
背景介紹 JSF(京東服務框架,類似dubbo)預設配置了可伸縮的最大到200的工作線程池,每一個向外提供的服務都在其中運行(這裡我們是服務端),這些服務內部調用外部依賴時(這裡我們是客戶端)一般是同步調用,不單獨限制調用併發量,因為同步調用時會阻塞原服務線程,因此實際上所有外部調用共用了JSF的2 ...
背景介紹
JSF(京東服務框架,類似dubbo)預設配置了可伸縮的最大到200的工作線程池,每一個向外提供的服務都在其中運行(這裡我們是服務端),這些服務內部調用外部依賴時(這裡我們是客戶端)一般是同步調用,不單獨限制調用併發量,因為同步調用時會阻塞原服務線程,因此實際上所有外部調用共用了JSF的200工作線程池。
Hystrix框架為了隔離依賴相互影響,預設使用了線程隔離機制,為每個依賴提供一個小的線程池,如果該線程池已滿新的調用將被立即拒絕,預設不排隊加快失敗返回。這與JSF原來的機制非常不一樣,我們的問題是:
額外的線程池是否有太大的性能開銷?
線程池大小設置多少合理?
希望通過本次測試調研得到答案。
用例介紹
構造兩個介面,分別調用原生mock方法和調用經過hystrix包裝的mock方法,兩個mock方法內部都是一個Thread.sleep,根據不同參數模擬不同性能的外部依賴調用。其中JSF線程池為預設值最大200,hystrix單個線程池大小為預設值10,預設超時1000ms,為了排除干擾禁用斷路器。根據兩個介面、不同mock參數和不同壓測線程數組合構造出共11個測試用例。
部署單台只包括這兩個介面的生產機器,使用分散式壓測平臺(多台Jmeter)對其進行壓測,主要通過介面內部的UMP進行性能和JVM狀態監控,JVM使用JDK8並且開啟G1收集器(壓測中無full gc)。
@Service
public class MockJsfServiceRef {
@HystrixCommand(commandProperties = {
@HystrixProperty(name = "circuitBreaker.enabled", value = "false")
})
public String doHystrix(Integer param) throws Exception {
Thread.sleep(param);
return "1";
}
public String doNative(Integer param) throws Exception {
Thread.sleep(param);
return "1";
}
}壓測數據及解析
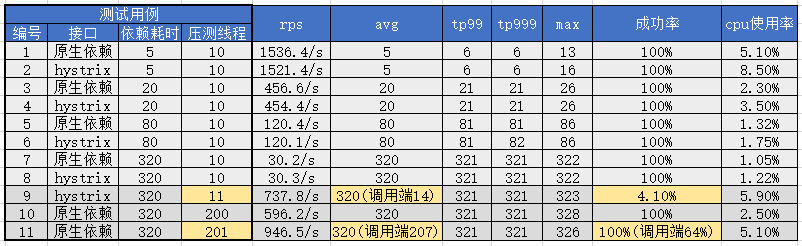
首先前8個用例和結果數據體現了在相同的正常壓力下(10線程)不同調用方式和不同性能依賴的吞吐量和性能指標,可以看出:
同樣耗時依賴條件下,hystrix會占用更多的cpu資源,但是並不顯著,並且當耗時增加時該影響持續減小(由於壓測介面無任何計算邏輯因此整體cpu使用很低,推測實際服務邏輯耗費CPU較多時hystrix的性能影響更不明顯,有待生產環境驗證)。
相同的壓測線程(hystrix處理線程也是10)下依賴耗時以及與之對應的平均耗時avg直接影響了介面的吞吐量(rps,每秒請求數)。觀察該規律可以得到公式:threads / avg(s) = rps,下麵舉例:
avg=320時,10 / 0.32 = 31.25,觀察用例7,8分別得到原生30.2和hystrix的30.3,基本吻合。
avg=80時,10 / 0.08 = 125,觀察用例5,6分別得到原生120.4和hystrix的120.1,有所損耗後吻合。
avg=20時,10 / 0.02 = 500,觀察用例3,4分別得到原生456.6和hystrix的454.4,損耗增加。
avg=5時,10 / 0.005 = 2000,觀察用例1,2分別得到原生1536.4和hystrix的1521.4,損耗較大。
其他信息:從上面數據也可以看出當rps增加到較高時線程調度本身帶來的損耗增加顯著,CPU使用率也顯著上升,即線程調度壓力開始顯著增加,無論是否使用hystrix這都是無法避免。hystrix在相同耗時對比中增加部分cpu使用率,對max指標有所影響,個別數據下對tp999也有所影響,但是影響都比較小。
後面三組測試用例則繼續提高壓測線程,由於hystrix預設配置10個線程,因此當壓測超過10個線程時,多出來的請求則會處理不過來,體現為線程池滿後直接拒絕,快速返回失敗,同時快速返回後壓測端又會立刻請求,結果就是rps迅速上升同時成功率急速下降,線程池正常處理的請求則未受影響,用例9體現了這一現象(服務端監控avg=320而客戶端由於大量1ms的快速失敗返回使avg=14)。
用例10和11是原生調用,我們繼續提高壓測線程到200和201,以期測試JSF的200線程池,得到結果符合預期,即JSF線程被打滿後無法處理額外的請求,與用例9表現相似,但是臨界值從10線程到200線程,更多的線程帶來了更多吞吐量。還有一點不同的細節在於,hystrix線程滿後返回異常時可以觸發我們的UMP監控,捕捉到成功率下降,但是JSF線程池滿後,直接拒絕請求,服務端無法監控到這些失敗,只有調用端能得到成功率下降的信息。
結論
通過上面壓測數據解析,我們可以對開始的問題進行解答。
額外的線程池是否有太大的性能開銷?
上述測試中hystrix對性能損耗並不大,不管是CPU使用率的增加已經性能指標的影響都不明顯,但是由於測試用例的局限性,不能說明所有情況,但我認為達到了到生產環境小範圍使用的條件,可以通過繼續積累使用經驗解答該問題。
The Netflix API processes 10+ billion HystrixCommand executions per day using thread isolation.
Each API instance has 40+ thread-pools with 5-20 threads in each (most are set to 10).
線程池大小設置多少合理?
我們在測試中得到了公式:threads / avg(s) = rps,實際上hystrix的文檔中也有一段類似的描述:
requests per second at peak when healthy × 99th percentile latency in seconds + some breathing room
30 rps * 0.2 second = 6 + breaking room = 10 threads
初看這段描述時難以理解,但是通過我們上面的壓測數據和公式可以明瞭,它將avg替換為了tp99,同時再增加了更多餘量,以期儘量避免正常流量增長和依賴波動導致線程池被打滿的情況。
舉一個實際例子,小金庫當前併發量最大的介面A,在去年雙十一壓測中達到了22.6W的RPS(是平時峰值10倍),一共有201台實例,單實例RPS=1124,tp99=6ms(avg=2ms),以此計算 1124 * 0.006 = 6.7,因此增加餘量到10(或15)即可滿足需求。
新問題,線程池滿了怎麼辦?
在上面測試數據解析中,我們發現由於hystrix為每個依賴嚴格限制了一個小的線程池,當線程池滿了後拒絕服務似乎影響很大。根據我們的公式threads = rps * avg(s),當流量過高時或依賴耗時增加過多時都會觸發線程池打滿。首先針對流量過高我們可以通過監控報警(主動增加線程數,可以動態配置生效) + 提前預設足夠的餘量解決。其次針對依賴耗時增加過多的問題,前面的做法也能部分解決該問題,但是回歸起點來說,某個依賴突然變得非常慢,以至於打滿JSF線程池造成應用整體不可用,這本來就是我們要用hystrix解決的問題,使用hystrix後故障依賴的調用快速失敗,同時失敗率積累到閾值後斷路器熔斷降級,在該依賴恢復後自動關閉斷路器,恢復對其調用 。

