
簡要概述索引 • 索引的特點 ○ 可以加快資料庫檢索的速度 ○ 降低資料庫插入 修改 刪除等維護的速度 ○ 只能創建在表上,不能創建到視圖上 ○ 既可以直接創建又可以間接創建 ○ 可以在優化隱藏中使用索引 ○ 使用查詢處理器執行SQL語句,在一個表上,一次只能使用一個索引 • 索引的優點 ○ 創建唯 ...
簡要概述索引
• 索引的特點
○ 可以加快資料庫檢索的速度
○ 降低資料庫插入 修改 刪除等維護的速度
○ 只能創建在表上,不能創建到視圖上
○ 既可以直接創建又可以間接創建
○ 可以在優化隱藏中使用索引
○ 使用查詢處理器執行SQL語句,在一個表上,一次只能使用一個索引
• 索引的優點
○ 創建唯一性索引,保證資料庫表中每一行數據的唯一性
○ 大大加快數據的檢索速度這時創建索引的主要原因
○ 加速資料庫之間的連接,特別是在實現數據的參考完整性方面特別有意義
○ 在使用分組和排序字句進行數據檢索時,同樣可以顯著減少查詢中分組和排序的時間
○ 通過使用索引,可以在查詢中使用優化隱藏器,提高系統的性能
• 索引的缺點
○ 創建索引和維護索引需要時間,這種時間隨著數據量的增加而增加,
○ 索引需要占用物理空間
○ 當對數據中的表中的數據進行增加 刪除 和修改的時候,索引也需要維護,降低數據維護的速度
• 索引的分類
○ 直接創建索引和間接創建索引
○ 普通索引和唯一性索引
○ 單個索引和複合索引
○ 聚簇索引和非聚簇索引
深入剖析其原理
「資料庫」和「資料庫索引」這兩個東西是在伺服器端開發領域應用最為廣泛的兩個概念,熟練使用資料庫和資料庫索引是開發人員在行業內生存的必備技能,使用索引很簡單,只要能寫創建表的語句,就肯定能寫創建索引的語句,要知道這個世界上是不存在不會創建表的伺服器端程式員的。然而,會使用索引是一回事,而深入理解索引原理又能恰到好處使用索引又是另一回事,這完全是兩個天差地別的境界(我自己也還沒有達到這層境界)。很大一部份程式員對索引的瞭解僅限於到“加索引能使查詢變快”這個概念為止。
• 為什麼要給表加上主鍵?
• 為什麼加索引後會使查詢變快?
• 為什麼加索引後會使寫入、修改、刪除變慢?
• 什麼情況下要同時在兩個欄位上建索引?
這些問題他們可能不一定能說出答案。知道這些問題的答案有什麼好處呢?如果開發的應用使用的資料庫表中只有1萬條數據,那麼瞭解與不瞭解真的沒有差別, 然而, 如果開發的應用有幾百上千萬甚至億級別的數據,那麼不深入瞭解索引的原理, 寫出來程式就根本跑不動,就好比如果給貨車裝個轎車的引擎,這貨車還能拉的動貨嗎?
接下來就講解一下上面提出的幾個問題,希望對閱讀者有幫助。
網上很多講解索引的文章對索引的描述是這樣的「索引就像書的目錄, 通過書的目錄就準確的定位到了書籍具體的內容」,這句話描述的非常正確, 但就像脫了褲子放屁,說了跟沒說一樣,通過目錄查找書的內容自然是要比一頁一頁的翻書找來的快,同樣使用的索引的人難到會不知道,通過索引定位到數據比直接一條一條的查詢來的快,不然他們為什麼要建索引。
想要理解索引原理必須清楚一種數據結構「平衡樹」(非二叉),也就是b tree或者 b+ tree,重要的事情說三遍:“平衡樹,平衡樹,平衡樹”。
我們平時建表的時候都會為表加上主鍵, 在某些關係資料庫中, 如果建表時不指定主鍵,資料庫會拒絕建表的語句執行。事實上, 一個加了主鍵的表,並不能被稱之為「表」。一個沒加主鍵的表,它的數據無序的放置在磁碟存儲器上,一行一行的排列的很整齊, 跟我認知中的「表」很接近。如果給表上了主鍵,那麼表在磁碟上的存儲結構就由整齊排列的結構轉變成了樹狀結構,也就是上面說的「平衡樹」結構,換句話說,就是整個表就變成了一個索引。沒錯, 再說一遍, 整個表變成了一個索引,也就是所謂的「聚集索引」。 這就是為什麼一個表只能有一個主鍵, 一個表只能有一個「聚集索引」,因為主鍵的作用就是把「表」的數據格式轉換成「索引(平衡樹)」的格式放置。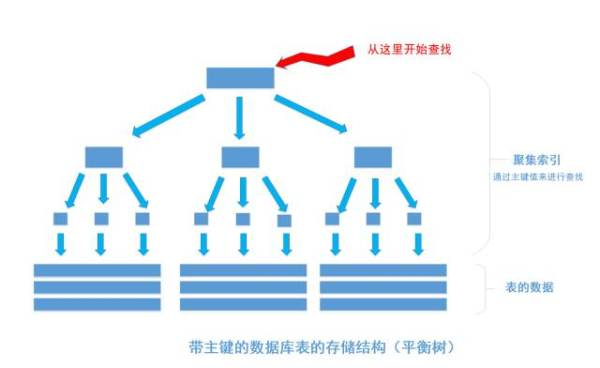
上圖就是帶有主鍵的表(聚集索引)的結構圖。圖畫的不是很好, 將就著看。其中樹的所有結點(底部除外)的數據都是由主鍵欄位中的數據構成,也就是通常我們指定主鍵的id欄位。最下麵部分是真正表中的數據。 假如我們執行一個SQL語句:
select * from table where id = 1256;
首先根據索引定位到1256這個值所在的葉結點,然後再通過葉結點取到id等於1256的數據行。 這裡不講解平衡樹的運行細節, 但是從上圖能看出,樹一共有三層, 從根節點至葉節點只需要經過三次查找就能得到結果。如下圖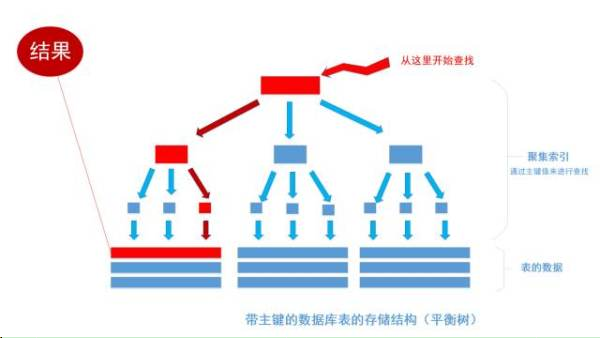
假如一張表有一億條數據 ,需要查找其中某一條數據,按照常規邏輯, 一條一條的去匹配的話, 最壞的情況下需要匹配一億次才能得到結果,用大O標記法就是O(n)最壞時間複雜度,這是無法接受的,而且這一億條數據顯然不能一次性讀入記憶體供程式使用, 因此, 這一億次匹配在不經緩存優化的情況下就是一億次IO開銷,以現在磁碟的IO能力和CPU的運算能力, 有可能需要幾個月才能得出結果 。如果把這張表轉換成平衡樹結構(一棵非常茂盛和節點非常多的樹),假設這棵樹有10層,那麼只需要10次IO開銷就能查找到所需要的數據, 速度以指數級別提升,用大O標記法就是O(log n),n是記錄總樹,底數是樹的分叉數,結果就是樹的層次數。換言之,查找次數是以樹的分叉數為底,記錄總數的對數,用公式來表示就是
用程式來表示就是Math.Log(100000000,10),100000000是記錄數,10是樹的分叉數(真實環境下分叉數遠不止10), 結果就是查找次數,這裡的結果從億降到了個位數。因此,利用索引會使資料庫查詢有驚人的性能提升。然而, 事物都是有兩面的, 索引能讓資料庫查詢數據的速度上升, 而使寫入數據的速度下降,原因很簡單的, 因為平衡樹這個結構必須一直維持在一個正確的狀態, 增刪改數據都會改變平衡樹各節點中的索引數據內容,破壞樹結構, 因此,在每次數據改變時, DBMS必須去重新梳理樹(索引)的結構以確保它的正確,這會帶來不小的性能開銷,也就是為什麼索引會給查詢以外的操作帶來副作用的原因。
講完聚集索引,接下來聊一下非聚集索引, 也就是我們平時經常提起和使用的常規索引。
非聚集索引和聚集索引一樣, 同樣是採用平衡樹作為索引的數據結構。索引樹結構中各節點的值來自於表中的索引欄位, 假如給user表的name欄位加上索引 , 那麼索引就是由name欄位中的值構成,在數據改變時,DBMS需要一直維護索引結構的正確性。如果給表中多個欄位加上索引 , 那麼就會出現多個獨立的索引結構,每個索引(非聚集索引)互相之間不存在關聯。 如下圖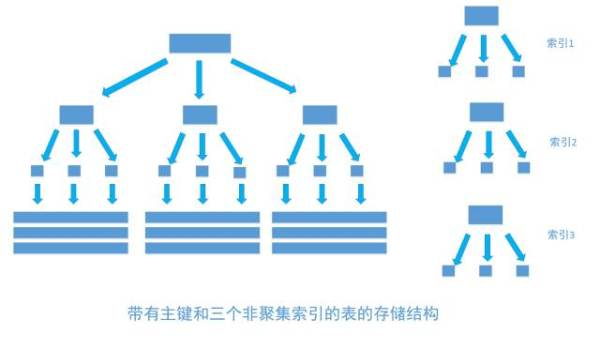
每次給欄位建一個新索引, 欄位中的數據就會被覆制一份出來, 用於生成索引。 因此, 給表添加索引,會增加表的體積, 占用磁碟存儲空間。
非聚集索引和聚集索引的區別在於, 通過聚集索引可以查到需要查找的數據, 而通過非聚集索引可以查到記錄對應的主鍵值 , 再使用主鍵的值通過聚集索引查找到需要的數據,如下圖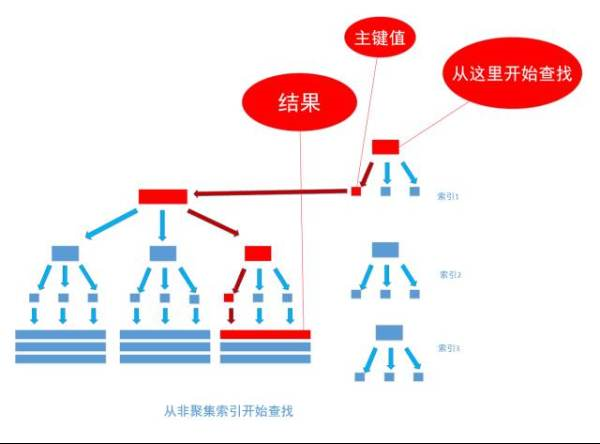
不管以任何方式查詢表, 最終都會利用主鍵通過聚集索引來定位到數據, 聚集索引(主鍵)是通往真實數據所在的唯一路徑。
然而, 有一種例外可以不使用聚集索引就能查詢出所需要的數據, 這種非主流的方法 稱之為「覆蓋索引」查詢, 也就是平時所說的複合索引或者多欄位索引查詢。 文章上面的內容已經指出, 當為欄位建立索引以後, 欄位中的內容會被同步到索引之中, 如果為一個索引指定兩個欄位, 那麼這個兩個欄位的內容都會被同步至索引之中。
先看下麵這個SQL語句
1 //建立索引 2 create index index_birthday on user_info(birthday); 3 //查詢生日在1991年11月1日出生用戶的用戶名 4 select user_name from user_info where birthday = '1991-11-1'
這句SQL語句的執行過程如下
• 首先,通過非聚集索引index_birthday查找birthday等於1991-11-1的所有記錄的主鍵ID值
• 然後,通過得到的主鍵ID值執行聚集索引查找,找到主鍵ID值對就的真實數據(數據行)存儲的位置
• 最後, 從得到的真實數據中取得user_name欄位的值返回, 也就是取得最終的結果
我們把birthday欄位上的索引改成雙欄位的覆蓋索引
1 create index index_birthday_and_user_name on user_info(birthday, user_name);
這句SQL語句的執行過程就會變為
• 通過非聚集索引index_birthday_and_user_name查找birthday等於1991-11-1的葉節點的內容。
• 然而, 葉節點中除了有user_name表主鍵ID的值以外, user_name欄位的值也在裡面。
• 因此不需要通過主鍵ID值的查找數據行的真實所在, 直接取得葉節點中user_name的值返回即可。 通過這種覆蓋索引直接查找的方式, 可以省略不使
覆蓋索引查找的後面兩個步驟, 大大的提高了查詢性能,如下圖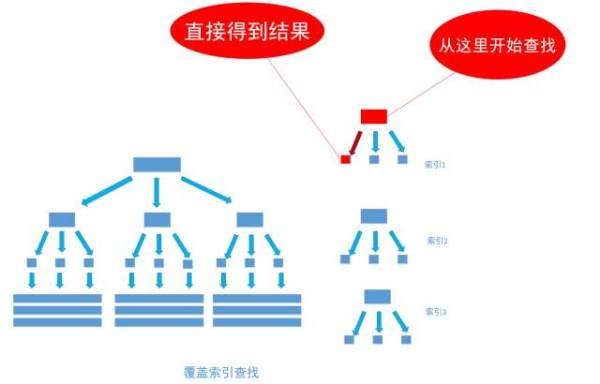
資料庫索引的大致工作原理就是像文中所述, 然而細節方面可能會略有偏差,這但並不會對概念闡述的結果產生影響 。


