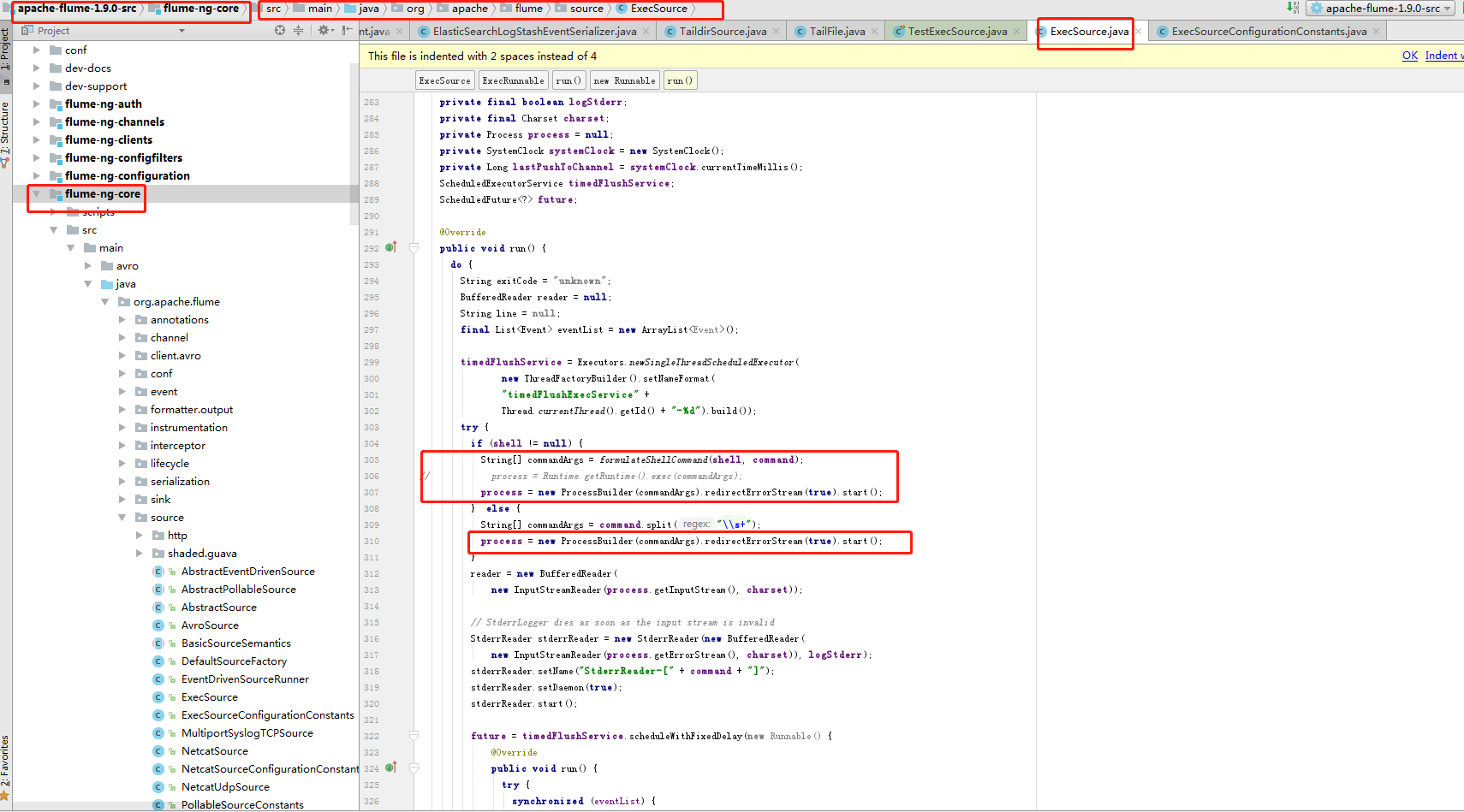
修改完成後,重新打包編譯,然後將生成的jar包替換原來老的jar包。
方式二:放棄EXECSource,使用TAILDIR Source。 使用這個source時,對應的配置如下:
...... agent.sources = seqGenSrc ...... # For each one of the sources, the type is defined agent.sources.seqGenSrc.type = TAILDIR agent.sources.seqGenSrc.positionFile = ./taildir_position.json agent.sources.seqGenSrc.filegroups = seqGenSrc agent.sources.seqGenSrc.filegroups.seqGenSrc = /opt/logs/test.log agent.sources.seqGenSrc.fileHeader = false agent.sources.seqGenSrc.batchSize = 1 ......
建議採用TAILDIR Source 比較好,這個可以對多個日誌進行監控和採集,而且日誌採集時會記錄日誌採集位置到positionFile 中,這樣日誌採集不會重覆。EXEC SOURCE在重啟採集時數據會重覆採集,還需要其他的方式去避免重覆採集
問題二、日誌超過1M後,flume的kafka sink 作為生產者發送給日誌給kafka失敗,kafka無法收到消息
原因:kafka 在預設情況下,只能接收1M大小以內的消息,在沒有做自定義設置時。所以單條消息大於1M後是無法處理的。
處理方式如下:
1)、修改kafka 服務端server.properties文件,做如下設置(修改大小限制)
# The send buffer (SO_SNDBUF) used by the socket server socket.send.buffer.bytes=502400 # The receive buffer (SO_RCVBUF) used by the socket server socket.receive.buffer.bytes=502400 # The maximum size of a request that the socket server will accept (protection against OOM) socket.request.max.bytes=104857600 message.max.bytes=5242880 replica.fetch.max.bytes=6291456
2)、修改producer.properties,做如下設置(修改大小限制)
# the maximum size of a request in bytes
max.request.size= 9242880
3)、java代碼中在初始化kafka 生產者時,也需要指定max.request.size= 9242880
Properties properties = new Properties();
...
properties.put("max.request.size", 5242880);
...
KafkaProducer<Object,Object> kafkaProducer = new KafkaProducer<Object,Object>(properties);
4)、消費者在消費kafka數據時,也需要註意設置消費消息的大小限制
Properties properties = new Properties();
...
properties.put(ConsumerConfig.FETCH_MAX_BYTES_CONFIG, 6291456);
...
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(properties);
對於flume不了的同學,可以看flume 1.9中文版用戶指南:https://www.h3399.cn/201906/700076.html
flume1.9 用戶指南 (中文版)
概述
Apache Flume 是一個分散式, 可靠且可用的系統, 用於有效地從許多不同的 source 收集, 聚合和移動大量日誌數據到集中式數據存儲.
Apache Flume 的使用不僅限於日誌數據聚合. 由於數據 source 是可定製的, 因此 Flume 可用於傳輸大量 event 數據, 包括但不限於網路流量數據, 社交媒體生成的數據, 電子郵件消息以及幾乎任何可能的數據 source.
Apache Flume 是 Apache Software Foundation 的頂級項目.
系統要求
Java 運行時環境 - Java 1.8 或更高版本
記憶體 - 為 source,channel 或 sink 配置的記憶體
磁碟空間 - channel 或 sink 配置的磁碟空間
目錄許可權 - agent 使用的目錄的讀 / 寫許可權
架構
數據流模型
Flume event 被定義為具有位元組有效負載和可選字元串屬性集的數據流單元. Flume agent 是一個 (JVM) 進程, 它承載 event 從外部 source 流向下一個目標 (躍點) 的組件.
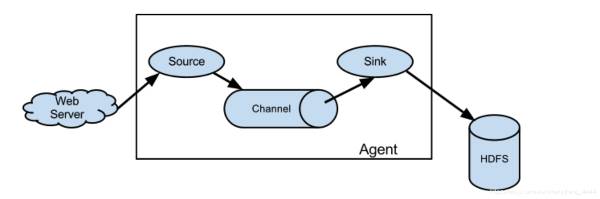

Flume source 消耗由外部 source(如 Web 伺服器)傳遞給它的 event . 外部 source 以目標 Flume source 識別的格式向 Flume 發送 event . 例如, Avro Flume source 可用於從 Avro 客戶端或從 Avrosink 發送 event 的流中的其他 Flume agent 接收 Avroevent . 可以使用 Thrift Flume Source 定義類似的流程, 以接收來自 Thrift Sink 或 Flume Thrift Rpc 客戶端或 Thrift 客戶端的 event , 這些客戶端使用 Flume thrift 協議生成的任何語言編寫. 當 Flume source 接收 event 時, 它將其存儲到一個或多個 channels . 該 channel 是一個被動存儲器, 可以保持 event 直到它被 Flume sink 消耗. 文件 channel 就是一個例子 - 它由本地文件系統支持. sink 從 channel 中移除 event 並將其放入外部存儲庫 (如 HDFS(通過 Flume HDFS sink)) 或將其轉發到流中下一個 Flume agent (下一跳)的 Flume source. 給定 agent 中的 source 和 sink 與 channel 中暫存的 event 非同步運行.
複雜的流程
Flume 允許用戶構建多跳流, 其中 event 在到達最終目的地之前經過多個 agent . 它還允許 fan-in 和 fan-out, 上下文路由和故障跳躍的備份路由(故障轉移).
可靠性
event 在每個 agent 的 channel 中進行. 然後將 event 傳遞到流中的下一個 agent 或終端存儲庫(如 HDFS). 只有將 event 存儲在下一個 agent 的 channel 或終端存儲庫中後, 才會從 channel 中刪除這些 event . 這就是 Flume 中的單跳消息傳遞語義如何提供流的端到端可靠性.
Flume 使用事務方法來保證 event 的可靠傳遞. source 和 sink 分別在事務中封裝由 channel 提供的事務中放置或提供的 event 的存儲 / 檢索. 這可確保 event 集在流中從一個點到另一個點可靠地傳遞. 在多跳流的情況下, 來自前一跳的 sink 和來自下一跳的 source 都運行其事務以確保數據安全地存儲在下一跳的 channel 中.
可恢復性
event 在 channel 中進行, 該 channel 管理從故障中恢復. Flume 支持由本地文件系統支持的持久文件 channel. 還有一個記憶體 channel, 它只是將 event 存儲在記憶體中的隊列中, 這更快, 但是當 agent 進程死亡時仍然留在記憶體 channel 中的任何 event 都無法恢復.
設置
設置 agent
Flume agent 配置存儲在本地配置文件中. 這是一個遵循 Java 屬性文件格式的文本文件. 可以在同一配置文件中指定一個或多個 agent 的配置. 配置文件包括 agent 中每個 source,sink 和 channel 的屬性以及它們如何連接在一起以形成數據流.
配置單個組件
流中的每個組件 (source,sink 或 channel) 都具有特定於類型和實例化的名稱, 類型和屬性集. 例如, Avrosource 需要主機名 (或 IP 地址) 和埠號來接收數據. 記憶體 channel 可以具有最大隊列大小 ("容量"),HDFS sink 需要知道文件系統 URI, 創建文件的路徑, 文件輪換頻率("hdfs.rollInterval") 等. 組件的所有此類屬性需要在托管 Flume agent 的屬性文件中設置.
將各個部分連接在一起
agent 需要知道要載入哪些組件以及它們如何連接以構成流程. 這是通過列出 agent 中每個 source,sink 和 channel 的名稱, 然後為每個 sink 和 source 指定連接 channel 來完成的. 例如, agent 通過名為 file-channel 的文件 channel 將 event 從名為 avroWeb 的 Avrosource 流向 HDFS sink hdfs-cluster1. 配置文件將包含這些組件的名稱和文件 channel, 作為 avroWebsource 和 hdfs-cluster1 sink 的共用 channel.
啟動 agent
使用名為 flume-ng 的 shell 腳本啟動 agent 程式, 該腳本位於 Flume 發行版的 bin 目錄中. 您需要在命令行上指定 agent 名稱, config 目錄和配置文件:
$ bin/flume-ng agent -n $agent_name -c conf -f conf/flume-conf.properties.template
現在, agent 將開始運行在給定屬性文件中配置的 source 和 sink.
一個簡單的例子
在這裡, 我們給出一個示例配置文件, 描述單節點 Flume 部署. 此配置允許用戶生成 event , 然後將其記錄到控制台.
# example.conf: A single-node Flume configuration # Name the components on this agent a1.sources = r1 a1.sinks = k1 a1.channels = c1 # Describe/configure the source a1.sources.r1.type = netcat a1.sources.r1.bind = localhost a1.sources.r1.port = 44444 # Describe the sink a1.sinks.k1.type = logger # Use a channel which buffers events in memory a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100 # Bind the source and sink to the channel a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1
此配置定義名為 a1 的單個 agent .a1 有一個監聽埠 44444 上的數據的 source, 一個緩衝記憶體中 event 數據的 channel, 以及一個將 event 數據記錄到控制台的 sink. 配置文件命名各種組件, 然後描述其類型和配置參數. 給定的配置文件可能會定義幾個命名的 agent 當一個給定的 Flume 進程啟動時, 會傳遞一個標誌, 告訴它要顯示哪個命名 agent.
鑒於此配置文件, 我們可以按如下方式啟動 Flume:
$ bin/flume-ng agent --conf conf --conf-file example.conf --name a1 -Dflume.root.logger=INFO,console
請註意, 在完整部署中, 我們通常會包含一個選項: --conf=<conf-dir> . 所述 <conf-dir> 目錄將包括一個 shell 腳本 f lume-env.sh 和潛在的一個 log4j 的屬性文件. 在這個例子中, 我們傳遞一個 Java 選項來強制 Flume 登錄到控制台, 我們沒有自定義環境腳本.
從一個單獨的終端, 我們可以 telnet 埠 44444 並向 Flume 發送一個 event :
$ telnet localhost 44444 Trying 127.0.0.1... Connected to localhost.localdomain (127.0.0.1). Escape character is '^]'. Hello world! <ENTER> OK
原始的 Flume 終端將在日誌消息中輸出 event .
12/06/19 15:32:19 INFO source.NetcatSource: Source starting
12/06/19 15:32:19 INFO source.NetcatSource: Created serverSocket:sun.nio.ch.ServerSocketChannelImpl[/127.0.0.1:44444]
12/06/19 15:32:34 INFO sink.LoggerSink: Event: {
headers:{
} body: 48 65 6C 6C 6F 20 77 6F 72 6C 64 21 0D Hello world!.
}
恭喜 - 您已成功配置並部署了 Flume agent ! 後續部分更詳細地介紹了 agent 配置.
在配置文件中使用環境變數
Flume 能夠替換配置中的環境變數. 例如:
a1.sources = r1
a1.sources.r1.type = netcat
a1.sources.r1.bind = 0.0.0.0
a1.sources.r1.port = ${
NC_PORT
}
a1.sources.r1.channels = c1
註意: 它目前僅適用於 values , 不適用於 keys . (IE. only on the "right side" of the = mark of the config lines.)
通過設置 propertiesImplementation = org.apache.flume.node.EnvVarResolverProperties, 可以通過 agent 程式調用上的 Java 系統屬性啟用此功能.
例如:
$ NC_PORT=44444 bin/flume-ng agent -conf conf -conf-file example.conf -name a1 -Dflume.root.logger=INFO,console -DpropertiesImplementation=org.apache.flume.node.EnvVarResolverProperties
請註意, 上面只是一個示例, 可以通過其他方式配置環境變數, 包括在 conf/flume-env.sh.
記錄原始數據
在許多生產環境中記錄流經攝取 pipeline 的原始數據流不是所希望的行為, 因為這可能導致泄漏敏感數據或安全相關配置 (例如密鑰) 泄漏到 Flume 日誌文件. 預設情況下, Flume 不會記錄此類信息. 另一方面, 如果數據管道被破壞, Flume 將嘗試提供調試 DEBUG 的線索.
調試 event 管道問題的一種方法是設置 連接到 Logger Sink 的附加記憶體 channel, 它將所有 event 數據輸出到 Flume 日誌. 但是, 在某些情況下, 這種方法是不夠的.
為了能夠記錄 event 和配置相關的數據, 除了 log4j 屬性外, 還必須設置一些 Java 系統屬性.
要啟用與配置相關的日誌記錄, 請設置 Java 系統屬性 - Dorg.apache.flume.log.printconfig=true . 這可以在命令行上傳遞, 也可以在 flume-env.sh 中的 JAVA_OPTS 變數中設置.
要啟用數據記錄, 請 按照上述相同方式設置 Java 系統屬性 -Dorg.apache.flume.log.rawdata=true . 對於大多數組件, 還必須將 log4j 日誌記錄級別設置為 DEBUG 或 TRACE, 以使特定於 event 的日誌記錄顯示在 Flume 日誌中.
下麵是啟用配置日誌記錄和原始數據日誌記錄的示例, 同時還將 Log4j 日誌級別設置為 DEBUG 以用於控制台輸出:
$ bin/flume-ng agent --conf conf --conf-file example.conf --name a1 -Dflume.root.logger=DEBUG,console -Dorg.apache.flume.log.printconfig=true -Dorgwdata=true
基於 Zookeeper 的配置
Flume 通過 Zookeeper 支持 agent 配置. 這是一個實驗性功能. 配置文件需要在可配置首碼下的 Zookeeper 中上傳. 配置文件存儲在 Zookeeper 節點數據中. 以下是 agent 商 a1 和 a2 的 Zookeeper 節點樹的外觀
- /flume |- /a1 [Agent config file] |- /a2 [Agent config file]
上傳配置文件後, 使用以下選項啟動 agent
$ bin/flume-ng agent -conf conf -z zkhost:2181,zkhost1:2181 -p /flume -name a1 -Dflume.root.logger=INFO,console
| Argument Name | Default | Description |
|---|---|---|
| z | – | Zookeeper 連接字元串。以逗號分隔的主機名列表:port |
| p | /flume | Zookeeper 中的基本路徑,用於存儲 agent 配置 |
Flume 擁有完全基於插件的架構. 雖然 Flume 附帶了許多開箱即用的 source,channels,sink,serializers 等, 但許多實現都與 Flume 分開運行. 安裝第三方插件
雖然通過將自己的 jar 包添加到 flume-env.sh 文件中的 FLUME_CLASSPATH 變數中, 始終可以包含自定義 Flume 組件, 但 Flume 現在支持一個名為 plugins.d 的特殊目錄, 該目錄會自動獲取以特定格式打包的插件. 這樣可以更輕鬆地管理插件打包問題, 以及更簡單的調試和幾類問題的故障排除, 尤其是庫依賴性衝突.
目錄
該 plugins.d 目錄位於 $FLUME_HOME/plugins.d . 在啟動時, flume-ng 啟動腳本在 plugins.d 目錄中查找符合以下格式的插件, 併在啟動 java 時將它們包含在正確的路徑中.
插件的目錄佈局
plugins.d 中的每個插件 (子目錄) 最多可以有三個子目錄:
lib - the plugin's jar(s) libext - the plugin's dependency jar(s) native - any required native libraries, such as .so files
plugins.d 目錄中的兩個插件示例:
plugins.d/ plugins.d/custom-source-1/ plugins.d/custom-source-1/lib/my-source.jar plugins.d/custom-source-1/libext/spring-core-2.5.6.jar plugins.d/custom-source-2/ plugins.d/custom-source-2/lib/custom.jar plugins.d/custom-source-2/native/gettext.so
數據攝取
Flume 支持許多從外部來 source 攝取數據的機制.
RPC
Flume 發行版中包含的 Avro 客戶端可以使用 avro RPC 機制將給定文件發送到 Flume Avrosource:
$ bin/flume-ng avro-client -H localhost -p 41414 -F /usr/logs/log.10
上面的命令會將 /usr/logs/log.10 的內容發送到監聽該埠的 Flume source.
執行命令
有一個 exec source 執行給定的命令並消耗輸出. 輸出的單 "行" 即. 文本後跟回車符 ('\ r') 或換行符 ('\ n') 或兩者一起.
網路流
Flume 支持以下機制從常用日誌流類型中讀取數據, 例如:
- Avro
- Thrift
- Syslog
- Netcat
設置多 agent 流程


為了跨多個 agent 或跳數據流, 先前 agent 的 sink 和當前跳的 source 需要是 avro 類型, sink 指向 source 的主機名 (或 IP 地址) 和埠.
合併
日誌收集中非常常見的情況是大量日誌生成客戶端將數據發送到連接到存儲子系統的少數消費者 agent . 例如, 從數百個 Web 伺服器收集的日誌發送給寫入 HDFS 集群的十幾個 agent .
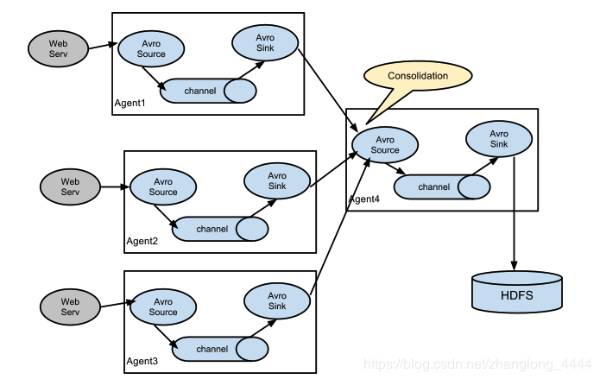

這可以通過使用 avrosink 配置多個第一層 agent 在 Flume 中實現, 所有這些 agent 都指向單個 agent 的 avrosource(同樣, 您可以在這種情況下使用 thriftsource/sink / 客戶端). 第二層 agent 上的此 source 將接收的 event 合併到單個通道中, 該通道由信宿器消耗到其最終目的地.
多路復用流程
Flume 支持將 event 流多路復用到一個或多個目的地. 這是通過定義可以複製或選擇性地將 event 路由到一個或多個通道的流復用器來實現的.
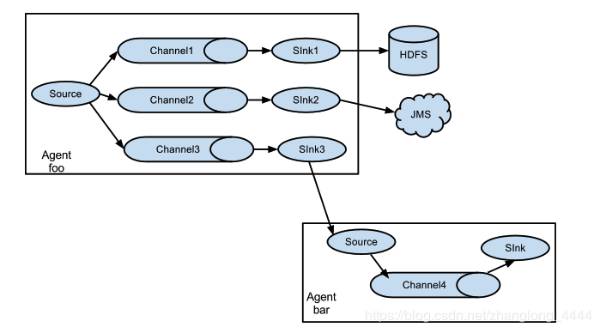

上面的例子顯示了來自 agent "foo" 的 source 代碼將流程擴展到三個不同的 channel. 扇出可以複製或多路復用. 在複製流的情況下, 每個 event 被髮送到所有三個 channel. 對於多路復用情況, 當 event 的屬性與預配置的值匹配時, event 將被傳遞到可用 channel 的子集. 例如, 如果一個名為 "txnType" 的 event 屬性設置為 "customer", 那麼它應該轉到 channel1 和 channel3, 如果它是 "vendor", 那麼它應該轉到 channel2, 否則轉到 channel3. 可以在 agent 的配置文件中設置映射.
配置
如前面部分所述, Flume agent 程式配置是從類似於具有分層屬性設置的 Java 屬性文件格式的文件中讀取的.
定義流程
要在單個 agent 中定義流, 您需要通過 channel 鏈接 source 和 sink. 您需要列出給定 agent 的 source,sink 和 channel, 然後將 source 和 sink 指向 channel.source 實例可以指定多個 channel, 但 sink 實例只能指定一個 channel. 格式如下:
# list the sources, sinks and channels for the agent <Agent>.sources = <Source> <Agent>.sinks = <Sink> <Agent>.channels = <Channel1> <Channel2> # set channel for source <Agent>.sources.<Source>.channels = <Channel1> <Channel2> ... # set channel for sink <Agent>.sinks.<Sink>.channel = <Channel1>
例如, 名為 agent_foo 的 agent 正在從外部 avro 客戶端讀取數據並通過記憶體 channel 將其發送到 HDFS.
配置文件 weblog.config 可能如下所示:
# list the sources, sinks and channels for the agent agent_foo.sources = avro-appserver-src-1 agent_foo.sinks = hdfs-sink-1 agent_foo.channels = mem-channel-1 # set channel for source agent_foo.sources.avro-appserver-src-1.channels = mem-channel-1 # set channel for sink agent_foo.sinks.hdfs-sink-1.channel = mem-channel-1
這將使 event 從 avro-AppSrv-source 流向 hdfs-Cluster1-sink, 通過記憶體 channelmem-channel-1.
當使用 weblog.config 作為其配置文件啟動 agent 程式時, 它將實例化該流程.
配置單個組件
定義流後, 您需要設置每個 source,sink 和 channel 的屬性. 這是以相同的分層命名空間方式完成的, 您可以在其中設置組件類型以及特定於每個組件的屬性的其他值:
# properties for sources <Agent>.sources.<Source>.<someProperty> = <someValue> # properties for channels <Agent>.channel.<Channel>.<someProperty> = <someValue> # properties for sinks <Agent>.sources.<Sink>.<someProperty> = <someValue>
需要為 Flume 的每個組件設置屬性 "type", 以瞭解它需要什麼類型的對象. 每個 source,sink 和 channel 類型都有自己的一組屬性, 使其能夠按預期運行. 所有這些都需要根據需要進行設置. 在前面的示例中, 我們有一個從 avro-AppSrv-source 到 hdfs-Cluster1-sink 的流程通過記憶體 channelmem-channel-1. 這是一個顯示每個組件配置的示例:
agent_foo.sources = avro-AppSrv-source agent_foo.sinks = hdfs-Cluster1-sink agent_foo.channels = mem-channel-1 # set channel for sources, sinks # properties of avro-AppSrv-source agent_foo.sources.avro-AppSrv-source.type = avro agent_foo.sources.avro-AppSrv-source.bind = localhost agent_foo.sources.avro-AppSrv-source.port = 10000 # properties of mem-channel-1 agent_foo.channels.mem-channel-1.type = memory agent_foo.channels.mem-channel-1.capacity = 1000 agent_foo.channels.mem-channel-1.transactionCapacity = 100 # properties of hdfs-Cluster1-sink agent_foo.sinks.hdfs-Cluster1-sink.type = hdfs agent_foo.sinks.hdfs-Cluster1-sink.hdfs.path = hdfs://namenode/flume/webdata #...
在 agent 中添加多個流
單個 Flume agent 可以包含多個獨立流. 您可以在配置中列出多個 source,sink 和 channel. 可以鏈接這些組件以形成多個流:
# list the sources, sinks and channels for the agent <Agent>.sources = <Source1> <Source2> <Agent>.sinks = <Sink1> <Sink2> <Agent>.channels = <Channel1> <Channel2>
然後, 您可以將 source 和 sink 鏈接到 channel(用於 sink)的相應 channel(用於 source), 以設置兩個不同的流. 例如, 如果您需要在 agent 中設置兩個流, 一個從外部 avro 客戶端到外部 HDFS, 另一個從尾部輸出到 avrosink, 那麼這是一個配置來執行此操作:
# list the sources, sinks and channels in the agent agent_foo.sources = avro-AppSrv-source1 exec-tail-source2 agent_foo.sinks = hdfs-Cluster1-sink1 avro-forward-sink2 agent_foo.channels = mem-channel-1 file-channel-2 # flow #1 configuration agent_foo.sources.avro-AppSrv-source1.channels = mem-channel-1 agent_foo.sinks.hdfs-Cluster1-sink1.channel = mem-channel-1 # flow #2 configuration agent_foo.sources.exec-tail-source2.channels = file-channel-2 agent_foo.sinks.avro-forward-sink2.channel = file-channel-2
配置多 agent 流程
要設置多層流, 您需要有 sink 指向下一跳的 avro/thrift source. 這將導致第一個 Flume agent 將 event 轉發到下一個 Flume agent . 例如, 如果您使用 avro 客戶端定期向本地 Flume agent 發送文件(每個 event 1 個文件), 則此本地 agent 可以將其轉發到另一個已安裝存儲的 agent
Weblog agent 配置:
# list sources, sinks and channels in the agent agent_foo.sources = avro-AppSrv-source agent_foo.sinks = avro-forward-sink agent_foo.channels = file-channel # define the flow agent_foo.sources.avro-AppSrv-source.channels = file-channel agent_foo.sinks.avro-forward-sink.channel = file-channel # avro sink properties agent_foo.sinks.avro-forward-sink.type = avro agent_foo.sinks.avro-forward-sink.hostname = 10.1.1.100 agent_foo.sinks.avro-forward-sink.port = 10000 # configure other pieces #...
HDFS agent 配置:
# list sources, sinks and channels in the agent agent_foo.sources = avro-collection-source agent_foo.sinks = hdfs-sink agent_foo.channels = mem-channel # define the flow agent_foo.sources.avro-collection-source.channels = mem-channel agent_foo.sinks.hdfs-sink.channel = mem-channel # avro source properties agent_foo.sources.avro-collection-source.type = avro agent_foo.sources.avro-collection-source.bind = 10.1.1.100 agent_foo.sources.avro-collection-source.port = 10000 # configure other pieces #...
在這裡, 我們將 weblog agent 的 avro-forward-sink 鏈接到 hdfs agent 的 avro-collection-source. 這將導致來自外部應用程式伺服器 source 的 event 最終存儲在 HDFS 中.
扇出流量
如前一節所述, Flume 支持扇出從一個 source 到多個 channel 的流量. 扇出有兩種模式 : 複製和多路復用. 在複製流程中, event 將發送到所有已配置的 channel. 在多路復用的情況下, event 僅被髮送到合格 channels 的子集. 為了散開流量, 需要指定 source 的 channel 列表以及扇出它的策略. 這是通過添加可以複製或多路復用的 channel"選擇器" 來完成的. 如果它是多路復用器, 則進一步指定選擇規則. 如果您沒有指定選擇器, 那麼預設情況下它會複製:
# List the sources, sinks and channels for the agent <Agent>.sources = <Source1> <Agent>.sinks = <Sink1> <Sink2> <Agent>.channels = <Channel1> <Channel2> # set list of channels for source (separated by space) <Agent>.sources.<Source1>.channels = <Channel1> <Channel2> # set channel for sinks <Agent>.sinks.<Sink1>.channel = <Channel1> <Agent>.sinks.<Sink2>.channel = <Channel2> <Agent>.sources.<Source1>.selector.type = replicating
多路復用選擇具有另一組屬性以分流流. 這需要指定 event 屬性到 channel 集的映射. 選擇器檢查 event 頭中的每個已配置屬性. 如果它與指定的值匹配, 則該 event 將發送到映射到該值的所有 channel. 如果沒有匹配項, 則將 event 發送到配置為預設值的 channel 集:
# Mapping for multiplexing selector <Agent>.sources.<Source1>.selector.type = multiplexing <Agent>.sources.<Source1>.selector.header = <someHeader> <Agent>.sources.<Source1>.selector.mapping.<Value1> = <Channel1> <Agent>.sources.<Source1>.selector.mapping.<Value2> = <Channel1> <Channel2> <Agent>.sources.<Source1>.selector.mapping.<Value3> = <Channel2> #... <Agent>.sources.<Source1>.selector.default = <Channel2>
映射允許為每個值重疊 channel.
以下示例具有多路復用到兩個路徑的單個流. 名為 agent_foo 的 agent 具有單個 avrosource 和兩個鏈接到兩個 sink 的 channel:
# list the sources, sinks and channels in the agent agent_foo.sources = avro-AppSrv-source1 agent_foo.sinks = hdfs-Cluster1-sink1 avro-forward-sink2 agent_foo.channels = mem-channel-1 file-channel-2 # set channels for source agent_foo.sources.avro-AppSrv-source1.channels = mem-channel-1 file-channel-2 # set channel for sinks agent_foo.sinks.hdfs-Cluster1-sink1.channel = mem-channel-1 agent_foo.sinks.avro-forward-sink2.channel = file-channel-2 # channel selector configuration agent_foo.sources.avro-AppSrv-source1.selector.type = multiplexing agent_foo.sources.avro-AppSrv-source1.selector.header = State agent_foo.sources.avro-AppSrv-source1.selector.mapping.CA = mem-channel-1 agent_foo.sources.avro-AppSrv-source1.selector.mapping.AZ = file-channel-2 agent_foo.sources.avro-AppSrv-source1.selector.mapping.NY = mem-channel-1 file-channel-2 agent_foo.sources.avro-AppSrv-source1.selector.default = mem-channel-1
選擇器檢查名為 "State" 的標頭. 如果該值為 "CA", 則將其發送到 mem-channel-1, 如果其為 "AZ", 則將其發送到文件 channel-2, 或者如果其為 "NY" 則為兩者. 如果 "狀態" 標題未設置或與三者中的任何一個都不匹配, 則它將轉到 mem-channel-1, 其被指定為 "default".
選擇器還支持可選 channel. 要為標頭指定可選 channel, 可通過以下方式使用 config 參數 "optional":
# channel selector configuration agent_foo.sources.avro-AppSrv-source1.selector.type = multiplexing agent_foo.sources.avro-AppSrv-source1.selector.header = State agent_foo.sources.avro-AppSrv-source1.selector.mapping.CA = mem-channel-1 agent_foo.sources.avro-AppSrv-source1.selector.mapping.AZ = file-channel-2 agent_foo.sources.avro-AppSrv-source1.selector.mapping.NY = mem-channel-1 file-channel-2 agent_foo.sources.avro-AppSrv-source1.selector.optional.CA = mem-channel-1 file-channel-2 agent_foo.sources.avro-AppSrv-source1.selector.mapping.AZ = file-channel-2 agent_foo.sources.avro-AppSrv-source1.selector.default = mem-channel-1
選擇器將首先嘗試寫入所需的 channel, 如果其中一個 channel 無法使用 event , 則會使事務失敗. 在所有渠道上重新嘗試交易. 一旦所有必需的 channel 消耗了 event , 則選擇器將嘗試寫入可選 channel. 任何可選 channel 使用該 event 的失敗都會被忽略而不會重試.
如果可選通道與特定報頭的所需通道之間存在重疊, 則認為該通道是必需的, 並且通道中的故障將導致重試所有必需通道集. 例如, 在上面的示例中, 對於標題 "CA",mem-channel-1 被認為是必需的 channel, 即使它被標記為必需和可選, 並且寫入此 channel 的失敗將導致該 event 在為選擇器配置的所有 channel 上重試.
請註意, 如果標頭沒有任何所需的 channel, 則該 event 將被寫入預設 channel, 並將嘗試寫入該標頭的可選 channel. 如果未指定所需的 channel, 則指定可選 channel 仍會將 event 寫入預設 channel. 如果沒有將 channel 指定為預設 channel 且沒有必需 channel, 則選擇器將嘗試將 event 寫入可選 channel. 在這種情況下, 任何失敗都會被忽略.
支持
多個 Flume 組件支持 SSL / TLS 協議, 以便安全地與其他系統通信.
| Component | SSL server or client |
|---|---|
| Avro Source | server |
| Avro Sink | client |
| Thrift Source | server |
| Thrift Sink | client |
| Kafka Source | client |
| Kafka Channel | client |
| Kafka Sink | client |
| HTTP Source | server |
| JMS Source | client |
| Syslog TCP Source | server |
| Multiport Syslog TCP Source | server |
SSL 相容組件具有若幹配置參數來設置 SSL, 例如啟用 SSL 標誌, 密鑰庫 / 信任庫參數 (位置, 密碼, 類型) 和其他 SSL 參數(例如禁用的協議)
始終在 agent 配置文件的組件級別指定為組件啟用 SSL. 因此, 某些組件可能配置為使用 SSL, 而其他組件則不配置(即使具有相同的組件類型)
密鑰庫 / 信任庫設置可以在組件級別或全局指定.
在組件級別設置的情況下, 通過組件特定參數在 agent 配置文件中配置密鑰庫 / 信任庫. 此方法的優點是組件可以使用不同的密鑰庫(如果需要). 缺點是必須為 agent 配置文件中的每個組件複製密鑰庫參數. 組件級別設置是可選的, 但如果已定義, 則其優先順序高於全局參數.
使用全局設置, 只需定義一次密鑰庫 / 信任庫參數, 並對所有組件使用相同的設置, 這意味著更少和更集中的配置.
可以通過系統屬性或通過環境變數來配置全局設置.
| 系統屬性 | 環境變數 | 描述 |
|---|---|---|
| javax.net.ssl.keyStore | FLUME_SSL_KEYSTORE_PATH | 密鑰庫位置 |
| javax.net.ssl.keyStorePassword | FLUME_SSL_KEYSTORE_PASSWORD | 密鑰庫密碼 |
| javax.net.ssl.keyStoreType | FLUME_SSL_KEYSTORE_TYPE | 密鑰庫類型(預設為 JKS) |
| javax.net.ssl.trustStore | FLUME_SSL_TRUSTSTORE_PATH | 信任庫位置 |
| javax.net.ssl.trustStorePassword | FLUME_SSL_TRUSTSTORE_PASSWORD | 信任庫密碼 |
| javax.net.ssl.trustStoreType | FLUME_SSL_TRUSTSTORE_TYPE | 信任庫類型(預設為 JKS) |
| flume.ssl.include.protocols | FLUME_SSL_INCLUDE_PROTOCOLS | 計算啟用的協議時要包括的協議。逗號(,)分隔列表。如果提供,排除的協議將從此列表中排除。 |
| flume.ssl.exclude.protocols | FLUME_SSL_EXCLUDE_PROTOCOLS | 計算啟用的協議時要排除的協議。逗號(,)分隔列表。 |
| flume.ssl.include.cipherSuites | FLUME_SSL_INCLUDE_CIPHERSUITES | 在計算啟用的密碼套件時包含的密碼套件。逗號(,)分隔列表。如果提供,排除的密碼套件將被排除在此列表之外。 |
| flume.ssl.exclude.cipherSuites | FLUME_SSL_EXCLUDE_CIPHERSUITES | 在計算啟用的密碼套件時要排除的密碼套件。逗號(,)分隔列表。 |
可以在命令行上傳遞 SSL 系統屬性, 也可以在 conf / flume-env.sh 中設置 JAVA_OPTS 環境變數(儘管使用命令行是不可取的, 因為包含密碼的命令將保存到命令歷史記錄中.)
export JAVA_OPTS="$JAVA_OPTS -Djavax.net.ssl.keyStore=/path/to/keystore.jks" export JAVA_OPTS="$JAVA_OPTS -Djavax.net.ssl.keyStorePassword=password"
Flume 使用 JSSE(Java 安全套接字擴展)中定義的系統屬性, 因此這是設置 SSL 的標準方法. 另一方面, 在系統屬性中指定密碼意味著可以在進程列表中看到密碼. 對於不可接受的情況, 也可以在環境變數中定義參數. 在這種情況下, Flume 在內部從相應的環境變數初始化 JSSE 系統屬性.
SSL 環境變數可以在啟動 Flume 之前在 shell 環境中設置, 也可以在 conf / flume-env.sh 中設置(儘管使用命令行是不可取的, 因為包含密碼的命令將保存到命令歷史記錄中.)
export FLUME_SSL_KEYSTORE_PATH=/path/to/keystore.jks
export FLUME_SSL_KEYSTORE_PASSWORD=password
** 請註意:**
必須在組件級別啟用 SSL. 僅指定全局 SSL 參數不會產生任何影響.
如果在多個級別指定全局 SSL 參數, 則優先順序如下(從高到低):
agent 配置中的組件參數
系統屬性
環境變數
如果為組件啟用了 SSL, 但未以上述任何方式指定 SSL 參數, 則
在密鑰庫的情況下: 配置錯誤
在 truststores 的情況下: 將使用預設信任庫(Oracle JDK 中的 jssecacerts / cacerts)
在所有情況下, 可信任密碼都是可選的. 如果未指定, 則在 JDK 打開信任庫時, 不會對信任庫執行完整性檢查.
source 和接收批量大小和 channel 事務容量
source 和 sink 可以具有批量大小參數, 該參數確定它們在一個批次中處理的最大 event 數. 這發生在具有稱為事務容量的上限的 channel 事務中. 批量大小必須小於渠道的交易容量. 有一個明確的檢查, 以防止不相容的設置. 只要讀取配置, 就會進行此檢查.
- Flume Source
- Avro Source
監聽 Avro 埠並從外部 Avro 客戶端流接收 event . 當與另一個(上一跳)Flume agent 上的內置 Avro Sink 配對時, 它可以創建分層集合拓撲. 必需屬性以粗體顯示
| 屬性名稱 | 預設 | 描述 |
|---|---|---|
| channels | - | |
| type | - | 組件類型名稱,需要是 avro |
| bind | - | 要偵聽的主機名或 IP 地址 |
| port | - | 要綁定的埠號 |
| threads | - | 生成的最大工作線程數 |
| selector.type | ||
| selector.* | ||
| interceptors | - | 以空格分隔的攔截器列表 |
| interceptors.* | ||
| compression-type | none | 這可以是 “none” 或“deflate”。壓縮類型必須與匹配 AvroSource 的壓縮類型匹配 |
| SSL | false | 將其設置為 true 以啟用 SSL 加密。如果啟用了 SSL,則還必須通過組件級參數(請參閱下文)或全局 SSL 參數(請參閱 SSL / TLS 支持部分)指定 “密鑰庫” 和“密鑰庫密碼” 。 |
| keysore | - | 這是 Java 密鑰庫文件的路徑。如果未在此處指定,則將使用全局密鑰庫(如果已定義,則配置錯誤)。 |
| keystore-password | - | Java 密鑰庫的密碼。如果未在此處指定,則將使用全局密鑰庫密碼(如果已定義,則配置錯誤)。 |
| keystore-type | JKS | Java 密鑰庫的類型。這可以是 “JKS” 或“PKCS12”。如果未在此處指定,則將使用全局密鑰庫類型(如果已定義,則預設為 JKS)。 |
| exclude-protocols | SSLv3 | 要排除的以空格分隔的 SSL / TLS 協議列表。除指定的協議外,將始終排除 SSLv3。 |
| include-protocols | - | 要包含的以空格分隔的 SSL / TLS 協議列表。啟用的協議將是包含的協議,沒有排除的協議。如果包含協議為空,則它包括每個支持的協議。 |
| exclude-cipher-suites | - | 要排除的以空格分隔的密碼套件列表。 |
| include-cipher-suites | - | 以空格分隔的密碼套件列表。啟用的密碼套件將是包含的密碼套件,不包括排除的密碼套件。如果 included-cipher-suites 為空,則包含每個支持的密碼套件。 |
| ipFilter | false | 將此設置為 true 以啟用 ipFiltering for netty |
| ipFilterRules | - | 使用此配置定義 N netty ipFilter 模式規則。 |
agent 名為 a1 的示例:
a1.sources = r1 a1.channels = c1 a1.sources.r1.type = avro a1.sources.r1.channels = c1 a1.sources.r1.bind = 0.0.0.0 a1.sources.r1.port = 4141
ipFilterRules 的示例
ipFilterRules 定義由逗號分隔的 N 個 netty ipFilters 模式規則必須採用此格式.
<'allow' or deny>:<'ip' or 'name' for computer name>:<pattern> or allow/deny:ip/name:pattern example: ipFilterRules=allow:ip:127.*,allow:name:localhost,deny:ip:*
請註意, 匹配的第一個規則將適用, 如下例所示, 來自 localhost 上的客戶端
這將允許 localhost 上的客戶端拒絕來自任何其他 ip 的客戶端 "allow:name:localhost,deny:ip: 這將拒絕 localhost 上的客戶端允許來自任何其他 ip 的客戶端"deny:name:localhost,allow:ip:
Thrift Sou


